NPU芯片技术与市场发展杂谈
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NPU芯片技术与市场发展杂谈相关的知识,希望对你有一定的参考价值。
NPU芯片技术与市场发展杂谈
推出新一代NPU!安谋科技应战AI新时代,要催化本土芯片创新
2023年,万象更新,AI芯片产业亦恢复生机。在生成式人工智能(AIGC)热潮的催化下,澎湃旺盛的研发和应用需求,令算力产业空前兴奋,连带着AI芯片产业也铆足干劲,蓄势待发。作为构筑AI芯片大厦的“砖瓦”,神经网络处理器(NPU)的设计会影响AI推理的性能、能效、灵活性、易扩展性、安全性。智能计算的多元化场景,正在改变新一代NPU的设计理念。冲在前线的安谋科技,刚刚交出新的答卷。国内头部芯片IP设计与服务供应商安谋科技推出其自研人工智能(AI)产品线的最新AI处理器产品——“周易”X2 NPU,将支持的算力提至最高320TOPS,针对车载、电脑、手机等特定场景做了性能优化,并正式发布NPU软件开源计划。

▲安谋科技“周易”NPU路线图
AI应用热潮日渐高涨,正值国际形势日益复杂,这些推力共同将国产AI芯片领入难得的历史机遇期。从降低设计成本、缩短开发周期、加速产品走向规模化落地等角度考虑,企业基于NPU研发加速AI计算的芯片需求预计将旺盛生长。在愈发热闹的AI算力军备竞赛中,安谋科技的打法是一边通过本土研发创新抬高NPU的技术壁垒,另一边借助开源力量携手更多伙伴共建更好用的软件工具,以更开阔的视野来做大本土NPU生态。安谋科技执行副总裁、产品研发负责人刘澍透露,除前述软件开源外,安谋科技后续还将逐步开放更多资源。合作伙伴在软件层面加入“周易”软件开源计划,硬件层面则兼容“周易”架构,以便企业基于“周易”架构开发全新NPU产品。这将催生更广泛的芯片设计创新。目前,“周易”X2 NPU已面向客户正式交付,今年会有多款搭载该NPU的芯片产品面世。
01.ChatGPT带飞异构计算如何影响终端NPU算力扩展?
发展通用人工智能是计算机行业一直以来的伟大梦想,而大模型与生成式AI取得的突破性进展,正以日新月异的速度缩短现实与想象之间的距离,也正重新制定AI芯片的规则。“在应用层面,ChatGPT把数据处理的热度推向一个高峰。”安谋科技执行副总裁、产品研发负责人刘澍说,ChatGPT的背后结合了知识图谱、数据库、数据收集和分析等一整套技术体系,开创了很多NPU在不同行业应用的窗口和前景,并带动NPU、CPU、GPU等多种异构算力的结合。动辄参数规模上亿的AI模型大多训练和运行于云上。科研人员正在探索如何将它们放到性价比更高的终端硬件上。最近十几天,国内外研究人员已经成功实现用单张消费级显卡、苹果M1/M2芯片跑大型语言模型,展现了在性价比更高的终端硬件上运行认知智能的可能性。近年来,智能汽车、AIoT等产业智能化进程提速。一方面,智能汽车、边缘计算、智能家居、移动设备等对AI处理图像分辨率的要求越来越高;另一方面,AI正与各行各业的典型应用场景相融合,并逐步向传统To B端产业渗透。相比将所有计算放在云上,终端NPU处理能够降低数据传输造成的延时,节省大量开销。特别是对于视觉、语音等人机交互以及自动驾驶等对实时处理要求严苛的应用场景,终端NPU的发展是必然且必须的。据刘澍观察,为了适应下游AI算法的发展,未来终端算力可能有两个发展路径:一是终端算力越来越强,终端算力的持续扩展是未来趋势,但会受限于成本和功耗;二是不断为终端裁剪网络,这是安谋科技长期在做的尝试,通过量化剪裁等措施将模型变得更小。两者相互并进,通过将云端的算法模型优化到位,实现其在拥有更高算力的终端的部署。沿着这些思路,安谋科技打造了能够兼顾多元化算力需求的新一代AI处理器“周易”X2 NPU。
