大算力,内存墙与功耗墙分析
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大算力,内存墙与功耗墙分析相关的知识,希望对你有一定的参考价值。
大算力,内存墙与功耗墙分析
大算力场景,“内存墙”、“功耗墙”等问题及解决途径
目前 AI 大模型的算力水平显著供不应求。以 Open AI 的算力基础设施为例,芯片层面 GPGPU 的需求最为直接受益,其次是 CPU、AI 推理芯片、FPGA 等。AI 服务器市场的扩容,同步带动高速网卡、HBM、DRAM、NAND、PCB 等需求提升。同时,围绕解决大算力场景下 GPU“功耗墙、内存墙”问题的相关技术不断升级,如存算一体、硅光/CPO 产业化进程有望提速。
1.“内存墙”、“功耗墙”等掣肘 AI 的算力发展
“存”“算”性能失配,内存墙导致访存时延高,效率低。内存墙,指内存的容量或传输带宽有限而严重限制 CPU 性能发挥的现象。内存的性能指标主要有“带宽”(Bandwidth)和“等待时间”(Latency)。近 20 年间,运算设备的算力提高了 90000 倍,提升非常快。虽然存储器从 DDR 发展到 GDDR6x,能够用于显卡、游戏终端和高性能运算,接口标准也从 PCIe1.0a 升级到 NVLink3.0,但是通讯带宽的增长只有 30 倍,和算力相比提高幅度非常缓慢。

冯诺依曼架构下,数据传输导致严重的功耗损失。冯·诺依曼架构要求数据在存储器单元和处理单元之间不断地“读写”,这样数据在两者之间来回传输就会消耗很多的传输功耗。根据英特尔的研究表明,当半导体工艺达到 7nm 时,数据搬运功耗高达 35pJ/bit,占总功耗的63.7%。数据传输造成的功耗损失越来越严重,限制了芯片发展的速度和效率,形成了“功耗墙”问题。

AI 模型参数量极速扩大,GPU 内存增长速度捉襟见肘。在 GPT-2 之前的模型时代,GPU 内存还能满足 AI 大模型的需求。近年来,随着 Transformer 模型的大规模发展和应用,模型大小每两年平均增长了 240 倍。GPT-3 等大模型的参数增长已经超过了 GPU 内存的增长。传统的设计趋势已经不适应当前的需求,芯片内部、芯片之间或 AI 加速器之间的通信成为了 AI训练的瓶颈。AI 训练不可避免地遇到了“内存墙”问题。

AI 模型运算量增长速度不断加快,推动硬件算力增长。预训练技术的进步导致了各领域模型计算量的快速增长,大约每两年就要增加 15 倍。而 Transformer 类模型的运算量更是每两年就要增加 750 倍。这种近乎指数的增长趋势促使 AI 硬件的研发方向发生变化,需要更高的峰值算力。

当前的研究为了实现更高的算力,甚至不惜简化或者优化其他部分组件,例如内存的分层架构,将 DRAM 容量用于需要高性能访问的热数据,将容量层用于处理需要大容量但性能要求不那么高的任务,以适应不同的数据类型、用例、技术需求和预算限制,适用于 AI、ML 和 HPC 等众多应用场景,能帮助企业以经济高效的方式满足内存需求。
2.“内存墙”、“功耗墙”等问题解决路径
2.2.1.存算一体技术:以 SRAM、RRAM 为主的新架构,大算力领域优势大存算一体在存储器中嵌入计算能力,以新的运算架构进行乘加运算。存算一体是一种以数据为中心的非冯诺依曼架构,它将存储功能和计算功能有机结合起来,直接在存储单元中处理数据。存算一体通过改造“读”电路的存内计算架构,可以直接从“读”电路中得到运算结果,并将结果“写”回存储器的目标地址,避免了在存储单元和计算单元之间频繁地转移数据。存算一体减少了不必要的数据搬移造成的开销,不仅大幅降低了功耗(降至 1/10~1/100),还可以利用存储单元进行逻辑计算提高算力,显著提升计算效率。它不仅适用于 AI 计算,也适用于感存算一体芯片和类脑芯片,是未来大数据计算芯片架构的主流方向。

