AI算力的阿喀琉斯之踵:内存墙
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI算力的阿喀琉斯之踵:内存墙相关的知识,希望对你有一定的参考价值。

作者 | Amir Gholami 责编 | 欧阳姝黎
出品 | OneFlow社区
这篇文章是我(Amir Gholami), Zhewei Yao,Sehoon Kim,Michael W. Mahoney 和 Kurt Keutzer 等人共同协作完成的。本文中用到的数据可以参考链接https://github.com/amirgholami/ai_and_memory_wall

图表 1:该图表展示了,目前 SOTA 模型训练的浮点数运算量(以 FLOPs为衡量单位)。蓝线上的是 CV,NLP和语音模型,模型运算量平均每两年翻 15 倍,红线上的是 Transformer 的模型,模型运算量平均每两年翻 750 倍。而灰线则标志摩尔定律下内存硬件大小的增长,平均每两年翻 2 倍。
如图表 1 所示,最近几年,计算机视觉(CV),自然语言处理(NLP)和语音识别领域最新模型的训练运算量,以大约每两年翻15倍数的速度在增长。而 Transformer 类的模型运算量的增长则更为夸张,约为每两年翻 750 倍。这种接近指数增长的趋势驱动了 AI 硬件的研发,这些 AI 硬件更专注于提高硬件的峰值算力,但是通常以简化或者删除其他部分(例如内存的分层架构)为代价。
然而,在应付最新 AI 模型的训练时,这些设计上的趋势已经显得捉襟见肘,特别是对于 NLP 和 推荐系统相关的模型:有通信带宽瓶颈。事实上,芯片内部、芯片间还有 AI 硬件之间的通信,都已成为不少 AI 应用的瓶颈。特别是最近大火的 Transformer 类模型,模型大小平均每两年翻240倍(如图表2所示)。类似的,大规模的推荐系统模型,模型大小已经达到了 O(10) TB 的级别了。与之相比,AI 硬件上的内存大小仅仅是以每两年翻2倍的速率在增长。
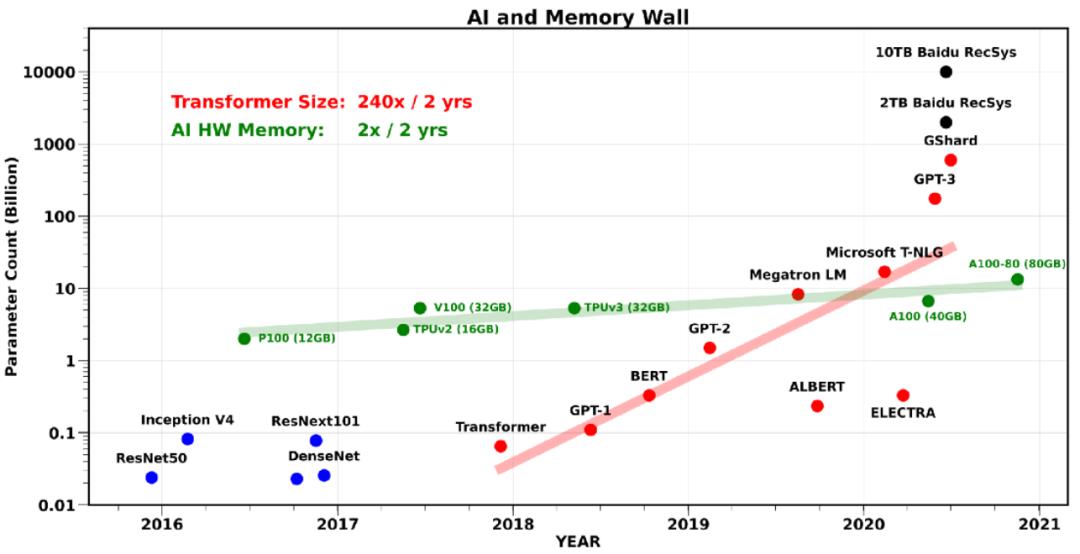
图表 2:该图表展示了 SOTA 模型的参数量的增长趋势。图中的绿点表示 AI 硬件(GPU)的内存大小。大型的 Transformer 模型以每两年翻 240 倍接近指数级的速率增长。但是单 GPU 的内存却只是每两年翻2倍,图片链接。*
