以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路
Posted 字节跳动数据平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路相关的知识,希望对你有一定的参考价值。
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
I. 传统数仓的演进:云数仓
近年来,随着数据“爆炸式”的增长,越来越多的数据被产生、收集和存储。而挖掘海量数据中的真实价值,从其中提取商机并洞见未来,则成了现代企业和组织不可忽视的命题。
随着数据量级和复杂度的增大,数据分析处理的技术架构也在不断演进。在面对海量数据分析时,传统 OLAP 技术架构中的痛点变得越来越明显,如扩容缩容耗时长,导致资源利用率偏低,成本居高不下;以及运维配置复杂,需要专业的技术人员介入等。
为了解决这类问题,云数仓的概念应运而生。和传统数仓架构不同的是,云原生数仓借助于云平台的基础资源,实现了资源的动态扩缩容,并最大化利用资源,从而达到 Pay as you go 按实际用量付费的模式。
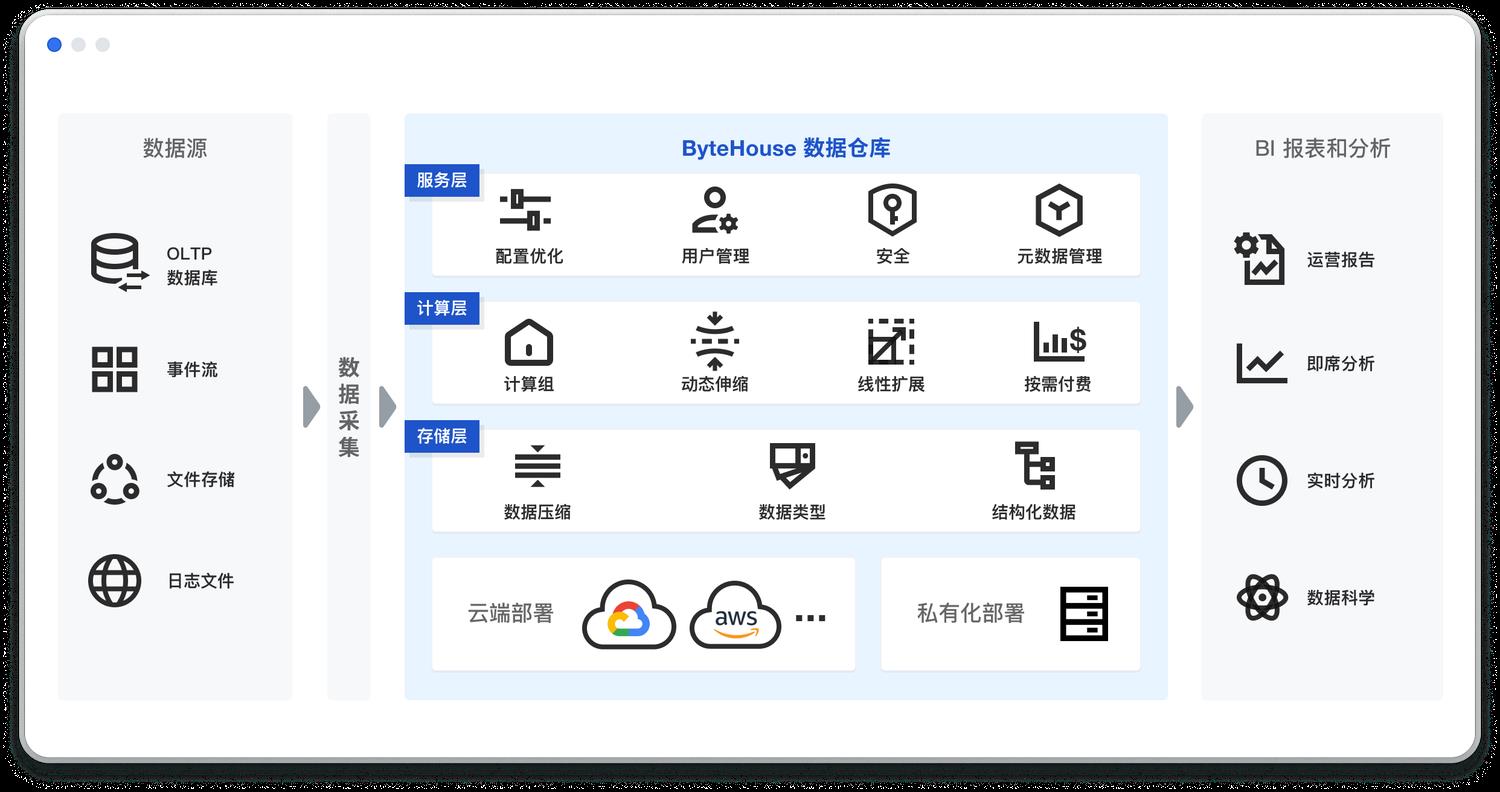
ByteHouse 作为云原生的数据平台,从架构层面入手,通过存储和计算分离的云原生架构完美适配云上基础设施。在字节跳动内部,ByteHouse 已经支持 80% 的分析应用场景,包括用户增长业务、广告、A/B 测试等。除了极致的分析性能之外,ByteHouse 开箱即用,按实际使用付费的特性也极大地降低了企业和个人的上手门槛,能够在短短数分钟内体验到数据分析的魅力。
Talk is cheap, 接下来就让我们通过一个实战案例来体验下 ByteHouse 云数仓的强大功能。
II. 快速上手 ByteHouse——轻量级云数仓
本章节通过使用 ByteHouse 云数仓进行 SSB 基准测试,在带领读者了解产品性能的同时,也一并熟悉产品中各个模块的功能,开启你的数据分析之路,通过分析海量数据,加速数据洞察。ByteHouse 的架构总览如下。
SSB 基准测试
SSB(Star Schema Benchmark)是由麻省州立大学波士顿校区的研究员定义的基于现实商业应用的数据模型。SSB 是在 TPC-H 标准的基础上改进而成,主要将 TPC-H 中的雪花模型改成了更为通用的的星型模型,将基准查询从复杂的 Ad-hoc 查询改成了结构更加固定的 OLAP 查询,从而主要用于模拟测试 OLAP 引擎和轻量数仓场景下的查询性能。由于 SSB 基准测试较为中立,并贴近现实的商业场景,因此在学界及工业界有广泛的应用。
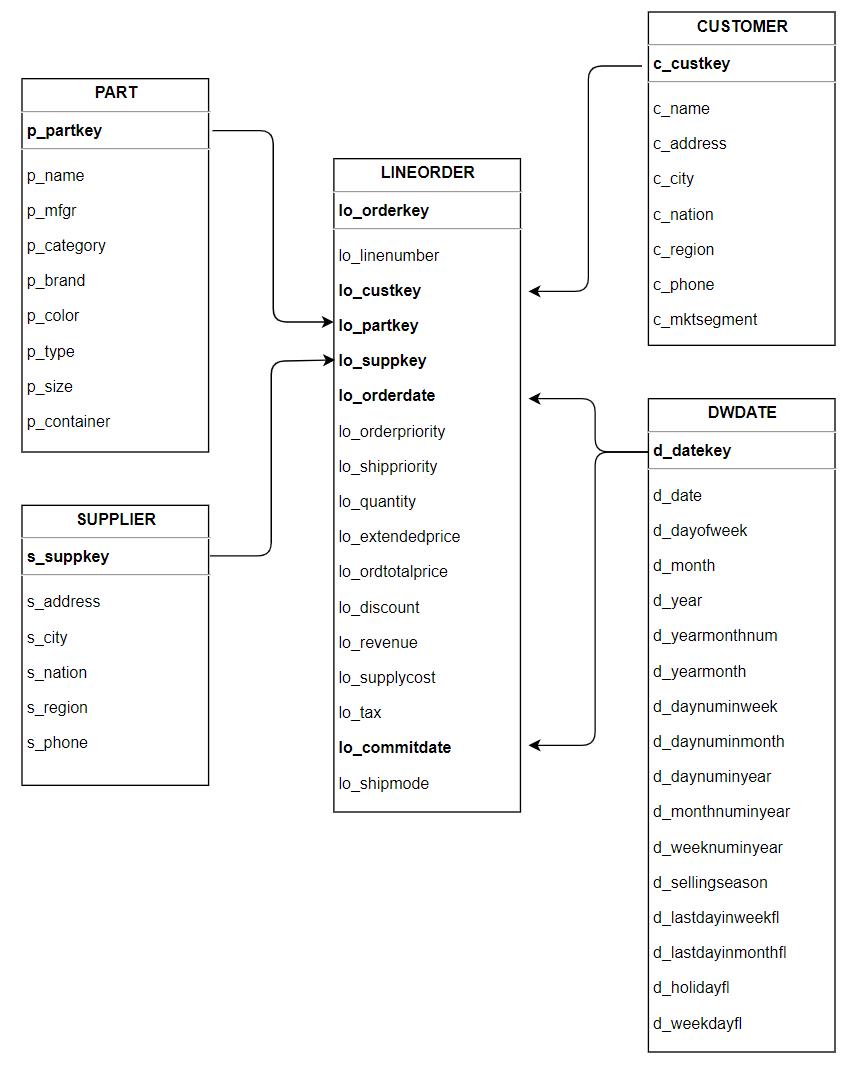
