JVM快速入门(图解超级详细通俗易懂)
Posted 小样5411
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM快速入门(图解超级详细通俗易懂)相关的知识,希望对你有一定的参考价值。
目录
前言
本篇是带你快速入门JVM的一篇文章,努力把JVM重点都讲下,并且尽量都讲通俗,干货满满,看完这篇文章,面试时大部分内容都能说出一二。原创不易,如转载,请标明转载处!文章如果哪里说的有纰漏,欢迎评论、交流、指正。
本文涉及以下内容:JVM体系结构、类加载器、双亲委派机制、Native、方法区、堆内存(新生区、老年区、元空间)、GC算法(复制算法、标记清除压缩算法、分代收集算法)
一、JVM体系结构
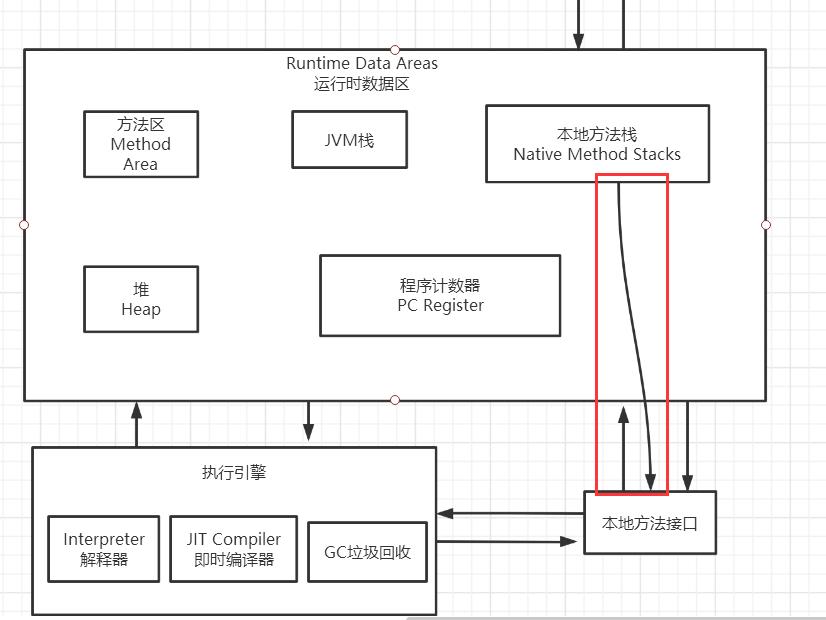
JVM体系结构如下,这个体系结构需要牢牢记住,现在先浏览一遍,等全学完后基本这幅图也记得挺牢了,注意这里不要把体系结构和内存模型搞混,先来讲JVM体系架构。
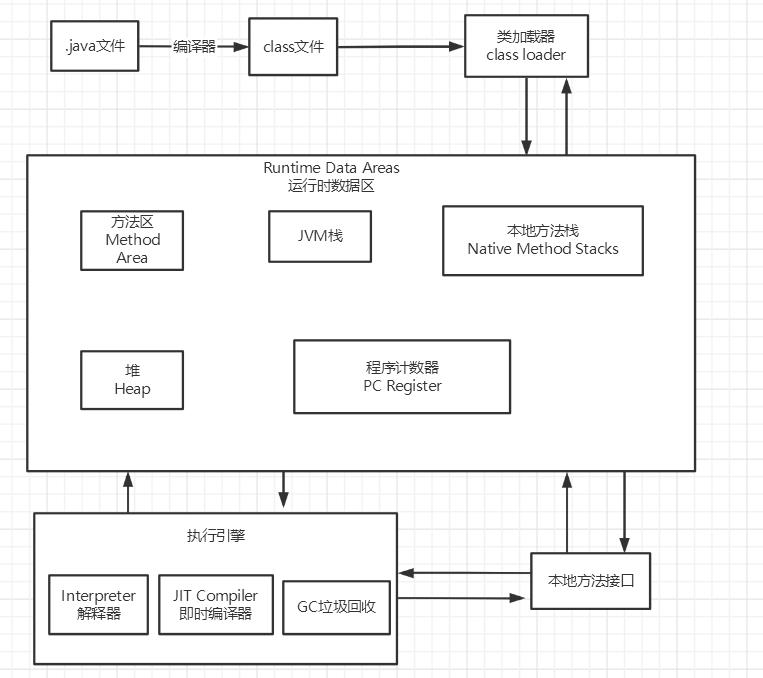
分析:
假设有一个Student.java文件,里面有两个属性name和age,然后还有一个Main.java文件,其中写了Student stu = new Student();这一条代码,运行Main.java来看看整个执行过程,通过执行过程来了解JVM,先上一副宏观图
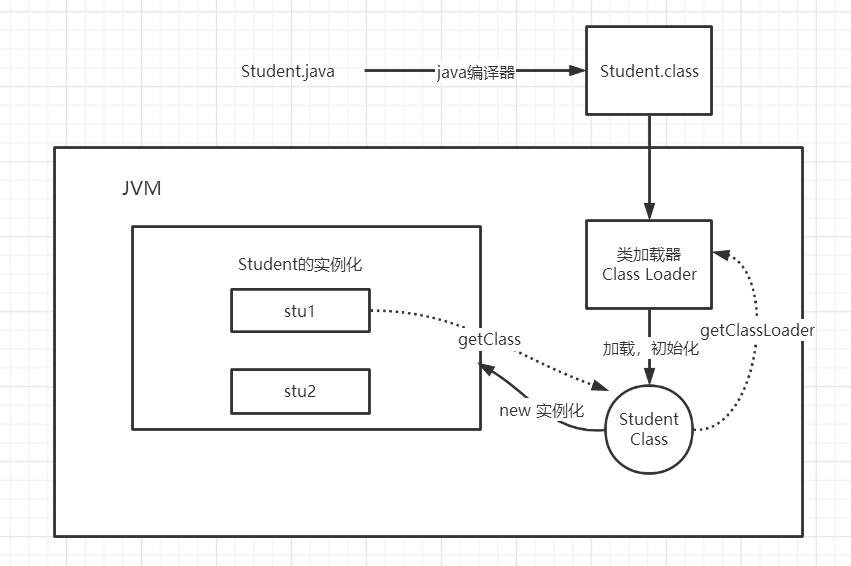
首先java源代码会被编译器编译成字节码文件,也就是.class文件,然后字节码文件通类加载器(Class Loader)加载并初始化,加载与初始化完毕后就会变成一个Class。如图,加载后会得到Student的Class对象,也就是Student的Class反射对象
我们都知道Student.class是全局唯一的,就是不管new多少个对象,对象的Class都是唯一,如下面代码执行后结果
public class Main {
public static void main(String[] args) {
// Class<Student> studentClass = Student.class;
Student stu1 = new Student();
Student stu2 = new Student();
Student stu3 = new Student();
System.out.println(stu1);
System.out.println(stu2);
System.out.println(stu3);
System.out.println("------------------");