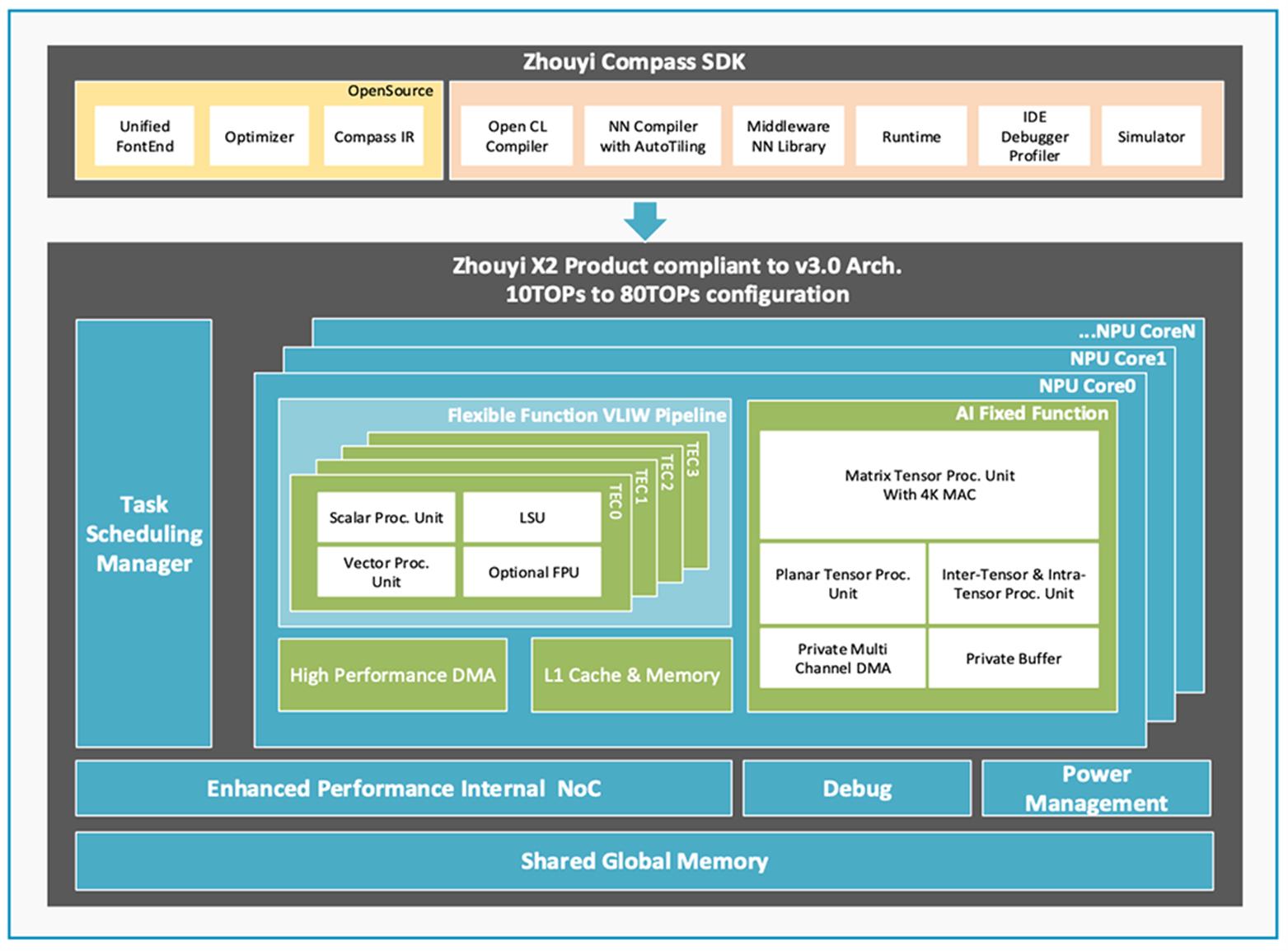
▲“周易”X2 NPU概览
02.“周易”X2 NPU升级:更高算力、更多精度,支持差异化定制
“周易”X2 NPU基于第三代“周易”架构,支持多核Cluster,子系统最高算力可达320TOPS。
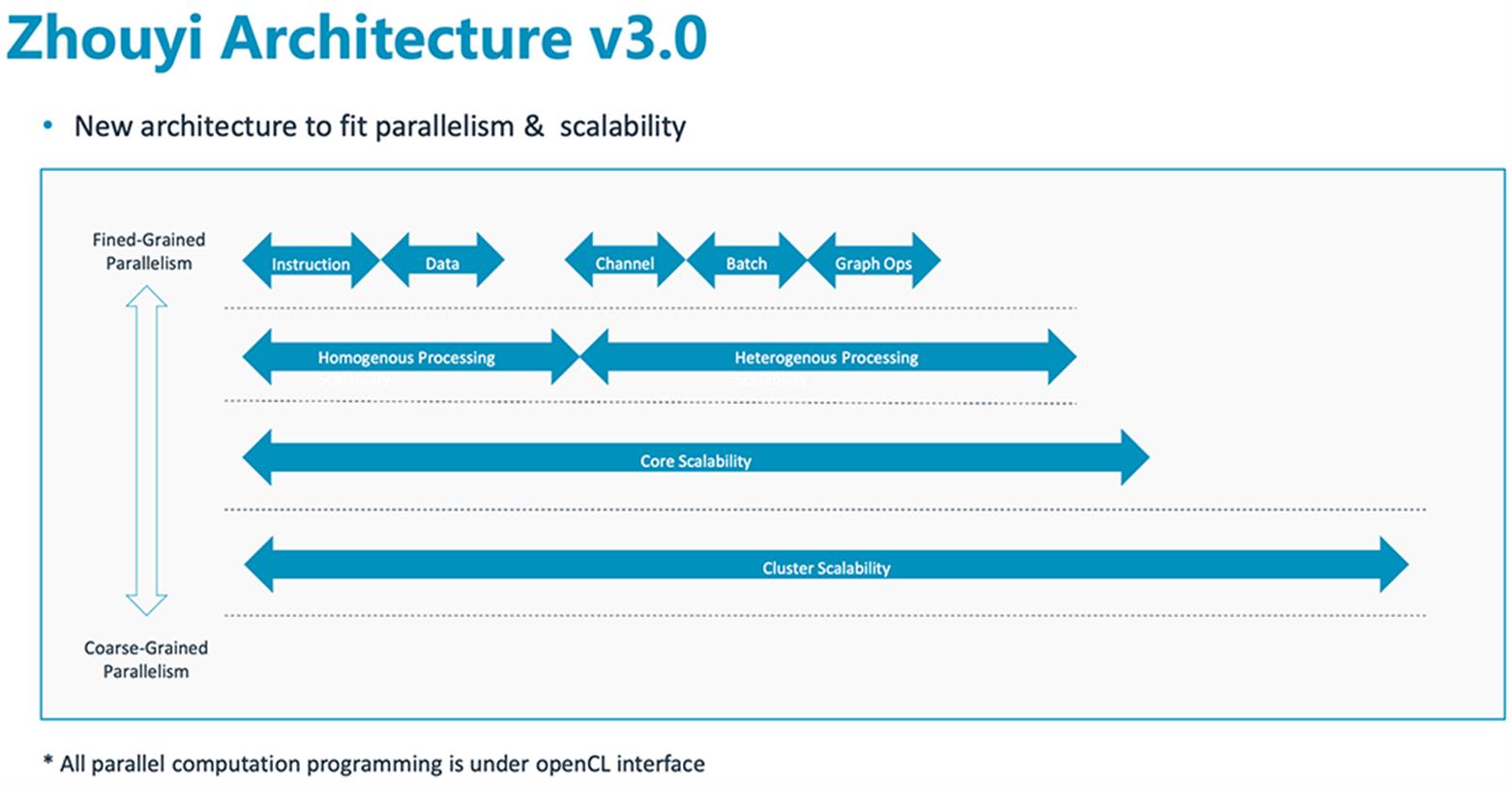
▲第三代“周易”架构的可扩展性
在精度方面,该NPU支持更多的浮点格式以及int4/int8/int12/int16/int32、fp16/bf16/fp32多精度融合计算,将计算效率与密度显著提升,从而更好支持通用算法。在灵活性方面,“周易”X2 NPU在支持自定义算子、满足各种模型部署需求的基础上,还面向各类应用场景提供定制化AI解决方案,以进一步满足客户在智能驾驶、手机影像AI处理、人机交互等场景中的差异化需求。
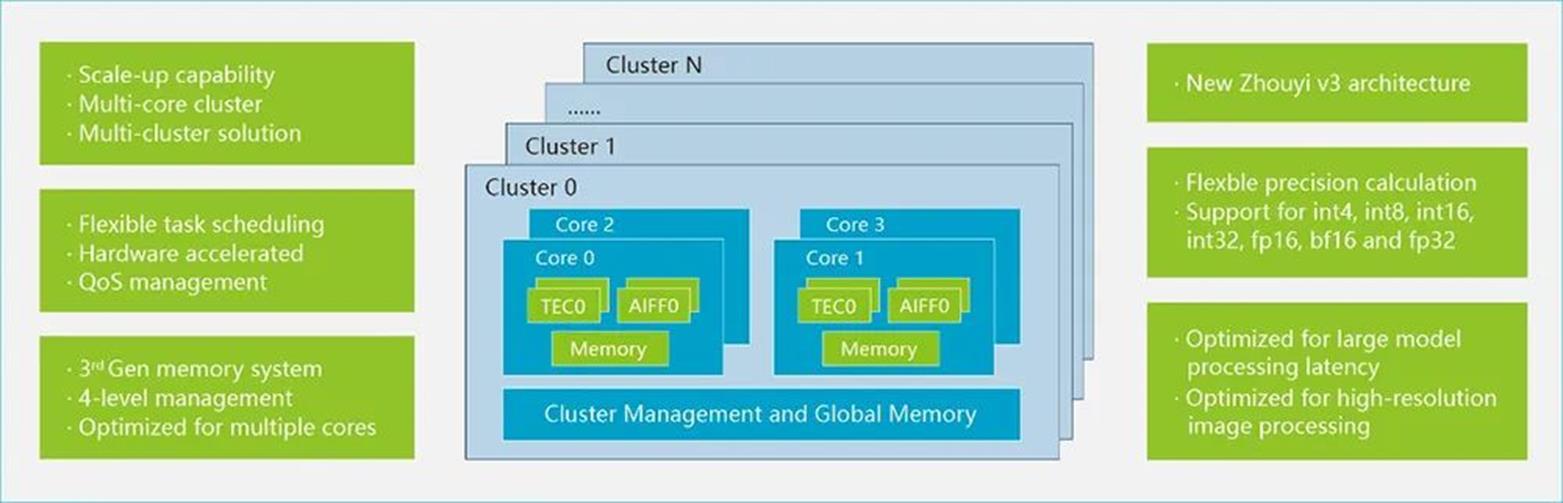
▲“周易”X2 NPU主要功能升级
“周易”X2 NPU针对高级驾驶辅助系统(ADAS)、智能座舱、平板电脑、台式机、手机等应用场景做了大量的性能优化,可大幅提升手机拍照、录像中的高分辨率图像处理能力,以及车载中常用的Transformer等应用的性能,同时采用i-Tiling技术大幅减少带宽需求,进一步提升计算效率。

▲相比其他汽车SoC和“周易” X1 SoC,在“周易” X2 SoC上跑Swin-Transformer模型的性能显著提升
刘澍强调说,整个“周易”NPU体系,包括指令集架构设计,全部由安谋科技本土研发团队完成。在面对国内客户对于NPU产品以及AI相关需求时,本土团队可以更及时、深入地捕捉和理解客户需求,响应速度也更快。
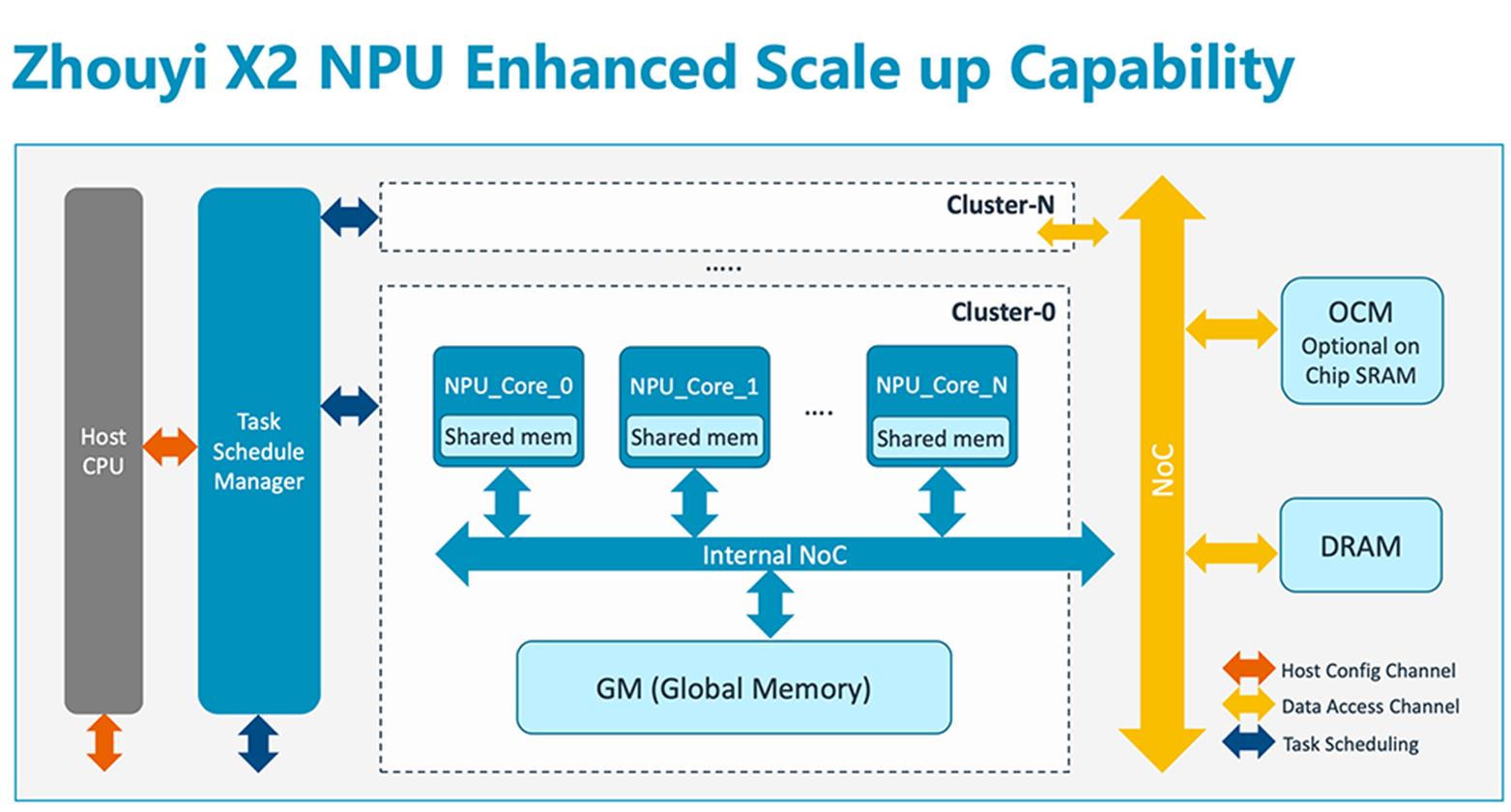
▲“周易”X2 NPU增强了可扩展能力
做NPU研发,拼的是长期投入。作为一家独立运营、中资控股的合资公司,安谋科技从2018年创立起就一直立足于本土创新,坚持开展自研IP和发展Arm IP业务并重的路线,至今已有超过370家国内授权客户,累计芯片出货量突破300亿片。刘澍谈道,此前芯片业的相互合作沟通相对欠缺,在未来前景战略的想法上各自为战,而芯片IP公司能够将从应用层、软件层到芯片层的整个产业链的需求与发展思路进行对齐统一,通过打造通用的硬件及软件工具,满足更广泛的市场需求。一家芯片IP公司的基因就好比一个产业各方所共享的研发中心,安谋科技的核心任务是为半导体产业提供一整套可共用的异构计算平台,基于自己所擅长的能力定位来做更多业务上的探索与创新。同时,安谋科技也起到与国际接轨的桥梁作用,可将一些在国际上已被验证过的或者正在发生的新技术趋势带到中国。从自研产品线来看,安谋科技正不断完善自研矩阵版图,同步推进CPU、NPU、ISP、VPU、SPU等各类IP产品线的研发。此前其自研产品已向160家本土客户授权,基于安谋科技自研IP的芯片出货量超过2亿颗。据刘澍透露,随着自研IP矩阵的日渐丰富,近两年,安谋科技愈发注重各类自研IP之间的协同,希望将所有视觉和多媒体相关IP聚拢。