SSB 基准测试中对应的表结构如下所示,可以看到 SSB 主要采用星型模型,其中包含了 1 个事实表 lineorder 和 4 个维度表 customer, part, dwdate 以及 supplier,每张维度表通过 Primary Key 和事实表进行关联。测试通过执行 13 条 SQL 进行查询,包含了多表关联,group by,复杂条件等多种组合。更多详细信息请参考 SSB 文献。
步骤一:官网注册并开通 ByteHouse
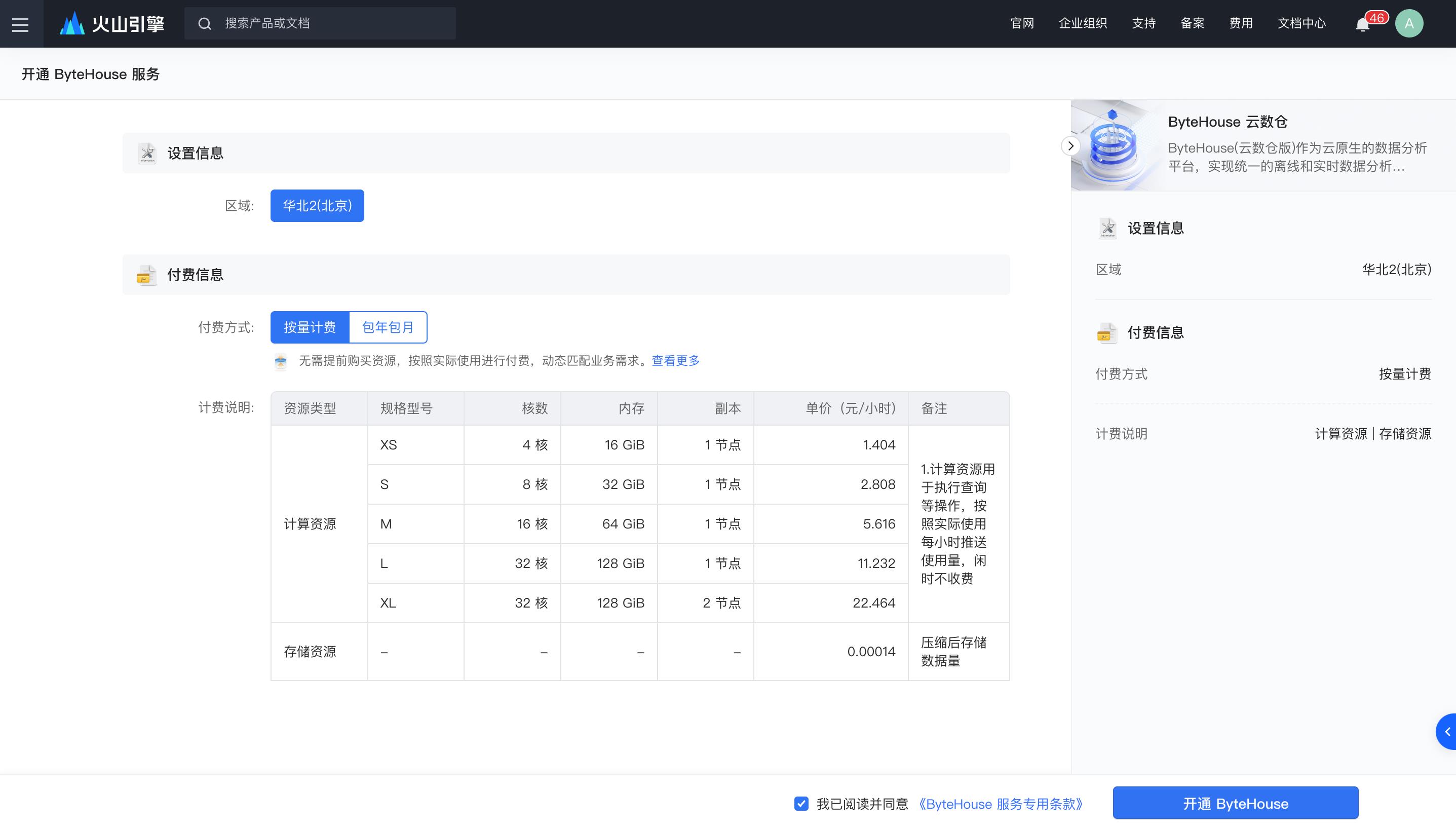
访问ByteHouse 云数仓火山引擎官网,注册火山引擎账户,完成实名认证后,即可登录到产品控制台。开通产品进行测试,目前 ByteHouse 支持包年包月和按量付费两种模式的实例,便于您根据业务需求进行选择。
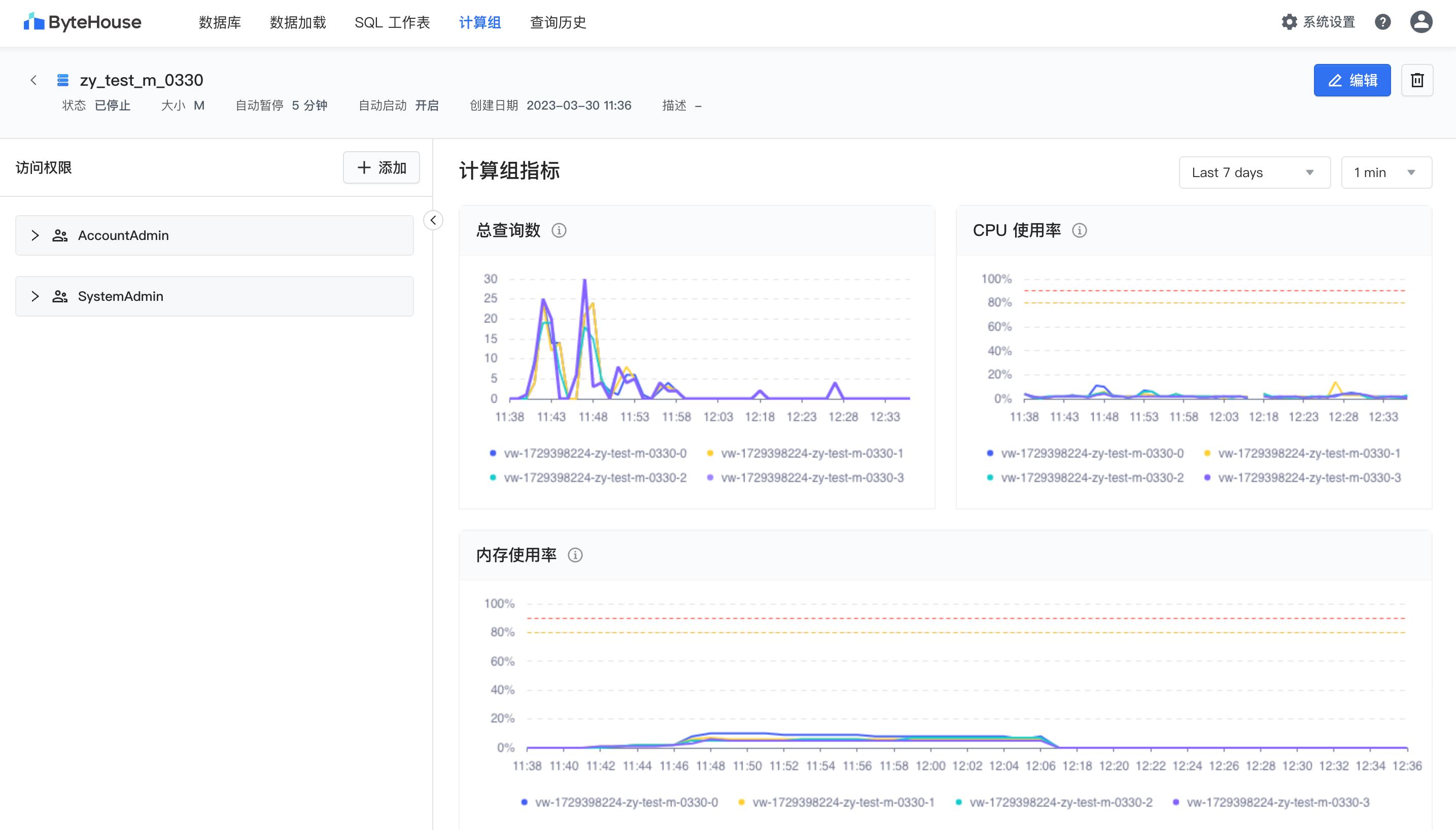
步骤二:创建计算组
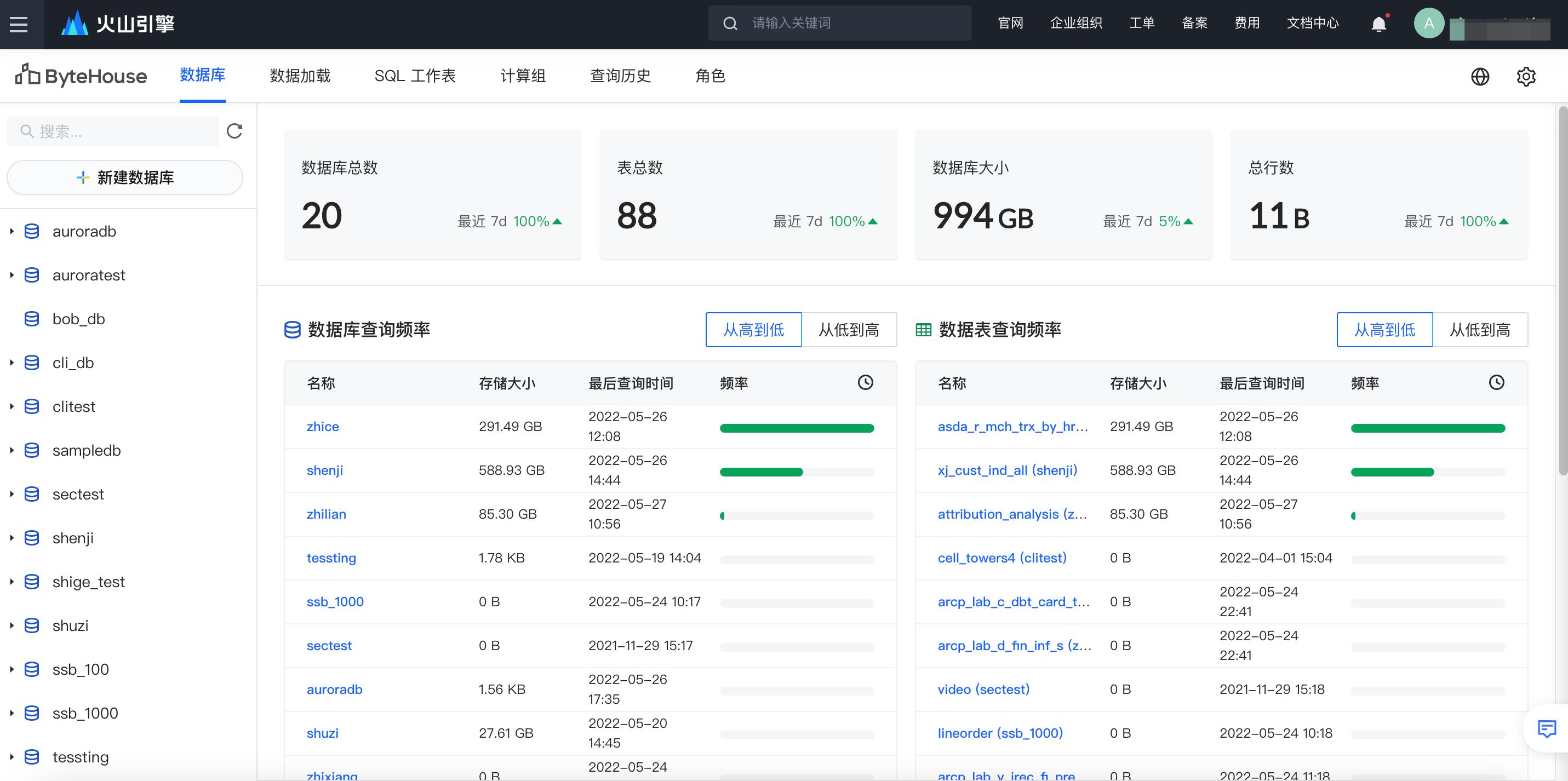
登录到控制台后,可以看到数据库表管理、数据加载、SQL 工作表、计算组、查询历史和角色管理等几大模块。分别具有如下作用:
-
数据库表管理:用于创建和管理数据库、数据表以及视图等数据对象
-
数据加载:用于从不同的离线和实时数据源如对象存储、Kafka 等地写入数据
-
SQL 工作表:在界面上编辑、管理并运行 SQL 查询
-
计算组:创建和管理虚拟的计算资源,用于执行数据查询等操作
-
查询历史:用于查看 SQL 的历史执行记录、状态和查询详情等
为了方便进行后续的建库建表和查询等操作,首先在 ByteHouse 控制台创建型号为 L 的计算组,如下图所示
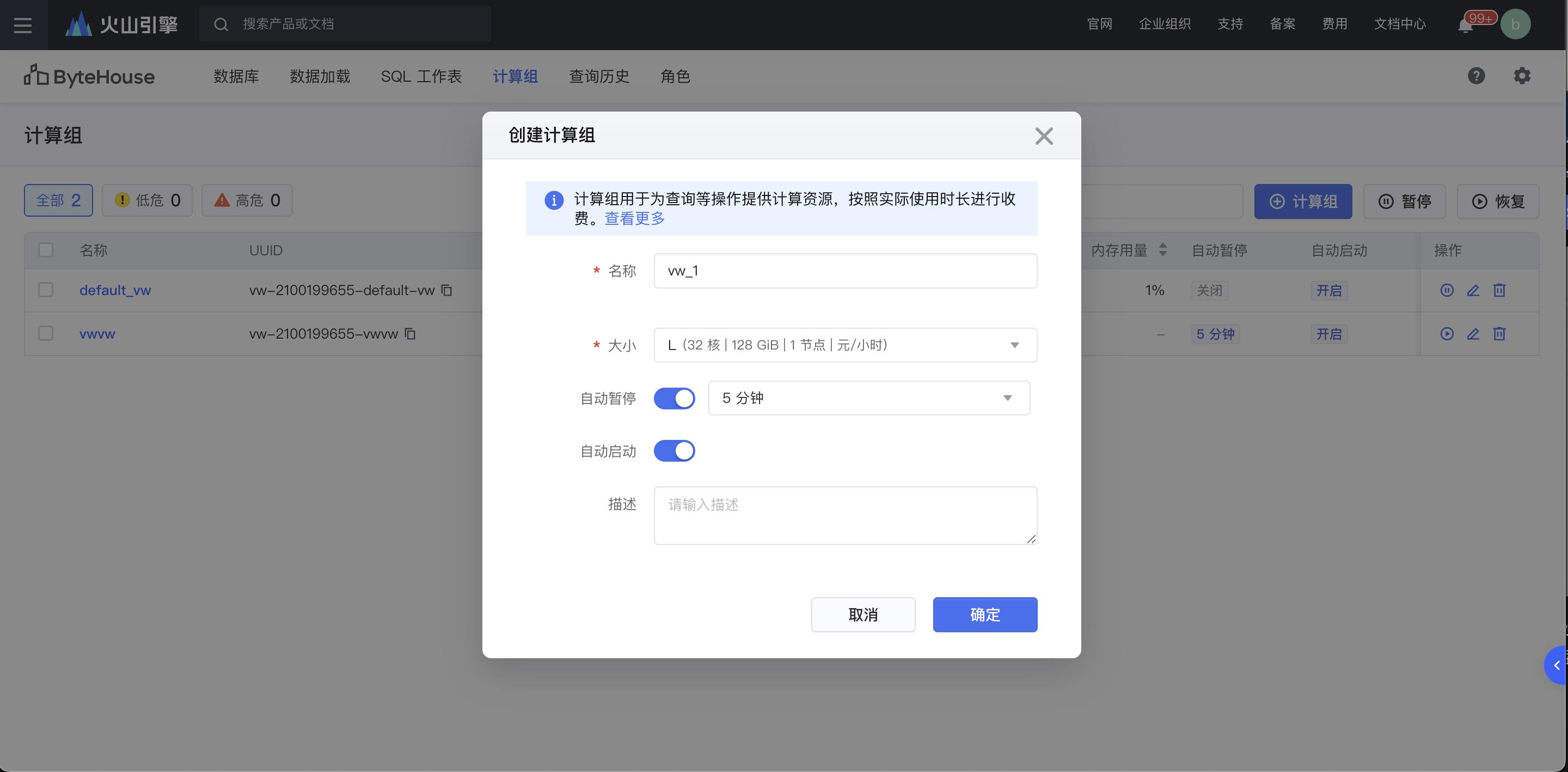
计算组是 Bytehouse 中的计算资源集群,可按需进行横向扩展。计算组提供所需的资源如 CPU、内存及临时存储等,用于执行数据查询 DQL、DML 等操作。ByteHouse 计算组能够实现弹性扩缩容,读写分离、存算分离等,并且能对资源进行细粒度的权限控制。
步骤三:创建数据库表
在控制台页面中创建名为 ssb_100 的数据库
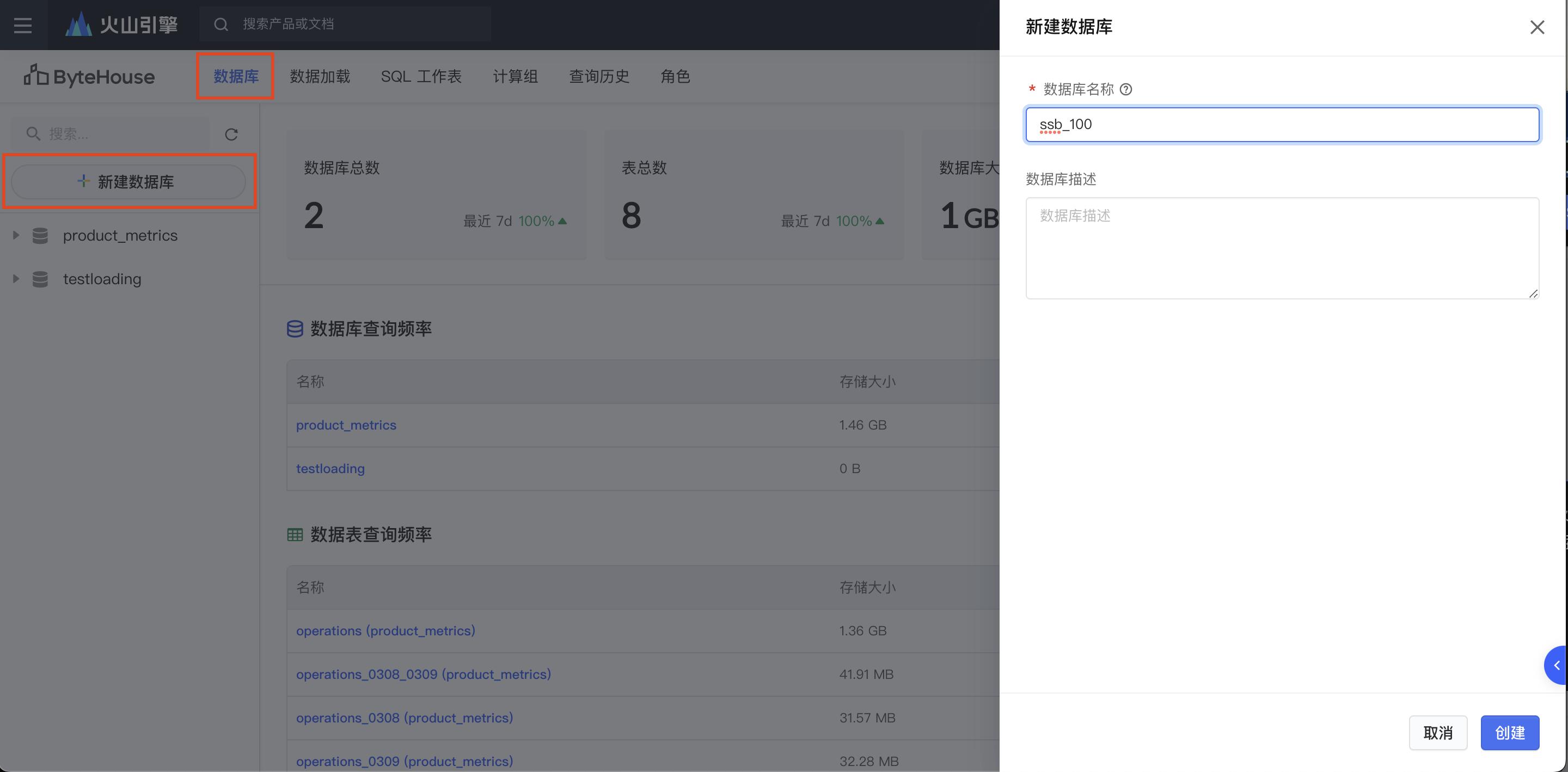
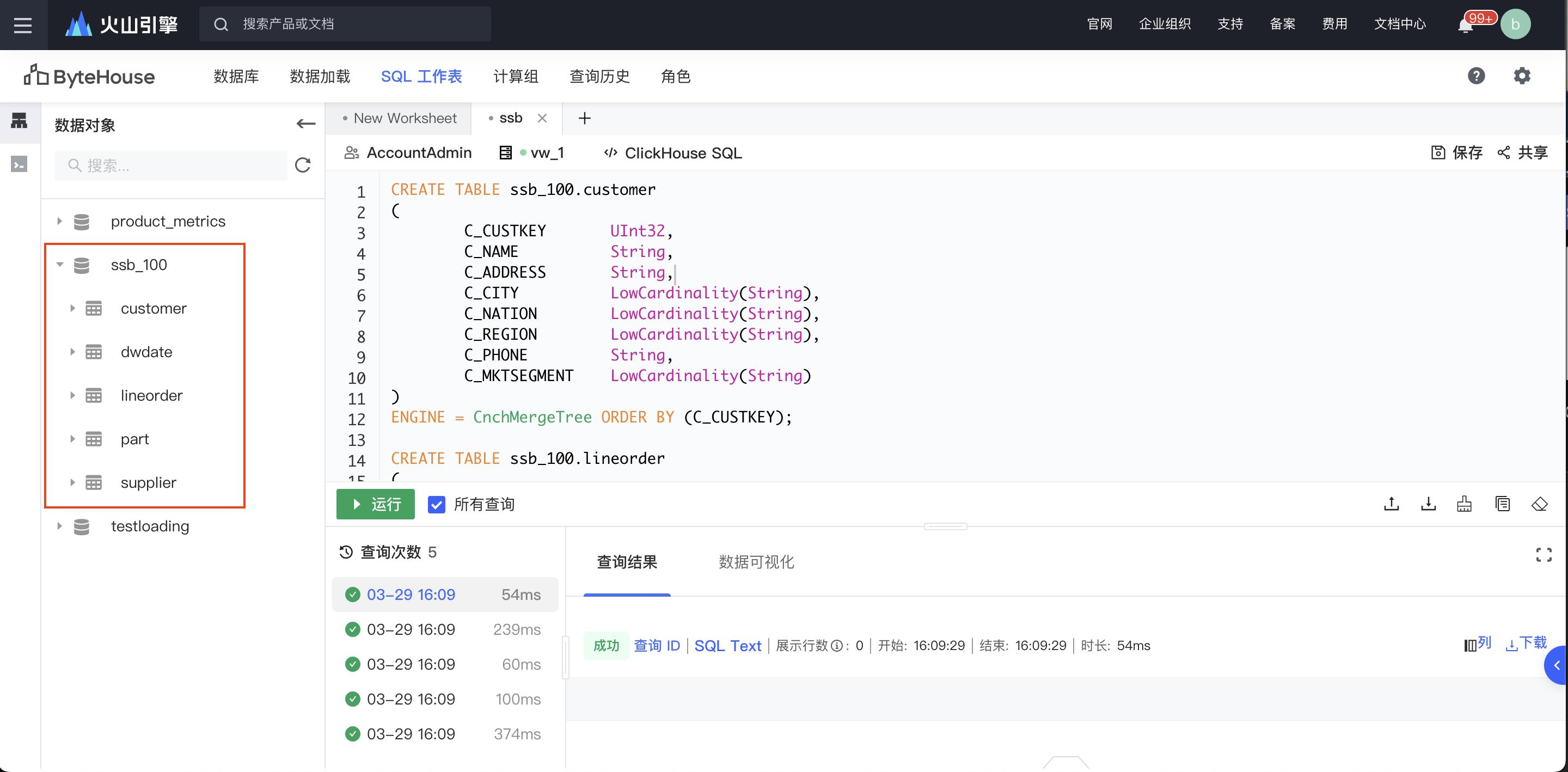
创建完毕后,进入到 SQL 工作表模块,通过如下建表语句建立四个数据表(事实表),并保存对应的 SQL 语句。
CREATE TABLE ssb_100.customer ( C_CUSTKEY UInt32, C_NAME String, C_ADDRESS String, C_CITY LowCardinality(String), C_NATION LowCardinality(String), C_REGION LowCardinality(String), C_PHONE String, C_MKTSEGMENT LowCardinality(String), C_PLACEHOLDER