Python爬虫库Scrapy入门1--爬取当当网商品数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫库Scrapy入门1--爬取当当网商品数据相关的知识,希望对你有一定的参考价值。
1.关于scrapy库的介绍,可以查看其官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/
2.安装:pip install scrapy 注意这个库的运行需要pywin32的支持,因此还需要安装pywin32。可以在这个网站上选择合适的版本下载安装:https://sourceforge.net/projects/pywin32/files/pywin32/
3.挖掘当当网商品数据:
首先需要创建一个名为dangdang的爬虫项目,在powershell中进入你项目所在的位置:
D:\\Py\\myweb>scrapy startproject dangdang
New Scrapy project ‘dangdang‘, using template directory ‘d:\\\\python35\\\\lib\\\\site-packages\\\\scrapy\\\\templates\\\\project‘, created in:
D:\\Python35\\myweb\\dangdang
You can start your first spider with:
cd dangdang
scrapy genspider example example.com
创建好了爬虫项目之后, 需要进入该爬虫项目,然后在爬虫项目中创建一个爬虫,如下所示:
D:\\Py\\myweb>cd .\\dangdang
D:\\Py\\myweb\\dangdang>scrapy genspider -t basic dangspd dangdang.com
Created spider ‘dangspd‘ using template ‘basic‘ in module:
Dangdang.spiders.dangspd
随后, 需要编写items.py文件,在该文件中定义好需要爬取的内容, 将items.py文件修改为如下所示:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#商品标题
title=scrapy.Field()
#商品评论数
num=scrapy.Field()
随后,需要编写pipelines.py文件,在pipelines.py文件中,一般会编写一些爬取后数据处理的代码们需要将爬取到的信息依次展现到屏幕上同时保存在本地txt中,将pipelines.py文件修改为如下所示:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class DangdangPipeline(object): def process_item(self, item, spider): #item=dict(item) #print(len(item["name"])) for j in range(0,len(item["title"])): print(j) title=item["title"][j] num=item["num"][j] print("商品名:"+title) print("商品评论数:"+num) print("--------")
with open("result.txt",‘a‘) as f:
f.write(title+"\\t"+num +"\\n") return item
随后,接下来 还需要编写配置文件settings.py,编写配置文件的目的有两个:
1)、启用刚刚编写的pipelines,因为默认是不启用的。
2)、设置不遵循robots协议爬行,因为该协议对 的爬虫有相关限制,遵循该协议,可能会无法爬取到结果。
可以将配置文件settings.py的robots协议配置部分修改为如下所示,此时值设置为False,代表让爬虫不遵循当当网的robots协议爬行,当然 不要利用这些技术做违法事项。
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
然后, 再将配置文件settings.py的pipelines配置部分设置为如下所示,开启对应的pipelines:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
‘dangdang.pipelines.DangdangPipeline‘: 300,
}
随后, 需要分析当当网的网页结构,总结出信息提取的规则以及自动爬行的规律。
打开某一个频道页,各页对应的网址如下所示:
http://category.dangdang.com/pg1-cid4002644.html
http://category.dangdang.com/pg2-cid4002644.html
http://category.dangdang.com/pg3-cid4002644.html
……
此时,会发现,网页的格式形如:http://category.dangdang.com/pg[页码]-cid4002644.html
有了该规律之后,可以将页码位置设置为变量,通过for循环就可以构造出一个频道中所有的商品页,也就通过这种方式实现了自动爬取。
然后,再分析商品信息的提取规律。
打开任意一个频道页http://category.dangdang.com/pg1-cid4002644.html,然后可以看到如下界面:

此时 需要提取该页面中所有的商品标题和商品评论信息,将其他无关信息过滤掉。所以, 可以查看该网页源代码,以第一个商品为例进行分析,然后总结出所有商品的提取规律。 可以右键--查看源代码,然后通过ctrl+find快速定位源码中该商品的对应源代码部分,如下所示:
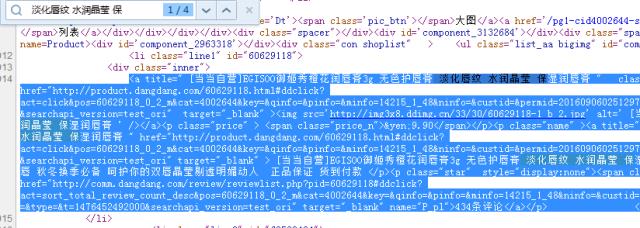
对应源代码复制出来如下所示:
……
