什么叫做P2P
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么叫做P2P相关的知识,希望对你有一定的参考价值。
常常听别人在互联网上说什么P2P。请问什么是P2P
未来互联网发展趋势是什么?(这个可以不回答。呵呵)
一、认识P2P
1998年,18岁的肖恩·范宁为了解决室友如何在网上找音乐的问题而开发了Napster软件,在短时间内就拥有了8000万的用户!它带给我们新的体验,改变了我们的生活,Napster也理所当然地成为了P2P技术诞生的标志,从此以后,P2P开始了极富生命力的发展。
[图1]P2P为英文Peer to Peer的简写,意为对等网络,简单地说就是互联网上的每台计算机都可以作为一个节点来与其他节点直接进行通讯,它又可以分为少量依赖Server、完全依赖Server和完全不依赖Server三种方式。P2P让人们通过互联网直接交互,每台计算机既充当着服务器又充当着客户端的角色。使用P2P模式进行下载可在下载同一文件的同时将已下载的部分数据传递给其它的计算机,将上传的开销分摊到各个下载者那里,这样“下载人数越多,下载速度越快”(P2P下载原理如图1所示)。
P2P下载最大的优点是下载速度不再受服务器带宽及下载人数的限制,它充分利用了传统下载方式空闲的上传带宽。但P2P下载也有一些缺点,如:长期霸占带宽资源可导致内网通信中断,如果“种子”过期则无法下载。
二、主流的P2P软件
目前,众多P2P下载工具已经给用户带来了各种便利,比较有特色的包括:Bitcomet、迅雷、Emule(电骡)、风播等。下面就这几种软件进行深入的比较,以便大家能够对P2P 技术有更深刻的认识。
Bitcomet:BT下载的全称是Bit Torrent,而Bitcomet是美国人Bram cohen 在2001年开发的一个开源和开放协议的下载工具,其技术特点是简单有效,设计十分精巧,而且比起老前辈 Napster、Kazaa 、Gnutella 等来,由于有了MFTP多源下载技术,速度提升十分快。
迅雷:它2004年出现,开始是与Flashget 网际快车类似的下载工具,由于迅雷兼容了传统的FTP和HTTP下载技术,同时支持P2SP 技术,所以下载速率得到不少提升。
Emule(电骡):它实际是源于电驴EDonkey,两者的协议基本相同,只不过后来由不同的开源组织进行维护。电骡最大的优点是可以支持软件内搜索,而且可以搜索到的资源很多。
风播:它是2006年出现的一个新兴的P2P视频点播软件,不仅仅支持常规下载,而且还支持在下载的同时观看影视节目。所以我们不必等待几小时到影片下载完毕再观看。最重要的是风播兼容BT协议和Torrent种子文件,所以节目源非常丰富。
三、下载技术大比武
1.如何找到下载文件
P2P技术的实现原理其实基本是一样的,打个比方,我要和某个不认识的朋友通信,但我不知道对方的联系方式,最简单的方式就是我和对方都在一个我们共同知道的地方留下联系方式。在P2P网络中,这个共同知道的地方就是目录服务器。每个客户端首先需要登录到目录服务器上,在登录的时候客户端需要将自己拥有的资源向服务器汇报一下,这样当其他客户端希望下载某个资源时,只需要向服务器查询一下拥有该资源的客户端IP地址和端口,然后直接联系客户端即可。在BT和风播中,目录服务器被称为Tracker;在电骡中,目录服务器被称为电骡服务器,迅雷也有类似的中央控制服务器。
当前,已经出现了纯P2P技术,就是无需目录服务器的DHT动态哈希表技术,BT、风播、电骡均支持。DHT技术实际上也是一种特殊的目录服务器,只不过把中央目录服务器变为很多小目录服务器。由于细节比较复杂,就不在这里继续讨论了。
2.如何让下载的人越多速度越快
P2P下载速度快的秘密就是MFTP(多源下载)技术,可以将下载速率提高至少10倍。MFTP技术的核心有三点:一是要将资源文件分割成等长的分片,这样便于标记和处理;二是客户端之间必须互相了解对方都有哪些文件分片,这样便于互通有无,达到边下载边上传的目的;三是客户端收到一个分片后,必须有机制可以校验该分片是正确的,否则如果一个分片错误会导致整个资源文件损坏。
BT和风播采用的分片是可以调整的,是从64KB到8MB不等,一般在512KB至1MB之间,电骡是9.28MB。迅雷也有类似的分片技术,但是不支持在下载的同时上传。分片大小对下载效率还是有影响的,一般来说,分片大了,客户端之间互相交互所消耗的流量也会比较小,因为客户端互相交互分片信息也是需要数据包的,但是分片大了,会导致传输效率下降。
有些用户使用BT和风播的时候,不明白Torrent 种子文件是什么,其实种子文件记录的信息很大一部分就是每个文件分片的校验和。而电骡的文件校验和又在哪里呢?大家可以打开电骡的Temp目录,里面有一个后缀名为part.met的文件,里面就包含了校验和。
3.如何搜索到下载资源
这里所说的资源搜索其实主要是资源的展示方面,也就是平时我们如何找到我们想下载的资源文件。
电骡是依靠服务器和客户端两种搜索方式,电骡依靠强制共享,将每个骡友的部分硬盘目录及文件共享出去,在电骡启动时候,它会将我们电脑的共享目录上报到电骡服务器上,这样其他骡友就可以直接到服务器上进行搜索了。