System.out.println(stu1.getClass());
System.out.println(stu2.getClass());
System.out.println(stu3.getClass());
}
}

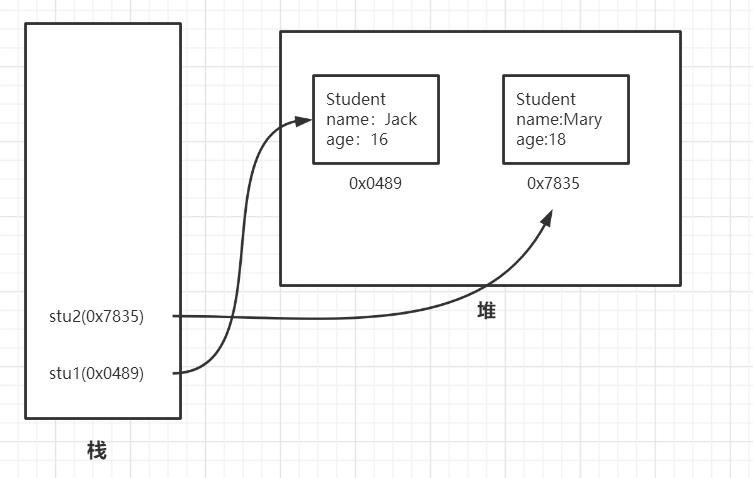
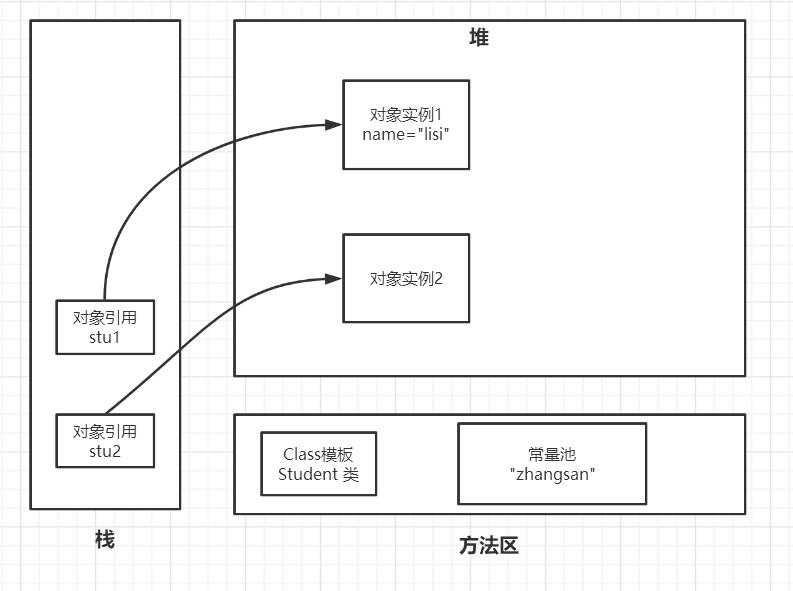
然后加载后变为Student Class,也就是Student类,这里回顾一下new Student()过程:Student是一个抽象类,用new关键字实例化,变成具体对象,栈中存放的是实例化对象的引用,实例化的对象就放在堆中,这是面向对象讲的知识,可能大家不记得了,画图给大家理解一下。
Student stu1 = new Student();
stu1.name='Jack'
stu1.age=16
Student stu2 = new Student();
stu2.name='Mary'
stu2.age=18
实例化两个对象,对象假设有name和age两个属性,stu1和stu2记录的就是对象的引用,指向堆中存放的对象。
 实例化stu1,stu2,还可以反向通过getClass方法获取Student Class,Student Class还可以通过getClassLoader方法获取类加载器,如下
实例化stu1,stu2,还可以反向通过getClass方法获取Student Class,Student Class还可以通过getClassLoader方法获取类加载器,如下
public static void main(String[] args) {
Class<Student> studentClass = Student.class;
System.out.println(studentClass.getClassLoader());
}
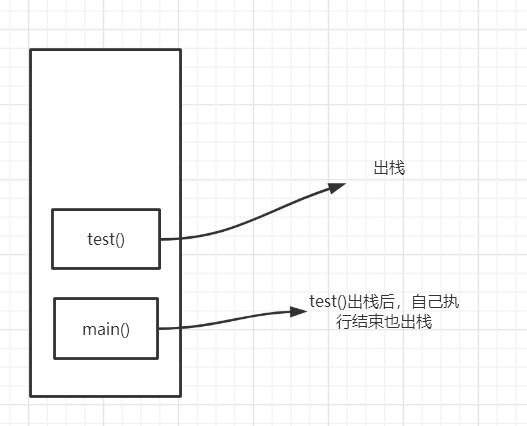
这里再补充一下栈的内容,假设有以下代码,我们看看它怎么在栈中执行的(栈主管程序运行)
public class test1 {
public static void main(String[] args) {
test();
}
private static void test() {
System.out.println("测试");
}
}
首先,先调用main(),于是main()方法入栈,main方法中又调用了一个test方法,于是test()入栈,test方法执行了打印操作结束,于是就出栈,然后回到main中,main也结束,也就是main线程结束,于是main()出栈,程序结束,栈为空,栈就会释放内存。关于栈更深的运行原理就不讲了,有兴趣可以自己查查。