其具体优化可分为三个层面:其一,考虑不同类型IP之间的数据格式、吞吐量、处理能力等相匹配。其二,优化这些IP所支持的格式对DDR带宽的要求,在有些特定场景或大规模场景下尽量减少甚至可以不用进行对总线和DDR来回导数据的访问,从而将系统压力降到极低,更加节省功耗。其三,面向特定应用场景实现不同类型IP之间的相互协同与创新,比如通过NPU帮助ISP去噪,对识别场景进行快速对焦和寻找一些热点区域等。“我们在解决完了从0到1,就开始去考虑1+1能不能大于2,”刘澍说,“这是一个不断尝试的过程,我们还没有做到非常完善,但一些协同效应正在一步步被实现。”
03.软件才是杀手锏
“越来越多的人认识到单靠NPU硬件并不能反映巨大价值,很多公司都有机会、有能力做类似的产品,但NPU硬件上承载的软件和生态才是非常重要的价值体现。”刘澍说。为了帮助开发者方便快速地进行算法移植和性能调优,“周易”X2 NPU还提供了一套完善的AI软件平台。
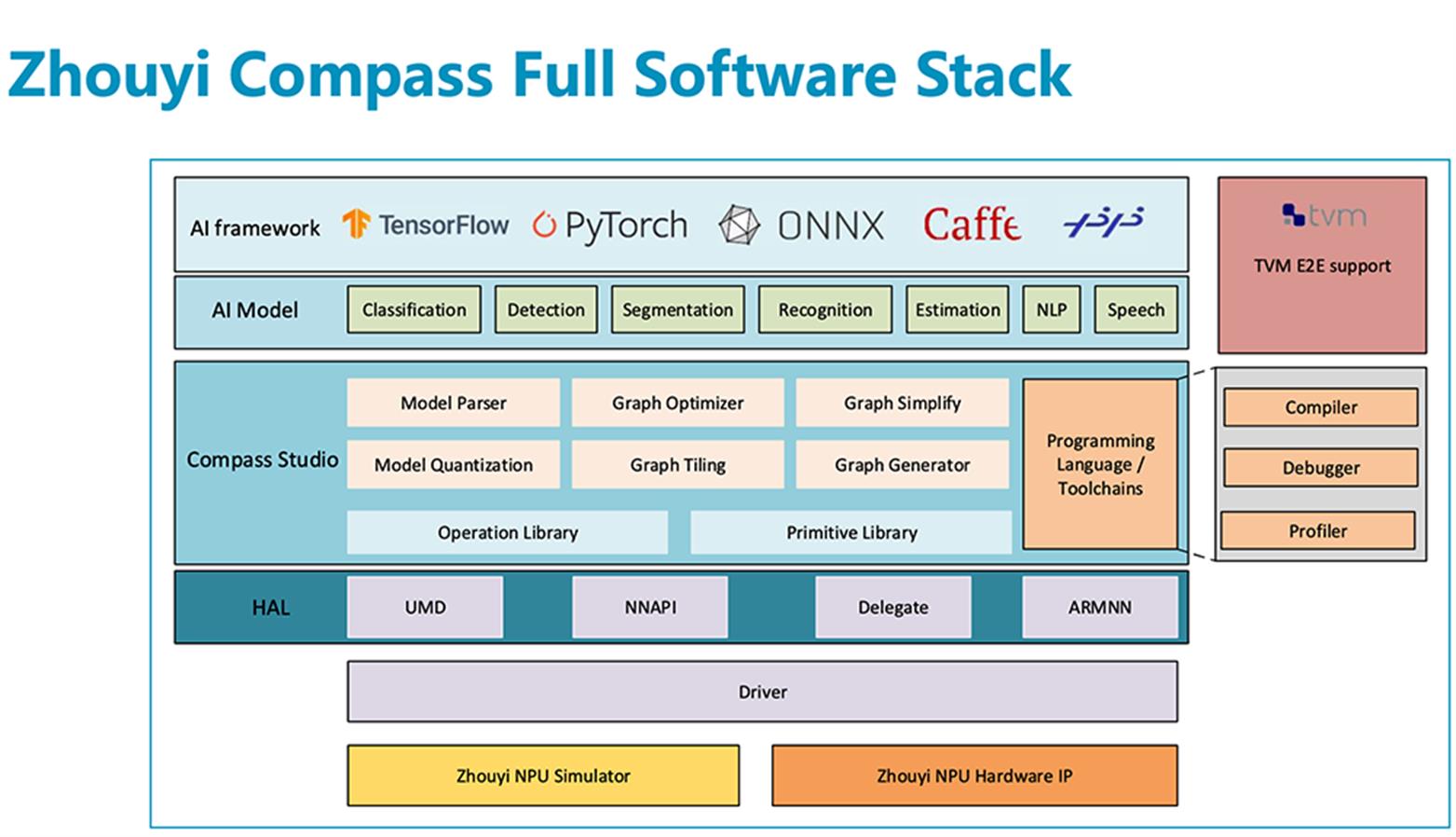
▲“周易”NPU软件栈
这个软件平台支持TensorFlow、Caffe、ONNX、 PyTorch等主流AI框架,Android、Linux、RTOS、QNX等不同操作系统,以及TVM、Arm NN的SoC异构计算,并拥有丰富的开放接口、调试工具和Bit精度的软件仿真平台。此外,安谋科技今日发布了NPU软件开源计划,通过开放源码,来满足客户更自主、更灵活的算法移植需求,和更多开发者及合作伙伴共建国内NPU产业生态。
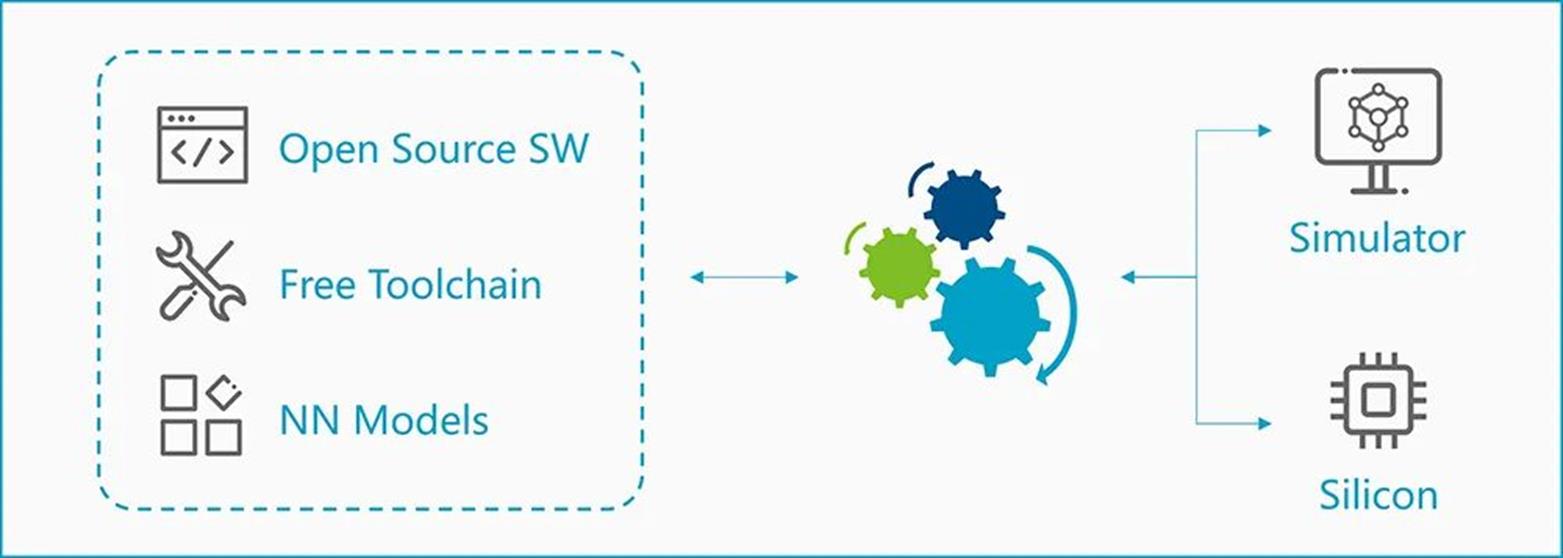
▲“周易”NPU软件部署
在该开源计划下,安谋科技率先对外开放NPU中间表示层规范、模型解析器、模型优化器、驱动等,并向相关合作伙伴提供“周易” Compass软件平台,包括软件模拟器、调试器、C编译器等在内的多种软件工具。

▲“周易”NPU开源计划
据了解,安谋科技已分别在代码托管平台Gitee、GitHub上建立该项目的开源库。上述只是“周易”NPU软件开源计划的第一步,安谋科技后续还将逐步开放更多资源,如模型优化器、模型量化、算子实现等源代码。对于软件工具而言,“能用”与“用好”是不同层次的事。刘澍认为,通过将软件开源及硬件架构免费开放,开发者无需在不同的硬件平台上进行开发,从而避免重复造轮,进一步提升软件开发效率,让生态快速发展。从成本角度考量,如果要完整做出一个比较好用的NPU,一家公司至少要投入两三百人,涉及到硬件、芯片、软件、上层应用等方方面面;但如果采用第三方NPU IP,可能只需投入100多人,用以应用层、中间层等开发。从生态角度考量,如果上游芯片公司们各推一套自己的NPU生态,那么应用厂商可能会无所适从。而共建生态是合作共赢,在一个可复用的生态平台上开枝散叶,并有望激起更多以前不曾想过的场景创新。据他透露,安谋科技将软件和工具链开源后,企业开发者可借此快速开发出自己的产品,或者是用这些工具结合对自家应用的深刻理解,从软硬件结合的角度对底层IP性能做优化。未来,安谋科技还计划开放更多资源,使得芯片设计公司能够用“周易”架构去快速开发出自己的NPU产品,并推向市场。截至目前,“周易”NPU软件开源计划已有第一批合作伙伴“入驻”,其中不乏来自AIoT、智能汽车、智能操作系统等领域的明星企业。这些合作伙伴均表示将基于该计划与安谋科技继续深化合作,加速构建中国智能计算生态“朋友圈”。除了NPU软件开源计划外,安谋科技还基于2022年7月发起的生态伙伴计划,通过战略合作、产品技术支持、项目协作、联合营销等形式,与合作伙伴共建上下游产业生态,共同推动各领域软硬件、工具链、行业标准以及社区联盟等生态环节的发展。