Nullable(String) ) ENGINE = CnchMergeTree ORDER BY (C_CUSTKEY); CREATE TABLE ssb_100.lineorder ( LO_ORDERKEY UInt32, LO_LINENUMBER UInt8, LO_CUSTKEY UInt32, LO_PARTKEY UInt32, LO_SUPPKEY UInt32, LO_ORDERDATE Date, LO_ORDERPRIORITY LowCardinality(String), LO_SHIPPRIORITY UInt8, LO_QUANTITY UInt8, LO_EXTENDEDPRICE UInt32, LO_ORDTOTALPRICE UInt32, LO_DISCOUNT UInt8, LO_REVENUE UInt32, LO_SUPPLYCOST UInt32, LO_TAX UInt8, LO_COMMITDATE Date, LO_SHIPMODE LowCardinality(String), LO_PLACEHOLDER Nullable(String) ) ENGINE = CnchMergeTree PARTITION BY toYear(LO_ORDERDATE) ORDER BY (LO_ORDERDATE, LO_ORDERKEY); CREATE TABLE ssb_100.part ( P_PARTKEY UInt32, P_NAME String, P_MFGR LowCardinality(String), P_CATEGORY LowCardinality(String), P_BRAND LowCardinality(String), P_COLOR LowCardinality(String), P_TYPE LowCardinality(String), P_SIZE UInt8, P_CONTAINER LowCardinality(String), P_PLACEHOLDER Nullable(String) ) ENGINE = CnchMergeTree ORDER BY P_PARTKEY; CREATE TABLE ssb_100.supplier ( S_SUPPKEY UInt32, S_NAME String, S_ADDRESS String, S_CITY LowCardinality(String), S_NATION LowCardinality(String), S_REGION LowCardinality(String), S_PHONE String, S_PLACEHOLDER Nullable(String) ) ENGINE = CnchMergeTree ORDER BY S_SUPPKEY; CREATE TABLE ssb_100.dwdate ( D_DATEKEY UInt32, D_DATE