图解 SQL 执行顺序,通俗易懂!
Posted Java技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解 SQL 执行顺序,通俗易懂!相关的知识,希望对你有一定的参考价值。
这是一条标准的查询语句:
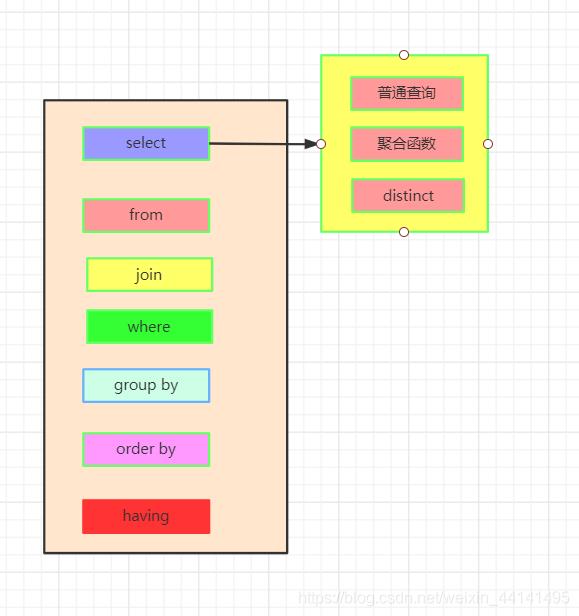
这是我们实际上SQL执行顺序:
- 我们先执行from,join来确定表之间的连接关系,得到初步的数据
- where对数据进行普通的初步的筛选
- group by 分组
- 各组分别执行having中的普通筛选或者聚合函数筛选。
- 然后把再根据我们要的数据进行select,可以是普通字段查询也可以是获取聚合函数的查询结果,如果是集合函数,select的查询结果会新增一条字段
- 将查询结果去重distinct
- 最后合并各组的查询结果,按照order by的条件进行排序
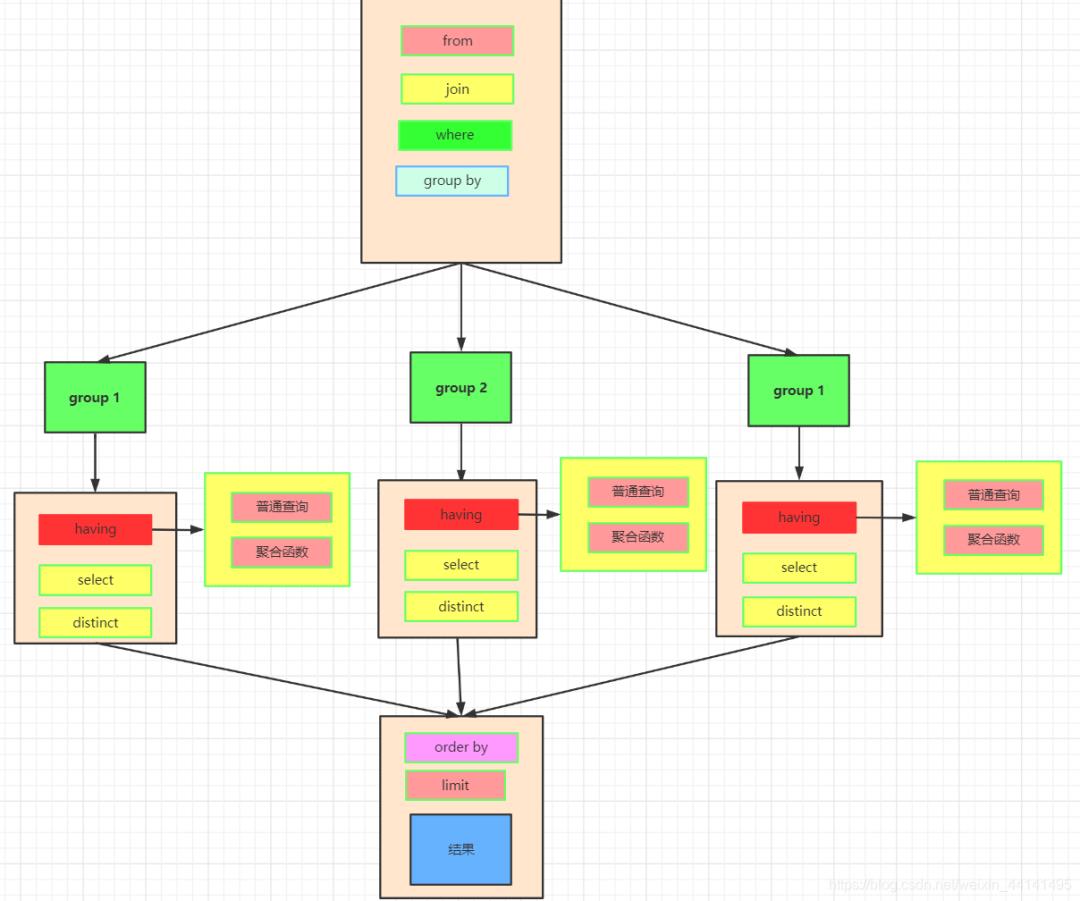
数据的关联过程
数据库中的两张表
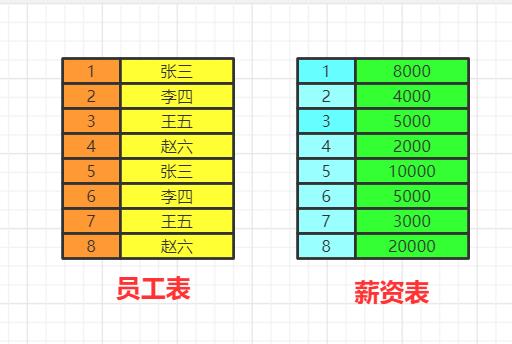
from&join&where
用于确定我们要查询的表的范围,涉及哪些表。
选择一张表,然后用join连接
from table1 join table2 on table1.id=table2.id
选择多张表,用where做关联条件
from table1,table2 where table1.id=table2.id
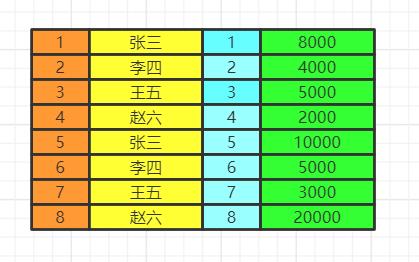
我们会得到满足关联条件的两张表的数据,不加关联条件会出现笛卡尔积。
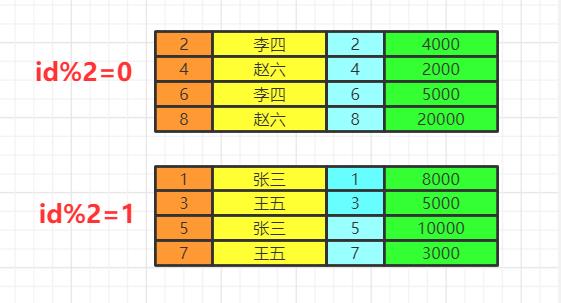
group by
按照我们的分组条件,将数据进行分组,但是不会筛选数据。
比如我们按照即id的奇偶分组
having&where
having中可以是普通条件的筛选,也能是聚合函数。而where只能是普通函数,一般情况下,有having可以不写where,把where的筛选放在having里,SQL语句看上去更丝滑。
使用where再group by
先把不满足where条件的数据删除,再去分组
使用group by再having
先分组再删除不满足having条件的数据,这两种方法有区别吗,几乎没有!
