卷积神经网络之GAN(附完整代码)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷积神经网络之GAN(附完整代码)相关的知识,希望对你有一定的参考价值。
参考技术A 不管何种模型,其损失函数(Loss Function)选择,将影响到训练结果质量,是机器学习模型设计的重要部分。对于判别模型,损失函数是容易定义的,因为输出的目标相对简单。但对于生成模型,损失函数却是不容易定义的。GAN算法原理:
1)G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
3)在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
4)这样目的就达成了:得到了一个生成式的模型G,它可以用来生成图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而判别网络D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
2.再以理论抽象进行说明:
GAN是一种通过对抗过程估计生成模型的新框架。框架中同时训练两个模型:捕获数据分布的生成模型G,和估计样本来自训练数据的概率的判别模型D。G的训练程序是将D错误的概率最大化。可以证明在任意函数G和D的空间中,存在唯一的解决方案,使得G重现训练数据分布,而D=0.5(D判断不出真假,50%概率,跟抛硬币决定一样)。在G和D由多层感知器定义的情况下,整个系统可以用反向传播进行训练。在训练或生成样本期间,不需要任何马尔科夫链或展开的近似推理网络。实验通过对生成的样品的定性和定量评估,证明了GAN框架的潜在优势。
Goodfellow从理论上证明了该算法的收敛性。在模型收敛时,生成数据和真实数据具有相同分布,从而保证了模型效果。
GAN公式形式如下:
1)公式中x表示真实图片,z表示输入G网络的噪声,G(z)表示G网络生成的图片;
2)D(x)表示D网络判断图片是否真实的概率,因为x就是真实的,所以对于D来说,这个值越接近1越好。
3)G的目的:D(G(z))是D网络判断G生成的图片的是否真实的概率。G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此公式的最前面记号是min_G。
4)D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大max_D。
GAN训练过程:
GAN通过随机梯度下降法来训练D和G。
1)首先训练D,D希望V(G, D)越大越好,所以是加上梯度(ascending)
2)然后训练G时,G希望V(G, D)越小越好,所以是减去梯度(descending);
GAN训练具体过程如下:
GAN算法优点:
1)使用了latent code,用以表达latent dimension、控制数据隐含关系等;
2)数据会逐渐统一;
3)不需要马尔可夫链;
4)被认为可以生成最好的样本(不过没法鉴定“好”与“不好”);
5)只有反向传播被用来获得梯度,学习期间不需要推理;
6)各种各样的功能可以被纳入到模型中;
7)可以表示非常尖锐,甚至退化的分布。
GAN算法缺点:
1)Pg(x)没有显式表示;
2)D在训练过程中必须与G同步良好;
3)G不能被训练太多;
4)波兹曼机必须在学习步骤之间保持最新。
GAN的应用范围较广,扩展性也强,可应用于图像生成、数据增强和图像处理等领域。
1)图像生成:
目前GAN最常使用的地方就是图像生成,如超分辨率任务,语义分割等。
2)数据增强:
用GAN生成的图像来做数据增强。主要解决的问题是a)对于小数据集,数据量不足,可以生成一些数据;b)用原始数据训练一个GAN,GAN生成的数据label不同类别。
GAN生成式对抗网络是一种深度学习模型,是近年来复杂分布上无监督学习最具有前景的方法之一,值得深入研究。GAN生成式对抗网络的模型至少包括两个模块:G模型-生成模型和D模型-判别模型。两者互相博弈学习产生相当好的输出结果。GAN算法应用范围较广,扩展性也强,可应用于图像生成、数据增强和图像处理等领域。
pytorch生成对抗网络GAN的基础教学简单实例(附代码数据集)
1.简介
这篇文章主要是介绍了使用pytorch框架构建生成对抗网络GAN来生成虚假图像的原理与简单实例代码。数据集使用的是开源人脸图像数据集img_align_celeba,共1.34G。生成器与判别器模型均采用简单的卷积结构,代码参考了pytorch官网。
建议对pytorch和神经网络原理还不熟悉的同学,可以先看下之前的文章了解下基础:pytorch基础教学简单实例(附代码)_Lizhi_Tech的博客-CSDN博客_pytorch实例
2.GAN原理
简而言之,生成对抗网络可以归纳为以下几个步骤:
随机噪声输入进生成器,生成虚假图片。
将带标签的虚假图片和真实图片输入进判别器进行更新,最大化 log(D(x)) + log(1 - D(G(z)))。
根据判别器的输出结果更新生成器,最大化 log(D(G(z)))。
3.代码
from __future__ import print_function
import random
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
# 设置随机算子
manualSeed = 999
random.seed(manualSeed)
torch.manual_seed(manualSeed)
# 数据集位置
dataroot = "data/celeba"
# dataloader的核数
workers = 2
# Batch大小
batch_size = 128
# 图像缩放大小
image_size = 64
# 图像通道数
nc = 3
# 隐向量维度
nz = 100
# 生成器特征维度
ngf = 64
# 判别器特征维度
ndf = 64
# 训练轮数
num_epochs = 5
# 学习率
lr = 0.0002
# Adam优化器的beta系数
beta1 = 0.5
# gpu个数
ngpu = 1
# 加载数据集
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# 创建dataloader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
# 使用cpu还是gpu
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# 初始化权重
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
# 生成器
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)
# 实例化生成器并初始化权重
netG = Generator(ngpu).to(device)
netG.apply(weights_init)
# 判别器
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
# 实例化判别器并初始化权重
netD = Discriminator(ngpu).to(device)
netD.apply(weights_init)
# 损失函数
criterion = nn.BCELoss()
# 随机输入噪声
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
# 真实标签与虚假标签
real_label = 1.