String, D_DAYOFWEEK String, -- defined in Section 2.6 as Size 8, but Wednesday is 9 letters D_MONTH String, D_YEAR UInt32, D_YEARMONTHNUM UInt32, D_YEARMONTH String, D_DAYNUMINWEEK UInt32, D_DAYNUMINMONTH UInt32, D_DAYNUMINYEAR UInt32, D_MONTHNUMINYEAR UInt32, D_WEEKNUMINYEAR UInt32, D_SELLINGSEASON String, D_LASTDAYINWEEKFL UInt32, D_LASTDAYINMONTHFL UInt32, D_HOLIDAYFL UInt32, D_WEEKDAYFL UInt32, S_PLACEHOLDER Nullable(String) ) ENGINE=CnchMergeTree() ORDER BY (D_DATEKEY);
SQL 执行完毕后,在控制台左侧对应的数据对象页面会展示出创建完成的五个工作表,分别为 customer,dwdate,lineorder以及part 和 supplier
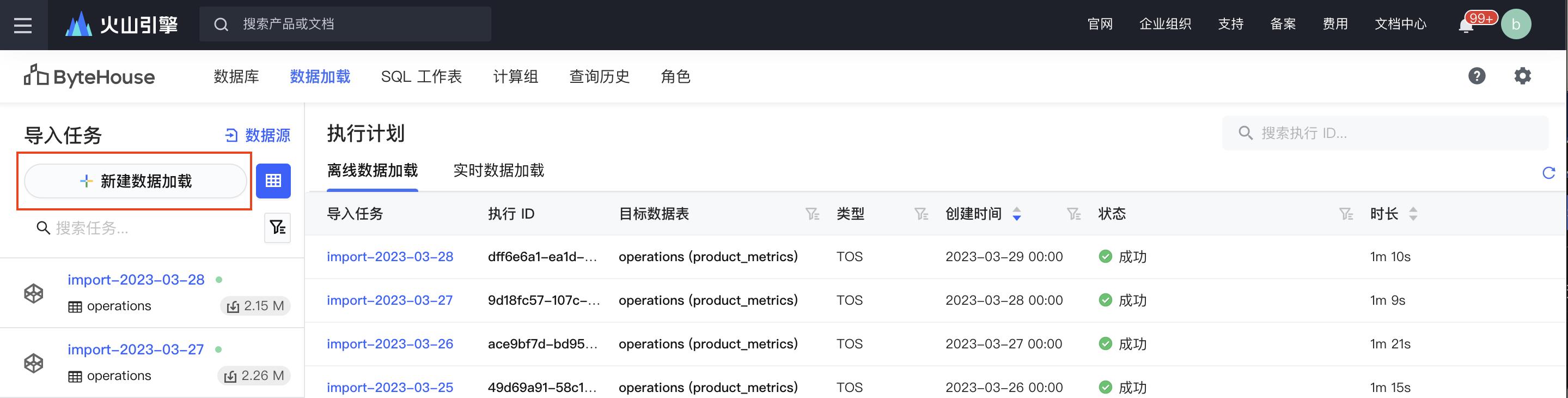
步骤四:从对象存储中导入 SSB 数据
通过预先生成 SSB_100 GB 的数据集并存储在对象存储(如 AWS S3 或者 火山引擎 TOS),我们可以方便且快速的将数据导入到 ByteHouse 中进行分析。本次实践中通过配置 火山引擎 TOS 的数据源对数据进行导入。
首先在数据加载模块,新建对象存储数据源,并配置对应的秘钥连接火山引擎对象存储
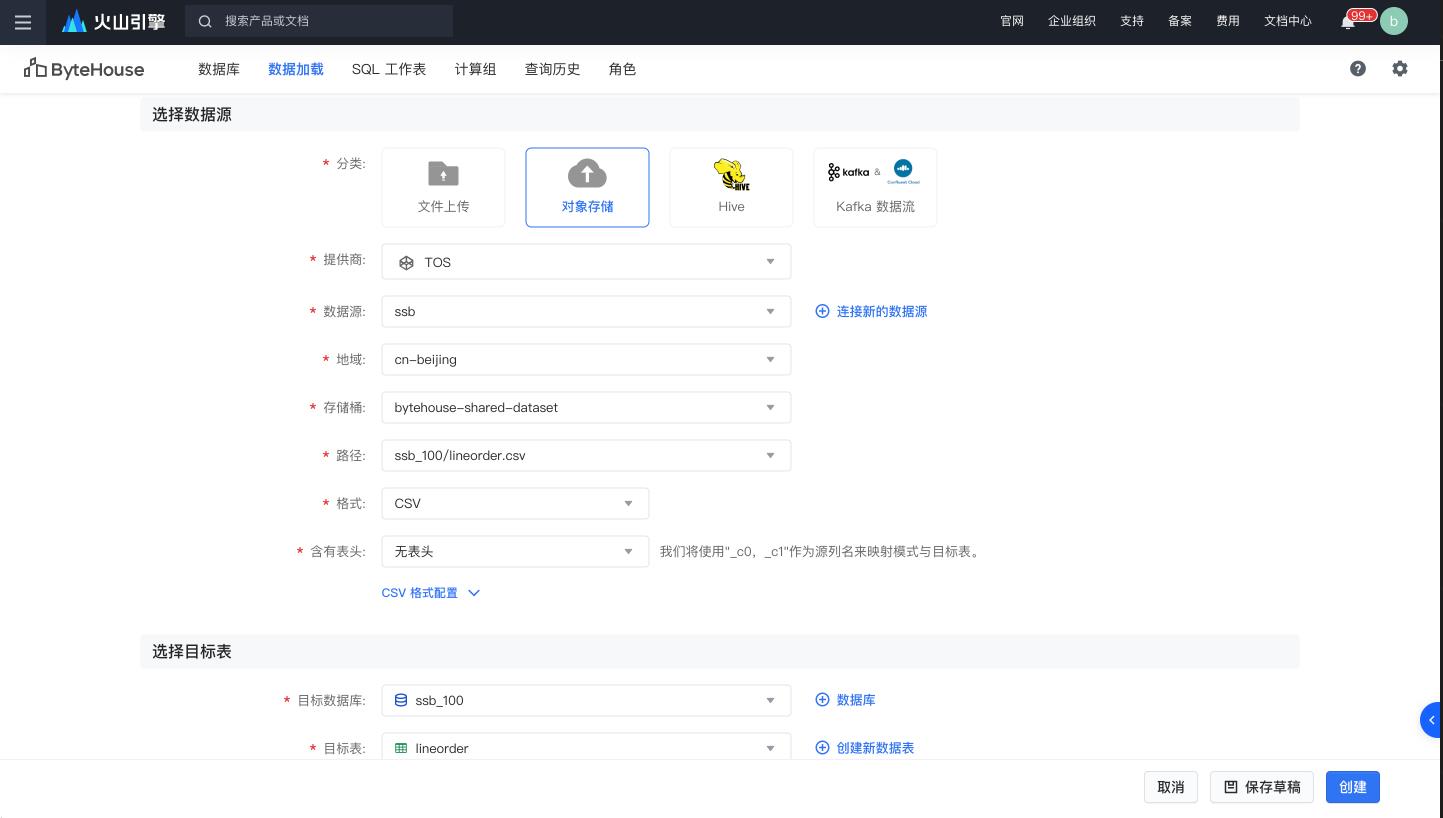
连接新的数据源后,选择 bytehouse-shared-dataset 的储存桶和ssb_100/lineorder.csv 相应的路径
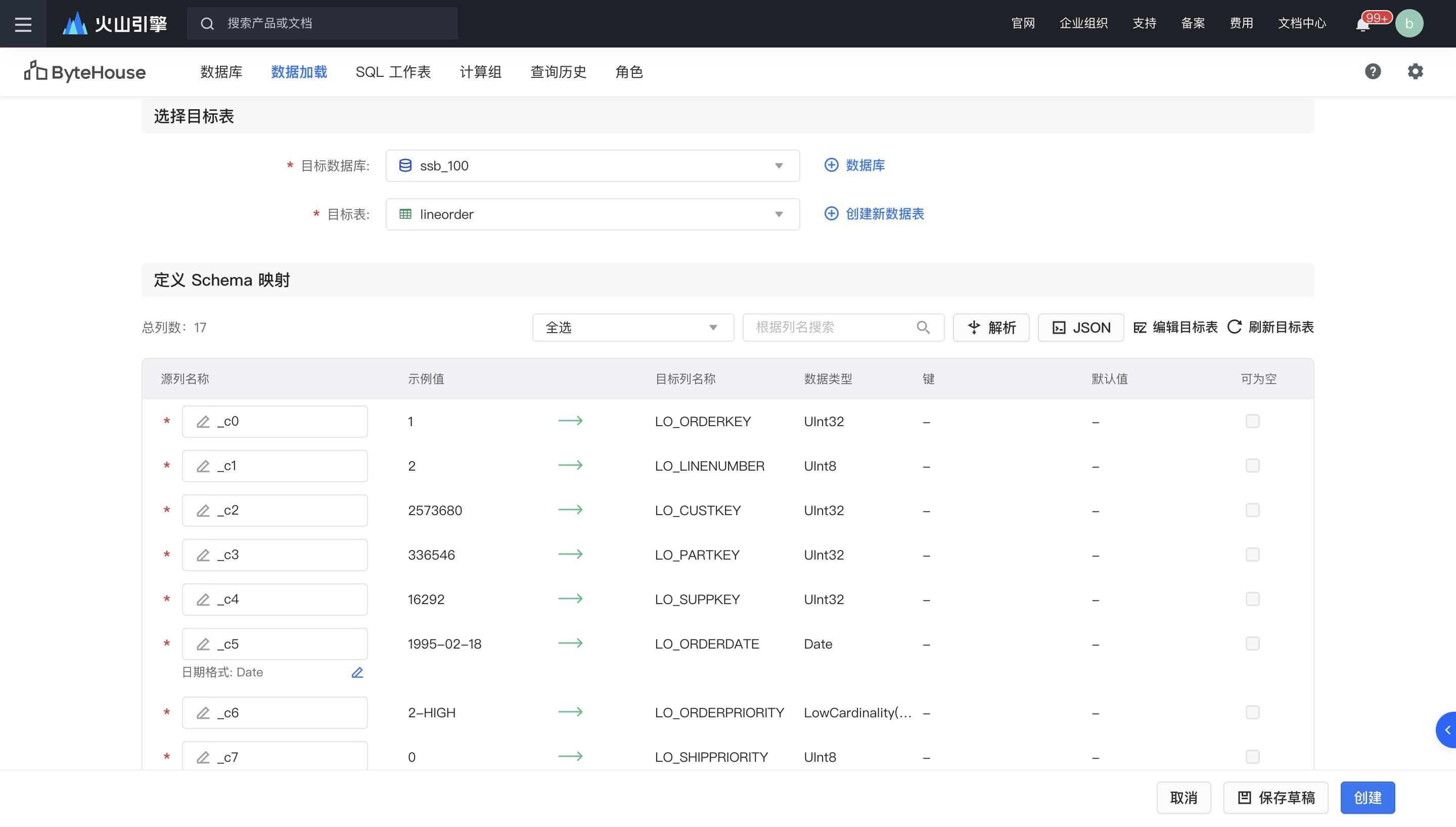
选择之前建的数据库ssb_100和对应标表lineorder,然后按创建。重复步骤为其他四个工作表数据加载。
数据源中存储的数据条数如下所示。用于导入完成后,对数据表的行数进行统计,进行准确性校验。
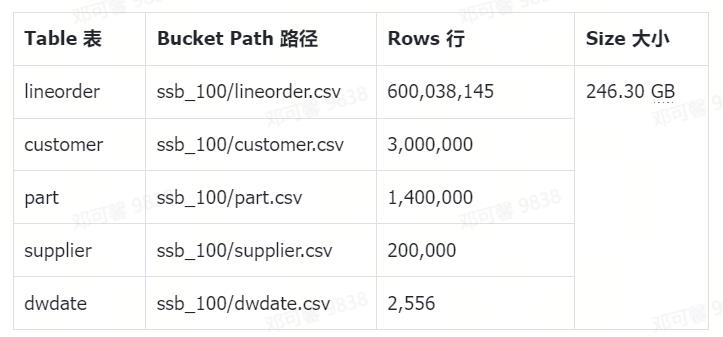
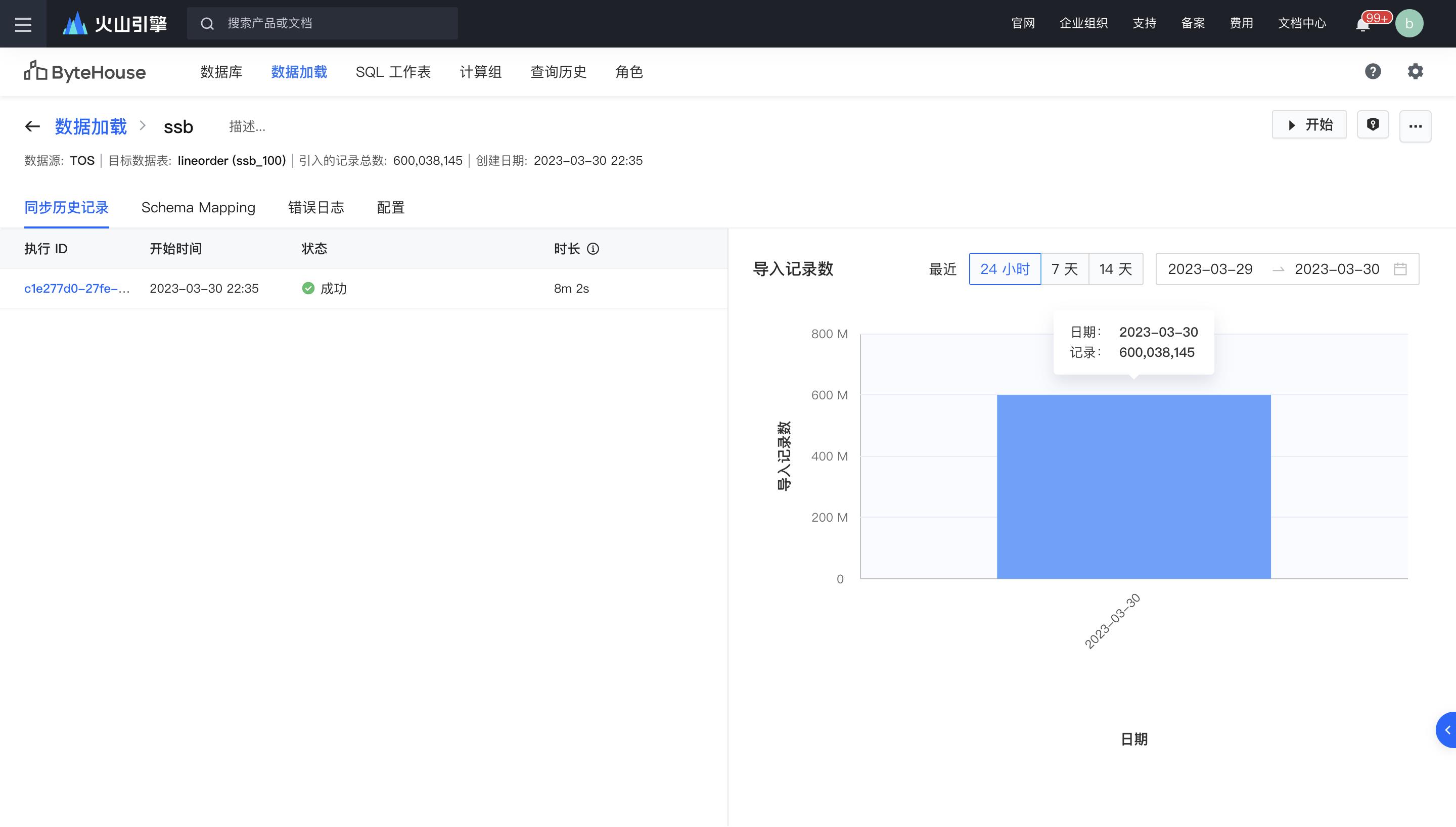
创建导入任务完成后,点击“开始”启动导入任务,任务启动后会在几秒钟内分配资源并初始化导入任务,并在导入过程中展示预估的时间和导入进度。在导入任务的执行详情中,可以查看导入状态、导入详细日志、配置信息等。
步骤五:数据处理及分析
-
原始查询测试
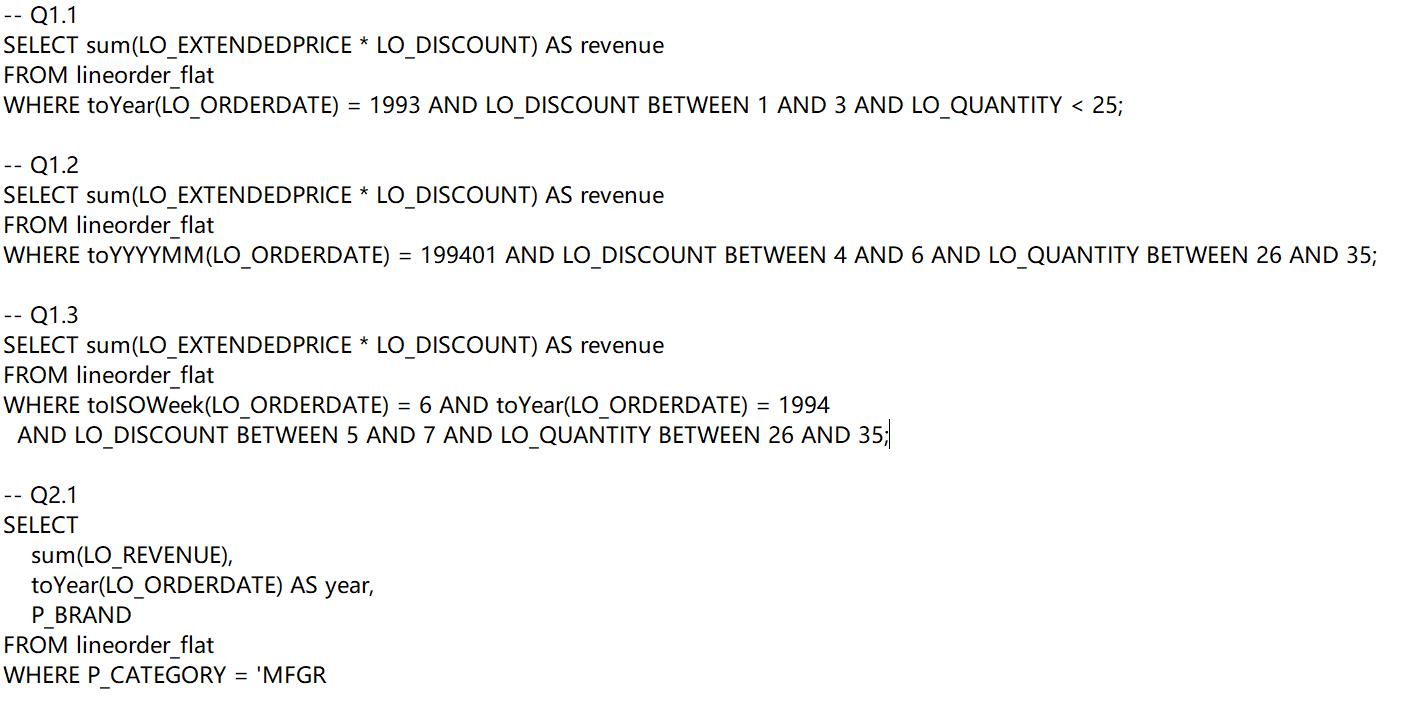