举个例子:
100/2=50,此时我们把100拆分
(10+10+10+10+10…)/2=5+5+5+…+5=50,只要筛选条件没变,即便是分组了也得满足筛选条件,所以where后group by 和group by再having是不影响结果的!
不同的是,having语法支持聚合函数,其实having的意思就是针对每组的条件进行筛选。我们之前看到了普通的筛选条件是不影响的,但是having还支持聚合函数,这是where无法实现的。
当前数据分组情况
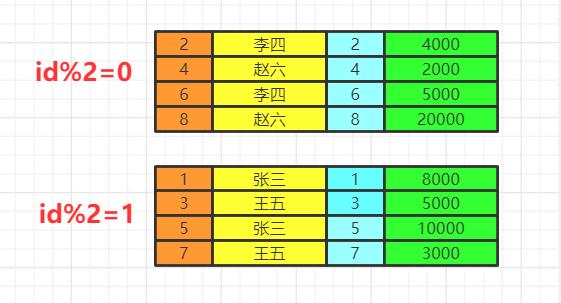
执行having的筛选条件,可以使用聚合函数。筛选掉工资小于各组平均工资的having salary<avg(salary)

select
分组结束之后,我们再执行select语句,因为聚合函数是依赖于分组的,聚合函数会单独新增一个查询出来的字段,这里用紫色表示,这里我们两个id重复了,我们就保留一个id,重复字段名需要指向来自哪张表,否则会出现唯一性问题。最后按照用户名去重。
select employee.id,distinct name,salary, avg(salary)
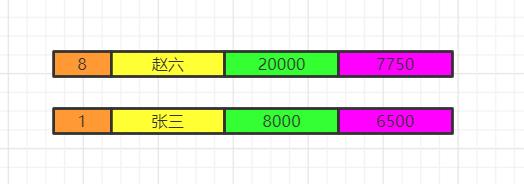
将各组having之后的数据再合并数据。
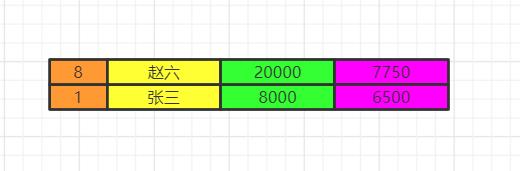
order by
最后我们执行order by 将数据按照一定顺序排序,比如这里按照id排序。如果此时有limit那么查询到相应的我们需要的记录数时,就不继续往下查了。
limit
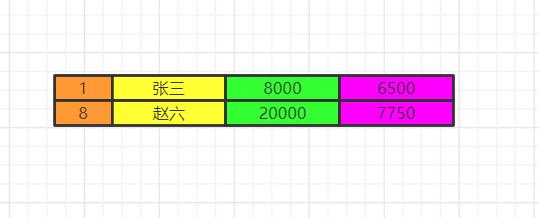
记住limit是最后查询的,为什么呢?假如我们要查询年级最小的三个数据,如果在排序之前就截取到3个数据。实际上查询出来的不是最小的三个数据而是前三个数据了,记住这一点。
我们如果limit 0,3窃取前三个数据再排序,实际上最少工资的是2000,3000,4000。你这里只能是4000,5000,8000了。
原文链接:https://blog.csdn.net/weixin_44141495/article/details/108744720
版权声明:本文为CSDN博主「程序员小章」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2022最新版)
4.别再写满屏的爆爆爆炸类了,试试装饰器模式,这才是优雅的方式!!
觉得不错,别忘了随手点赞+转发哦!
图解堆和堆排序通俗易懂
堆
堆的定义
堆是计算机科学中一类特殊的数据结构的统称,堆通常可以被看做是一棵完全二叉树的数组对象。
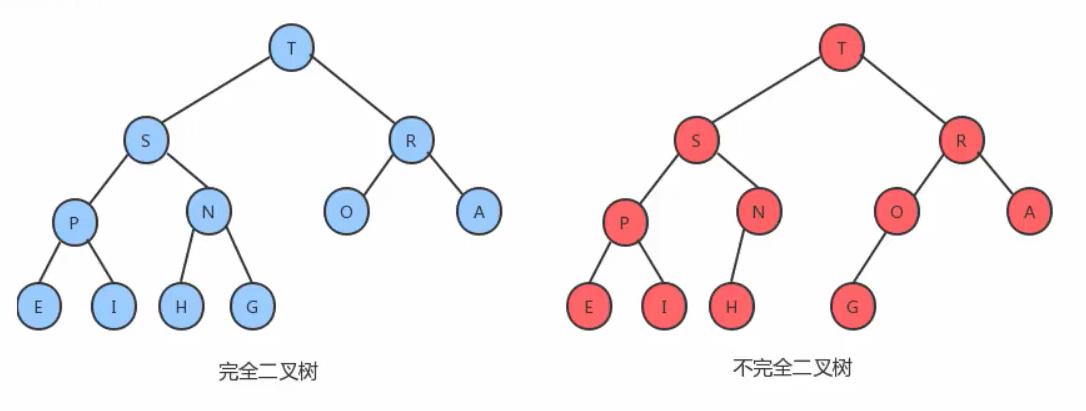
从定义上来看堆也是一种树但是必须是完全二叉树,完全二叉树定义:
是一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
我们看如下图所示:左边的是一个完全二叉树,右边的不是,如何判断是不是一棵完全二叉树我们看下面堆的性质1
堆的特性:
1.它是完全二叉树,除了树的最后一层结点不需要是满的,其它的每一层从左到右都是满的,如果最后一层结点不是满的,那么要求左满右不满。
2.它通常用数组来实现。
具体方法就是将二叉树的结点按照层级顺序放入数组中,根结点在位置1,它的子结点在位置2和3,而子结点的子结点则分别在位置4,5,6和7,以此类推。0索引处不存数据因为将数据从第一个开始存储方便我们表示父节点和子节点的关系
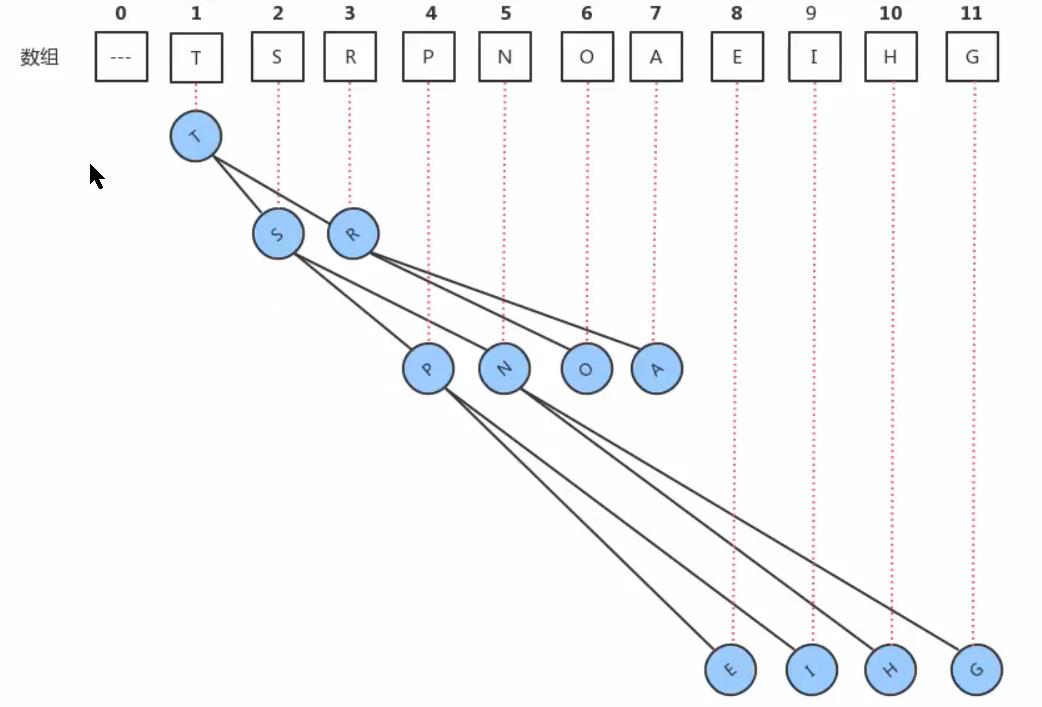
如果一个结点的位置为k,则它的父结点的位置为[k/2],而它的两个子结点的位置则分别为2k和2k+1。这样,在不使用指针的情况下,我们也可以通过计算数组的索引在树中上下移动:从a[k]向上一层,就令k等于k/2,向下一层就令k等于2k或2k+1。
3.每个结点都大于等于它的两个子结点。这里要注意堆中仅仅规定了每个结点大于等于它的两个子结点,但这两个子结点的顺序并没有做规定,这一点与二叉查找树是有区别的。
堆的实现
API设计
insert插入方法的实现
堆是用数组完成数据元素的存储的,由于数组的底层是一串连续的内存地址,所以我们要往堆中插入数据,我们只能往数组中从索引0处开始,依次往后存放数据,但是堆中对元素的顺序是有要求的,每一个结点的数据要大于等于它的两个子结点的数据,所以每次插入一个元素,都会使得堆中的数据顺序变乱,这个时候我们就需要通过一些方法让刚才插入的这个数据放入到合适的位置。那么该方法便是swim方法使索引k处的元素能在堆中处于一个正确的位置。我们来看一个向堆中插入元素的上浮过程。
初始堆如下
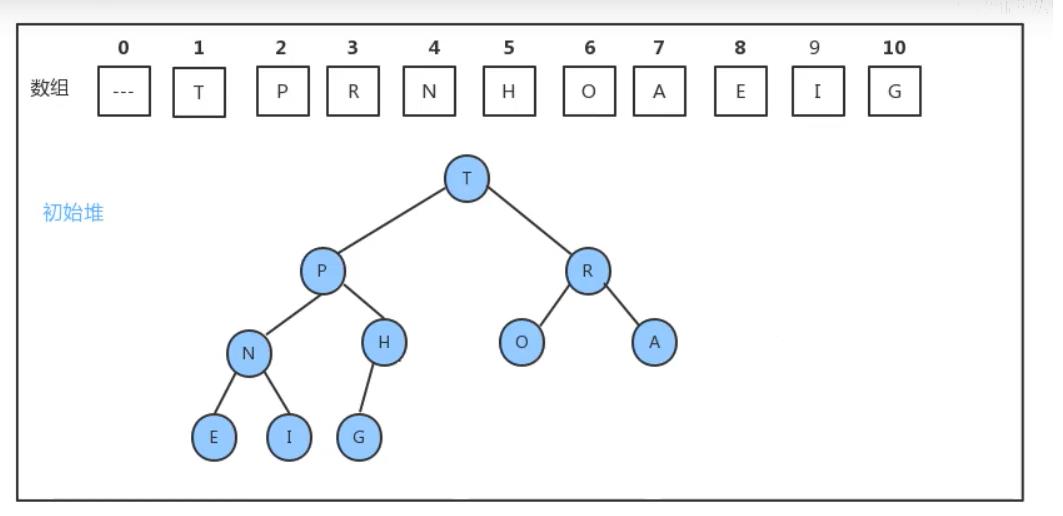
此时要插入一个元素S那么该如何插入呢?为了满足堆的性质我们只能在H的右结点处插入
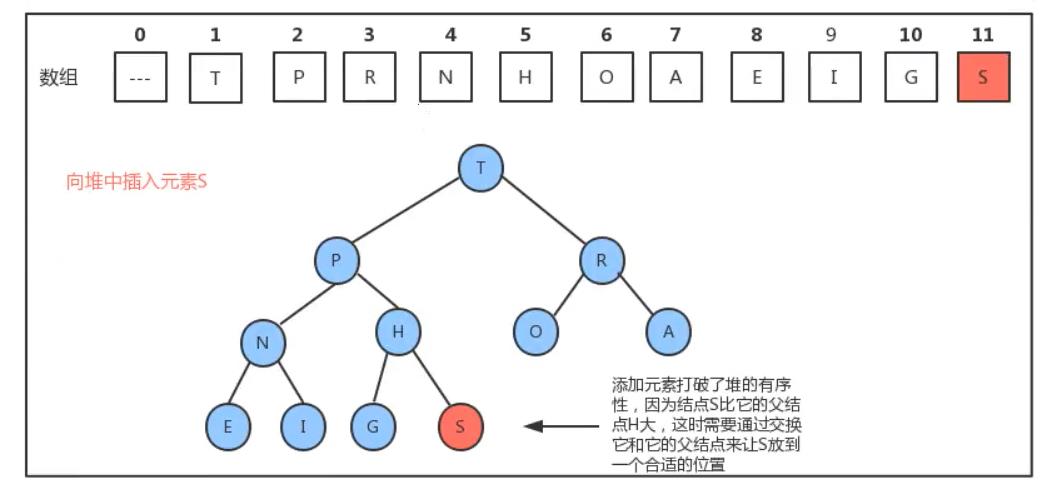
插入S后我们发现S比他的父节点H要大所以我们需要交换S和H的位置
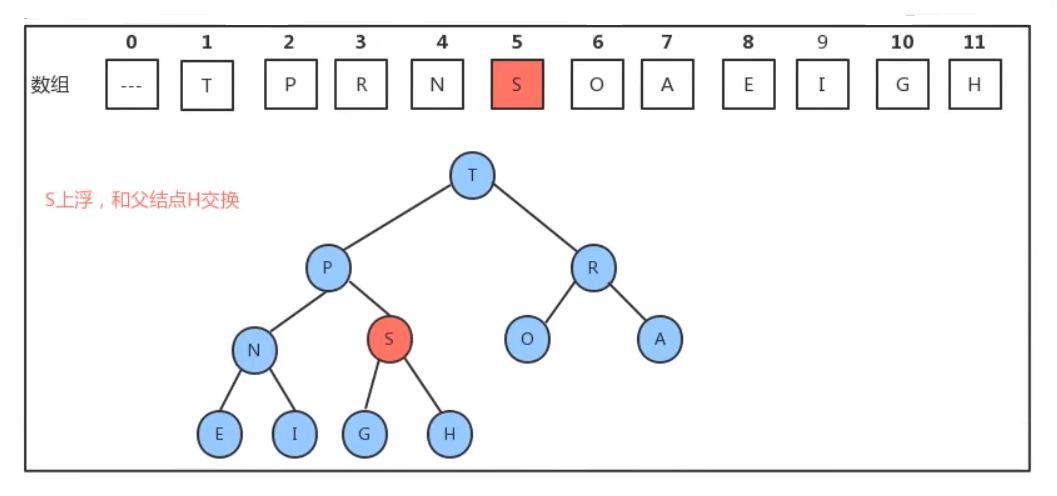
S继续和其父节点P进行比较S比P大则继续交换得到如下所示

此时S比其父节点T要小故不用交换,所以便完成了元素的插入。因此,如果要往堆中新插入元素,我们只需要不断的比较新结点a[k]和它的父结点a[k/2]的大小,然后根据结果完成数据元素的交换,就可以完成堆的有序调整。
将上诉过程转换为代码如下:
//往堆中插入一个元素
public void insert(T t){
//因为我们是从索引为1的位置开始存数据故先++N
items[++N]=t;
swim(N);
}
//使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置
private void swim(int k){
//通过循环,不断的比较当前结点的值和其父结点的值,
//如果发现父结点的值比当前结点的值小,则交换位置
while(k>1){
//比较当前结点和其父结点
if (less(k/2,k)){
exch(k/2,k);
}
k = k/2;
}
}
delMax删除最大元素方法的实现