栈中存的东西有哪些呢?8大基本类型、对象引用、实例的方法
加载器也分很多种,也存在父子关系:
1、虚拟机自带的加载器
2、启动类(根)加载器BootStrapLoader
3、扩展类加载器 ExtClassLoader
4、应用程序类加载器 AppClassLoader
执行下面程序
public static void main(String[] args) {
Class<Student> studentClass = Student.class;
System.out.println(studentClass.getClassLoader());//AppClassLoader
System.out.println(studentClass.getClassLoader().getParent());//ExtClassLoader
System.out.println(studentClass.getClassLoader().getParent().getParent());//null 1、不存在 2、java程序获取不到(如用C++写的,java就获取不到,如线程中的new Thread().start底层还是调用一个native修饰的start0(),native修饰就表示java处理不了,要用c++处理)
}

注:有父子类关系,就是子类不能加载,就会往上到其父类,看父类能否加载,不能就再往上,启动类加载器就是最上的了。
为什么要讲多个加载器呢?因为这设计一个重要知识点—双亲委派机制

步骤:
1、类加载器(如AppClassLoader)收到类加载的请求
2、将这个请求向上委托给父类加载器(如ExtClassLoader),一直向上委托,直到启动类加载器
3、启动类(BootStrapLoader)加载器检查是否能加载这个类,能加载就结束,使用当前加载器,否则抛出异常,通知子类加载器进行加载,子类又重复这个过程,不能加载就再找子类,能加载就自己加载,如此往复
总结:App->Ext->Boot,先正向到Boot找,找不到再逆向
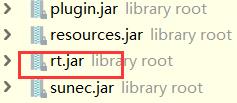
举例:安装的jdk下会有很多库,这个rt就是启动类加载器找是否能加载的地方,看到它下面的一些包和类都是我们常见的。一般我们自己定义的类,比如Student类,先到启动类加载器,启动类加载器肯定没有,因为都是java内置的类,比如java.lang中的Character包装类,自定义的类这里找不到就会到其子类找,最后会到应用程序加载器(AppClassLoader),所以一般自定义的类都是AppClassLoader加载的,这样我们studentClass.getClassLoader()才会打印出AppClassLoader