▲安谋科技生态伙伴计划
04.结语:本土创新+生态构建,撬动芯片设计“大局”
生成式AI的火爆出圈,正激发新一轮AI研发与商用热潮。各类硬件终端智能化渗透率不断提升,对作为底层算力基础设施“大脑”的AI芯片提出了更高的要求。快速迭代的AI算法、日趋广泛的应用场景,既离不开高性能NPU来提供更强算力支撑,也离不开易用的软件平台来加快芯片产品的部署和落地流程。可以看到,一直走在国内芯片IP赛道前排的安谋科技,正采用迭代更强NPU产品和开放软件源码的并行策略,拉更多开发者及合作伙伴一起,共同加快NPU生态建设脚步。在立足全球生态、聚焦本土需求、深耕本土创新的基础上,安谋科技逐渐发展成产业链上下游的“黏合剂”,为提高芯片设计创新的效率、降低生产成本、优化资源配置提供重要支撑,通过推动NPU技术创新和产业发展,为芯片公司打通走向市场的必要通路,进而助益中国智能计算生态的创新与繁荣。
ADS-NPU芯片计算架构的产品痛点和设计挑战
对比CPU几十级的并行处理单元和GPU上万级的并行处理单元,NPU会有百万级以上的并行计算单元,大算力与低功耗的优势非常明显。当前市场上主流AI大算力SoC芯片,常用的NPU计算架构可以简单总结成以下几种形态:
1) GEMM加速架构 (TensorCore from nVidia, Matrix Core from AMD)2) Systolic Array (Google TPU)3) CGRA (初创公司)4) Dataflow (Wave, Graphcore,初创公司)5) Spatial Dataflow (Samba Nova, Groq)6) Sparse架构 (Inferentia)7) PIM内存计算架构(初创公司)

图1 nVidia A100的TensorCore架构与UPCYCLE 融合架构的计算效率对比(Davies 2021)

图 2 nVidia AI加速芯片 H100与A100性能对比
如图 1所示案例可以看出, 下一代NPU芯片架构设计中一个最主要的挑战是低计算效率问题,除了内存墙、功耗墙原因之外,还有一个最主要原因是ADS算法从Compute-bound(Convolution)向Memory-bound(Matrix Multiply + Data Move)演进,而现有架构多只针对3x3卷积进行优化,现有硬件计算架构难以全方位优化覆盖。对应于ADS传感器负载多样化和融合感知决策算法多样化的演进趋势,ADS的算力需求和芯片加速能力以(十倍速/每几年)的持续高增长态势呈现。对ADS新的存算混合需求,业界有几种主要应对措施:
• 以Tesla FSD芯片为主:
o 以新工艺和增加海量MAC阵列数量和SRAM容量来提供高达400TOPS的算力
• 以nVidia为主:
o 如图 2所示,通过适量增加计算单元,添加新的张量核心和新的Transformer引擎来解决Memory-bound类算法的低效率问题
• 以初创和手机芯片公司为主:
o 在近内存或者内存计算基础上,采用融合架构,将高速数据接口+数据压缩+模型压缩+低精度逼近计算+稀疏计算加速相结合 o 结合模型-硬件联合设计,通过添加硬设计可配置+硬件调度+软运行可编程调度引擎来提升架构的整体算法计算效率