由堆的特性我们可以知道,索引1处的元素,也就是根结点就是最大的元素,当我们把根结点的元素删除后,需要有一个新的根结点出现,这时我们可以暂时把堆中最后一个元素放到索引1处,充当根结点,但是它有可能不满足堆的有序性需求,这个时候我们就需要使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置,让这个新的根结点放入到合适的位置。
初始堆如下:
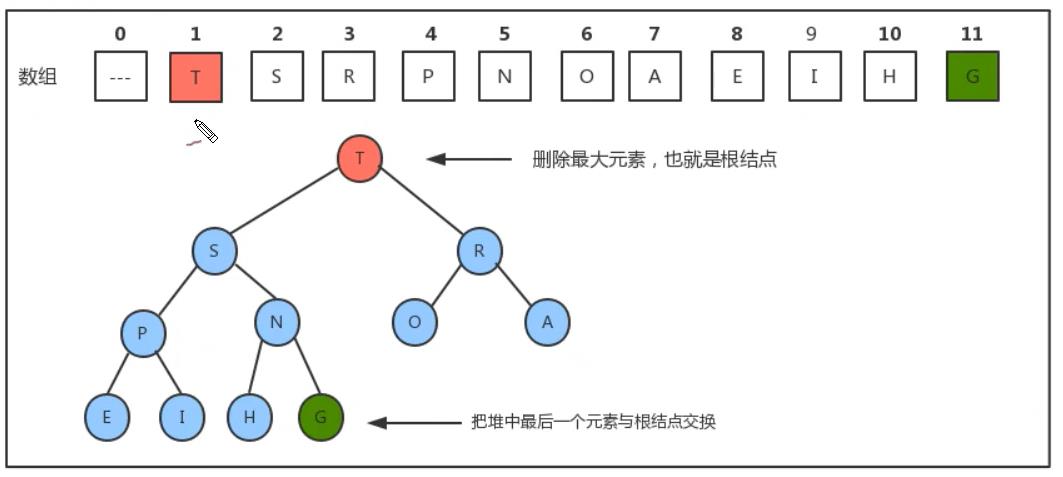
删除最大元素T,最大元素即为根结点,删除了根元素之后那么树便成了左右两棵树即变成了森林,所以删除掉根元素后我们需要找一个元素来替换根元素。可能我们一开始想到的是其子节点,其实是不妥的因为左右节点不知道哪个大,而且交换后树的结构更乱了。因此我们可以把根结点与最后一个结点交换。交换后再把根结点删除,删除后此时的堆也是无序的。
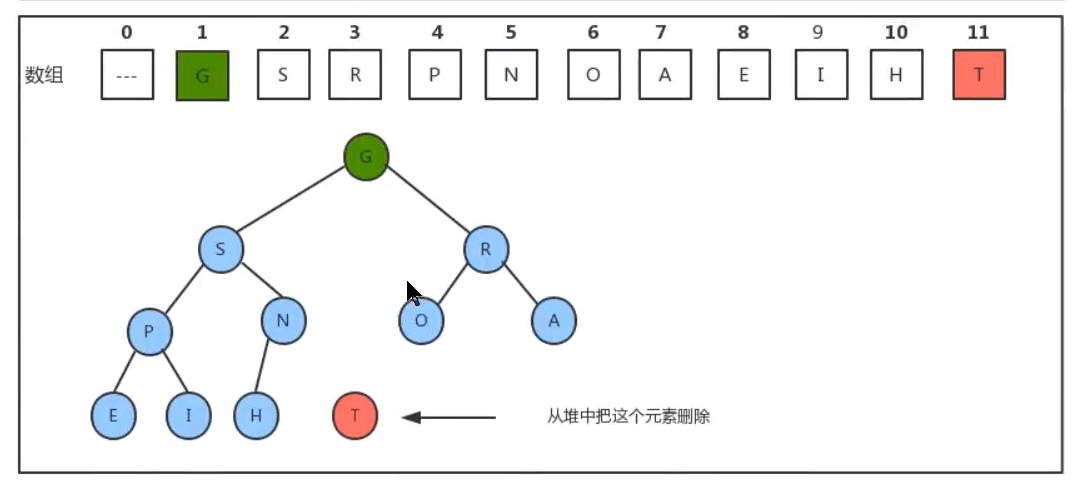
我们需要对堆做出调整,我们只需要找出原来结点的左右子结点中最大的然后与当前结点比较如果当前节点比他大则位置不需要变化,如果要小则最大的结点与当前结点交换。
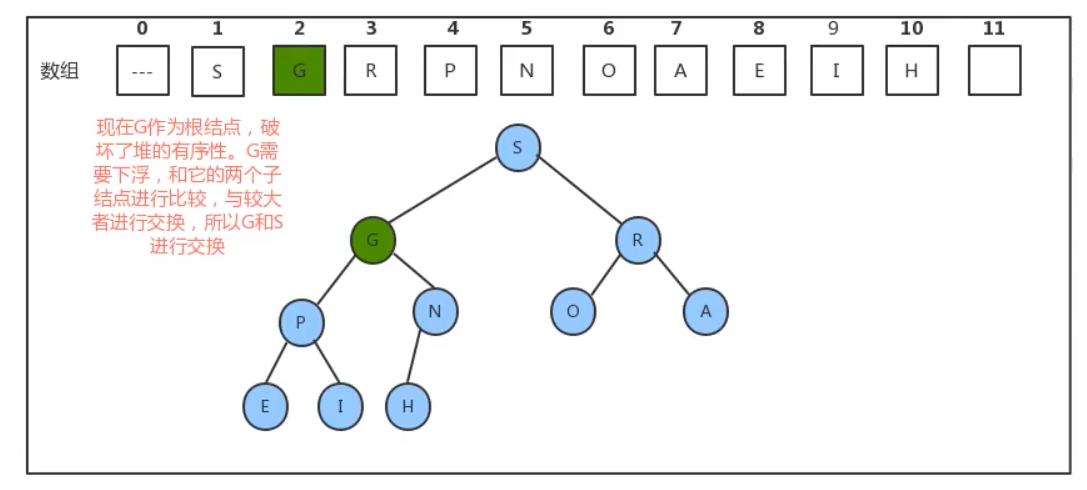
GS交换后此时仍然需要继续比较G与其子结点的大小继续比较。
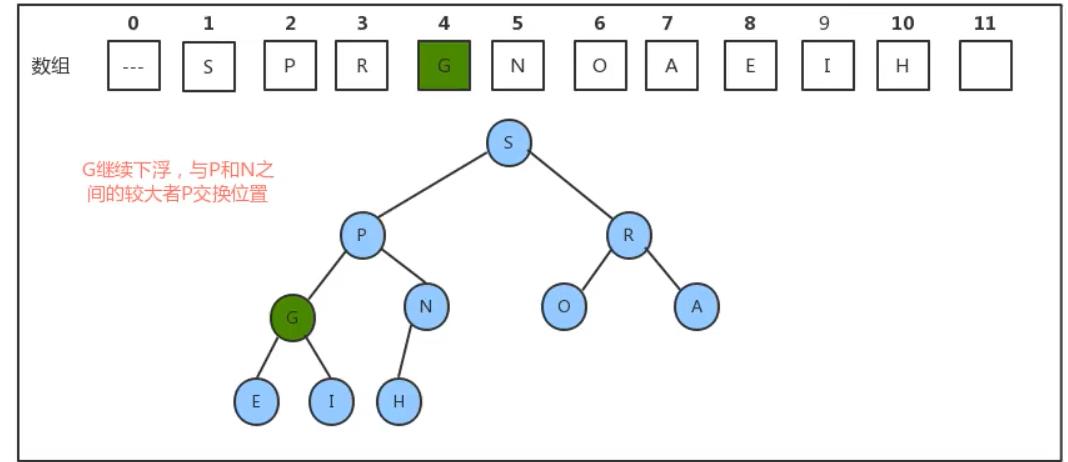
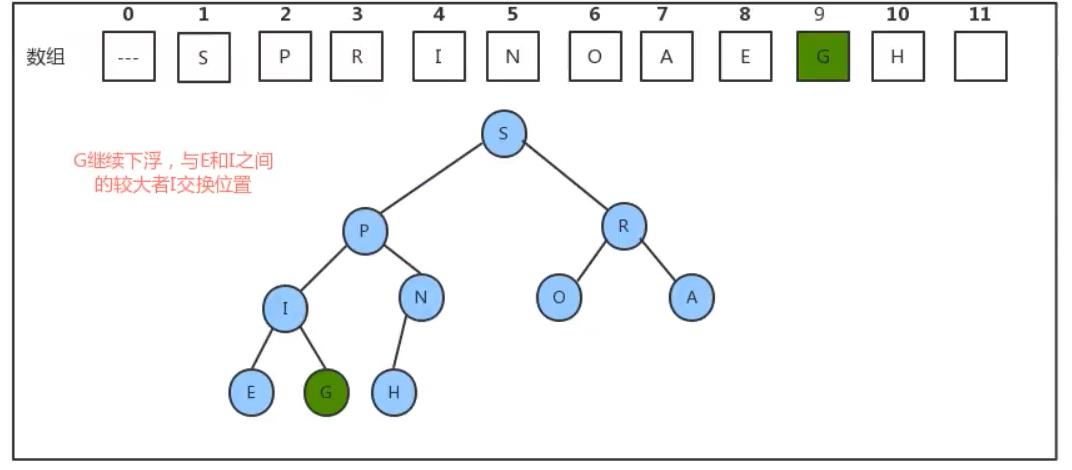 所以,当删除掉最大元素后,只需要将最后一个元素放到索引1处,并不断的拿着当前结点a[k]与它的子结点a[2k]和a[2k+1]中的较大者交换位置,即可完成堆的有序调整。
所以,当删除掉最大元素后,只需要将最后一个元素放到索引1处,并不断的拿着当前结点a[k]与它的子结点a[2k]和a[2k+1]中的较大者交换位置,即可完成堆的有序调整。
代码实现如下
//删除堆中最大的元素,并返回这个最大元素
public T delMax(){
T max = items[1];
//交换索引1处的元素和最大索引处的元素,
//让完全二叉树中最右侧的元素变为临时根结点
exch(1,N);
//最大索引处的元素删除掉
items[N]=null;
//元素个数-1
N--;
//通过下沉调整堆,让堆重新有序
sink(1);
return max;
}
//使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置
private void sink(int k){
//通过循环不断的对比当前k结点和其左子结点2*k以及右子结点2k+1处
//中的较大值的元素大小,如果当前结点小,则需要交换位置
while(2*k<=N){
//获取当前结点的子结点中的较大结点
int max;//记录较大结点所在的索引
if (2*k+1<=N){
if (less(2*k,2*k+1)){
max=2*k+1;
}else{
max=2*k;
}
}else {
max = 2*k;
}
//比较当前结点和较大结点的值