通过执行 SSB 的 13 条查询语句,对于多表关联和排序等场景进行性能测试。查询语句如下所示:

为了方便对 SSB 数据集进行测试,我们可以通过改写 SSB,将星型模型打平转换为大宽表进行分析
注:为了确保打平表的执行,需要配置参数 SET max_memory_usage = 20000000000; 此外需要在 ByteHouse 控制台中配置查询超时为 3600s,避免执行超时导致的失败。
建表完成后,通过执行查询语句进行 SSB 性能测试,如下所示:
III. 查询结果和成本分析
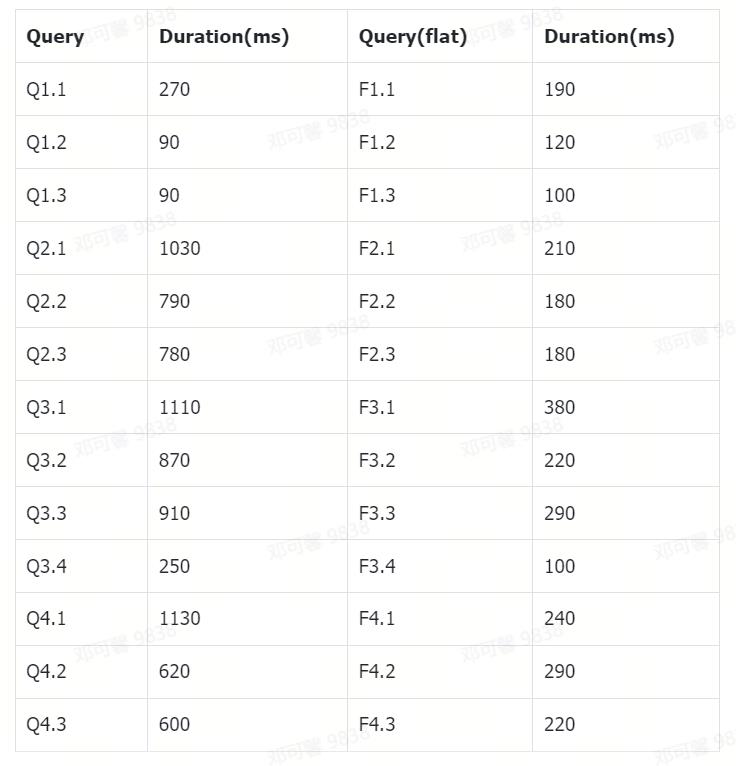
执行完毕后,统计查询结果如下所示:
注:查询结果因配置参数和资源配置的不同,耗时也有差异,欢迎联系 ByteHouse 进行查询优化。
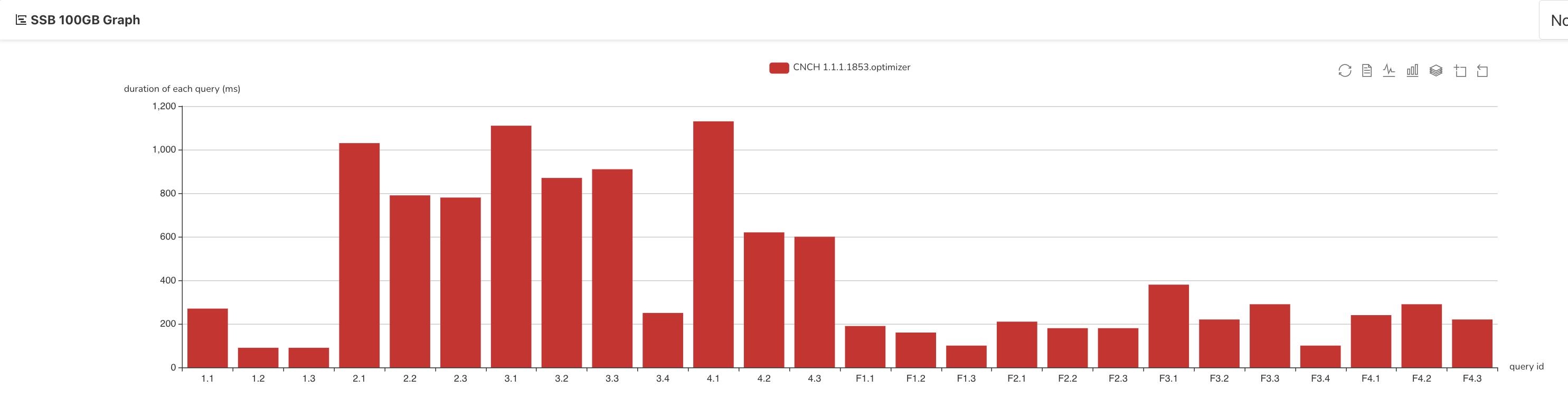
查询完成后,在 ByteHouse 计算组详情页面可以查看工作负载,包括总查询条数和 CPU/Mem 利用率等,从而确认计算资源的使用情况。
根据本次压测进行预估,消耗计算和存储资源如下表所示,由于 ByteHouse 云数仓版本按使用量计费的能力,在空闲时支持自动关闭计算组并不收取闲置费用,从而能够极大的节省资源。测试完成后,预估的总体消耗约为 31.23 元。

点击跳转 ByteHouse云原生数据仓库 了解更多
clickhouse SSB 性能测试
SSB(Star Schema Benchmark)的介绍论文地址:
https://www.cs.umb.edu/~poneil/StarSchemaB.PDF
官网链接 https://clickhouse.com/docs/en/getting-started/example-datasets/star-schema/
如果安装系统时,时最小化mini安装,经常会提示很多命令不存在
- 提示 git 不存在,使用
yum install git安装即可 - 提示
make: command not found,使用以下命令安装 makeyum install -y gcc gcc-c++ automake autoconf libtool make
ssb-dbgen 测试工具 GitHub 地址 https://github.com/vadimtk/ssb-dbgen
下载并编译测试工具
git clone https://github.com/vadimtk/ssb-dbgen.git
cd ssb-dbgen
make
之后就会在当前目录生成 dbgen 和 qgen 这两个可执行文件

|
| 命令 | 结果 |
|---|---|
./dbgen -s 1 -T p | part.tbl |
./dbgen -s 1 -T s | suppliers.tbl |
./dbgen -s 1 -T c | customers.tbl |