典型的CNN(Compute-bound)和Transformer(Memory-bound)的网络架构详细对比如图 3和图 4所示,以Swin Transformer做图像分类的案例,可以看到其中Matrix Multiply占70%计算时间,由于数据复用远低于CNN中最常见的卷积(占CNN任务推理总耗时多数在90%-95%以上)计算,Data Move也需要~29%的耗时。对NPU 硬件计算架构而言, CNN主要的计算算子包括:卷积,池化,激活函数(ReLU等), Batch Normalization,以及全连接Fully-Connected(FC),主要计算是卷积算子,计算耗时占比可以到95%左右或更高,CNN中卷积的复用率要比Transformer高15倍左右。Transformer主要的计算算子包括:卷积Conv1x1 (即FC),Multi-Head Self-Attention(MSA),激活函数(GeLU等), 和Layer Normalization,其中Multi-Layer Perception (MLP)层由FC+GeLU+FC组合而成,Transformer主要计算是FC算子,计算占比可以到90%以上,所用滤波器的数量比CNN的卷积层多6倍左右。应用到ADS的Transformer的不同类别,包括ViT,Swin等众多系列,架构上主要区别是Self-Attention架构的变化,以及Channel数量和CONV尺寸的不同。ADS中众多手工设计的算法架构可以将CNN、Transformer、GNN和RNN等DNN网络的部分子模块重新组合来进行有效的特征提取特征融合和特征重建,同时结合贝叶斯统计和强化学习RL等理论以满足ADS多模感知与融合推理决策需求,所以DNN网络形态目前还没有走向统一,仍呈现多样化态势,模型-硬件的联合设计以及网络架构自动搜索NAS设计方法会加剧这种趋势的发散,这些都是下一代NPU计算先进架构设计所面临的全新挑战。
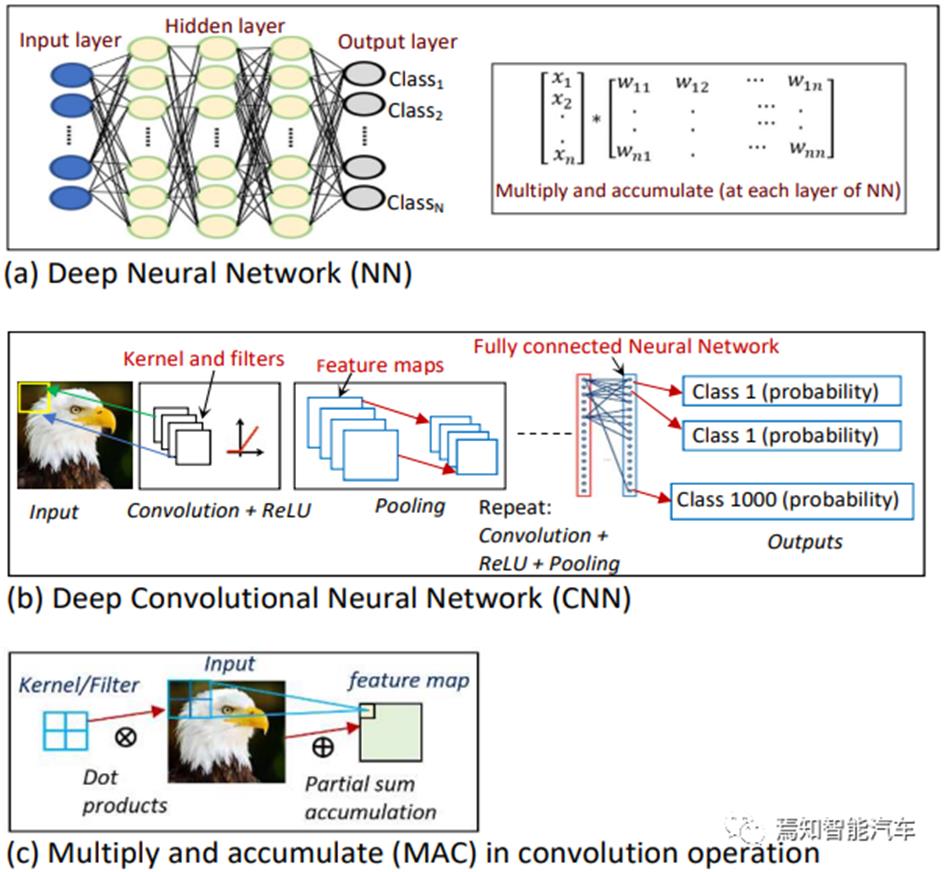
图 3 典型CNN网络结构、算法模块与常用算子 (Said, 2020)

图 4 Swin Transformer模块和图像分类任务的推理时间占比案例 (Hu, 2021)
ADS-NPU计算架构的痛点与挑战
当前NPU计算架构主要是Spatial加速器架构,即Spatial PE空间单元阵列通过NoC,数据总线,或跨PE的互联来实现数据流交互。粗颗粒度的可配置架构CGRA是Spatial加速器的一种形态,即可配置的PE Array通过纳秒或微秒级别可配置的Interconnect来对接,可以支持配置驱动或者数据流驱动运行。脉动Systolic加速器架构也是Spatial加速器的一类实现方式,其主要计算是通过1D或2D计算单元对数据流进行定向固定流动处理最终输出累加计算结果。当前脉动阵列依旧是主流架构之一,常用的单元尺寸为32x32,可以通过添加额外的逻辑单元来支撑压缩模型与压缩数据的稀疏计算加速处理以及低比特的逼近计算模式。
