Lecture #09: Index Concurrency Control
Posted Angelia-Wang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lecture #09: Index Concurrency Control相关的知识,希望对你有一定的参考价值。
review:
上几节讲了 hash table、B+Tree、Radix Tree 及其他树形结构。我们假设这些数据结构只能被一个线程访问,且在同一时间只有一个线程能对该数据结构进行读写数据。
然而大部分DBMS在实际场景中需要允许多线程安全地访问数据结构,以充分利用CPU多核以及隐藏磁盘I/O延时。(有DBMS只支持单线程,如Redis)。
1 Index Concurrency Control
并发控制协议,是DBMS使用以保证并发操作正确性的方法。
并发控制协议正确性标准有:
- Logical Correctness,线程可以读它期望读到的值,如在一个 transaction 中,一个线程在写完一个值之后,再读它,应该是它之前写的值。
- Physical Correctness,共享对象的内部表示是安全的,如共享对象内部指针不能指向非法物理位置。
本讲着重于Physical Correctness,Logical Correctness后面会讲。
2 Locks vs. Latches
1️⃣ Locks:
Locks 不同于 OS 中的锁,数据库中的 lock是一个 higher-level 的,概念上的。DBMS 使用 lock 避免不同 transactions 的竞争,如对 tuples、tables、databases 的 lock。Transactions 会在它整个生命周期持有 lock。lock 可以回滚。
2️⃣ Latches:
Latches是一个 low-level 的保护原语,DBMS 将 latch 用于其内部数据结构中的临界区,如 hash table 等。Latch 只在操作执行的时候被持有。latch 不支持回滚。
lock 专指的是事务语义层面的锁,例如两阶段提交锁。
latch 指的是程序层面对代码的锁保护,主要为了线程安全,例如常见的 mutex 等。
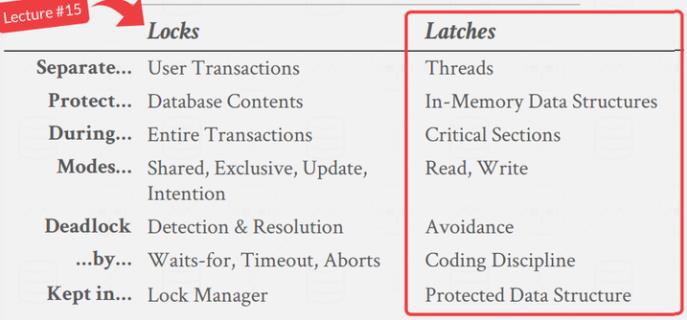
本节主要专注于 latch 相关的概念,事务层面的 lock 会在后续进行介绍。
latch 的语义比较类似我们在编程语言中见到的各种锁,它有两种模式:读和写。
- 读模式
- 多个线程可以同时访问一个对象而不阻塞
- 如果一个线程占据了读锁,另一个线程还可以继续申请读锁
- 写模式
- 同一时刻只能有一个线程访问对象
- 如果一个线程已经有写锁了,则另一个线程不能申请读锁,也不能申请写锁
3 Latch Implementations
用来实现latch的基本原理是通过现代 CPU 提供的 atomic compare-and-swap (CAS) 指令。借此,一个线程可以检查一个内存位置的内容,看它是否用某个值。如果有,则CPU将用一个新的值来交换旧的值,否则,该内存位置将保持不被修改。
在DBMS 实现 latch 用几种方法:每种都有不同的权衡。工程复杂性和运行时性能都有不同权衡。这些 test-and-set 是以原子方式进行的。
Blocking OS Mutex
- Latch 的一个可能的实现是 OS 的内置互斥机制。Linux 提供了 Futex(快速用户控件互斥)。由 (1) 用户空间的自旋latch 和 (2) OS 级互斥组成。如果 DBMS 能够获得用户空间的 latch,那么 latch 就会被设置。在 DBMS 看来,它是一个单一的 latch,尽管内部其实有 2 个。如果 DBMS 不能获取用户空间的 latch,则会进入内核并试图获取更加昂贵的mutex。如果又不能获得,则线程会通知 OS 它在 mutex 被阻塞,然后取消调度。
- OS mutex 在 DBMS 中,一般是不好的决定。因为它有 OS 控制,而且开销大。
- 例子:
std::mutex - 优点:使用简单