二、Native、方法区、程序计数器、JVM栈
方法区
方法区是被所有线程共享的,静态变量、常量、类信息、常量池、编译后的代码都存在于方法区中,实例变量存在堆中,和方法区无关
即static,final,Class,常量池
方法区和堆栈一样,和类加载密切相关,类加载后得到Class模板(如Student的Class),实例化过程会用到Class模板去实例化,用这个Class模板实例化的对象放在堆中,而引用就放在栈中,并且引用会指向堆中的对象,而这个Class模板就是放在方法区,如果事先在定义属性时就赋值了一个常量,如Student类中有private String name=“zhangsan”,那么这个字符串就会在常量池,如果是后面在类中以stu1.name="lisi"方式赋值,那么就在堆的对象实例1中,没有stu1.name="lisi"这样的赋值时,则会默认取常量池的,stu1.name="lisi"相当于一个覆盖常量池的name值。方法区属于共享空间,可以被所有线程共享,即所有线程都可以到方法区拿自己需要的东西。
Native
题中三个主要掌握前两个,最后一个了解即可
看下面这段代码,ctrl+点击start,看其源码

会出现下面的源码
public synchronized void start() {
/**
* This method is not invoked for the main method thread or "system"
* group threads created/set up by the VM. Any new functionality added
* to this method in the future may have to also be added to the VM.
*
* A zero status value corresponds to state "NEW".
*/
if (threadStatus != 0)//1、判断是否是新生的线程
throw new IllegalThreadStateException();
/* Notify the group that this thread is about to be started
* so that it can be added to the group's list of threads
* and the group's unstarted count can be decremented. */
group.add(this);//2、新生则添加
boolean started = false;//3、没有启动,started为false
try {
start0();//4、调用start0()启动线程,start=true