值得注意的是,训练 AI 模型时候所需要的内存一般比模型参数量还要多几倍。这是因为训练时候需要保存中间层的输出激活值,通常需要增加3到4倍的内存占用。图表3中展示了最新的 AI 模型训练时候,内存占用大小逐年的增长变化趋势。从中能清楚地看到,神经网络模型的设计是如何受 AI 硬件内存大小影响的。
这些挑战也就是通常所说的 “内存墙” 问题。内存墙问题不仅与内存容量大小相关,也包括内存的传输带宽。这涉及到多个级别的内存数据传输。例如,在计算逻辑单元和片上内存之间,或在计算逻辑单元和主存之间,或跨不同插槽上的不同处理器之间的数据传输。上述所有情况中,容量和数据传输的速度都大大落后于硬件的计算能力。
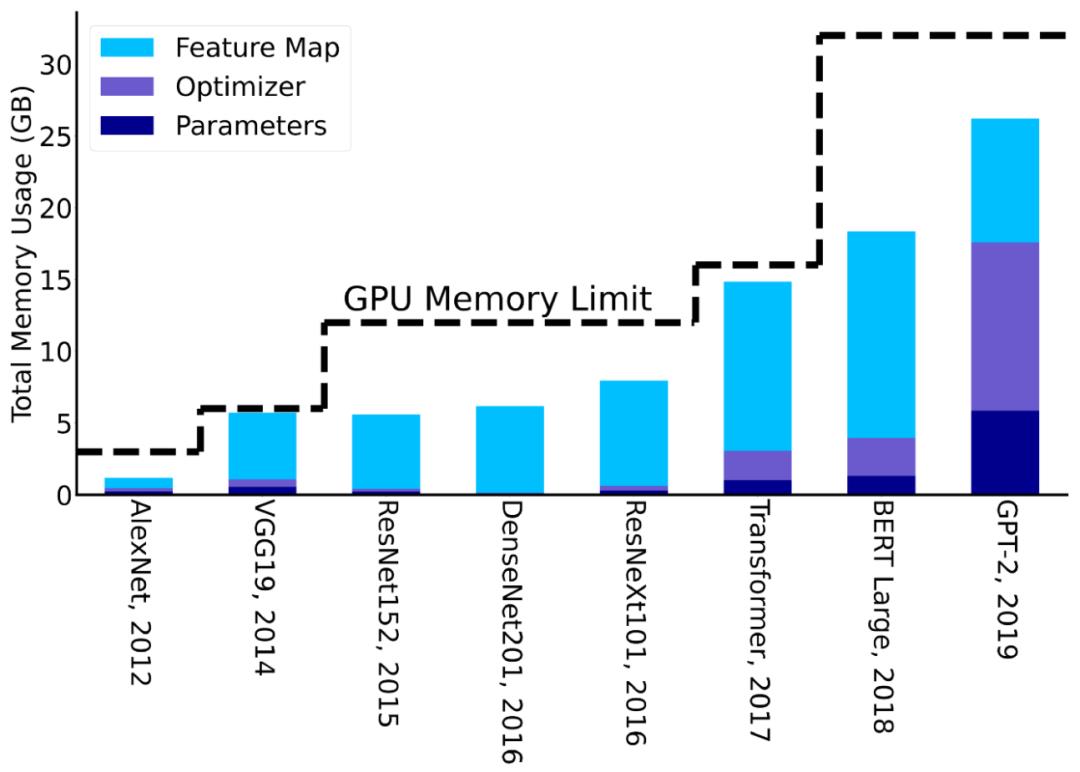
图表 3:图中展示了,训练不同神经网络模型所需要的内存大小。对于 CV 模型优化器用的是 SGD+Momentum,而对于 NLP 模型则用的是 ADAM。从中能看出一个趋势,随着 GPU 内存的上限增长,新设计模型的参数大小也在增长。每次 GPU 的内存上限有提升,研究人员都会提出新的参数更大的模型。因此如果能打破所谓的 GPU 内存墙 则可能会带来进一步的创新。更多详细信息可以参考[2]。
大家可能会想到,是否可以尝试采用分布式的策略将训练扩展到多个 AI 硬件(GPU)上,从而突破于单个硬件内存容量和带宽的限制。然而这么做 也会遇到内存墙 的问题:AI 硬件之间会遇到通信瓶颈,甚至比片上数据搬运更慢、效率更低。和单设备的内存墙问题类似,扩展 AI 硬件之间的网络带宽的技术难题同样还未被攻破。如图表4所示,其中展示了在过去20年中,硬件的峰值计算能力增加了90,000倍,但是内存/硬件互连带宽却只是提高了30倍。而要增加内存和硬件互连带宽[1],需要克服非常大的困难。因此,分布式策略的横向扩展仅在通信量和数据传输量很少的情况下,才适合解决计算密集型问题。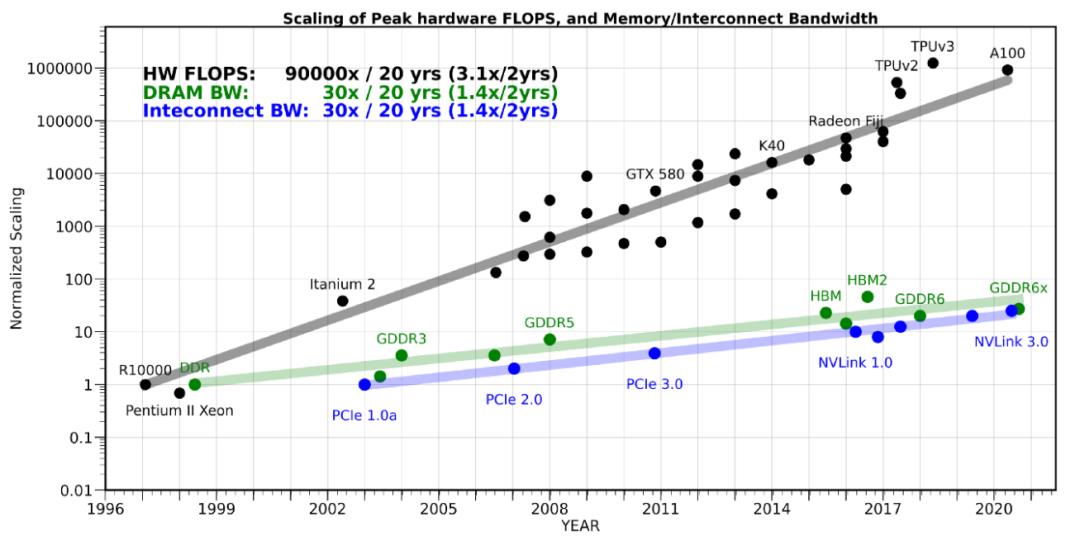
图表 4:图中展示了,带宽、内存和硬件的计算能力的增长趋势。从中可以看出带宽增长非常的缓慢(大约每20年增加30倍,而硬件的计算能力则增加了90,000倍)。