- 缺点:消耗大。不可扩展。因为OS的调度。
- 例子:
Test-and-Set Spin Latch (TAS)
- 自旋锁比 OS mutex 更有效。因为它被 DBMS 控制。自旋锁基本上是线程试图更新的内存位置(比如将一个 bool 设为 true)。一个线程执行 CAS 来尝试更新内存位置。DBMS 可以控制如果不能获得 latch 会发生什么。比如可以选择尝试再次尝试(while 循环)或允许操作系统取消调度。所以这种方式给了 DBMS 更多控制权。
- 例子:
std::atomic<T> - 优点:上锁解锁更高效。单一指令即可。
- 缺点:不具有扩展性,也不适合缓存。因为在多线程中,CAS 指令将在不同指令多次执行。浪费的指令会在高竞争环境中堆积起来。比较浪费 CPU。(一直停在 while 循环上)
- 例子:
Reader-Writer Latches
- Mutex 和自旋锁不区分读写。DBMS 需要一种允许并发读取的方法,所以如果用程序大量读取,就会有更好的性能。因为读可以共享,而不是等待。
- 读写锁允许 latch 以读或者写的模式保持。可以跟踪有多少线程持有该 latch,并在每种模式下等待获取 latch。读写锁使用前两种 latch 现的一种作为基础,并用额外的逻辑来处理读写队列。不同的 DBMS 可以有不同的策略来处理。
- 例子:
std::shared_mutex - 优点:并发读取
- 缺点:必须维护读写队列。以防饥饿。所以内存开销更大。
- 例子:
总结 latch 的实现方式:
1️⃣ 可以使用互斥原语,例如大多数编程语言中都内置了的锁,C 语言中的 pthread_mutex,C++ 中的 std::mutex,Go 中的 Mutex。
2️⃣ 使用 CAS 指令,这主要依赖于 CPU 的 cas 原子操作,这种方式基于硬件平台的汇编指令,效率很高。大多数语言中的 atomic 都依赖于 cas 实现。
3️⃣ 利用上述的两种方式,将锁的粒度减小,可以分离为读锁和写锁,分别锁定不同的对象,减少获取锁的冲突。
4 Hash Table Latching
了解过 latch 的概念,再来看看在哈希表中如何保证线程安全的。
静态哈希表比较好加锁,如开放地址哈希,进行查找的线程都是从上到下查找,从上到下地获取 slot 的锁,不会出现死锁的情况。如果要调整哈希表的大小,则对整个哈希表上把大锁就行。
动态哈希方法(如可扩展哈希)加锁更复杂,因为有更多的共享状态,更难进行并发控制。一般有两种加锁方式:
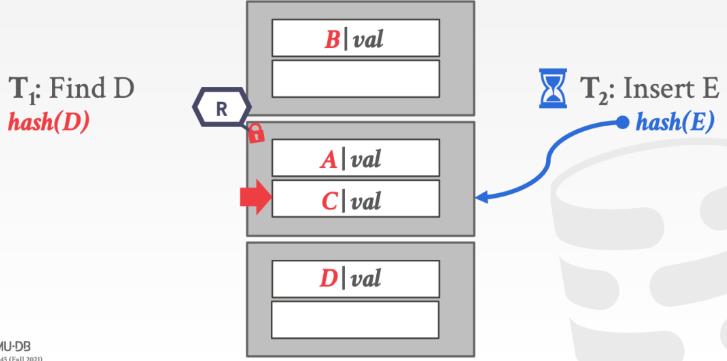
- Page Latches:对每个 page 上读写锁,线程访问页之前上锁,但会降低一些并行性。
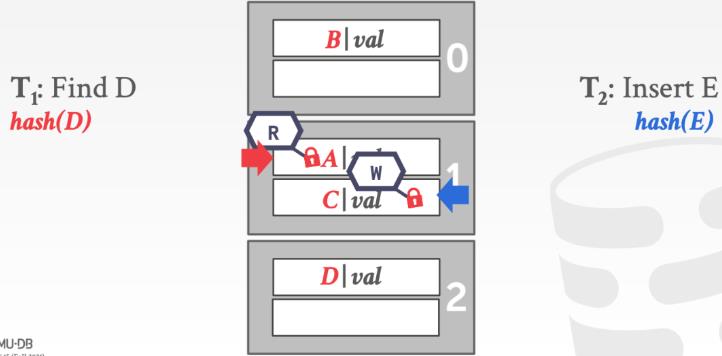
- Slot Latches:对每个 slot 上读写锁,增加了并行性,但是也增加了内存和计算开销 (因为线程要为访问的每个 slot 都获取锁)。可以使用单模式锁(即自旋锁)来减少内存和计算开销,代价是降低了并行性。
对 page 加锁,理解起来也比较简单,例如下面的例子,一个线程获取到锁,访问到 page 之后,如果另一个线程同时需要加写锁,那么就会阻塞。
对 slot 加锁,减小了锁的粒度。多个线程可以同时访问一个 page,但是在访问具体的 slot 时仍然需要加锁。
5 B+Tree Latching
哈希表中的加锁操作相对简单容易理解,B+ 树中的线程安全保证就稍微麻烦点了,需要考虑类似下面这样的问题:
- 多个线程在同一时刻去修改 B+ 树中的同一个结点
- 一个线程在遍历 B+ 树,而另一个线程在执行 split/merge 操作
[9][lecture] Lecture 5: Raft
6.824 2017 Lecture 5: Raft (1)
第一部分,介绍raft选举和log复制技术,相关的lab是lab2A 2B;第二部分设计,raft持久化,client行为以及快照技术,涉及lab 2C和lab 3