./dbgen -s 1 -T d | date.tbl |
./dbgen -s 1 -T l | lineorder.tbl |
./dbgen -s 1 -T a | 一次性生成以上所有表 |
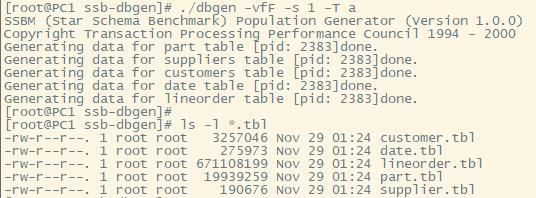
添加 -h 符号,会将文件大小进行格式化,并显示单位
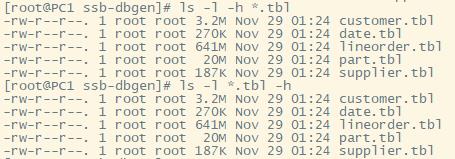
使用 head -n 10 customer.tbl 命令打印前10行可以看到,tbl 文件是用逗号分隔列,然后使用换行符分割行的

这里数据量业界有一个统称叫做SF 1SF == 1G
装载数据 1G -s 1 == 1G #:但这样有一个弊端 那就是如果装载的数据量特别大的时候例如 1T 这样基本需要花费一天的时间 所以我来用多线程的dbgen方法
方法如下:
./dbgen -vfF -s 1000 -S 1 -C 6 &
./dbgen -vfF -s 1000 -S 2 -C 6 &
./dbgen -vfF -s 1000 -S 3 -C 6 &
./dbgen -vfF -s 1000 -S 4 -C 6 &
./dbgen -vfF -s 1000 -S 5 -C 6 &
./dbgen -vfF -s 1000 -S 6 -C 6
参数详解
- -v 详细信息
- -s 表示生成数据的规模
- -S 切分数据
- -f 覆盖之前的文件
dss.ddl 这个文件存储的是建表的语句
cat dss.ddl 逐一执行里面的建表语句
建表语句可以在官网拿到,使用外部工具,比如 DBeaver 建表
CREATE DATABASE IF NOT EXISTS ssb
USE ssb
CREATE TABLE IF NOT EXISTS customer
(
C_CUSTKEY UInt32,
C_NAME String,
C_ADDRESS String,
C_CITY LowCardinality(String),
C_NATION LowCardinality(String),
C_REGION LowCardinality(String),
C_PHONE String,
C_MKTSEGMENT LowCardinality(String)
)
ENGINE = MergeTree ORDER BY (C_CUSTKEY);
CREATE TABLE IF NOT EXISTS lineorder
(
LO_ORDERKEY UInt32,
LO_LINENUMBER UInt8,
LO_CUSTKEY UInt32,
LO_PARTKEY UInt32,
LO_SUPPKEY UInt32,
LO_ORDERDATE Date,
LO_ORDERPRIORITY LowCardinality(String),
LO_SHIPPRIORITY UInt8,
LO_QUANTITY UInt8,