fake_label = 0.
# 创建优化器
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
# 开始训练
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
for epoch in range(num_epochs):
for i, data in enumerate(dataloader, 0):
############################
# (1) 更新D: 最大化 log(D(x)) + log(1 - D(G(z)))
###########################
# 使用真实标签的batch训练
netD.zero_grad()
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=device)
output = netD(real_cpu).view(-1)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
# 使用虚假标签的batch训练
noise = torch.randn(b_size, nz, 1, 1, device=device)
fake = netG(noise)
label.fill_(fake_label)
output = netD(fake.detach()).view(-1)
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake
# 更新D
optimizerD.step()
############################
# (2) 更新G: 最大化 log(D(G(z)))
###########################
netG.zero_grad()
label.fill_(real_label)
output = netD(fake).view(-1)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
# 更新G
optimizerG.step()
# 输出训练状态
if i % 50 == 0:
print('[%d/%d][%d/%d]\\tLoss_D: %.4f\\tLoss_G: %.4f\\tD(x): %.4f\\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# 保存每轮loss
G_losses.append(errG.item())
D_losses.append(errD.item())
# 记录生成的结果
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
# loss曲线
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
# 生成效果图
real_batch = next(iter(dataloader))
# 真实图像
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# 生成的虚假图像
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()4.结果

真实图像与生成图像
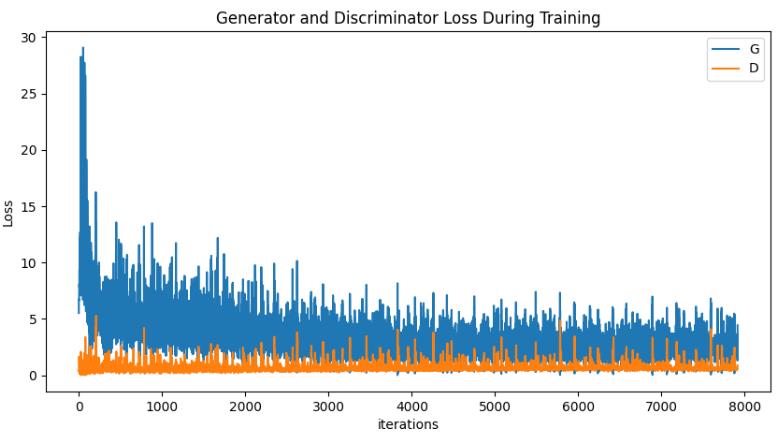
loss曲线
完整的代码与数据集可以在我的github上找到:lizhiTech/pytorch_GAN_simple_example: 介绍了使用pytorch框架构建生成对抗网络GAN来生成虚假图像的原理与简单实例代码 (github.com)
或者csdn下载:
我们也提供包括深度学习、计算机视觉、机器学习等其他方向的其他代码及辅导服务,有需求可以通过csdn私聊或github上的联系方式联系我们。
以上是关于卷积神经网络之GAN(附完整代码)的主要内容,如果未能解决你的问题,请参考以下文章
pytorch生成对抗网络GAN的基础教学简单实例(附代码数据集)
深度卷积生成对抗网络(DCGAN)简介及图像生成仿真(附代码)
Matlab基于MNIST数据集的图像识别(深度学习入门卷积神经网络附完整学习资料)
Matlab基于MNIST数据集的图像识别(深度学习入门卷积神经网络附完整学习资料)