有希望打破内存墙的解决方案
“指数增长不可持续”,即使对于巨头公司来说,以每2年240倍的速度持续指数增长也是不可能的。再加上算力和带宽能力之间的差距越来越大,训练更大的模型的成本将以指数级增长,训练更大模型将更具有挑战性。
为了继续创新和 “打破内存墙”,我们需要重新思考人工智能模型的设计。这里有几个要点:
首先,当前人工智能模型的设计方法大多是临时的,或者仅依赖非常简单的放大规则。例如,最近的大型 Transformer 模型大多是原始 BERT 模型[22]的缩放版本,二者基本架构几乎一样。
其次,我们需要设计更有效的数据方法来训练 AI 模型。目前的网络训练非常低效,需要大量的训练数据和数十万次的迭代。有些人也指出,这种训练方式,不同于人类大脑的学习方式,人类学习某个概念或分类,往往只需要很少的学习例子。
第三,现有的优化和训练方法需要大量的超参调整(如学习率、动量等) ,在设置好参数从而训练成功前,往往需要数以百计次的试错。这样看来,图1中只是展示了训练成本的下限,实际成本通常要高得多。
第四,SOTA 类网络规模巨大,使得光部署它们就极具挑战。这不仅限于 GPT-3 等模型。事实上,部署大型推荐系统(类似于 Transformers ,但 embedding 更大且后接的 MLP 层更少)是巨头公司所面临的主要挑战。
最后,AI 硬件的设计主要集中在提高算力上,而较少关注改善内存。这让训练大模型、探索新模型都变得困难。例如图神经网络(GNN)就常常受限于带宽,不能有效地利用当前硬件(的算力)。
以上几点都是机器学习中的重要基础问题。在这里,我们简要讨论最近针对后三点(包括我们自己)的研究。