BT、迅雷、风播基本上是依靠到Web服务器上搜索资源文件或检索资源文件,在BT和风播中,打开种子文件即可下载。而迅雷是保存了FTP或HTTP的原始链接,打开链接以后启动下载功能。
4.坏人算法与好人算法
有朋友问,为什么我用电骡下载某个文件即使源很多,下载速度也特别慢呢?这就要从P2P分享率谈起,分享率是P2P世界的一个非常重要的指标,分享率指上传和下载的比值。
不同的P2P技术对于解决分享率有不同的处理方式。大致可以分为两种:坏人算法和好人算法。所谓坏人算法和好人算法其实是一种假设,坏人算法假定所有的客户端都是自私的,但是为了大家都来贡献自己的力量,制定了一个规则:如果不共享,就要遭受一定的惩罚;好人算法默认每个客户端都会按照自己能力尽量上传。
在电骡的网络中,采用了一种信用机制,当你上传流量很多的时候,你就获得比较高的信用值,从其他人那里获取流量的可能性就加大。每个电骡会维护一个服务队列,当我向别人请求数据时候,别人会根据我的信用等级进行排队,信用等级越低,排队越靠后。因此,老电骡们由于上传多,积分也高,下载速度就比较快;而新手由于上传少,积分低,下载速度也相对比较慢。
BT采用的是坏人算法,客户端定时会计算对方是否给自己流量,如果对方不给我流量,我会将对方阻塞掉。这样迫使对方必须提供一定的上传带宽。
迅雷采用的主要还是好人算法,每个客户端不可以控制自己不向别人贡献流量。风播采用好人算法和坏人算法相结合的方式。
5.调度算法
调度算法是所有P2P技术的核心,不同的厂商有不同的实现方式,一般都是技术机密。对于BT、电骡、迅雷来说,一般采用乱序下载算法,这是迅速利用客户端上传带宽比较有效的方式。风播为了实行在线播放,调度算法完全不同于其他P2P软件,是一种顺序和乱序的结合算法。
假设做种的Seed 有1、2、3、4、5 五个分片,如果按照传统的HTTP或FTP下载方式,Peer1和Peer2 向Seed 都从文件头部的分片1开始请求,那么极端的后果就是P2P无法实行,因为Peer1和Peer2还是把压力加在Seed上(原理如图2所示)。
但是如果采用乱序下载就不一样了,Peer1 从Seed获取分片1,Peer2从Seed获取分片2,它们相互就可以从对方获取自己没有的数据,P2P 方式就很容易发挥作用(原理如图3所示)。
对于P2P下载,乱序方式解决得很好。但是对于流媒体,必须要求文件分片是顺序获取,风播采用了一种乱序和顺序相结合的方式来解决该问题,也就是整个文件的获取方式,基本上是顺序方式获取,但是具体每个分片,又采用乱序方式获取,这样就取得了下载速度和顺序观看影片的平衡。
参考资料:http://hi.baidu.com/haiaiwoba/blog/item/9c895960741f1fdf8cb10d0b.html
参考技术A P2P是peer-to-peer的缩写,peer在英语里有“(地位、能力等)同等者”、“同事”和“伙伴”等意义。这样一来,P2P也就可以理解为“伙伴对伙伴”的意思,或称为对等联网。目前人们认为其在加强网络上人的交流、文件交换、分布计算等方面大有前途。简单的说,P2P直接将人们联系起来,让人们通过互联网直接交互。P2P使得网络上的沟通变得容易、更直接共享和交互,真正地消除中间商。P2P就是人可以直接连接到其他用户的计算机、交换文件,而不是像过去那样连接到服务器去浏览与下载。P2P另一个重要特点是改变互联网现在的以大网站为中心的状态、重返“非中心化”,并把权力交还给用户。 P2P看起来似乎很新,但是正如B2C、B2B是将现实世界中很平常的东西移植到互联网上一样,P2P并不是什么新东西。在现实生活中我们每天都按照P2P模式面对面地或者通过电话交流和沟通。 参考技术B 点对点
360什么叫做覆盖索引?
什么叫做覆盖索引?
在了解覆盖索引之前我们先大概了解一下什么是聚集索引(主键索引)和辅助索引(二级索引)
聚集索引(主键索引):
聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的即为整张表的记录数据。
聚集索引的叶子节点称为数据页,聚集索引的这个特性决定了索引组织表中的数据也是索引的一部分。
辅助索引(二级索引):
非主键索引,叶子节点=键值+书签。Innodb存储引擎的书签就是相应行数据的主键索引值。
再来看看什么是覆盖索引,有下面三种理解:
- 解释一: 就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
- 解释二: 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫 做覆盖索引。
- 解释三:是非聚集组合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建立索引的字段正好是覆盖查询语句[select子句]与查询条件[Where子句]中所涉及的字段,也即,索引包含了查询正在查找的所有数据)。
不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引的列,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引
当发起一个被索引覆盖的查询(也叫作索引覆盖查询)时,在EXPLAIN的Extra列可以看到“Using index”的信息