从上所述,NPU计算架构的性能(throughput/Watt, throughput/area)取决于针对DNN网络模型负载与计算阵列的颗粒度匹配度,能否支持动态配置,以及互联interconnect拓扑与模型如何切片tiling相关,目的是确保计算单元的使用效率与数据通道的调度效率。颗粒度可配置是一个选择,同时可以将阵列Array+矢量Vector+标量Scalar计算单元组合来构成异构单元和弹性扩展。另外一个可行的思路是采用不同配置尺寸的脉动阵列multi-Pod混合,来解决不同DNN的负载需求(CONV, FC, Attention)中DNN网络层与阵列维度不匹配问题, 提升并行计算效率。PE计算阵列或者NPU核的互联,包括直连与分布式,需要解决计算单元与片上片间内存的通道竞争与延迟问题。比较有趣的是脉动阵列的multi-Pod组合中,CNN比较适合66x32阵列尺寸,Transformer比较适合20x128尺寸,总体上比32x32尺寸性能会有1.5x以上提升。互联的设计方案中,Crossbar interconnect可以有比较好的二分带宽,但随着挂靠的计算core数量增加,硬件成本成加速度上升趋势,对比而言H-tree interconnect硬件成本也非常高。2D Mesh interconnect比较常用,硬件成本低但难以支撑大的使用模块或者计算core数量。对比Ring interconnect而言,Butterfly interconnect可以做一个比较好的均衡,这里Network-on-Chip (NOC)还会有其它设计选择,本文在这里不打算做深度分析。
ADS-NPU微计算架构的设计挑战
ADS算法的典型系统分层架构一般包括传感层,感知层,定位层,决策层和控制层。DNN在这类认知任务和视觉任务上取得了巨大的进展。DNN网络主要包括CNN、Transformer、GAN、GNN和RNN等几类。本文在这里主要讨论一下CNN卷积核和Transformer完整核心功能模块的硬件设计挑战与加速实现。
Multiply-and-Accumulation (MAC)设计
DNN的最核心最底层的计算操作是MAC,即网络参数与量化输入的点积Dot-Product运算,以及累加输出,所以减少点积(即内积)或者累加器数量,可以提升数据复用率,自然可以有效提升能耗比,图 5就是这样一个典型的基于加法树的内积引擎案例。这类实现在脉动阵列架构上是基本可行的。
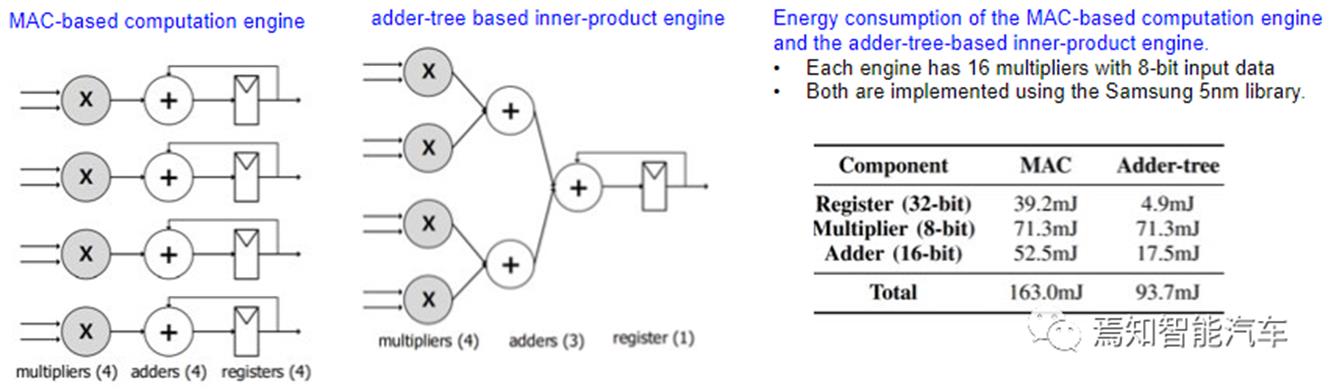
图 5 基于加法树的内积引擎案例 (Jang 2021)
全连接FC设计
如图 6所示,偏Memory-bound的FC层常用在RNN和Max Probability Perception MLP (Transformer)模型系列里,数据搬移多,滤波器参数在不同神经元的复用率低于CNN中的卷积层CONV。对Swin Transformer网络架构而言,其中FC参数占比会超过83%,FLOPs计算超过97%。只针对CONV优化的计算架构应用到FC,计算效率自然会严重降低。
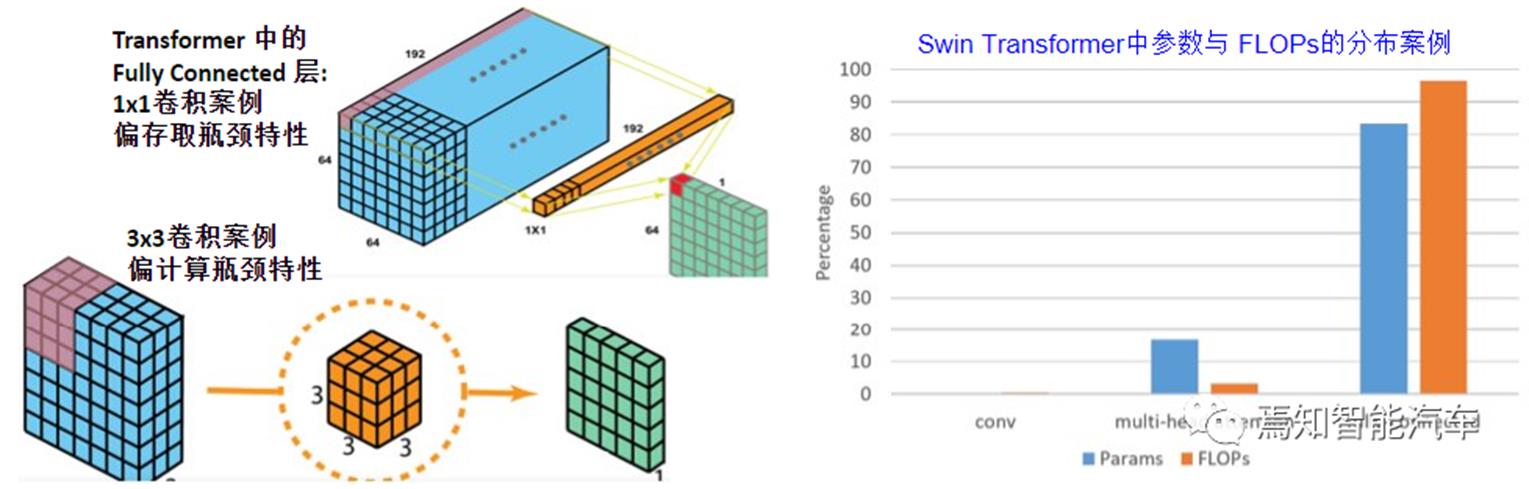
图 6 FC计算对比 案例
FC层的计算主要是动态输入的矢量与参数矩阵的点积。线性量化也就是逼近计算技术,可以压缩模型参数降低计算复杂度。从图 7可以看出一个比较有趣的现象,包括Transformer在内,平均有80%以上的输入在与64个不重复的模型参数进行点积,而且其中约44个参数值在常用8比特量化后不会超过256。这种稀疏特性,与DNN模型检测以及稀疏计算架构非常相似。这意味着在设计中可以考虑用索引来进行参数表征和实现点积运算。如图 8所示。基于索引的实现机制可以进一步压缩模型减少内存带宽使用,可以将点积乘减少33%,参数存储减少20%。这类优化实现在脉动阵列架构上是基本可行的,也可以考虑做为单独的Vector计算单元来设计,与Array计算单元进行异构组合实现。