存算一体技术可分为查存计算、近存计算、存内计算和存内逻辑,提供多种方式解决内存墙问题。
查存计算:早期技术,在存储芯片内部查表来完成计算操作。
近存计算:早已成熟,计算操作由位于存储区域外部的独立计算芯片/模块完成。典型代表是 AMD 的 Zen 系列 CPU,以及封装 HBM 内存(包括三星的 HBM-PIM)与计算模组(裸Die)的芯片。
存内计算:计算操作由位于存储芯片/区域内部的独立计算单元完成,存储和计算可以是模拟或数字的。典型代表是 Mythic、千芯科技、闪亿、知存、九天睿芯等。
存内逻辑:通过在内部存储中添加计算逻辑,直接在内部存储执行数据计算。典型代表包括 TSMC(在 2021 ISSCC 发表论文)和千芯科技。

SRAM、RRAM 是存算一体介质的主流研究方向。存算一体的成熟存储器有几种,比如 NOR FLASH、SRAM、DRAM、RRAM、MRAM 等 NVRAM。
FLASH 是非易失性存储,成本低,可靠性高,但制程有瓶颈。
SRAM 速度快,能效比高,在存内逻辑技术发展后有高能效和高精度的特点。
DRAM 容量大,成本低,但速度慢,需要不断刷新电力。
新型存储器 PCAM、MRAM、RRAM 和 FRAM 也适用于存算一体。其中 RRAM 在神经网络计算中有优势,是下一代存算一体介质的主流方向之一。除了 SRAM 之外,RRAM 也是未来发展最快的新型存储器之一,它结构简单,速度高,但材料不稳定,工艺还需 2-5 年才能成熟。

存算一体有着广泛的应用场景,在不同大小设备上均有需求。
从技术领域来看,存算一体可以应用于:
(1)AI 和大数据计算:将 AI 计算中大量乘加计算的权重部分存在存储单元中,从而在读取的同时进行数据输入和计算处理,在存储阵列中完成卷积运算。
(2)感存算一体:集传感、储存和运算为一体构建感存算一体架构,在传感器自身包含的 AI存算一体芯片上运算,来实现零延时和超低功耗的智能视觉处理能力。
(3)类脑计算:使计算机像人脑一样将存储和计算合二为一,从而高速处理信息。存算一体天然是将存储和计算结合在一起的技术,是未来类脑计算的首选和产品快速落地的关键。
从应用场景来分,存算一体可以适用于各类人工智能场景和元宇宙计算,如可穿戴设备、移动终端、智能驾驶、数据中心等。
(1)针对端侧的可穿戴等小设备,对成本、功耗、时延难度很敏感。端侧竞品众多,应用场景碎片化,面临成本与功效的难题。存算一体技术在端侧的竞争力影响约占 30%。(例如 arm占 30%,降噪或 ISP 占 40%,AI 加速能力只占 30%)
(2)针对云计算和边缘计算的大算力设备,是存算一体芯片的优势领域。存算一体在大算力领域的竞争力影响约占 90%。
传统存储大厂纷纷入局,新兴公司不断涌现。
(1)国外方面,三星电子在多个技术路线进行尝试,发布新型 HBM-PIM(存内计算)芯片、全球首个基于 MRAM(磁性随机存储器)的存内计算研究等。台积电在 ISSCC 2021 上提出基于数字改良的 SRAM 设计存内计算方案。英特尔也早早提出近内存计算战略,将数据在存储层级向上移动,使其更接近处理单元进行计算。