LO_EXTENDEDPRICE UInt32,
LO_ORDTOTALPRICE UInt32,
LO_DISCOUNT UInt8,
LO_REVENUE UInt32,
LO_SUPPLYCOST UInt32,
LO_TAX UInt8,
LO_COMMITDATE Date,
LO_SHIPMODE LowCardinality(String)
)
ENGINE = MergeTree PARTITION BY toYear(LO_ORDERDATE) ORDER BY (LO_ORDERDATE, LO_ORDERKEY);
CREATE TABLE IF NOT EXISTS part
(
P_PARTKEY UInt32,
P_NAME String,
P_MFGR LowCardinality(String),
P_CATEGORY LowCardinality(String),
P_BRAND LowCardinality(String),
P_COLOR LowCardinality(String),
P_TYPE LowCardinality(String),
P_SIZE UInt8,
P_CONTAINER LowCardinality(String)
)
ENGINE = MergeTree ORDER BY P_PARTKEY;
CREATE TABLE IF NOT EXISTS supplier
(
S_SUPPKEY UInt32,
S_NAME String,
S_ADDRESS String,
S_CITY LowCardinality(String),
S_NATION LowCardinality(String),
S_REGION LowCardinality(String),
S_PHONE String
)
ENGINE = MergeTree ORDER BY S_SUPPKEY;
之后定位到 dbgen 生成的目录,使用 pwd 命令,可以打印出当前目录

接下来,使用 clickhouse-client 工具,将 tbl 中的数据导入数据库
clickhouse-client --query "INSERT INTO ssb.customer FORMAT CSV" < customer.tbl
clickhouse-client --query "INSERT INTO ssb.part FORMAT CSV" < part.tbl
clickhouse-client --query "INSERT INTO ssb.supplier FORMAT CSV" < supplier.tbl
clickhouse-client --query "INSERT INTO ssb.lineorder FORMAT CSV" < lineorder.tbl
注意:如果你使用的不是 default 数据库(默认数据库),请在表前面加上数据库前缀,否则会报如下错误