高效的训练算法
训练模型时的一大困难是需要用暴力探索的方法调整超参。寻找学习率以及其配套的退火策略,模型收敛所需的迭代次数等等,这给训练 SOTA 模型带来了不少额外开销(overhead)。
这些问题大多是由于训练中使用的是一阶 SGD 优化方法。虽然 SGD 超参容易实现,却没有稳健的方法去调试超参,特别是对于那些还没得到正确超参集合的新模型,调参就更加困难了。
一个可能的解决方法是使用二阶 SGD 优化方法,如我们最近发表的 ADAHESSIAN 方法[4]。这类方法在超参调优时往往更加稳健,从而达到可以达到 SOTA。
但是,这种方法也有亟待解决的问题:目前占用的内存是原来的3-4倍。微软关于 Zero 论文种介绍了一个很有前景的工作:可以通过删除/切分冗余优化器状态参数[21, 3],在保持内存消耗量不变的前提下,训练8倍大的模型。如果这些高阶方法的引入的 overhead 问题可以得到解决,那么可以显著降低训练大型模型的总成本。
另一种很有前景的方法是提高优化算法的数据本地性(data locality)并减少内存占用,但是这会增加计算量。一个简单的例子是,在前向 forward 期间,不保存所有的激活参数(activations),而只保存它的子集,这样可以减少图3所示的用于特征映射内存占用。未保存的激活参数可以在需要的时候进行重计算,尽管这个方法会增加计算量,但只增加 20% 的计算量,可以减少高达5倍 [2]的内存占用。
还有另一个重要的解决方案是设计足够稳健的、适用于低精度训练的优化算法。事实上,AI 硬件的主要突破之一是支持了半精度(FP16)运算,用以替代单精度运算[5,6]。这使得算力提高了10倍以上。接下来的挑战是,如何在保证准确度不降低的前提下,进一步将精度从半精度降低到 INT8。

高效部署
当部署最新的 SOTA 模型,如 GPT-3 或大型推荐系统模型时,为了推理,常常需要做分布式部署,因此相当具有挑战性。可能的解决方案是,通过降低精度(如量化)或移除冗余参数(如剪枝)来压缩推理模型。
量化方法,既可以用于训练,也可以用于推理。虽然量化用于推理是可能做到超低精度级别的,但是用于训练时,想要将精度做到远低于 FP16 的级别是非常困难的。目前,在最小限度影响准确率的前提下,已经可以相对容易地将推理精度量化至 INT4 级别,这使得模型所占空间及延时,减少至原有的 1/8。然而,如何将精度量化至低于 INT4 级别,是一个颇具挑战的问题,也是当前研究的热门领域。
除量化外,剪枝掉模型中冗余的参数也是高效部署的一种办法。在最小限度影响准确率的前提下,目前已经可以使用基于 structured sparsity 的方法剪枝掉高达 30% 的神经元,使用基于 non-structured sparsity 的方法可以剪枝掉高达 80% 的神经元。然而,如果要进一步提高剪枝的比率,则非常困难,常常会导致准确度下降非常多,这该如何解决,还是一个开放问题。