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}

可以看到start0()方法,就像一个接口或者抽象类,没有方法体。但是Thread.java不是抽象类啊,怎么能出现抽象方法呢?

这就要说说native关键字了!!!

重点:native关键字修饰的方法其实就是本地方法接口(JNI),凡是带了native关键字的,说明java作用范围达到不了,需要调用底层c语言的库。
再回到执行流程,类加载器加载完毕,并且在栈堆分配结束后,就会进入本地方法栈,这里本地方法栈有调用一个start0方法,而start0()方法java作用不到,不属于Java能处理的范围,就会调用本地方法接口(JNI),因此我们可以提出JNI的作用:扩展java的使用,粘合不同的编程语言为java所用。这是因为java诞生初,c语言和c++十分火热,java想有一席之地就必须要有能调用c、c++的程序,集各方之所长。但如今使用native情况很少了,只有需要调用硬件以及驱动本地的一些东西的时候才要用native,正常情况下不用。
程序计数器(PC寄存器):每一个线程都有一个程序计数器,是线程私有的,每一次执行新的一条指令时都计数+1,它占用的空间是非常非常小的,小到可以忽略不计,上面图画的倒挺大,但是是很小的,在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿,进而恢复继续执行,了解一下上面概念即可。
注意:线程上下文切换(线程切换)就是我们cpu是按照时间片轮转的方式分配时间片给线程执行的,当目前在cpu上运行的线程时间片执行完毕后,此时线程没完全执行完毕,只是时间片用完了,线程就会从运行态转化成为就绪态,再次等待cpu的调度,然后后面就绪的线程获得cpu时间片执行,一小会儿后,之前的线程又等待到cpu的调度了,然后程序计数器记录着上次他执行的状态,将其状态恢复,进而接着上次执行,这就是一次切换。
栈、堆和方法区三个联系总结:一个java文件首先通过编译器(javac.exe),编程字节码文件,然后通过类加载器变成Class模板(抽象的,没有实例化),之后就是实例化过程,栈中放一个引用(一个名字,如stu1),指向堆中的实例化对象,实例化时用到存在方法区中的Class模板,实例对象的属性默认会到常量池中找,实例化后,就会进入本地方法栈,如果本地方法栈实现不了方法(超出java作用范围)就要调用本地方法接口,用本地方法库(如C、C++程序)来实现,但现在这种情况很少。OK,现在运行时数据区中的所有区域都讲了一遍,相信大概都有初步了解,后面会详细学习堆内存(新生代、老年代)的内容。
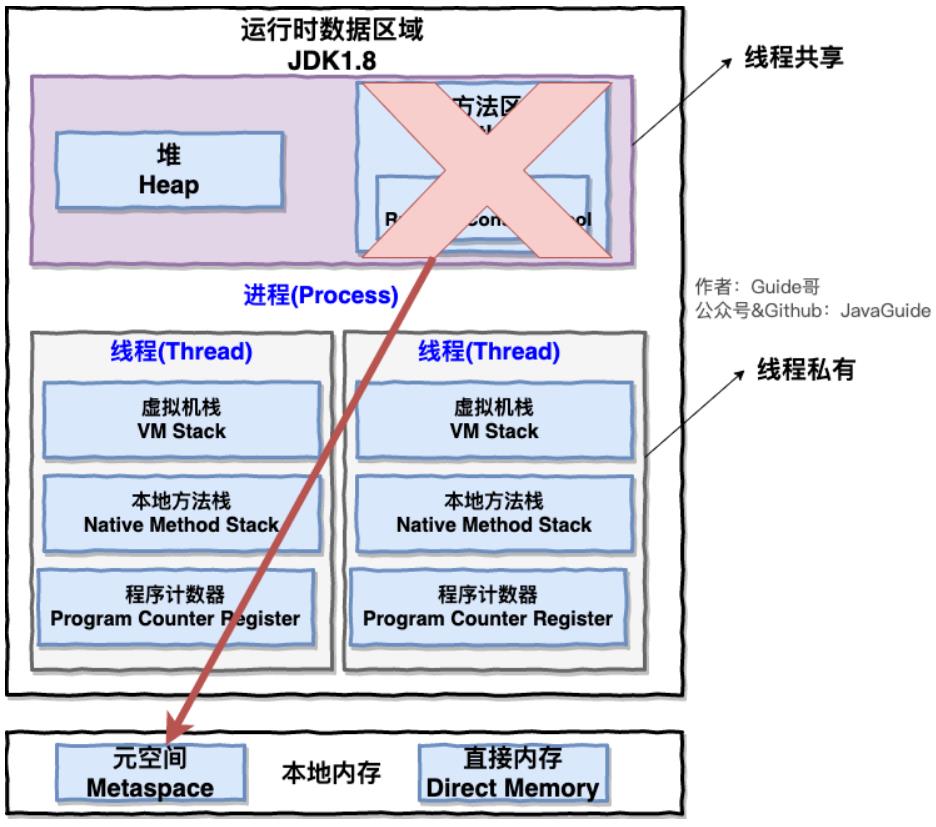
