Python爬虫编程思想(47):项目实战:抓取豆瓣Top250图书榜单
Posted 蒙娜丽宁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫编程思想(47):项目实战:抓取豆瓣Top250图书榜单相关的知识,希望对你有一定的参考价值。
本文使用requests库、lxml库以及XPath抓取豆瓣网Top250图书排行榜。读者可以通过https://book.douban.com/top250访问Top250图书榜单,如图1所示。
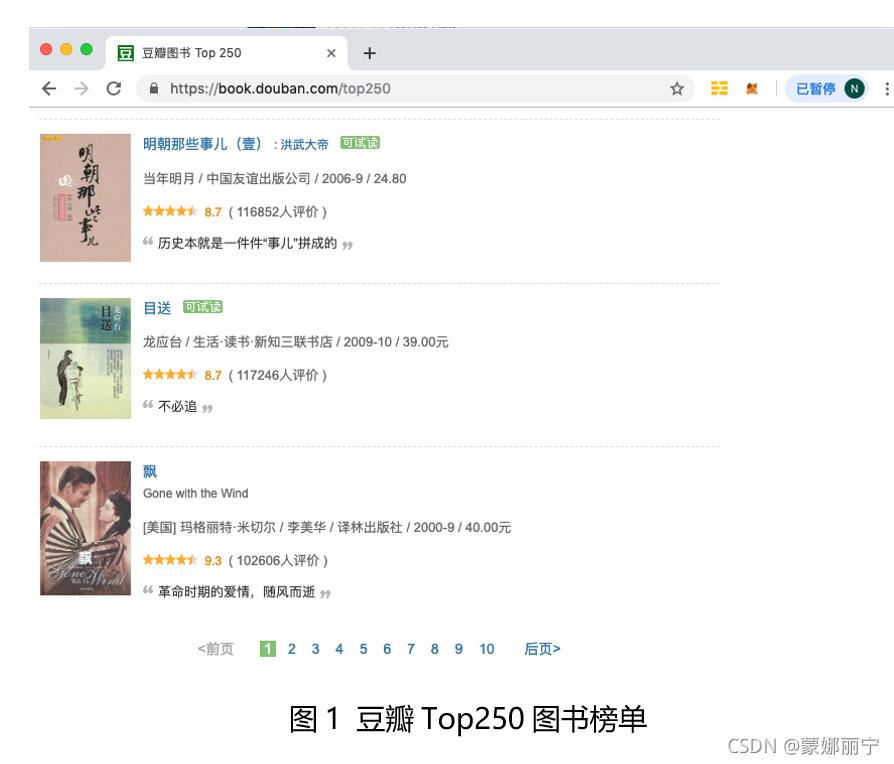
在开始编写爬虫之前,先要分析一下Top250榜单代码和页面切换的规律。首先来分析一下页面切换的规则。在页面的最下方是分页导航条,分别切换到第1页、第2页、第3页、第4页,在地址栏会看到如下的4个URL
https://book.douban.com/top250?start=0
https://book.douban.com/top250?start=25
https://
以上是关于Python爬虫编程思想(47):项目实战:抓取豆瓣Top250图书榜单的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(92):项目实战:抓取京东图书评价
Python爬虫编程思想(126):项目实战--实时抓取“得到”App在线课程
Python爬虫编程思想(126):项目实战--实时抓取“得到”App在线课程