(2)国内方面,阿里达摩院成功研发全球首款基于 DRAM 的 3D 键合堆叠存算一体芯片,可突破冯·诺依曼架构的性能瓶颈。千芯科技是可重构存算一体 AI 芯片的领导者和先驱,核心产品包括高算力低功耗的存算一体 AI 芯片/IP 核(支持多领域多模态人工智能算法)。
破解内存墙,除了“存算一体”还需要什么?
20世纪初的物理学家不会想到,悬浮在物理学大厦上的两朵乌云会彻底颠覆整个物理学体系,冯·诺依曼在参与曼哈顿工程提出新架构时,也不会想到未来阻止芯片算力进步的竟然不是芯片本身。
冯·诺依曼结构的诞生与局限
1945年6月30日,美国正在秘密进行曼哈顿计划。冯·诺依曼作为该计划的重要参与者与领导者,与另外两位组内科学家发表了一篇长达101页的报告,这就是计算机史上著名的“101页报告”,也是现代计算机科学发展里程碑式的文献。
这份文件基于当时世界上第一台计算机埃尼阿克(ENIAC)提出,详细阐述了一种新型的计算机架构类型。彼时的电脑虽然采用了世界上最先进的电子技术,但缺乏整理论指导,用现在的话讲就是“只堆料,不优化”。此外,早期电脑的用途单一,若仅设计用于数学计算,那它就不能用来处理文字内容,变更用途就需要对整体电路进行重新设计。
冯·诺依曼精准找出电脑运行缓慢的关键:处理器虽然可以快速完成计算,但在计算间隙,需要进行大量I/O步骤来保存计算的中间数据,这极大的拖累了处理器的整体处理速度。他将计算机结构重新调整,巧妙的将存储与计算分离,通过内部存储器存储程序,成功解决了当时计算机存储容量太小,运算速度过慢的问题。这种结构也创造了一组指令集架构,可以将机器运算转换为一串串编程语言,让此机器更有 “弹性”,不再需要频繁更改电路。后来人们将这种结构定义为冯·诺依曼结构(Von Neumann architecture)。