if (!less(k,max)){
break;
}
//交换k索引处的值和max索引处的值
exch(k,max);
//变换k的值
k = max;
}
整个堆的完整代码如下:
public class Heap<T extends Comparable<T>> {
//存储堆中的元素
private T[] items;
//记录堆中元素的个数
private int N;
public Heap(int capacity) {
this.items= (T[]) new Comparable[capacity+1];
this.N=0;
}
//判断堆中索引i处的元素是否小于索引j处的元素
private boolean less(int i,int j){
return items[i].compareTo(items[j])<0;
}
//交换堆中i索引和j索引处的值
private void exch(int i,int j){
T temp = items[i];
items[i] = items[j];
items[j] = temp;
}
//往堆中插入一个元素
public void insert(T t){
items[++N]=t;
swim(N);
}
//使用上浮算法,使索引k处的元素能在堆中处于一个正确的位置
private void swim(int k){
//通过循环,不断的比较当前结点的值和其父结点的值,
//如果发现父结点的值比当前结点的值小,则交换位置
while(k>1){
//比较当前结点和其父结点
if (less(k/2,k)){
exch(k/2,k);
}
k = k/2;
}
}
//删除堆中最大的元素,并返回这个最大元素
public T delMax(){
T max = items[1];
//交换索引1处的元素和最大索引处的元素,
//让完全二叉树中最右侧的元素变为临时根结点
exch(1,N);
//最大索引处的元素删除掉
items[N]=null;
//元素个数-1
N--;
//通过下沉调整堆,让堆重新有序
sink(1);
return max;
}
//使用下沉算法,使索引k处的元素能在堆中处于一个正确的位置
private void sink(int k){
//通过循环不断的对比当前k结点和其左子结点2*k以及右子结点2k+1处
//中的较大值的元素大小,如果当前结点小,则需要交换位置
while(2*k<=N){
//获取当前结点的子结点中的较大结点
int max;//记录较大结点所在的索引
if (2*k+1<=N){
if (less(2*k,2*k+1)){
max=2*k+1;
}else{
max=2*k;
}
}else {
max = 2*k;
}
//比较当前结点和较大结点的值
if (!less(k,max)){
break;
}
//交换k索引处的值和max索引处的值
exch(k,max);
//变换k的值
k = max;
}
}
public static void main(String[] args) {
Heap<String> heap = new Heap<String>(20);
