错误合集
Posted liuyujie-zhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了错误合集相关的知识,希望对你有一定的参考价值。
我最开始为什么会搞这些问题,都是因为这个错误:

所以我去百度了empty vocabulary; perhaps the documents only contain stop words,但是这个错误真的很难搞,百度了一圈也没搞明白解决办法,真的无语。
所以我开始想会不会是我的cutWords.pickle文件出了问题,于是开始打开文件输出:

我的pickle文件你咋了,昨天明明还好好的,咋变红了,好吓人,去搜了一下:

应该是文件太大了,所以我只输出了一个就没问题了:

所以pickle文件没有问题。
是不是我不该替换为空格呀,因为下面这个就没有分词且替换为空格,当时我为什么替换呀。

它这里的fit_transform(corpus)中的corpus可以是这种吗,然后我突然想起来我之前看到的逻辑回归的博主好像就是这样写的,我要回去看看。而且vectorizer = TfidfVectorizer(tokenizer=preprocess)中的tokenizer=preprocess这个作用是什么啊。
因为这里要用到mailContent_list,但每次再运行太麻烦了,所以我也把它生成pickle文件了,但是我是pycharm生成的:
import jieba import re import os import pickle def getFilePathList2(rootDir): filePath_list = [] for walk in os.walk(rootDir): part_filePath_list = [os.path.join(walk[0], file) for file in walk[2]] filePath_list.extend(part_filePath_list) return filePath_list filePath_list = getFilePathList2(\'./trec06c/data\') mailContent_list = [] for filePath in filePath_list: with open(filePath, errors=\'ignore\') as file: file_str = file.read() mailContent = file_str.split(\'\\n\\n\', maxsplit=1)[1] mailContent_list.append(mailContent) mailContent_list = [re.sub(\'\\s+\', \'\', k) for k in mailContent_list] mailContent_list = [re.sub("([^\\u4e00-\\u9fa5])", \'\', k) for k in mailContent_list] with open(\'mailContent_list.pickle\', \'wb\') as file: pickle.dump(mailContent_list, file)

现在我要试一下博主的代码,就是没有这句:mailContent_list = [re.sub("([^\\u4e00-\\u9fa5])", \'\', k) for k in mailContent_list],这时候的输出结果是3241

然后输出看一下这3241个特征词,都是句子,并不是词。

然后我如果加上了这句:mailContent_list = [re.sub("([^\\u4e00-\\u9fa5])", \'\', k) for k in mailContent_list],这时候的输出结果是44

然后也输出看一下这44个特征词,如下图,这哪是特征词,明明是句子:

还是按我之前的来,嗯。
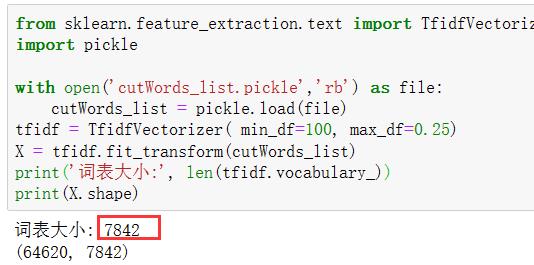
总共有7842个特征词,看下能不能输出来特征词。
可以欸,可是我在pycharm输不出来欸,就是下面这个错误:





怀疑人生了,难道刚刚不能运行是假的。
第二天我又试着运行了一下,也是可以运行的。
于是就到了下面这个问题,特征个数不符,即我分完后只有54个词,而predict()中的参数需要7842个词:

于是我想到把特征数扩为相同的,就是下面这个代码:
# 获取两个列表中的相同元素 common_elements = np.intersect1d(features, cutWords) # 创建一个和features长度相同的全0数组 words = np.zeros_like(features) for element in common_elements: # 获取相同元素在features中的下标 indices = np.where(np.array(features) == element) # 将相同元素在words中的下标设为1 words[indices] = 1
并且也实现了,没有任何问题,就是[1,0,0...]这种,我想着改成这种形式了应该不会出错了吧,但我用predict时又提示我出错。
就是这个错误:ValueError: Expected 2D array, got 1D array instead: array=[0. 0. 0. ... 0. 0. 0.]. Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.但是这个错搜都搜不到。
翻译成中文是应该是二维的数组,但我输入的是一维的。

根本不会解决。

这个错误到底怎么回事啊。
搜了一下二维数组:

于是我去chatGPT上搜到了解决办法,改完之后又出现了下面这个错误:
ValueError: Shape of passed values is (7842, 1), indices imply (7842, 7842),然后又胡搞瞎搞,根本不会。
然后我想到之前看过的一篇文章里有介绍怎么对一封邮件分类,于是我去看他的文章。

好像是这一步:
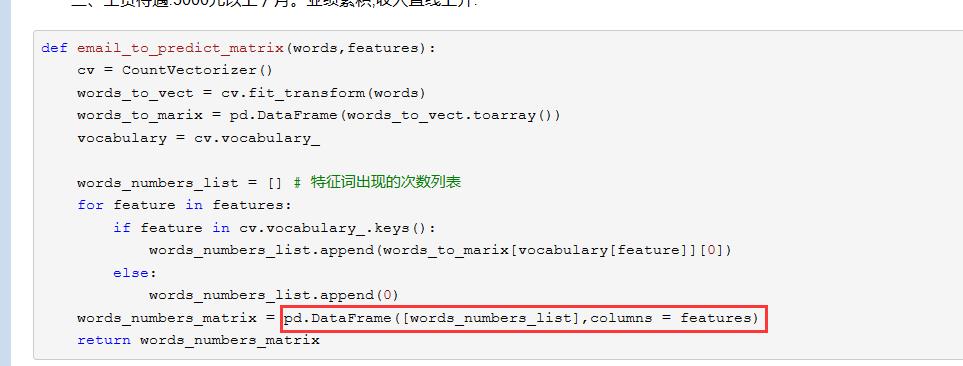
就是将上面扩的列表words改成二维的:words_martrix =pd.DataFrame([words],columns = features)
这样再使用predict函数就不会再出现问题了。下面是使用代码:

但是有一个疑问就是我忘记了0和1哪个是正常邮件和垃圾邮件。
于是我print:


与index对比,发现spam垃圾邮件是1:

然后这是我的运行结果:

完美!perfect!
错误语句合集及整理方法
试用Djiango的时候发现执行mange.py makemigrations 和 migrate是会报错,少位置参数on_delete,查了一下是因为指定外键的方式不对,改一下就OK了。
# 英雄出现的书 一对多设计 多方持有一方的外键 # hbook = models.ForeignKey(BookInfo) hbook = models.ForeignKey(‘BookInfo‘, on_delete=models.CASCADE)
以上是关于错误合集的主要内容,如果未能解决你的问题,请参考以下文章