冯·诺依曼结构
图源 | 百度百科
冯·诺依曼结构也称冯·纽曼模型(Von Neumann model)或普林斯顿结构(Princeton architecture),它有以下几个特点:(1)以运算单元为中心。(2)采用存储程序原理。(3)存储器是按地址访问、线性编址的空间(4)控制流由指令流产生。(5)指令由操作码和地址码组成。(6)数据以二进制编码。该结构由运算器、控制器、存储器、输入设备、输出设备五个部分组成。简单来讲,冯·诺依曼结构将电路与程序分离,方便进行后期程序重新调整;程序员仅通过内部存储器写入相关运算命令,让计算机可以快速执行运算操作;二进制运算也能大大加快计算机的整体速度。
这种“存算分离”的结构也有自己的局限性:处理器与内存间的数据交换量同内存的整体储存量相比太小了,随着处理器技术的发展,这一比例更为悬殊。在一些特殊使用场景中(尤其是近年来火热的AI计算领域),处理器需要经常等待内存的数据回传,超高的延时严重拖慢了计算机整体的运行效率,内存性能逐渐成为限制计算机发展的关键。与此同时,过高的信息交换量也带来了严重的发热问题与功耗问题。内存墙、功耗墙与散热墙成为阻拦计算机算力发展绕不开的“三堵高墙”。
内存墙,绕开还是撞穿?
破解内存墙问题目前已经成为工业界和学术界的焦点问题。
绕开,意味着要放弃冯·诺依曼的“存算分离”结构,采用“存算一体”的结构模式来规避内存墙对运算性能的限制。一些研究人员提出了一种以存储器为中心的体系结构,称为“智能存储”。其核心思想是将部分或全部的计算移到存储中,计算单元和存储单元集成在同一个芯片,在存储单元内完成运算,让存储单元具有计算能力。
“存算一体”结构目前较成熟的方案有查存计算(Processing With Memory)或近存计算(Computing Near Memory),可拉进内存与处理器的距离来降低大规模数据交换延时。除了成熟方案,存内计算(Computing In Memory)方案目前已成为各厂商的主要发力点,它的计算操作由位于存储芯片区域内部的独立计算单元完成,存储和计算可以是模拟的也可以是数字的,一般用于算法固定的场景算法计算。存内逻辑(Logic In Memory)属于较新的架构,通过在内部存储中添加计算逻辑,直接在内部存储执行数据计算,真正做到了“存算一体”。它的数据传输距离最短,同时能满足大模型的计算精度要求,目前已有部分厂商已经在该结构上做出尝试。
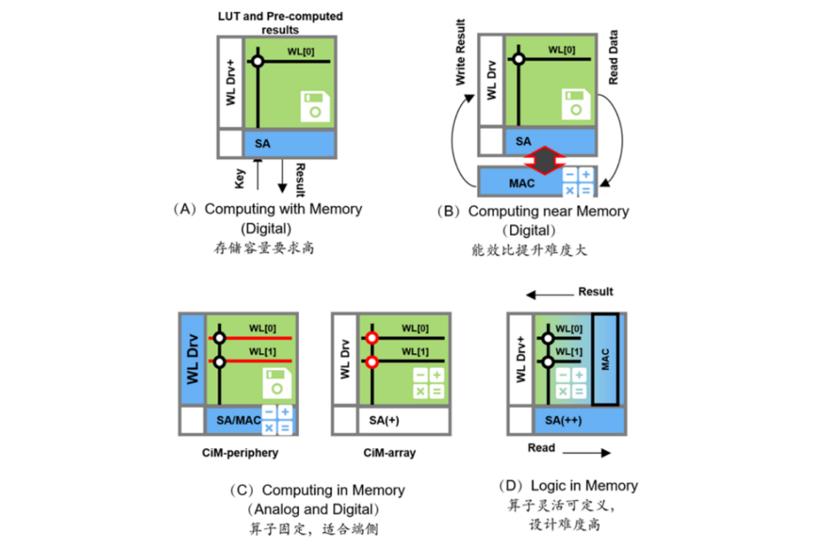
四种存算一体结构
图源 | 互联网
撞穿,意味着要在冯·诺依曼结构内部做出技术革新,其核心问题就是提升内存处理速度与数据传输速度。提升传输速度需要在总线技术上发力,光互联技术采用波导方式传输数据,相比硅晶内部的载流子传输,具有损耗低、速度快、延时小的优点,可实现数据的高速传输,减少功耗。不过,面对内存墙无论是绕开还是撞穿,终归还是要降低内存处理的延时,提升整体计算速度,因此降低内存本身延时也很关键。
存算一体
离不开新式存储方式
冯·诺依曼结构中,DRAM作为一种能够快速反应的易失性存储介质,是作为处理器一级内存的不二之选。DRAM基于场效应管工作,通过电流控制MOS管开闭来控制电荷进出晶体管,晶体管中的电荷多与少代表了1和0,即每个存储单位可以储存1Bit数据。当电流消失,晶体管就会释放所有电荷,因此这种存储介质被称为易失性存储介质。目前DRAM提升效率的主要方式就是增加工作频率,2666MHz、3200MHz、3600MHz等参数就是内存的工作频率。但随着半导体工艺尺寸逐渐减小,传统的基于互补金属氧化物半导体工艺的缓存和主存遭遇了性能瓶颈,量子隧穿问题时刻困扰着内存工艺的进步,延时也无法进一步降低。
近年来,各类“存算一体”芯片架构的诞生,让一部分延时更低的新式存储方式走进人们视线。其中PCRAM相变储存器、ReRAM电阻式存储器、MRAM磁变/磁阻存储器以及铁电存储器FRAM的出现为破解内存墙提供了新思路。
PCRAM又称PCM、OUM(Ovonic UnifiedMemory)和 CRAM(Chalcogenide Random AccessMemory),从名字可以看出,它利用相变材料作为储存介质。PCRAM在工作时通过对相变材料施加不同时长的电脉冲,使相变材料在不同程度的电流热效应下分别呈现出不同的结晶状态,并在两种状态之间快速切换。相变材料在非晶相态时呈现出半导体特性,具有较高的电阻值;在结晶相态时呈现出半金属特性,具有较低的电阻值。因此,可以分别通过相变材料在非晶相态和结晶相态时呈现出的不同电阻特性来分别表示需要存储的数据。PCRAM具有较好的微缩能力,目前已经可以做到20nm工艺,因此其储存密度较DRAM更高。此外,由于相变材料可以在晶体态和非晶体态之间无极变换,通过更加精密的电阻探测方式,可以在单一存储单元内存储多Bit数据,因此PCRAM未来开发潜力巨大。

