python基础之文件操作
Posted 杜杜精灵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python基础之文件操作相关的知识,希望对你有一定的参考价值。
文件操作首先做的是,打开文件,打开文件有两种方法open(...) 和 file(...),本质上前者在内部会调用后者来进行文件操作,但是一般都用open()
操作文件包括了文件的读、写和关闭,首先来谈谈打开方式:当我们执行 文件句柄 = open(\'文件路径\', \'模式\')操作的时候,要传递给open方法一个表示模式的参数:
来段代码演示一下
f = open(\\d:..,mode=\'r\',\'encodeing=utf-8\') #文件句柄 = open(\'文件路径\', \'模式\') 路径分为相对路径和绝对路径
打开文件的模式有:
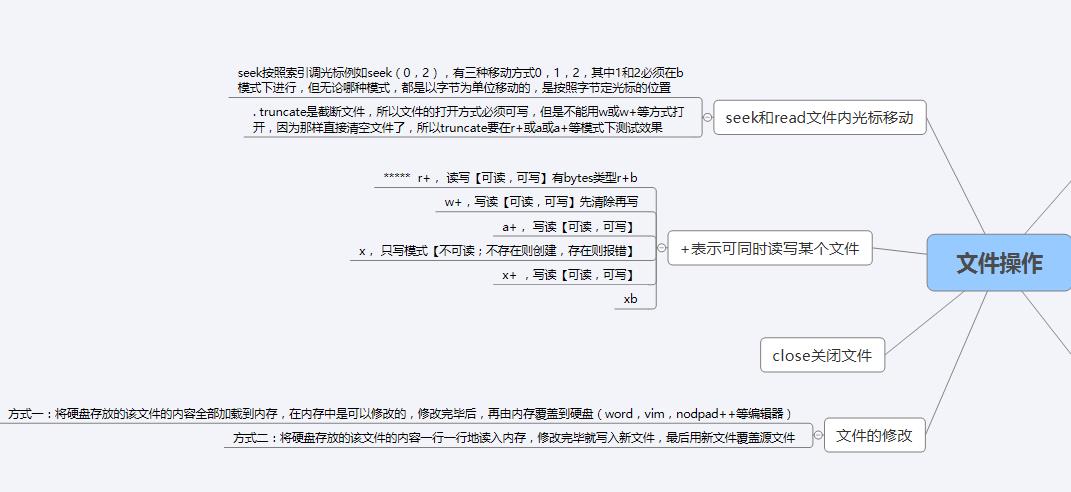
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,先写再读。【这个方法打开文件会清空原本文件中的所有内容,将新的内容写进去,之后也可读取已经写入的内容】
- a+,同a
"U"表示在读取时,可以将 \\r \\n \\r\\n自动转换成 \\n (注意:只能与 r 或 r+ 模式同使用)
- rU
- r+U
- rbU
- rb+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
#用rb打开不需要编码解码,用在非文字的读写
# f = open(\'d\\作品\\模特主妇护士班主任\',mode=\'r\')
# content = f.read()
# print(content)
# f.close()
#
#只写 对于W,没有此文件就会创建
# f = open(\'log\',mode=\'w\',encoding=\'utf-8\')
# f.write(\'骑兵步兵\')
# f.close()
#先将源文件内容全部清除,再写
# f = open(\'log\',mode=\'w\',encoding=\'utf-8\')
# f.write(\'高清\')
# f.close()
# f = open(\'log\',mode=\'wb\')
# f.write(\'剧情\'.encode(\'utf-8\')) #endode后面跟的是所用软件默认的编码方式,否则会报错
# f.close()
#追加 r,rb
# f = open(\'log\',mode=\'a\',encoding=\'utf-8\')
# f.write(\'佳琪\')
# f.close()
#追加写
#f = open(\'log\',mode=\'ab\')
# f.write(\'佳琪\'.encode(\'utf-8\'))
# f.close()
#读写
# f = open(\'log\',mode=\'r+\',encoding=\'utf-8\')
# f.write(\'佳琪\')
# print(f.read())
# f.close()
#读写的bytes类型,r+b也是读写,但是是以bytes类型,最常用r+
# f = open(\'log\',mode=\'r+b\')
# print(f.read())
# f.write(\'佳琪\'.encode(\'utf-8\'))
# print(f.read())
# f.close()
#w+写读,只要有w都是先清除再写
# f = open(\'log\',mode=\'w+\',encoding=\'utf-8\')
# f.write(\'佳琪\')
# print(f.read())
# f.close()
# f = open(\'log\',mode=\'w+\',encoding=\'utf-8\')
# f.write(\'佳琪\')
# print(f.read())
# f.close()
#功能详解 read(这里放数字,放几就按照想要读取的文件(字符)最小单位读取)
# f = open(\'log\',mode=\'w+\',encoding=\'utf-8\')
# countent = f.read(2)
# print(countent)
#断点续传***** tell告诉你光标的位置,然后再seek把光标调到这个位置就可以实现断点续传
#f.readline()一行一行读,只能读第一行,想读下面就调光标
#f。readlines()每一行当成列表中的一个元素,添加到列表中
#f.truncate(这里填截取的数字)在原文件文件截取
#open打开文件是依赖了操作系统的提供的途径
#操作系统有自己的编码,open在打开文件的时候默认使用操作系统的编码
#win gbk mac/linux utf-8
#习惯叫 f file f_obj f_handler fh
# print(f.writable()) #判断文件是否可写
# print(f.readable()) #判断文件是否可读
# f.write(\'7018201890\') #写文件的时候需要写数字,需要把数字转换成字符串
# f.write(\'aasjgdlwhoojfjdaj\')
# f.write(\'iq349jdsh\\n\')
# f.write(\'aks\')
# f.write(\'\\nsdgawo\') #文件的换行
# f.write(\'志强德胜\') #utf-8 unicode gbk
f.close()
#找到文件详解:文件与py的执行文件在相同路径下,直接用文件的名字就可以打开文件
#文件与py的执行文件不在相同路径下,用绝对路径找到文件
#文件的路径,需要用取消转译的方式来表示:1.\\\\ 2.r\'\'
#如果以写文件的方式打开一个文件,那么不存在的文件会被创建,存在的文件之前的内容会被清空
\' \\\\n\'
f = open(r\'C:\\Users\\Administrator\\Desktop\\s8_tmp.txt\',\'w\',encoding=\'utf-8\') #文件路径、操作模式、编码