从执行结果上看,这个SQL语句只通过索引,就取到了所需要的数据,这个过程就叫做索引覆盖。
几种优化场景:
1.无WHERE条件的查询优化:
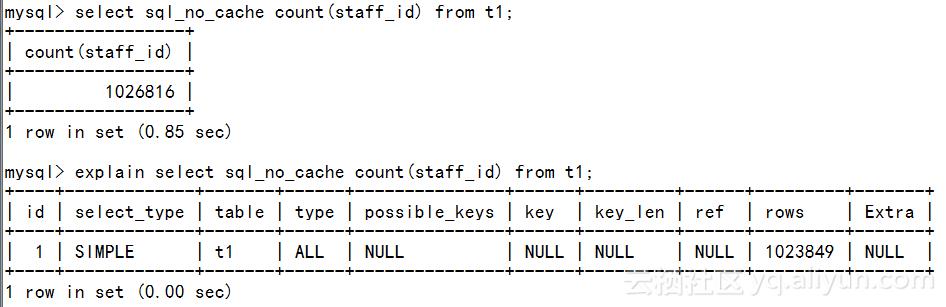
执行计划中,type 为ALL,表示进行了全表扫描
如何改进?优化措施很简单,就是对这个查询列建立索引。如下,
ALERT TABLE t1 ADD KEY(staff_id);
- 再看一下执行计划