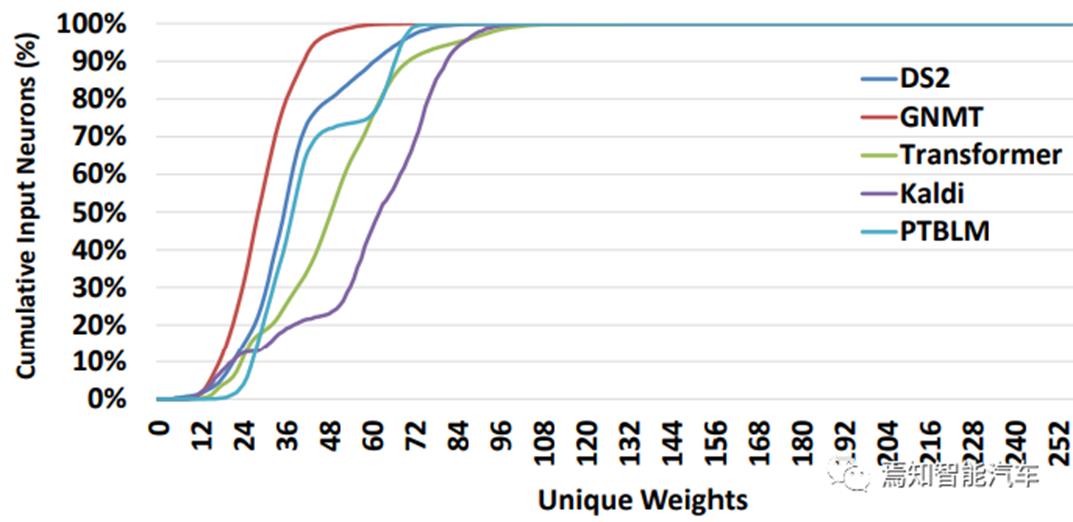
图 7 FC层模型量化后 不重复的参数的累计分布 (Riera, 2021)

图 8 CREW 计算复用和有效参数存取的FC设计案例 (Riera, 2021)
Convolution设计
如图 6所示,对Transformer网络而言,CONV和Multi-Head Self-Attention (MHSA)层的计算占时不多,都属于矩阵-矩阵的乘计算,而FC层属于矩阵-矢量的乘计算。通常NPU微计算架构将计算单元PE设计成1D或者2D Array,针对CONV 3x3进行优化,对其它卷积尺寸采用可配置设计模式,数据流的设计会相对简单,只是计算效率会低。这里值得一提的是,在Transformer (ViT)的网络架构里,首先采用了CNN来做特征提取,而且ViT采用了CONV4x4,现有NPU硬件计算效率会继续有低于66%的相对下降比例。如图 9所示是一个针对ViT CONV4x4 PE块的设计案例。如图 10所示是一个针对ViT 的NPU顶层架构的设计案例。ViT模型不同层中x7的尺寸比例设置,另外不同层的通道数都是x96的比例,PE4x7的阵列尺寸设置可以和模型对应进行有效匹配来计算卷积,其中每行4个MAC单元,NPU顶层案例采用了12个PE块。在每个PE单元里,每个权值系数从顶到底广播到所有乘法器,每个MAC可以从输入SRAM收到不同的输入来支撑FC层计算,PE乘法器的结果在水平方向累加,可以存到本地缓存便于后续累计。如图 10所示,顶层架构中将PE输出结果在累加器中累加,随后在加法器中求和,其结果会通过Layer Normalizatio进行归一化或Softmax进行计算处理,最终结果输出到片外内存里。对于MHSA的计算 ,

Q(Query)矩阵可以认为是PE单元块的参数输入,K(Key)矩阵可以认为是PE单元块的数据输入,由于矩阵尺寸小与网络其它层类型,8个PE单元模块可以搞定。对于Q矩阵映射,Q矩阵的4个列分配到一个PE单元然后按照行-行模式处理,每行7个时钟时间。K转置矩阵映射,可以安排到7行x 8个PE块进行计算,12个PE块中只用了8 个,硬件利用效率相对只有66%,但MHSA总的FLOPs占比不超过模型的3%,这种效率影响估计不会超过1%。
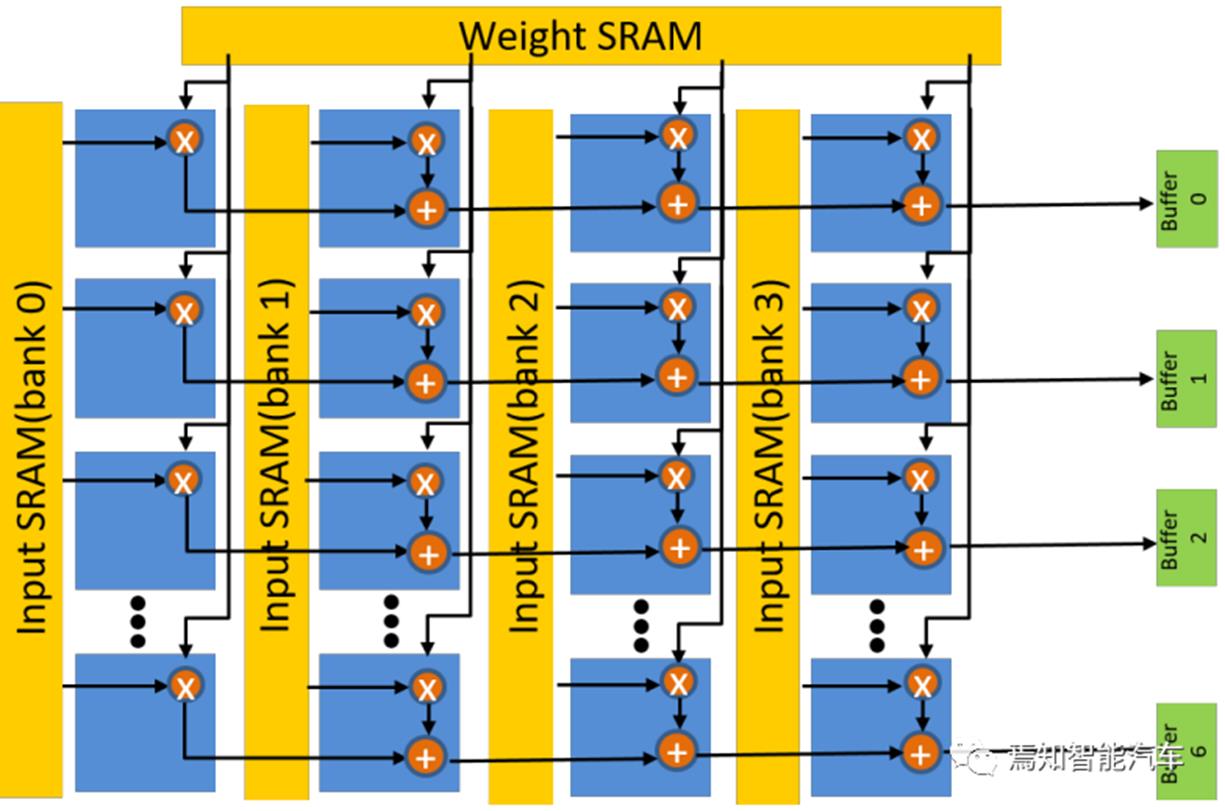
图 9 CONV4x4 PE块的设计案例 (Wang, 2022)

图 10 NPU顶层架构的设计案例 (Wang, 2022)
Integer-Only逼近计算设计
如上文所述,Transformer在ADS算法应用中的作用越来越有优势,几乎涵盖感知融合决策控制的每个流程,但Memory-bound的存算需求对设计有更大的挑战,本文的技术讨论和设计思路也是聚焦这个方面。如图 11所示的基于整数的量化逼近计算策略案例,可以通过Integer-only整数操作与bit-shifting位移处理来取代浮点数除法做逼近计算。ViT中的线性运算包括MatMul和Dense(即上述所说的FC)中的MAC,可以采用Integer-only流水线操作+Dyadic Arithmatic二分算术方法。ViT中的非线性运算包括上文所所述的Softmax,GELU, LayerNorm,也可以通过一个轻量级的Integer-only算术方法来进行快速逼近计算,即ShiftMax和ShiftGELU,来提升NPU微架构的整体性能。基于整数的量化逼近计算策略案例,在TVM上的仿真设计,声称可以有将近4倍推理速度提升,而且图 11所示的INT8量化策略,可以取得与FP相当或更高的性能,参数的INT4表征也可以是NPU设计的一个可行的发力点。