PCRAM 图源 | 百度百科
ReRAM,也称RRAM,电阻式存储器,是以非导性材料(金属氧化物)的电阻在外加电场作用下,在高阻态和低阻态之间实现可逆转换的非易失性存储器。ReRAM在工作时可以对金属氧化物施加电压,使材料的电阻在高阻态和低阻态间发生相应变化,并利用这种性质储存各种信息。与PCRAM原理类似,ReRAM也能在单个存储单元中存储多Bit数据。与DRAM相比,RRAM不仅满足高读写速度和存储密度的要求,同时延迟更低,可满足未来智能驾驶高实时数据吞吐量。

ReRAM 图源 | Objective Analysis
MRAM(Magnetoresistive Random Access Memory)是一种利用磁性工作的非易失性随机存储器。它和我们熟悉的“磁带”不同,MRAM的磁性并不依赖介质表面的磁粉,而是基于两个铁磁层磁化状态来存储信息,其核心元件就是磁性隧道结 (magnetic tunnel junction,MTJ),当电流流过MTJ时它会因为存储信息的不同而表现出不同的阻值。当下的 MRAM 家族成员包括了三类:自旋转移扭矩 (spin-transfer torque :STT)、自旋轨道扭矩 (spin-orbit torque:SOT)、电压控制(VCMA-和 VG-SOT)。
FRAM(FRAM,ferroelectric RAM)铁电存储器也是一种特殊工艺的非易失性的存储器,采用人工合成的铅锆钛(PZT) 材料形成存储器结晶体存储数据。当一个电场被施加到铁晶体管时,中心原子顺着电场停在低能量位置处,大量中心原子在晶体单胞中移动最终形成极化电荷,然后外界通过判断铁晶体管内的电荷高低来读取数据。与DRAM相比,FRAM在速度与价格方面都具有较大优势。

FRAM
图源 | Objective Analysis
值得注意的是,无论是哪种新式存储方式,目前都存在部分局限性。由于存算一体架构在片内计算基本都属于模拟计算,计算精度完全取决于工艺精度,更不能计算浮点运算,因此新式存储方式搭配存算一体架构仅适合应用于需要大规模存储的场景中。此外新式存储往往专注于降低延时与持久储存,往往还不具备Flash、DRAM等成熟工艺的可靠性,还需要继续发展并完善。
总结
随着摩尔定律逼近极限,芯片算力提升已经达到瓶颈,尤其是在需要大规模存储的计算场景中,处理器与内存的数据交换上限逐渐成为新瓶颈。目前存算一体架构搭配延时更低的新存储方式成为破解内存墙的关键。
参考文献链接
https://mp.weixin.qq.com/s/Ti2UmJaZNlRym58Hokqs2A
https://mp.weixin.qq.com/s/bZgMgTiaj4CaHvtiARrxSg
小米笔记本pro CPU GPU 做科学计算的算力对比
小米笔记本pro:15.6寸,i7-8850,16G,256G,GPU:MX150
测试对象Caffe,MNIST训练
使用纯CPU训练:
1.耗时:11分58秒
2.功耗:35W
使用GPU训练:
1.耗时:1分17秒
2.功耗:49W
笔记本静止功耗:12W
总结:
1.GPU 与 CPU的算力比9.2倍。
2.GPU 与 CPU的能效比5.7倍。
以上是关于大算力,内存墙与功耗墙分析的主要内容,如果未能解决你的问题,请参考以下文章
存算一体芯片离普及还有多远?听听从业者怎么说 | 对撞派 x 后摩智能
国内首款百TOPS大算力芯片征程5,Q4将落地车企正式SOP