explain select sql_no_cache count(staff_id) from t1
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: index
possible_keys: NULL
key: staff_id
key_len: 1
ref: NULL
rows: 1023849
Extra: Using index
1 row in set (0.00 sec)

possible_key: NULL,说明没有WHERE条件时查询优化器无法通过索引检索数据,这里使用了索引的另外一个优点,即从索引中获取数据,减少了读取的数据块的数量。 无where条件的查询,可以通过索引来实现索引覆盖查询,但前提条件是,查询返回的字段数足够少,更不用说select *之类的了。毕竟,建立key length过长的索引,始终不是一件好事情。
- 查询消耗

从时间上看,小了0.13 sec
2、二次检索优化
如下这个查询:

select sql_no_cache rental_date from t1 where inventory_id<80000; … … | 2005-08-23 15:08:00 | | 2005-08-23 15:09:17 | | 2005-08-23 15:10:42 | | 2005-08-23 15:15:02 | | 2005-08-23 15:15:19 | | 2005-08-23 15:16:32 | +---------------------+ 79999 rows in set (0.13 sec)

执行计划:

explain select sql_no_cache rental_date from t1 where inventory_id<80000*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: range
possible_keys: inventory_id
key: inventory_id
key_len: 3
ref: NULL
rows: 153734
Extra: Using index condition
1 row in set (0.00 sec)

Extra:Using index condition 表示使用的索引方式为二级检索,即79999个书签值被用来进行回表查询。可想而知,还是会有一定的性能消耗的
尝试针对这个SQL建立联合索引,如下:
alter table t1 add key(inventory_id,rental_date);
执行计划:

explain select sql_no_cache rental_date from t1 where inventory_id<80000*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: range
possible_keys: inventory_id,inventory_id_2
key: inventory_id_2
key_len: 3
ref: NULL
rows: 162884
Extra: Using index
1 row in set (0.00 sec)

Extra:Using index 表示没有会标查询的过程,实现了索引覆盖
3、分页查询优化
如下这个查询场景

select tid,return_date from t1 order by inventory_id limit 50000,10; +-------+---------------------+ | tid | return_date | +-------+---------------------+ | 50001 | 2005-06-17 23:04:36 | | 50002 | 2005-06-23 03:16:12 | | 50003 | 2005-06-20 22:41:03 | | 50004 | 2005-06-23 04:39:28 | | 50005 | 2005-06-24 04:41:20 | | 50006 | 2005-06-22 22:54:10 | | 50007 | 2005-06-18 07:21:51 | | 50008 | 2005-06-25 21:51:16 | | 50009 | 2005-06-21 03:44:32 | | 50010 | 2005-06-19 00:00:34 | +-------+---------------------+ 10 rows in set (0.75 sec)

在未优化之前,我们看到它的执行计划是如此的糟糕
explain select tid,return_date from t1 order by inventory_id limit 50000,10*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1023675
1 row in set (0.00 sec)

看出是全表扫描。加上而外的排序,性能消耗是不低的
如何通过覆盖索引优化呢?
我们创建一个索引,包含排序列以及返回列,由于tid是主键字段,因此,下面的复合索引就包含了tid的字段值
alter table t1 add index liu(inventory_id,return_date);
那么,效果如何呢?

select tid,return_date from t1 order by inventory_id limit 50000,10; +-------+---------------------+ | tid | return_date | +-------+---------------------+ | 50001 | 2005-06-17 23:04:36 | | 50002 | 2005-06-23 03:16:12 | | 50003 | 2005-06-20 22:41:03 | | 50004 | 2005-06-23 04:39:28 | | 50005 | 2005-06-24 04:41:20 | | 50006 | 2005-06-22 22:54:10 | | 50007 | 2005-06-18 07:21:51 | | 50008 | 2005-06-25 21:51:16 | | 50009 | 2005-06-21 03:44:32 | | 50010 | 2005-06-19 00:00:34 | +-------+---------------------+ 10 rows in set (0.03 sec)

