Python爬虫实战---抓取图书馆借阅信息
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫实战---抓取图书馆借阅信息相关的知识,希望对你有一定的参考价值。
Python爬虫实战---抓取图书馆借阅信息
原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息
前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约,影响日后借书,而自己又懒得总是登录到学校图书馆借阅系统查看,于是就打算写一个爬虫来抓取自己的借阅信息,把每本书的应还日期给爬下来,并写入txt文件,这样每次忘了就可以打开该txt文件查看,每次借阅信息改变了,只要再重新运行一遍该程序,原txt文件就会被新文件覆盖,里面的内容得到更新。
用到的技术:
Python版本是 2.7 ,同时用到了urllib2、cookielib、re三个模块。urllib2用于创建请求(request),并抓取网页信息,返回一个类似于文件类型的response对象;cookielib用于储存cookie对象,以实现模拟登录功能;re模块提供对正则表达式的支持,用于对抓取到的页面信息进行匹配,以得到自己想要的信息。
抓取一个页面:
使用urllib2简单抓取一个网页的过程非常简单:
1 import urllib2 2 response = urllib2.urlopen("http://www.baidu.com") 3 html = response.read()urllib2中的urlopen()方法,看其字面意思就知道是打开一个URL(uniform resource locator)地址,上面例子传入的时百度首页的地址,遵循HTTP协议,除了http协议外,urlopen()方法还可以打开遵循ftp、file协议的地址,如:
1 response = urllib2.urlopen("ftp://example.com")除URL参数外,urlopen()方法还接受data和timeout参数:
1 response = urllib2.urlopen(url ,data ,timeout)其中data是打开一个网页时需要传入的数据,比如打开一个登录界面时往往需要传入用户名和密码等信息,在下文登录图书馆系统时将会看到其用法;timeout是设置超时时间,即超过一定时间页面无响应即报错;在urlopen()方法中,data和timeout不是必须的,即可填可不填,注意:当页面需要有数据传入时,data是必需的。
可以看到,在打开一个网页时,有时往往需要传入多个参数,再加上HTTP协议是基于请求(request)和应答(response)的,即客户端发出请求(request),服务器端返回应答(response),所以在使用urlopen()方法时,往往是构造一个request对象作为参数传入,该request对象包括url、data、timeout、headers等信息:
1 import urllib2 2 request = urllib2.Request("http://www.baidu.com") 3 response = urllib2.urlopen(request) 4 html = response.read()这段代码得到的结果和上面得到的结果一样,但是在逻辑上显得更明确、清晰。
Cookie的使用:
在访问某些网站时,该网站需要在客户端本地储存一些数据、信息(经过加密),并在接下来的请求(request)中返回给服务器,否则服务器将拒绝该请求,这些数据即存储在本地的cookie中。例如,访问学校图书馆系统时,需进行登录,等登录完成之后,服务器端将会在本地储存一些经过加密的数据在cookie中,当客户端发送查询借阅信息的请求(request)时,会连带cookie里面的数据一起发送给服务器,服务器确定cookie信息后允许访问,否则拒绝该请求。
Cookielib模块提供了CookieJar类用于捕捉和储存HTTP 的cookie数据,所以要创建一个cookie只要创建一个CookieJar实例即可:
1 import cookielib 2 cookie = coolielib.CookieJar()创建cookie了就万事大吉了吗?没那么简单,我们要完成的操作是发送登录请求、记录cookie、再发送读取借阅信息的请求并向服务器反馈cookie信息,要完成这一系列的操作,原来的urlopen()方法已不能胜任,幸运的是,urllib2模块还提供了一个OpenerDirector类,可以接受一个cookie处理器为参数,实现上述功能,而这个cookie处理器则可以通过HTTPCookieProcessor类接受一个cookie对象实例化后得到。即先通过HTTPCookieProcessor实例化得到一个cookie处理器handler,再将此处理器headler作为参数传入OpenDirector实例化得到一个能捕捉cookie数据的opener,代码如下:
1 import urllib2 2 import cookielib 3 4 cookie = cookielib.CookieJar() 5 handler = urllib2.HTTPCookieProcessor(cookie) 6 opener = urllib2.build_opener(handler) 7 response = opener.open("http://www.baidu.com")登录图书馆系统:
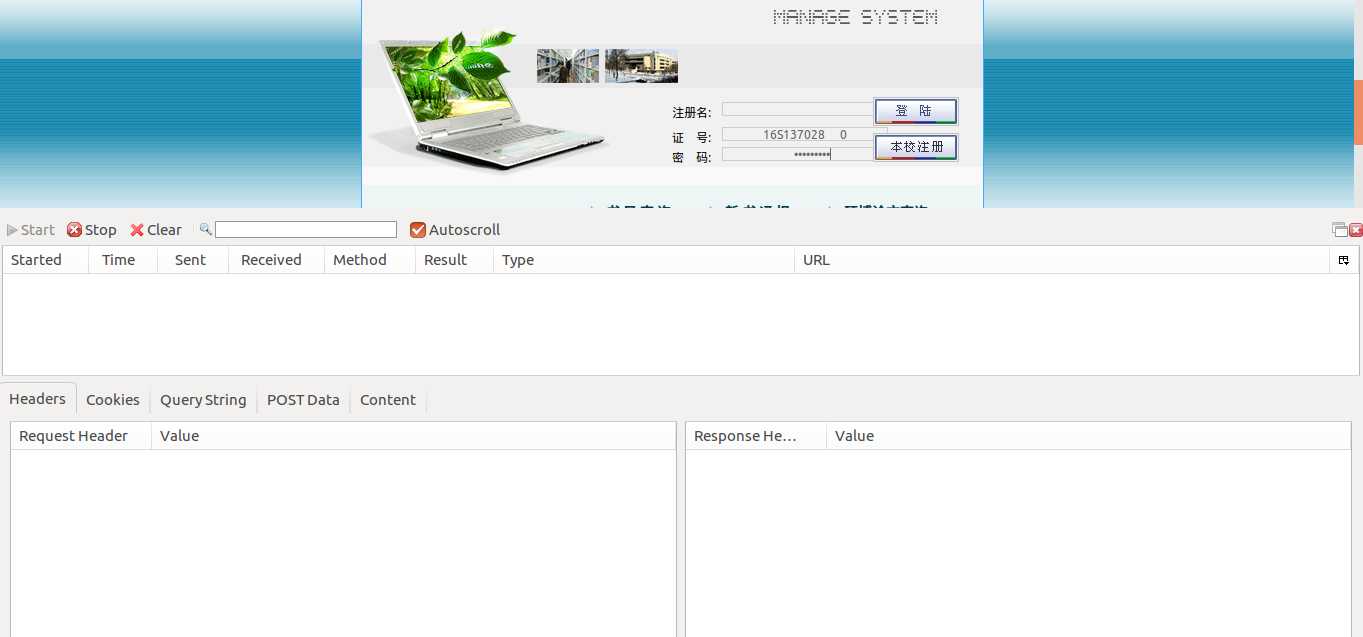
至此,我们就可以进行图书馆借阅信息的抓取了。来看看hit图书馆登录界面:
首先,在Firefox浏览器下,借助httpfox插件进行网络监听,看看登录此页面需要向服务器发送哪些数据:
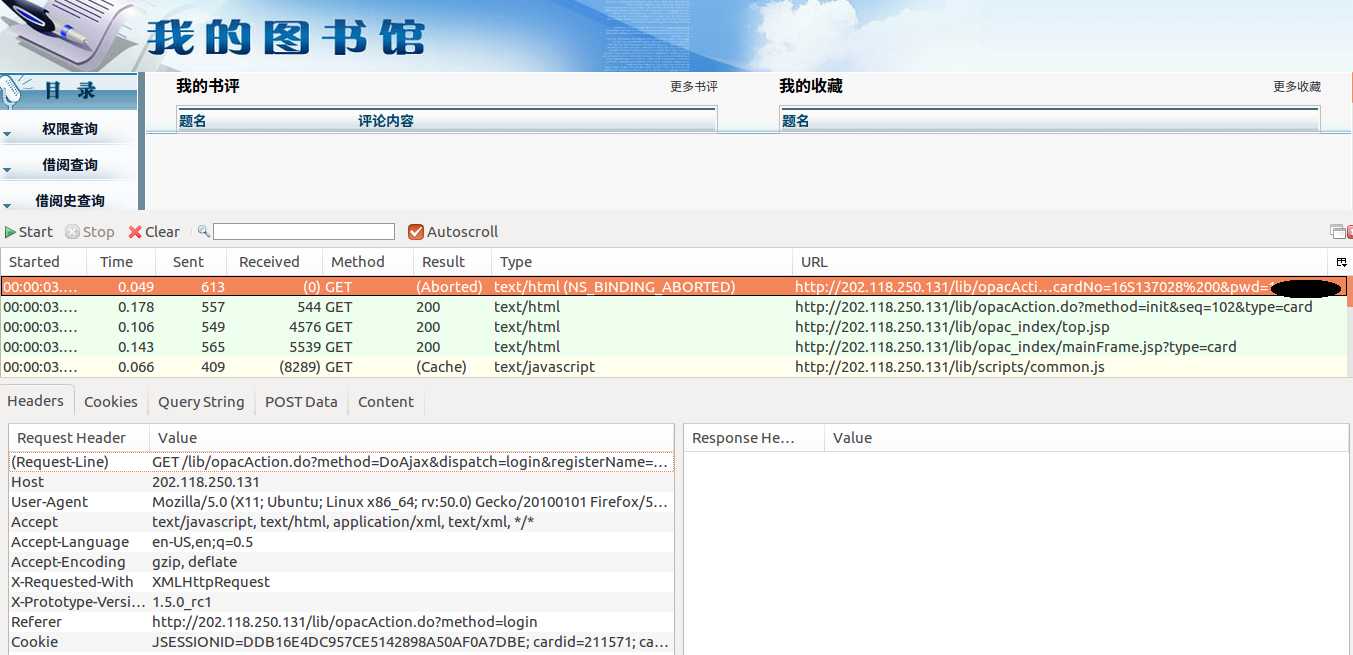
输入登录账号和密码,打开httpfox插件,点击start开始监听,然后点击登陆按钮进行登陆:
上图便是登陆之后的页面,以及整个登陆过程捕捉到的信息。选择第一条捕捉到的信息,点击下方数据头(Headers)选项卡,可以看见登录此页面需要发送的一些数据。有一些网站,对于访问它们的请求需要检查数据头(Headers),只有数据头信息符合要求才允许访问。在登录图书馆系统时,可以先尝试不发数据头,如果能顺利访问则说明没有Headers检查这一环节。数据发送的方法为GET,即只需要将要发送的数据信息加在登陆请求的后面。在Headers选项卡的Request-Line属性中,问号前面的即为登陆请求"GET /lib/opacAction.do",加上IP地址之后真实的请求URL为"http://202.118.250.131/lib/opacAction.do",问号后面的即为登陆需要的数据,包括账号、密码等信息。
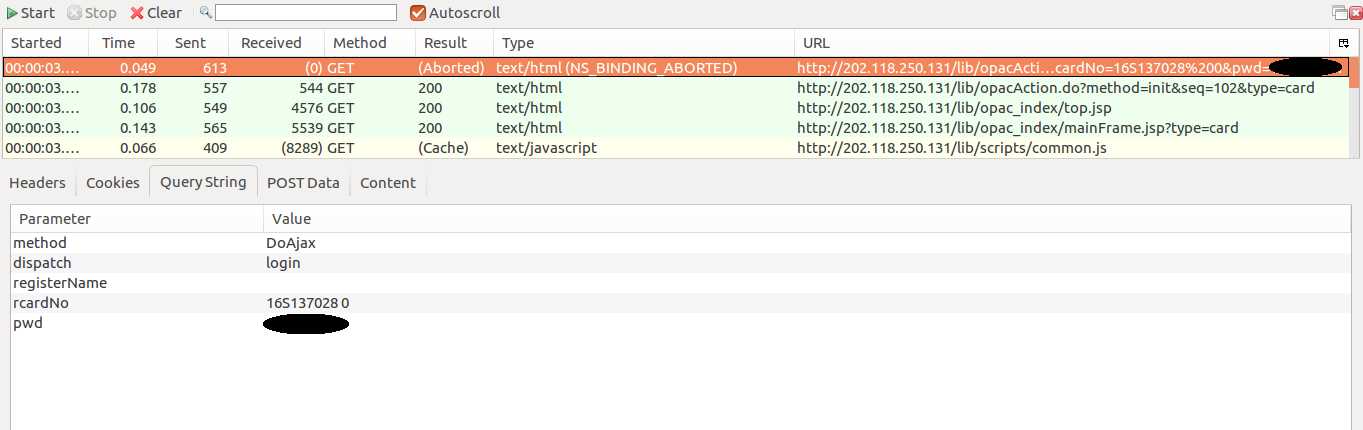
接下来点开QueryString选项卡,查看由GET方法传送的数据:
需要传送的数据包括5项,以字典类型将其储存,经过urlencode()方法编码之后直接加在登陆URL之后即可,所以最后向服务器发送的请求(request)为:
1 import urllib 2 3 loginURL = ‘http://202.118.250.131/lib/opacAction.do‘ 4 queryString = urllib.urlencode({ 5 ‘method‘:‘DoAjax‘, 6 ‘dispatch‘:‘login‘, 7 ‘registerName‘:‘‘, 8 ‘rcardNo‘:‘16S137028 0‘, 9 ‘pwd‘:‘******‘ 10 }) 11 requestURL = self.loginURL + ‘?‘ + self.queryString得到请求URL之后就可以模拟登陆图书馆系统了,在模拟登陆的过程中需要用到前面讲到的cookie,否则无法进行后续的访问。在编代码过程中,定义一个library类,使访问过程变成一个面向对象的过程,可以根据需要实例化多个library对象,分别对多个实例进行操作。首先分析,该library类应该有一个初始化方法(__init__)以及一个获取页面的方法(getPage),在打开网页是,应使用上文提到opener实例,自动捕获并储存cookie:
1 import urllib 2 import urllib2 3 import cookielib 4 import re 5 6 class library: 7 def __init__(self): 8 self.loginURL=‘http://202.118.250.131/lib/opacAction.do‘ 9 self.queryString = urllib.urlencode({ 10 ‘method‘:‘DoAjax‘, 11 ‘dispatch‘:‘login‘, 12 ‘registerName‘:‘‘, 13 ‘rcardNo‘:‘16S137028 0‘, 14 ‘pwd‘:‘114477yan‘ 15 }) 16 self.requestURL = self.loginURL + ‘?