另外运行数据区中,其中堆和方法区是线程共享的,程序计数器,虚拟机栈,本地方法栈三个是线程私有的,如下图,图来自JavaGuide
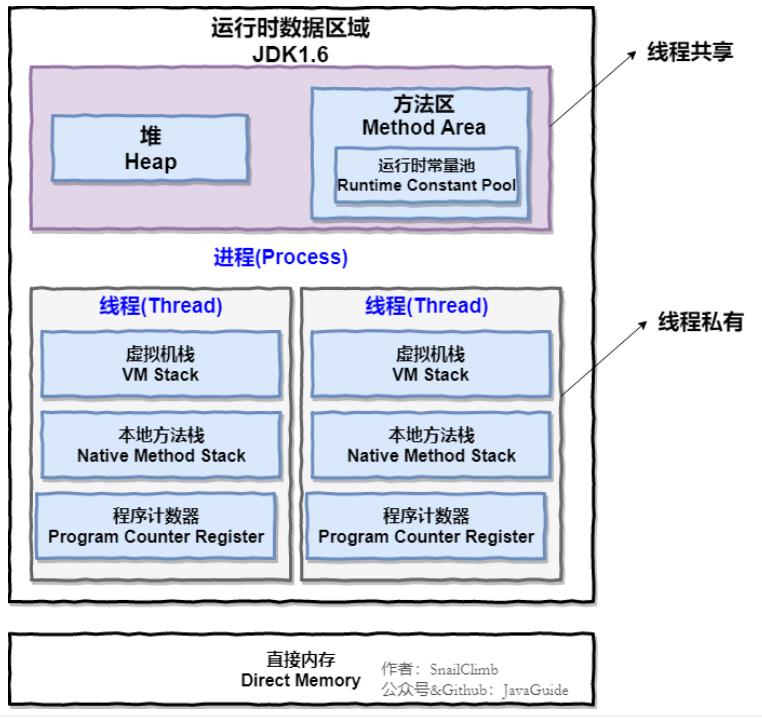
JVM栈(虚拟机栈):每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程,上面画的栈、堆和方法区图中的栈就是指虚拟机栈,不过他用的是JVM栈的局部变量表部分,局部变量表可存放8种基本类型、对象引用。而本地方法栈为虚拟机使用到的 Native 方法服务。
三、走进堆的世界
首先,我们看看自己用的JVM的哪个,其实虚拟机也有很多版本,大多数都用Sun公司的HotSpot,其实IBM、Oracle都有他们自己的JVM和JDK,cmd进入命令窗口,输入java -version命令,可以看到自己用的是(HotSpot),了解即可,然后我们正式将堆。

一个JVM只有一个堆,堆内存的大小可以调节,堆也是垃圾存在最多的地方,也是主要需要调优的地方,相比栈,程序结束,栈内存就被释放了,所以栈不会存在垃圾。
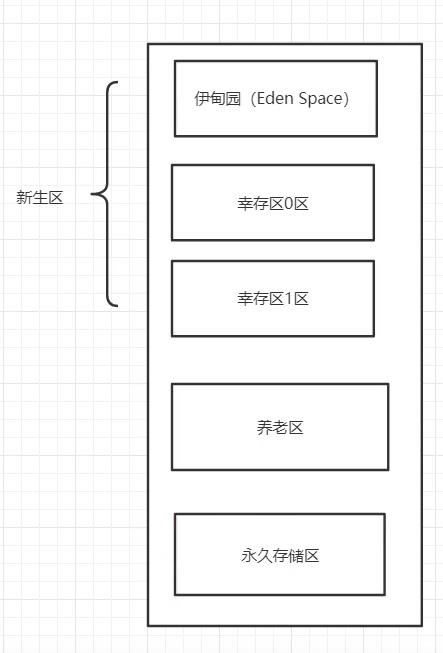
堆中又可以细分为三个区域:新生区,老年区(养老区),永久区(JDK8以后叫元空间)
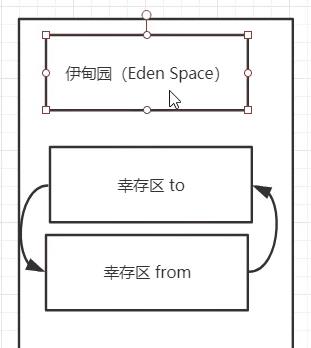
下图即为这三个区域,其中新生区又可以分为三个区,一开始通过new实例化的会在新生区的伊甸园区,然后通过垃圾回收后,没有被回收就会在幸存区,幸存区相当于一个过度区,经过多次垃圾回收都没被回收就会在养老区,GC垃圾回收主要在新生区和老年区,新生区更为频繁,如果新生区创建的过多而满了,老年区也满了,就会发生OOM(内存溢出),后面会详细讲解。
我们来写一个java程序让堆内存满,进而抛出OOM(OutOfMemoryError)异常(堆内存一般不会满,但一满就是个大问题,JVM整个也会跟着崩掉),执行下面程序,一直new,新生区一直增加,并且数字很大,最后导致新生区和老年区都满了,就堆内存溢出了。
注意:在新生区触发的垃圾回收叫轻GC(Garbage Collection),老年区触发的垃圾回收叫重GC
public class test2
{
public static void main(String[] args) {
String str = "abcdefghijklm";
while (true){
str += str+ new Random().nextInt(999999999)+new Random().nextInt(999999999);
}
}
}

分别详细介绍三个区
新生区分伊甸园区、幸存0区、幸存1区(幸存区)
为什么这里写幸存0区、幸存1区呢?