可以发现,添加复合索引后,速度提升0.7s!
我们看一下改进后的执行计划
explain select tid,return_date from t1 order by inventory_id limit 50000,10\\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
type: index
possible_keys: NULL
key: liu
key_len: 9
ref: NULL
rows: 50010
Extra: Using index
1 row in set (0.00 sec)
执行计划也可以看到,使用到了复合索引,并且不需要回表
对比一下如下的改写SQL,思想是通过索引消除排序
select a.tid,a.return_date from t1 a inner join (select tid from t1 order by inventory_id limit 800000,10) b on a.tid=b.tid;
并在此基础上,我们为inventory_id列创建索引,并删除之前的覆盖索引
alter table t1 add index idx_inid(inventory_id); drop index liu;
然后收集统计信息。

select a.tid,a.return_date from t1 a inner join (select tid from t1 order by inventory_id limit 800000,10) b on a.tid=b.tid; +--------+---------------------+ | tid | return_date | +--------+---------------------+ | 800001 | 2005-08-24 13:09:34 | | 800002 | 2005-08-27 11:41:03 | | 800003 | 2005-08-22 18:10:22 | | 800004 | 2005-08-22 16:47:23 | | 800005 | 2005-08-26 20:32:02 | | 800006 | 2005-08-21 14:55:42 | | 800007 | 2005-08-28 14:45:55 | | 800008 | 2005-08-29 12:37:32 | | 800009 | 2005-08-24 10:38:06 | | 800010 | 2005-08-23 12:10:57 | +--------+---------------------+

这种优化手段较前者时间多消耗了大约140ms。这种优化手段虽然使用索引消除了排序,但是还是要通过主键值回表查询。因此,在select返回列较少或列宽较小的时候,我们可以通过建立复合索引的方式优化分页查询,效果更佳,因为它不需要回表!
4、建了索引但是查询不走索引
表结构:

CREATE TABLE `t_order` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `order_code` char(12) NOT NULL, `order_amount` decimal(12,2) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uni_order_code` (`order_code`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;

查询语句:
select order_code,order_amount from t_order order by order_code limit 1000;
发现虽然在order_code上建了索引,但是看查询计划却不走索引,为什么呢?因为数据行读取order_amount,所以是随机IO。那怎么办?重新建索引,使用覆盖索引。
ALTER TABLE `t_order` ADD INDEX `idx_ordercode_orderamount` USING BTREE (`order_code` ASC, `order_amount` ASC);
这样再查看SQL的执行计划,就发现可以走到索引了。
总结:覆盖索引的优化及限制
覆盖索引是一种非常强大的工具,能大大提高查询性能,只需要读取索引而不需要读取数据,有以下优点:
1、索引项通常比记录要小,所以MySQL访问更少的数据。
2、索引都按值得大小存储,相对于随机访问记录,需要更少的I/O。
3、数据引擎能更好的缓存索引,比如MyISAM只缓存索引。
4、覆盖索引对InnoDB尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引包含查询所需的数据,就不再需要在聚集索引中查找了。
限制:
1、覆盖索引也并不适用于任意的索引类型,索引必须存储列的值。
2、Hash和full-text索引不存储值,因此MySQL只能使用BTree。
3、不同的存储引擎实现覆盖索引都是不同的,并不是所有的存储引擎都支持覆盖索引。
4、如果要使用覆盖索引,一定要注意SELECT列表值取出需要的列,不可以SELECT * ,因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降。
参考文献:
【1】 袋鼠云技术团队博客,文章-阿里云开发者社区-云计算社区-阿里云
【2】MySQL覆盖索引优化,文章-阿里云开发者社区-云计算社区-阿里云
【3】MySQL SQL优化之索引覆盖
【4】 Baron Schwartz等 著,宁海元等 译 ;《高性能MySQL》(第3版); 电子工业出版社 ,2013
以上是关于什么叫做P2P的主要内容,如果未能解决你的问题,请参考以下文章
区块链实战什么是 P2P 网络,区块链和 P2P 网络有什么关系
区块链实战什么是 P2P 网络,区块链和 P2P 网络有什么关系