‘ + self.queryString 17 self.cookies=cookielib.CookieJar() 18 self.handler=urllib2.HTTPCookieProcessor(self.cookies) 19 self.opener=urllib2.build_opener(self.handler) 20 def getPage(self): 21 request1 = urllib2.Request(self.requestURL) 22 request2 = urllib2.Request(‘ http://202.118.250.131/lib/opacAction.do?method=init&seq=301 ‘) 23 result = self.opener.open(request1) 24 result = self.opener.open(request2) 25 return result.read() 26 27 lib = library() 28 print lib.getPage()
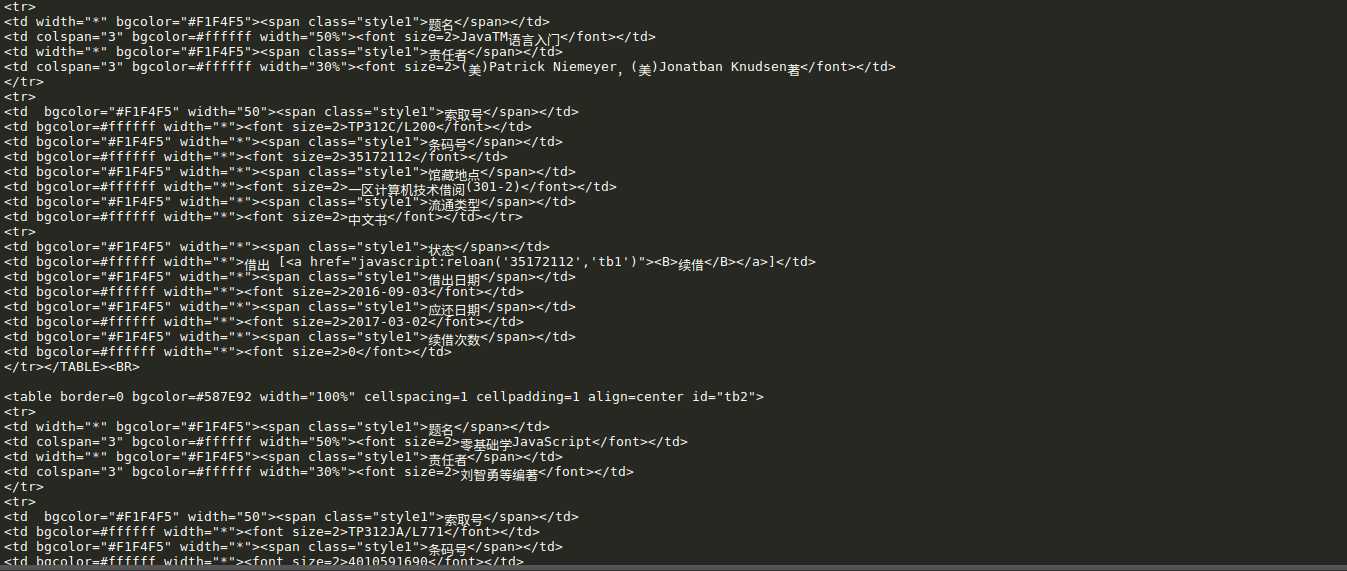
上述代码中,先是进行登录 result = self.opener.open(request1) ,登录没有异常,说明登录过程不用检查数据头;然后再用此 self.opener 打开借阅查询页面
http://202.118.250.131/lib/opacAction.do?method=init&seq=301 ,所以这段代码将打印借阅查询界面的HTML代码,下图是部分打印结果:
获取借阅信息:
抓取了页面信息之后,接下来就是根据自己的需要匹配、储存信息了。在匹配页面信息时,这里用的是正则表达式的方式进行匹配,正则表达式的支持由Python的Re模块提供支持,关于如何使用正则表达式,可以参考这里:Python正则表达式指南
使用Re模块进行匹配时,往往先将正则表达式字符串编译(compile)成一个Pattern实例,再利用Re模块中的re.findall(pattern , string),将字符串string中和正则表达式匹配的数据以列表的形式返回。如果在pattern中有超过一个组(group),则返回的结果将是一个元组列表,如此正则表达式: <table.*?id="tb.*?width="50%"><font size=2>(.*?)</font>.*?<tr>.*?<tr>.*?<font size=2>(.*?)</font>.*?<font size=2>(.*?)</font>.*?</TABLE> ,式中,每一个 (.*?) 代表一个组,即此式中有3个组,则匹配时,返回一个元组列表,其中每一个元组又有3个数据。
在library类中,定义一个获取信息的方法(getInformation),以通过正则表达式匹配的方式获取所需数据:
1 def getInformation(self): 2 page = self.getPage() 3 pattern = re.compile(‘<table.*?id="tb.*?width="50%"><font size=2>(.*?)</font>.*?<tr>.*?<tr>.*?‘+ 4 ‘<font size=2>(.*?)</font>.*?<font size=2>(.*?)</font>.*?</TABLE>‘,re.S) 5 items = re.findall(pattern,page)获取所需数据之后,接下来就是将数据写入文本文件(txt)储存,以读写模式(W+)打开一个文件(library.txt),然后通过write()方法将数据一条一条的写入文件。不过,在信息写入之前,需要对抓取到的信息做一些小处理,刚才说过了,findall()方法返回的是一个元组列表,即[[a,b,c],[d,e,f],[g,h,i]]的形式,write()方法是不能对元组进行操作的,所以需要手动将元组翻译成一条条字符串,再保存到一个列表里,通过遍历将每条字符串写入文件:
1 def getInformation(self): 2 page = self.getPage() 3 pattern = re.compile(‘<table.*?id="tb.*?width="50%"><font size=2>(.*?)</font>.*?<tr>.*?<tr>.*?‘+ 4 ‘<font size=2>(.*?)</font>.*?<font size=2>(.*?)</font>.*?</TABLE>‘,re.S) 5 items = re.findall(pattern,page) 6 7 contents = [] 8 for item in items: 9 content = item[0]+‘ from ‘+item[1]+‘ to ‘+item[2]+‘\\n‘ 10 contents.append(content) 11 self.writeData(contents) 12 def writeData(self,contents): 13 file = open(‘libraryBooks.txt‘,‘w+‘) 14 for content in contents: 15 file.write(content) 16 file.close()至此,整个爬虫就算完成了,下面贴上完整代码:
大功告成:
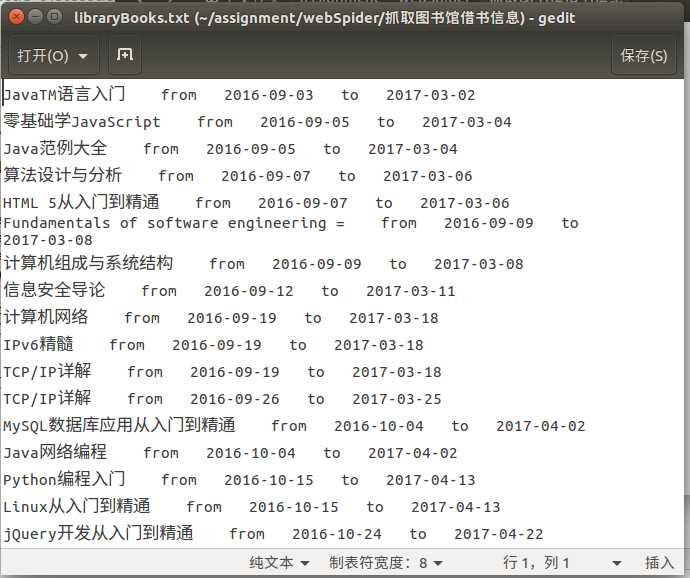
1 __author__=‘Victor‘ 2 #_*_ coding:‘utf-8‘ _*_ 3 import urllib 4 import urllib2 5 import cookielib 6 import re 7 8 class library: 9 def __init__(self): 10 self.loginURL=‘http://202.118.250.131/lib/opacAction.do‘ 11 self.queryString = urllib.urlencode({ 12 ‘method‘:‘DoAjax‘, 13 ‘dispatch‘:‘login‘, 14 ‘registerName‘:‘‘, 15 ‘rcardNo‘:‘16S137028 0‘, 16 ‘pwd‘:‘114477yan‘ 17 }) 18 self.requestURL = self.loginURL + ‘?