AI 硬件设计的再思考
如何同时提高硬件带宽和算力是一个极具挑战的基本问题,不过,通过牺牲算力来谋求更好的“算力/带宽”平衡点是可行的。事实上,CPU 架构包含了充分优化后的缓存架构,因此在内存带宽受限类问题(如大型推荐系统)上,CPU 的性能表现要明显优于 GPU。然而,当前 CPU 的主要问题是,它的计算能力(FLOPS)与 GPU 和 TPU 这类 AI 芯片相比,要弱一个数量级。个中原因之一,就是 AI 芯片为追求算力最大化,往往在设计时,就考虑移除了一些组件(如缓存层级)来增加更多的计算单元。我们有理由想象,可以有一种架构,处于以上两种极端架构之间:它将使用更高效的缓存,更重要的是,使用更高容量的 DRAM(设计 DRAM 层次结构,不同层次拥有不同带宽)。后者对于解决分布式内存通信瓶颈将非常有帮助。

结论
目前 NLP 中的 SOTA Transformer 类模型的算力需求,以每两年750倍的速率增长,模型参数数量则以每两年240倍的速率增长。相比之下,硬件算力峰值的增长速率为每两年3.1倍。DRAM 还有硬件互连带宽增长速率则都为每两年1.4倍,已经逐渐被需求甩在身后。深入思考这些数字,过去20年内硬件算力峰值增长了90000倍,但是DRAM/硬件互连带宽只增长了30倍。在这个趋势下,数据传输,特别是芯片内或者芯片间的数据传输会迅速成为训练大规模 AI 模型的瓶颈。所以我们需要重新思考 AI 模型的训练,部署以及模型本身,还要思考,如何在这个越来越有挑战性的内存墙下去设计人工智能硬件。
感谢 Suresh Krishna 跟 Aniruddha Nrusimha 给出的非常有价值的回答。
[1] 我们特意没有把强化学习的计算代价放入图中,因为它的训练代价大多跟模拟的环境有关,而现阶段并没有标准的模拟环境。值得注意的是,在我们的报告中用了训练模型需要的运算数而不是硬件部署使用的多少,因为后者依赖于具体的库以及使用的硬件。最后,文件里的所有倍率都是用每个图中的数据来进行线性回归得出的。
[2] 图2里面的增长倍率是用转化训练模型(也就是图中的蓝色圆点)算出来的,而不是用推荐系统算出来的。
[3] 对于能够训练的最大模型,GPU 的内存是取对应内存大小除以6来得到的一个大概的上界。
[4] 我们用 R10000系统来变准话算力峰值,因为它在文献[24]中被用于报告训练Lenet-5的计算代价。
原文链接:https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8
译文链接:https://blog.csdn.net/OneFlow_Official/article/details/115549991

生于2001年的《程序员》曾陪伴了无数开发者成长,影响了一代又一代的中国技术人。时隔20年,《新程序员》带着全球技术大师深邃思考、优秀开发者技术创造等深度内容回来了!同时将全方位为所有开发者呈现国内外核心技术生态体系全景图。扫描下方小程序码即可立即订阅!
加入新程序员读者俱乐部:
- 季度会员:https://mall.csdn.net/item/76421?spm=1235995414
- 年度会员:https://mall.csdn.net/item/76785?spm=170298316
移动端的同学也可以扫码下方二维码加入

以上是关于AI算力的阿喀琉斯之踵:内存墙的主要内容,如果未能解决你的问题,请参考以下文章