- 目前为止,讨论的技术主要是使用RSM技术做容错,比如configure server,gfs master或者mapreduce主节点,要达到的效果就是复制集对于client的表现和单点server一致,且具备容错性,挂少数的server依旧可用,策略就是复制,复制log同样的顺序执行,gfs和vmft都是这个套路
- 如何避免脑裂?集群分裂为AB,client连接到A,那么B挂了,A一定要可用;B没挂,那么要么A可用要么B可用,不能都可用
- 主要问题是无法区别crash或者网络不可达
- 我们需要RSM具备以下特性:第一,少数挂掉依旧可用;第二,处理网络分区问题避免脑裂;第三,多数挂掉,修复后依旧可用
- 多数投票制度可以避免分区,防止脑裂,1990s主要技术就是paxos和view-timestamped replication技术,两者都在工业系统中得到实践;raft提出的比较晚
raft overview
lab 3 system,multi-clients,3 replicas,k/v layer,raft layer,logs
- server’s raft layer选主
- client发送rpc请求到主节点,put,get,append
- k/v layer将请求转发到raft layer,此时不返回client,raft复制log到复制集节点,多数完成复制后,主节点commit,确保这个command已经持久化且达到了一致性要求,此时server apply这个command到到k/v state machine,其他节点通过心跳得到commit信息,本地执行,主节点在commit之后返回到KV layer,KV layer执行命令到db,返回给client
- 为何选取log技术?命令单身不够吗,要加入term信息,index信息,保证复制集之间达成一致,同时做写前日志使用,未完成commit时,持久化供后续commit
lab 2A 选主
leader简化了复制过程;raft中使用term代表逻辑时间序列,每个term一个主或者没有主,不会有2个主;每次选举有一个唯一的term,term帮助区分哪些节点比较新
- 发起选举的时机?followers timeout没收到心跳信息,发起选举;候选者 timeout发起新一轮选举
- 成为候选人后的具体操作?首先,获取多数票,成为leader,本地统计投票(对拜占庭问题无法解决);然后,对于没有得到多数票的场景,如果其他选主成功,成功追随者;如果没有选出主来,等待timeout继续下一轮选举,选举过程中要保证主节点日志最新,保证了不丢失数据
- 如何保证只有一个主?多数票决定,且每个term每个节点只能一次投票
- 成为新主后的操作?发送心跳,防止下一轮选举发生
- 选举失败可能的原因?没有足够的节点,分票
- 选举失败后面?继续选,直到成功为止
- 如何设计超时时间?随机超时设计,防止分票,不能太大防止长时间无主,不能太小,会造成分票选举失败;最少需要几倍的rpc执行时间,允许几次重试
lab 2B log复制
区别replicated log vs commited log,提交的log保证永远不会丢失,复制的但是没提交的log可能被覆盖。
- commit机制保证了,server只会执行稳定的log entry,即commit过的,commit过的意味着在当前term保证了多数节点复制成功
- leader无法复制上一任期的log entry,如果它没有commit,依旧会丢失
- 主节点覆盖log的时机?log务必是没有提交过的;过世的log会被主节点发来的消息覆盖掉
接口rf.Start(command) (index, term, isleader)
- kv service中put和get请求执行start,来就一个log entry达成共识,start立即返回,此时kv应等待commit返回的isLeader告诉是否要请求其他节点,term帮助确认当前主节点是否过期,index帮助确定是否已提交
接口ApplyMsg, with Index and Command
- Raft发送消息到applychannel,对于每条commit过的entry,此时等待的kv会开始真正执行command
raft FAQ
Q: raft为了简单牺牲了什么?