heap.insert("A");
heap.insert("B");
heap.insert("C");
heap.insert("D");
heap.insert("E");
heap.insert("F");
heap.insert("G");
String del;
while((del=heap.delMax())!=null){
System.out.print(del+",");
}
}
测试结果:
G,F,E,D,C,B,A,
堆排序
问题引入
给定一个数组:
String[] arr = {“S”,“O”,“R”,“T”,“E”,“X”,“A”,“M”,“P”,“L”,“E”}
请对数组中的字符按从小到大排序。
实现步骤:
- 构造堆;
- 得到堆顶元素,这个值就是最大值;
- 交换堆顶元素和数组中的最后一个元素,此时所有元素中的最大元素已经放到合适的位置;
- 对堆进行调整,重新让除了最后一个元素的剩余元素中的最大值放到堆顶;
- 重复2~4这个步骤,直到堆中剩一个元素为止。
堆构建过程
堆的构造,最直观的想法就是另外再创建一个和新数组数组,然后从左往右遍历原数组,每得到一个元素后,添加到新数组中,并通过上浮,对堆进行调整,最后新的数组就是一个堆。
上述的方式虽然很直观,也很简单,但是我们可以用更巧妙一点的办法完成它。创建一个新数组,把原数组0-length-1的数据拷贝到新数组的1~length处,再从新数组长度的一半处开始往1索引处扫描(从右往左)(因为堆的性质是知道一个节点便可以知道其两个子节点),然后对扫描到的每一个元素做下沉调整即可。具体看下面图解
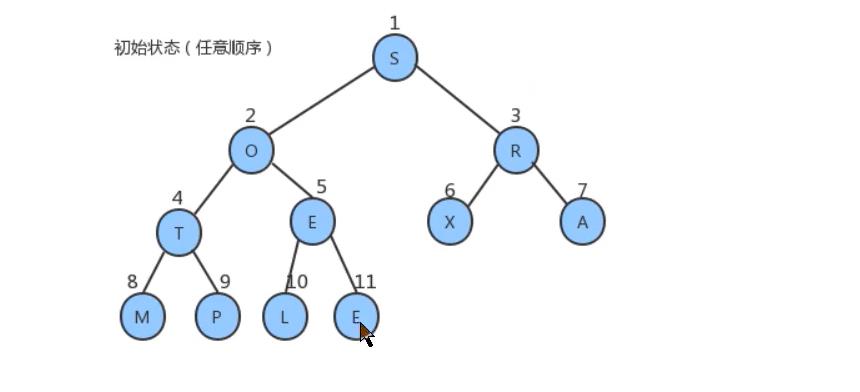
从新数组长度的一半处开始往1索引处扫描,即从5处开始扫描L比E大交换位置
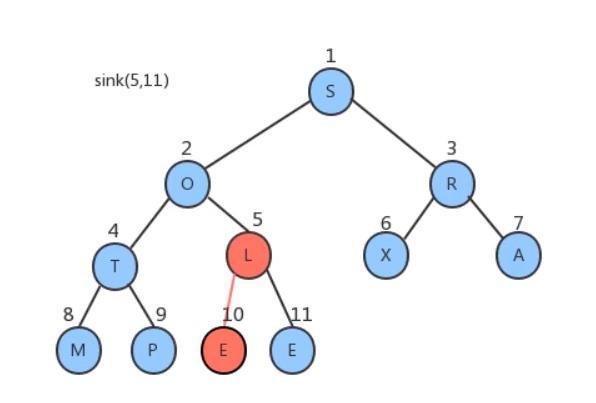
索引4处T比其子节点MP都大故不需要移动
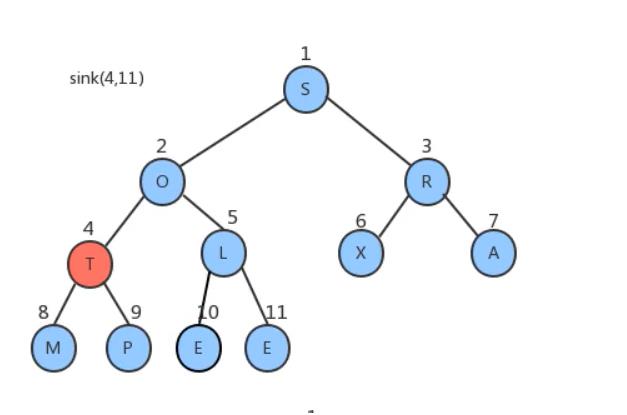
索引3处R比其两个子节点大也不需要移动
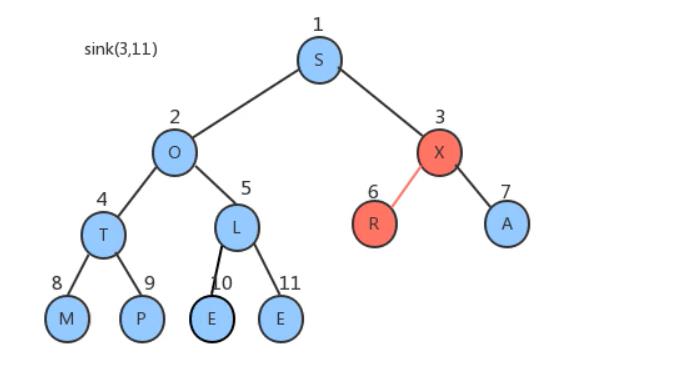
索引2处T比其两个子节点大也不需要移动
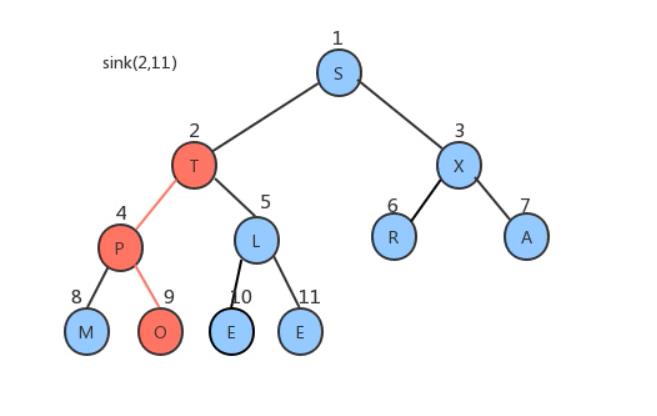
索引1处X比其两个子节点大也不需要移动
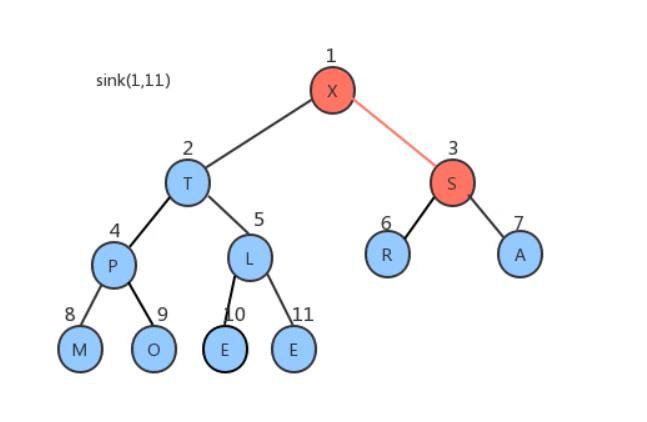
经过5次比较后堆便构建好了我们用代码将该过程实现
//根据原数组source,构造出堆heap
private static void createHeap(Comparable[] source, Comparable[] heap) {
//把source中的元素拷贝到heap中,heap中的元素就形成一个无序的堆
System.arraycopy(source,0,heap,1,source.length);
//对堆中的元素做下沉调整(从长度的一半处开始,往索引1处扫描)
for (int i = (heap.length)/2;i>0;i--){