<a title=" [当当自营]EGISOO御姬秀橙花润唇膏3g 无色护唇膏 淡化唇纹 水润晶莹 保湿润唇膏 " class="pic" href="https://ask.hellobi.com/http://product.dangdang.com/60629118.html#ddclick?act=click&pos=60629118_0_2_m&cat=4002644&key=&qinfo=&pinfo=&minfo=14215_1_48&ninfo=&custid=&permid=20160906025129757347420307757891648&ref=&rcount=&type=&t=1476452492000&searchapi_version=test_ori" target="_blank" ><img src=‘http://img3x8.ddimg.cn/33/30/60629118-1_b_2.jpg‘ alt=‘ [当当自营]EGISOO御姬秀橙花润唇膏3g 无色护唇膏 淡化唇纹 水润晶莹 保湿润唇膏 ‘ /></a><p class="price" > <span class="price_n">¥9.90</span></p><p class="name" ><a title=" [当当自营]EGISOO御姬秀橙花润唇膏3g 无色护唇膏 淡化唇纹 水润晶莹 保湿润唇膏 " href="https://ask.hellobi.com/http://product.dangdang.com/60629118.html#ddclick?act=click&pos=60629118_0_2_m&cat=4002644&key=&qinfo=&pinfo=&minfo=14215_1_48&ninfo=&custid=&permid=20160906025129757347420307757891648&ref=&rcount=&type=&t=1476452492000&searchapi_version=test_ori" target="_blank" > [当当自营]EGISOO御姬秀橙花润唇膏3g 无色护唇膏 淡化唇纹 水润晶莹 保湿润唇膏 </a></p><p class="subtitle" > 明星都在用 水润护唇 秋冬换季必备 呵护你的双唇晶莹剔透明媚动人 正品保证 货到付款 </p><p class="star" style="display:none"><span class="level"><span style="width: 100%;"></span></span><a href="https://ask.hellobi.com/http://comm.dangdang.com/review/reviewlist.php?pid=60629118#ddclick?act=sort_total_review_count_desc&pos=60629118_0_2_m&cat=4002644&key=&qinfo=&pinfo=&minfo=14215_1_48&ninfo=&custid=&permid=20160906025129757347420307757891648&ref=&rcount=&type=&t=1476452492000&searchapi_version=test_ori" target="_blank" name="P_pl">434条评论</a></p> </div>
……
所以,可以得到提取商品标题和商品评论的Xpath表达式,如下所示:
#提取商品标题
"//a[@class=‘pic‘]/@title"
#提取商品评论
"//a[@name=‘P_pl‘]/text()"
此时, 已经总结出了信息提取的对应的Xpath表达式,然后 可以编写刚才最开始的时候创建的爬虫文件dangspd.py了, 将爬虫文件编写修改为如下所示:
# -*- coding: utf-8 -*-
import scrapy
import re
from dangdang.items import DangdangItem
from scrapy.http import Request
class DangspdSpider(scrapy.Spider):
name = "dangspd"
allowed_domains = ["dangdang.com"]
start_urls = (
‘http://category.dangdang.com/pg1-cid4002644.html‘,
)
def parse(self, response):
item=DangdangItem()
item["title"]=response.xpath("//a[@class=‘pic‘]/@title").extract()
item["num"]=response.xpath("//a[@name=‘P_pl‘]/text()").extract()
yield item
for i in range(2,101):
url="http://category.dangdang.com/pg"+str(i)+"-cid4002644.html"
yield Request(url, callback=self.parse)
这样,就可以实现爬虫的编写了。
随后, 可以进入调试和运行阶段。
进入cmd界面,运行该爬虫,出现如下所示结果,中间结果太长,省略了部分:
D:\\Py\\myweb\\dangdang>scrapy crawl dangspd --nolog
……
43
商品名: WIS水润面膜套装24片 祛痘控油补水保湿淡痘印收缩毛孔面膜贴男女
商品评论数:255条评论
--------
44
商品名: 欧诗漫 水活奇迹系列【水活奇迹珍珠水(清润型)+珍珠水活奇迹保湿凝乳】
商品评论数:0条评论
--------
45
商品名: 【法国进口】雅漾(Avene)活泉恒润保湿精华乳30ml 0064
商品评论数:0条评论
--------
46
商品名: 【法国进口】Avene雅漾敏感肌肤护理净柔洁面摩丝150ml温和泡沫洁面乳洗面奶0655
商品评论数:0条评论
--------
47
商品名: 珍视明中老年护眼贴2盒装 30对60贴 针对中老年用眼问题 缓解眼疲劳
商品评论数:226条评论
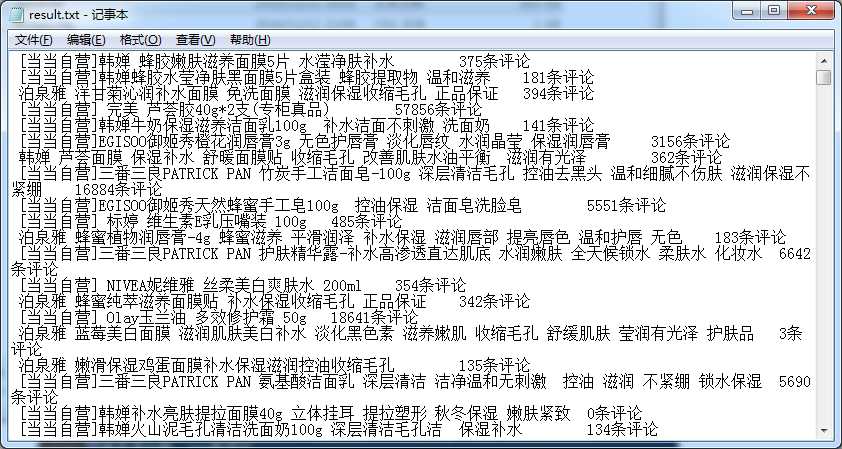
而且在本地文件会有一个result.txt文件。里面数据:
以上是关于Python爬虫库Scrapy入门1--爬取当当网商品数据的主要内容,如果未能解决你的问题,请参考以下文章