图 11 ViT基于整数 的计算图(Li, 2022)
ShiftMax和ShiftGELU硬件逼近计算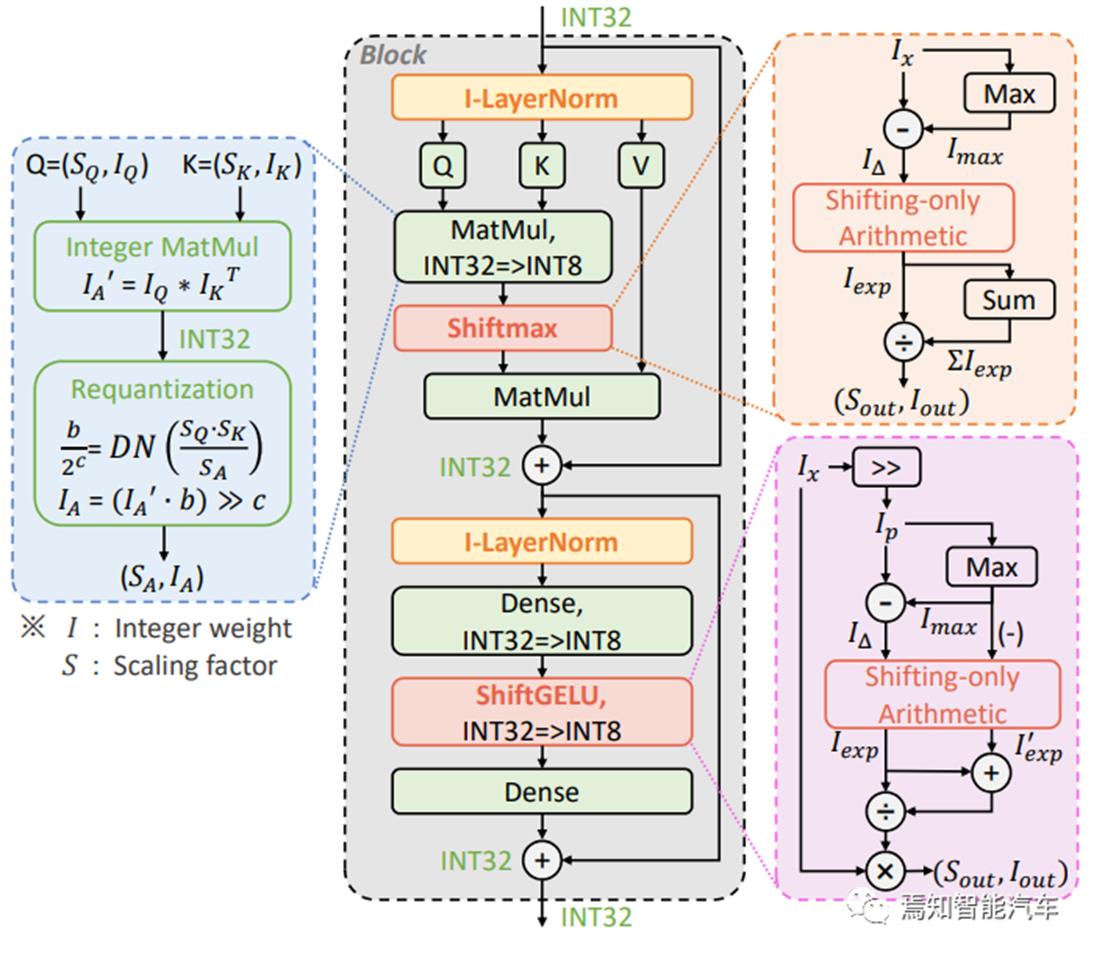

如图 11所示,GELU是Transformer中所用的非线性激活函数,可以通过Sigmoid函数进行逼近(Li, 2022)
对应于Integer-only的逼近计算方法,可以首先通过Integer Shifting操作家电技术智能化发展,无线WiFi芯片模块应用,WiFi模组技术
智能家居是容易标配WiFi的产品,尤其是白色家电产品,市场的基数大,空调、冰箱、洗衣机三大件,中国市场都过亿了。
一般而言智能家居是指智能主机、智能终端设备、通讯技术及控制设备在内的一套系统。在实际应用中,智能家居系统则能够做到对房间的灯光、温度、湿度进行智能化管控,安全防护、健康娱乐、家庭设备系统的自动化、智能化运行。
WiFi模块是整个系统的控制中心,控制就是输出一个开关信号控制继电器。这个模块的核心是WiFi的连接,这类本身没有屏幕和键盘的硬件设备,要想接入WiFi网络就需要便捷的连接方案。

即手机APP扫描WiFi,在APP上输入连接密码后自动由APP发送到模块,进行模块和WiFi的连接,本质上是一样的,只是叫的名字不同而已,并无啥差别。
物联网下,不仅有无数的信令、控制指令传输的需求,依然还有音视频等大数据流传输的应用需求,为此WiFi通讯协议在物联网时代自然会拥有一席之地。
物联网技术能够帮助智能家居环境中的门厅场景、客厅场景、厨房场景、卧室场景以及阳台场景的智能化管理。智能家居和智能应用之间的配合,离不开WiFi模块的帮助。没有WiFi模块,智能家居就不能很好的工作,不能进行数的交换。

WiFi在我们日常生活中并不陌生,简单来说,使用了WiFi模块的设备可以连接互联网,实现家电联网、设备联网等。
什么是WiFi模块呢?wifi模块属于物联网传输层,内置无线网络协议IEEE802.11b.g.n协议栈,可将串口或TTL电平转为符合wifi无线网络通信标准的嵌入式模块。很多能够联网的传统设备就是嵌入了嵌入式模块,具备了智能基因。
首先 ,将在家电设备中嵌入串口wifi模块,实现串口数据到无线数据的转换。在手机上APP上进行连接,手机联网之后在APP界面里进行操作,它能帮助你远程控制家中的电器,实现智能控制应用。
WiFi模块在智能家居领域的进军速度挺快。传统电器厂商在形势压力下纷纷转型开启智能化,WiFi模块成为传统厂商开启智能化道路的钥匙。传统的空调、冰箱、洗衣机、灯泡等都可以植入WiFi模块实现智能化发展。

为服务于物联网领域的智能家居产品发展,满足智能家居和智能应用之间的数据传输,飞睿科技代理乐鑫方案,提供ESP32 WiFi芯片模块技术和方案,针对有特殊功能需求的客户,可提供定制服务。
ESP32系列模组具备高性能和丰富的外设,集Wi-Fi、传统蓝牙、低功耗蓝牙为一体,提供集成Wi-Fi和蓝牙连接的MCU整体解决方案,广泛适用于各物联网应用。
以上是关于NPU芯片技术与市场发展杂谈的主要内容,如果未能解决你的问题,请参考以下文章