因为新生区常常用的GC算法是复制算法,该算法就是将幸存区分为两个同样大小的区域,这个算法详细内容GC部分会说。
首先,对象的创建(new)都是在伊甸园区进行的,当伊甸园区创建对象将其占满后,就会触发垃圾回收(轻GC),由于栈执行完毕后,对象引用也会消除,但是堆中实例化的对象并没有随着栈中引用清除而清除,依然在堆中占着内存,相当于孤零零的在堆中。垃圾回收就是清除这些孤零零的实例化对象,而一些栈中有引用连着的,它就先不清楚,因为还在用。这经过垃圾回收没有被回收的就会进入幸存0区,然后伊甸园区被垃圾回收清除后,又空了起来,就又可以放new的对象了。
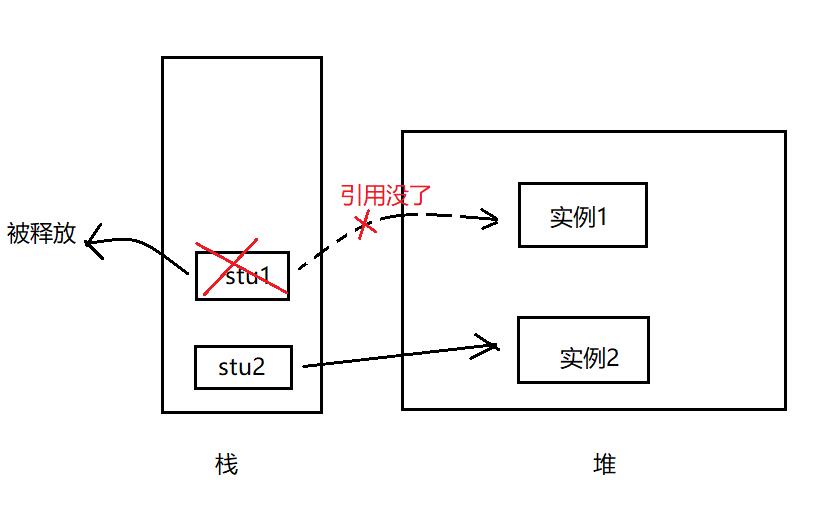
但是如果往复执行,幸存区满了,伊甸园区也满了,那么新生区就满了,这时候就会触发一次重GC,会把幸存区和伊甸园区都清一遍,如果还有没被清除的,就会进入养老区。当养老区也满了,也就是新生区与养老区都满时,堆内存就满了,就会发生OOM。
不过庆幸的是:99%的对象都是临时对象,用一下就不用了,比如new Student(),调用几次就不用了,我们不会写一个程序一直调用它,就像刚刚写个死循环while(true)一直调对象,这样垃圾回收就一直回收不了,这是没有意义的,实际开发中,肯定不会这样,我们为了测试OOM(内存溢出)才这么做,正常情况下很少对象能进入养老区,一般在新生区就会被回收,所以我们很少会碰到OOM问题。
永久区
JDK1.8之前,称永久区或者永久代。JDK1.8之后称元空间,方法区也在这里。这个区域是常驻内存的,用来存放jdk自身携带的Class对象,以及java运行时的一些环境及类信息,不存在垃圾回收。这个区域只有关闭JVM后才会被释放。发生OOM基本都和这个永久区无关
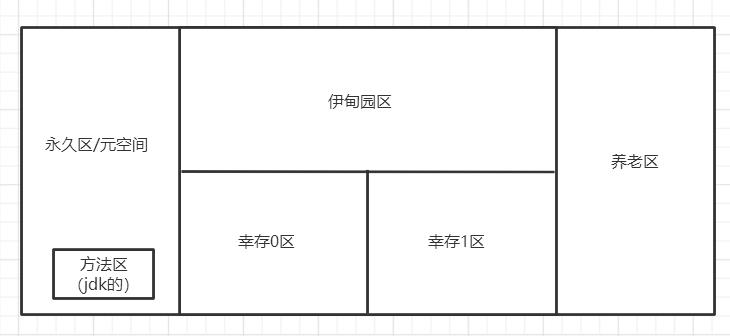
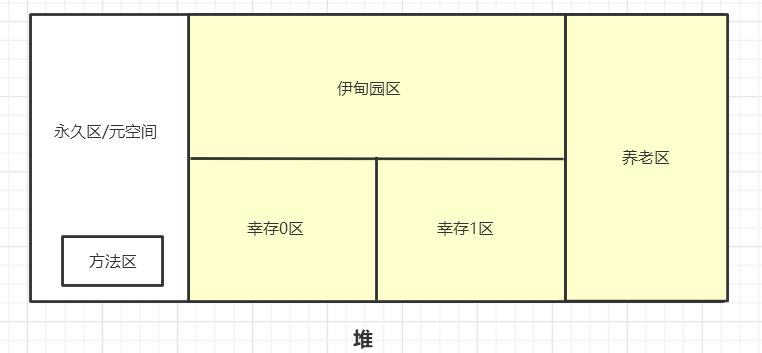
如上图为堆的内存,方法区在永久区,被其他所有对象共享。
问题:有人可能会说,那为什么之前画的图,方法区都是和堆区分开的呢?
答:永久区,又被称为非堆区。在HotSpot中,方法区仅仅只是逻辑上的独立,因为有些人会认为,实际上堆内存应该是新生区+老年区的,永久区不会存实例化对象,只存一些"死"的东西,所以不算做堆,这也是非堆称呼的由来,所以有人把堆内存看作新生区+养老区(黄色部分),而存放一些静态变量、常量、类信息(构造方法、接口定义) 、运行时常量池的方法区就看作独立于堆,所以我们一般在逻辑上认为方法区独立,但实际在物理层面,方法区还是属于堆中一部分。所以JVM体系结构将其独立画出来时,逻辑上单独分为一个区。在JDK1.8方法区变为元空间,彻底独立不放到堆中,放在本地内存,如下面第二个图(图来自JavaGuide)
三、GC(垃圾回收)