sink(heap,i,heap.length-1);
}
}
//在heap堆中,对target处的元素做下沉,范围是0~range
private static void sink(Comparable[] heap,
int target, int range){
while(2*target<=range){
//1.找出当前结点的较大的子结点
int max;
if (2*target+1<=range){
if (less(heap,2*target,2*target+1)){
max = 2*target+1;
}else{
max = 2*target;
}
}else{
max = 2*target;
}
//2.比较当前结点的值和较大子结点的值
if (!less(heap,target,max)){
break;
}
exch(heap,target,max);
target = max;
}
}
堆排序过程
- 将堆顶元素和堆中最后一个元素交换位置;
- 通过对堆顶元素下沉调整堆,把最大的元素放到堆顶(此时最后一个元素不参与堆的调整,因为最大的数据已经到了数组的最右边)
- 重复1~2步骤,直到堆中剩最后一个元素。
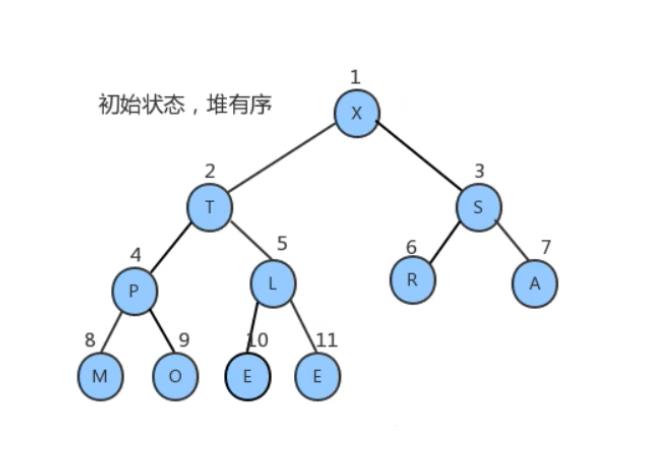
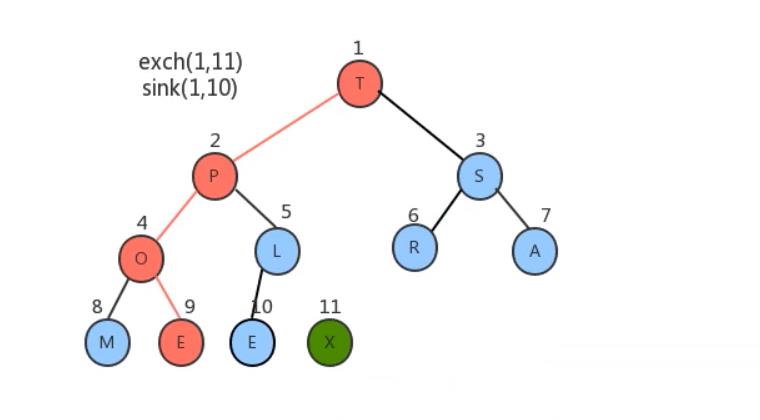

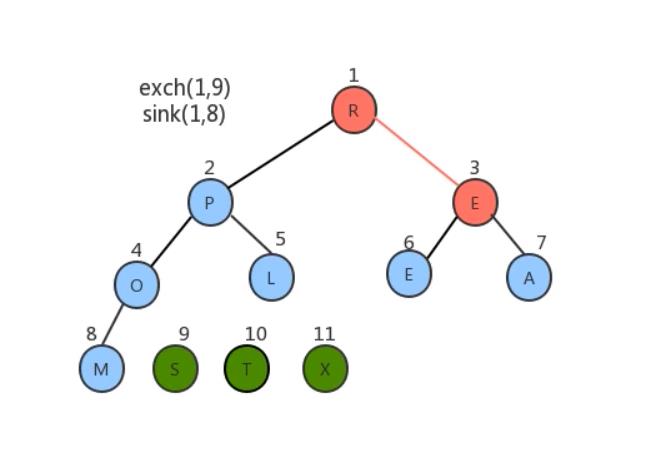
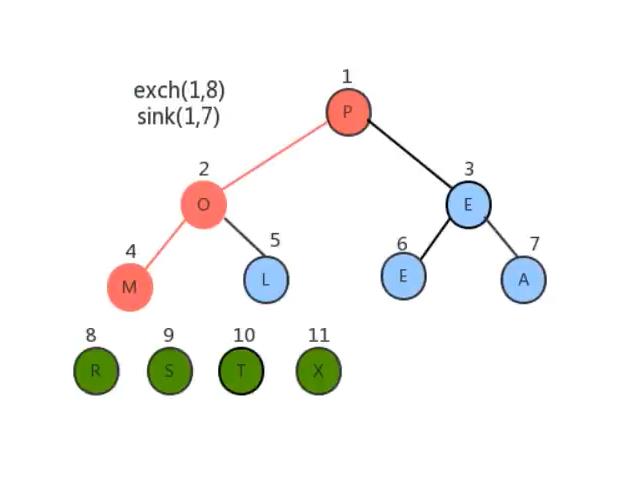
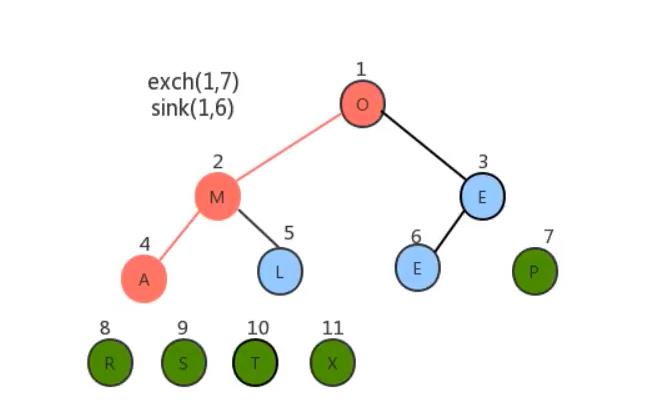

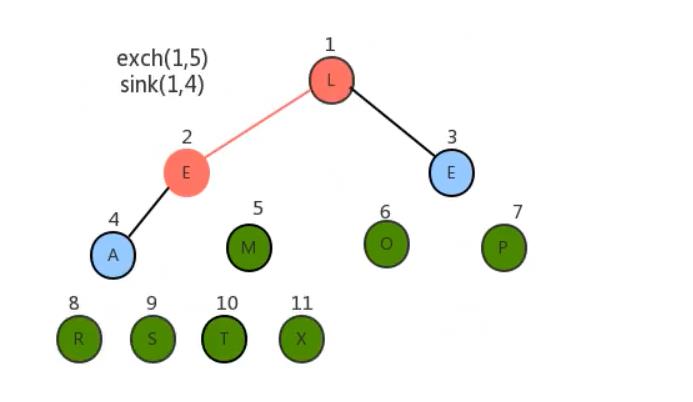
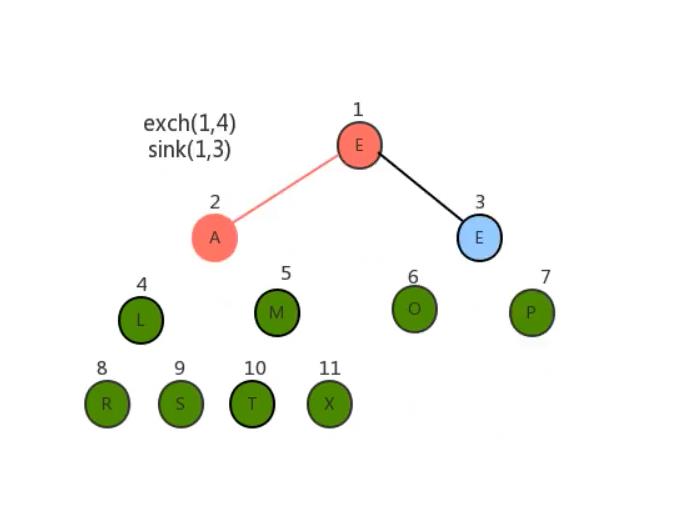
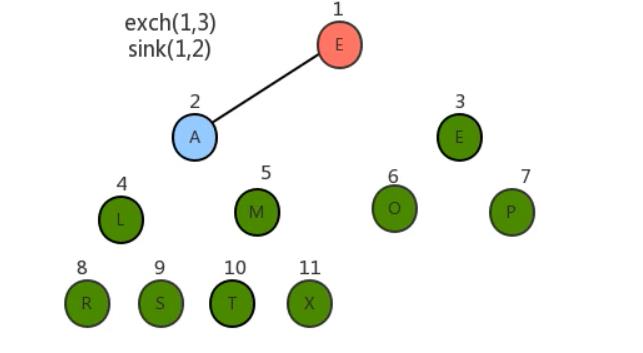
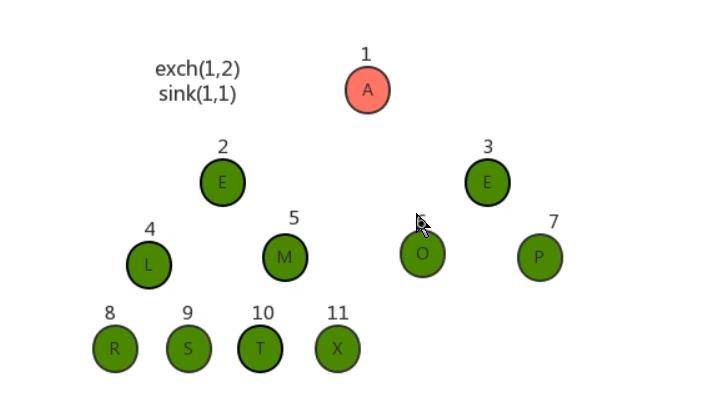
经过上面的操作后数组已经有序了。我们用代码将其实现。
//对source数组中的数据从小到大排序
public static void sort(Comparable[] source) {
//构建堆
Comparable[] heap = new Comparable[source.length+1];
createHeap(source,heap);
//定义一个变量,记录未排序的元素中最大的索引
int N = heap.length-1;
//通过循环,交换1索引处的元素和排序的元素中最大的索引处的元素
while(N!=1){
//交换元素
exch(heap,1,N);
//排序交换后最大元素所在的索引,让它不要参与堆的下沉调整
N--;
//需要对索引1处的元素进行对的下沉调整
sink(heap,1, N);
}
//把heap中的数据复制到原数组source中
System.arraycopy(heap,1,source,0,source.length);
}
堆排序完整代码