A: 主要牺牲了性能;比如每个op需要单独落盘保证一致性,如果可以batch会提升性能;第二,appendentry只能从主到从,且in-order,out-order就需要反复重试,可以流水线最好;第三,快照机制对于小的状态可以,对于大的状态不可用;第四,恢复回放对于大的状态也比较慢,完整的发送快照;第五,多核利用性不好,每次只能执行一个操作按照in log order TODO why;上述都可以通过修改基本协议来改进
Q: paxos?
A: paxos基本协议解决的问题是多个角色就一个值达成一致,因此需要额外的补充实现,持久化等等,已经基于paxos实践的系统,chubby,zookeeper,paxos made live,具体的实现都很复杂,不容易理解。raft容易理解,但是要实际使用还需要一些改进,来达到理想的性能。paxos 1980s,raft 2012,raft和view timestamp类似,后者在1988s提出。基于raft的系统变得多了起来,包括etcd,tikv,rethinkDB,CockroachDB等等
Q: raft性能如何?
A: paxos变种zab很快,不过最新的改进版本raft在etcd3中显示已经优化的更快了
Q: 少数节点存在下,是否可以保证可用性?
A: 取决于一致性要求,raft是强一致性的系统,因此不行。如果放宽一致性要求,可以实现,比如最终一致性。主要解决的问题是脑裂,主要方案有两种。第一,明确少数节点活着,多数节点挂掉了,需要人为介入,因为机器无法区别挂了还是网络中断了;第二,允许双写,稍后来处理冲突,一些nosql场景下可以大幅度提高性能,保障最终一致性。
Q: 选举过程中服务是halt住的?
A: 是的,不过实际中选举很短,发生频率也很低,影响较小
Q: 是否介意不通过选举完成一致性?
A: 可以,paxos就是如此,但是需要更多的通信达成共识
Q: raft vs vmft
A: vmft更广泛,raft只能对那些基于此协议的软件生效,但是raft会更加高效
Q: fake 消息?
A: 一般来说,raft相信节点都是可靠度的,可以部署在内网环境;如果要公网部署,则可以每个节点配置公私钥对,加密所有rpc请求完成认证操作。
Q: 如何使用raft接口?
A: 比如lab3,get put请求首先调用Start,然后读applychann得知是否commit,完成后续操作返回client
Q: 超时时间设置多少合适?
A: 太短,还没选举完成就超时了,频繁超时有负担;太长,浪费了不可用时间
Q: 主节点不挂也会切主吗?
A: 可能的,网络分区也会导致切主
Q: 主节点发送rpc后应该阻塞等待吗?
A: 绝不,发起新的go完成发送,同时原子更新返回的个数,达到多数时可以commit
reference
以上是关于Lecture #09: Index Concurrency Control的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读自然语言模型的尺度法则(CS224N WINTER 2022 Lecture17 推荐阅读整理)
论文阅读自然语言模型的尺度法则(CS224N WINTER 2022 Lecture17 推荐阅读整理)
论文阅读自然语言模型的尺度法则(CS224N WINTER 2022 Lecture17 推荐阅读整理)
原Andrew Ng斯坦福机器学习——Lecture 5 Octave Tutorial—5.5 控制语句: for, while, if 语句
(ResultSet.TYPE_SCROLL_INSENSITIVE,ResultSet.CONCUR_READ_ONLY)讲解