首先,GC发生在堆中
GC分为两大类:轻GC,重GC,新生区(伊甸园区和幸存区)用轻GC,老年区用重GC
3.1 GC算法—复制算法
GC复制算法是将幸存区划分为两个相同大小的内存区域实现的,这里就叫From空间和To空间。当From空间被完全占满时,GC会将存活对象全部复制到To空间。当复制完成后,该算法会把From空间和To空间互换,GC也就结束了。
总结执行过程:
1、From空间满了,GC就会来清除
2、复制存活对象到To区,清除垃圾对象,此时From为空
3、From空间与To空间转换,From空间有存活对象,To为空,就保证了原则
原则:GC结束时,保证To空间为空。
下图为两个空间,From中的标记为淡红色的就是存活对象(有引用所以没被清除),白色就是垃圾对象,当From区满时,会触发GC来清除。
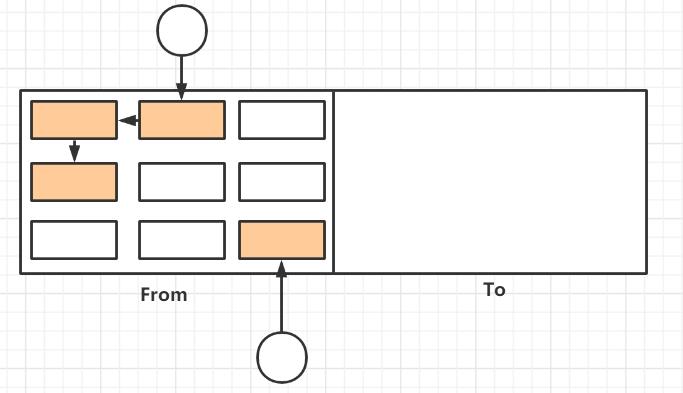
复制过程如下,GC复制算法会将五个存活对象复制到To区,并且保证在To区内存空间上的连续性。
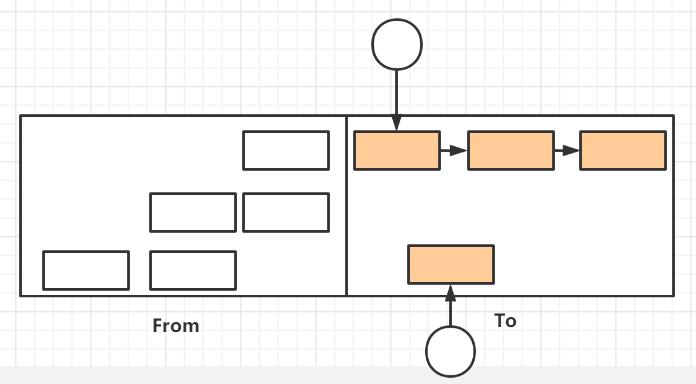
然后GC将From区中垃圾对象清除
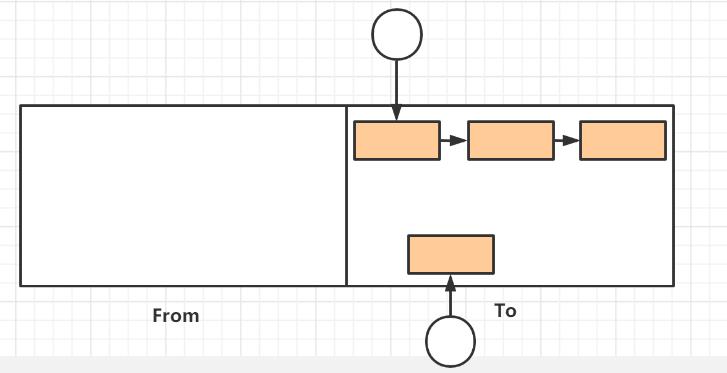
最后,From空间与To空间互换,保证To空间为空,之后From继续接收伊甸园区来的存活对象,重复上述过程
复制算法优缺点如下
优点:不会产生内存碎片
唯一缺点:幸存区一半空间永远是空的
复制算法最佳使用场景:对象存活度较低时,就是垃圾回收后存活少情况,即新生区
3.2 GC算法—标记清除压缩算法
1、将存活的对象标记

2、清除未被标记的对象

两次扫描,严重浪费时间,会产生内存碎片(不是连续的内存空间)
3、压缩(再次扫描,向一段移动存活的对象,防止产生内存碎片)

三次扫描又多了时间成本+移动成本
还可以进一步调优,就是多经过几次清除,然后再压缩,具体清除几次最好,这个就是JVM调优做的
总结:复制算法也就是空间复杂度高些,标记清除压缩就是时间复杂度高些,所以我们要根据具体场景使用具体算法,看什么场景用什么算法最合适。年轻代(新生区):存活率低,用复制算法。老年代(老年区):存活率高,区域大,用标记清除+压缩,几次清除再压缩效果好,需要调,比如内存碎片到达一个量级再统一压缩
3.3 GC分代收集算法
GC分代收集算法思想就是年轻代用复制算法,老年代用标记清除压缩算法。因为年轻代存活率低,老年代存活率高,正好分别取两个的最适合场景,达到全局最优。
以上就是本文全部内容,本文通过.java文件的整个执行流程带你入门JVM。希望对你有帮助,想要继续深入,强推《深入理解JVM》这本书。

以上是关于JVM快速入门(图解超级详细通俗易懂)的主要内容,如果未能解决你的问题,请参考以下文章