‘ + self.queryString 19 self.cookies=cookielib.CookieJar() 20 self.handler=urllib2.HTTPCookieProcessor(self.cookies) 21 self.opener=urllib2.build_opener(self.handler) 22 def getPage(self): 23 request1 = urllib2.Request(self.requestURL) 24 request2 = urllib2.Request(‘http://202.118.250.131/lib/opacAction.do?method=init&seq=301‘) 25 result = self.opener.open(request1) 26 result = self.opener.open(request2) 27 return result.read() 28 def getInformation(self): 29 page = self.getPage() 30 pattern = re.compile(‘<table.*?id="tb.*?width="50%"><font size=2>(.*?)</font>.*?<tr>.*?<tr>.*?‘+ 31 ‘<font size=2>(.*?)</font>.*?<font size=2>(.*?)</font>.*?</TABLE>‘,re.S) 32 items = re.findall(pattern,page) 33 34 contents = [] 35 for item in items: 36 content = item[0]+‘ from ‘+item[1]+‘ to ‘+item[2]+‘\\n‘ 37 contents.append(content) 38 self.writeData(contents) 39 def writeData(self,contents): 40 file = open(‘libraryBooks.txt‘,‘w+‘) 41 for content in contents: 42 file.write(content) 43 file.close() 44 45 lib = library() 46 lib.getInformation()下面就是抓到的借阅信息,不得不说效果不怎么样,不过还是凑合着看把:
原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息
以上是关于Python爬虫实战---抓取图书馆借阅信息的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(69): 项目实战--抓取当当图书排行榜
Python爬虫编程思想(92):项目实战:抓取京东图书评价
Python爬虫编程思想(92):项目实战:抓取京东图书评价
Python爬虫编程思想(47):项目实战:抓取豆瓣Top250图书榜单