f.write(\'哈哈哈\')
f.close()
#关闭文件详解
#操作系统级别的关闭文件资源:f.close() 必须写
#del f主动释放了一个python程序内存中的变量 可写可不写
#1.读文件的第一种方式:read方法,用read方法会一次性的读出文件中的所有内容
2.读一部分内容:read(n),指定读n个单位
#3.读文件的第三种方式:按照行读,每次执行readline就会往下读一行
# content = f.readline()
#5.读:最常用
f = open(\'歌词\',encoding=\'utf-8\')
for l in f:
print(l.strip())
f = open(\'shoplist\',encoding=\'utf-8\') #读文件并整理成需要的数据类型
goods_list = []
for line in f:
if line.strip():
goods_dic = {\'name\':None,\'price\':None}
line = line.strip()
goods_lst = line.split()
print(goods_lst)
goods_dic[\'name\'] = goods_lst[0]
goods_dic[\'price\'] = goods_lst[1]
goods_list.append(goods_dic)
print(goods_list)
f.close()
# f = open(\'shoplist\',encoding=\'utf-8\') #只显示文件中有内容的行
# goods_list = []
# for line in f:
# if line.strip():
# print(line.strip())
# f.close()
# f = open(\'歌词\',\'rb\')
# f.close()
#b:图片、音乐、视频等任何文件
#传输:上传、下载
#网络编程:
#修改文件的编码——非常不重要,不重要程度五颗星
#utf-8 用utf8的方式打开一个文件
#读文件里的内容str
#将读出来的内容转换成gbk
#以gbk的方式打开另一个文件
#写入
#a+
# f = open(\'shoplist\',\'a+\',encoding=\'utf-8\')
# print(f.readable())
# f.write(\'\\ncomputer 6000 5\')
# f.write(\'\\ncomputer 6000 5\')
# f.write(\'\\ncomputer 6000 5\')
# f.write(\'\\ncomputer 6000 5\')
# f.close()
#1.被动接受知识 - 主动提出问题
#2.主动的找到问题,并且找到对应的解决方法
#3.主动的学习
# r+ 可读可写:
#1.先读后写:写是追写
#2.先写后读:从头开始写
# f = open(\'歌词\',\'r+\',encoding=\'utf-8\')
# line = f.readline()
# print(line)
# f.write(\'0000\')
# f.close()
# w+ 可写可读:一上来文件就清空了,
# 尽管可读:1.但是你读出来的内容是你这次打开文件新写入的
# 2.光标在最后,需要主动移动光标才可读
# f = open(\'歌词\',\'w+\',encoding=\'utf-8\')
# f.write(\'abc\\n\')
# f.write(\'及哈哈哈\')
# f.seek(0)
# print(f.read())
# f.close()
# a+ 追加可读
# f = open(\'歌词\',\'a+\',encoding=\'utf-8\')
# f.write(\'\\nqq星\')
# f.seek(0)
# print(f.read())
# f.close()
#一般情况下:文件操作,要么读,要么写,很少会用到读写、写读同时用的
#常用的:
#r、w、a
#rb、wb、ab,不需要指定编码了
#
# f = open(\'歌词\',\'rb\')
# content = f.read()
# f.close()
# print(content)
# f2 = open(\'歌词2\',\'wb\')
# f2.write(content)
# f2.close()
# print(\'readline : \',content.strip()) #strip去掉空格、制表符、换行符
# content2 = f.readline()
# print(content2.strip())
#4.读文件的第四种方式:readlines,返回一个列表,将文件中的每一行作为列表中的每一项返回一个列表
f = open(\'歌词\',\'r+\',encoding=\'utf-8\')
#seek 光标移动到第几个字节的位置
# f.seek(0) 移动到最开始
# f.seek(0,2) 移动到最末尾
f.truncate(3) #从文件开始的位置只保留指定字节的内容
# f.write(\'我可写了啊\')
#tell 告诉我光标在第几个字节
#seek移动光标到指定位置
# content = f.readline()
# print(content.strip())
#tell告诉你当前光标所在的位置
# print(f.tell())
# f.seek(4) #光标移动到三个字节的地方‘\\r\\n’
# content = f.read(1) #读一个字符
# print(\'***\',content,\'***\')
# content = f.readline()
# print(content.strip())
# print(f.tell())
f.close()
#tell
#seek:去最开始、去最结尾
#truncate:保留n个字节

以上是关于python基础之文件操作的主要内容,如果未能解决你的问题,请参考以下文章