public class HeapSort {
//判断heap堆中索引i处的元素是否小于索引j处的元素
private static boolean less(Comparable[] heap, int i, int j) {
return heap[i].compareTo(heap[j])<0;
}
//交换heap堆中i索引和j索引处的值
private static void exch(Comparable[] heap, int i, int j) {
Comparable tmp = heap[i];
heap[i] = heap[j];
heap[j] = tmp;
}
//根据原数组source,构造出堆heap
private static void createHeap(Comparable[] source, Comparable[] heap) {
//把source中的元素拷贝到heap中,heap中的元素就形成一个无序的堆
System.arraycopy(source,0,heap,1,source.length);
//对堆中的元素做下沉调整(从长度的一半处开始,往索引1处扫描)
for (int i = (heap.length)/2;i>0;i--){
sink(heap,i,heap.length-1);
}
}
//对source数组中的数据从小到大排序
public static void sort(Comparable[] source) {
//构建堆
Comparable[] heap = new Comparable[source.length+1];
createHeap(source,heap);
//定义一个变量,记录未排序的元素中最大的索引
int N = heap.length-1;
//通过循环,交换1索引处的元素和排序的元素中最大的索引处的元素
while(N!=1){
//交换元素
exch(heap,1,N);
//排序交换后最大元素所在的索引,让它不要参与堆的下沉调整
N--;
//需要对索引1处的元素进行对的下沉调整
sink(heap,1, N);
}
//把heap中的数据复制到原数组source中
System.arraycopy(heap,1,source,0,source.length);
}
//在heap堆中,对target处的元素做下沉,范围是0~range
private static void sink(Comparable[] heap, int target, int range){
while(2*target<=range){
//1.找出当前结点的较大的子结点
int max;
if (2*target+1<=range){
if (less(heap,2*target,2*target+1)){
max = 2*target+1;
}else{
max = 2*target;
}
}else{
max = 2*target;
}
//2.比较当前结点的值和较大子结点的值
以上是关于图解 SQL 执行顺序,通俗易懂!的主要内容,如果未能解决你的问题,请参考以下文章