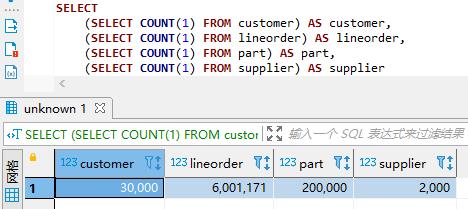
这是维度为1,即 -s 1 情况下的数据量
SELECT
(SELECT COUNT(1) FROM customer) AS customer,
(SELECT COUNT(1) FROM lineorder) AS lineorder,
(SELECT COUNT(1) FROM part) AS part,
(SELECT COUNT(1) FROM supplier) AS supplier
下面这段SQL,会将星型模式(star schema)转化为 非标准化的(denormalized)平面模型(flat schema)。也就是说,将原本相关联的表结构,通过某种关系,整合到一张表里去。
DROP TABLE IF EXISTS ssb.lineorder_flat;
CREATE TABLE ssb.lineorder_flat
ENGINE = MergeTree
PARTITION BY toYear(LO_ORDERDATE)
ORDER BY (LO_ORDERDATE, LO_ORDERKEY) AS
SELECT
l.LO_ORDERKEY AS LO_ORDERKEY,
l.LO_LINENUMBER AS LO_LINENUMBER,
l.LO_CUSTKEY AS LO_CUSTKEY,
l.LO_PARTKEY AS LO_PARTKEY,
l.LO_SUPPKEY AS LO_SUPPKEY,
l.LO_ORDERDATE AS LO_ORDERDATE,
l.LO_ORDERPRIORITY AS LO_ORDERPRIORITY,
l.LO_SHIPPRIORITY AS LO_SHIPPRIORITY,
l.LO_QUANTITY AS LO_QUANTITY,
l.LO_EXTENDEDPRICE AS LO_EXTENDEDPRICE,
l.LO_ORDTOTALPRICE AS LO_ORDTOTALPRICE,
l.LO_DISCOUNT AS LO_DISCOUNT,
l.LO_REVENUE AS LO_REVENUE,
l.LO_SUPPLYCOST AS LO_SUPPLYCOST,
l.LO_TAX AS LO_TAX,
l.LO_COMMITDATE AS LO_COMMITDATE,
l.LO_SHIPMODE AS LO_SHIPMODE,
c.C_NAME AS C_NAME,
c.C_ADDRESS AS C_ADDRESS,
c.C_CITY AS C_CITY,
c.C_NATION AS C_NATION,
c.C_REGION AS C_REGION,
c.C_PHONE AS C_PHONE,
c.C_MKTSEGMENT AS C_MKTSEGMENT,
s.S_NAME AS S_NAME,
s.S_ADDRESS AS S_ADDRESS,
s.S_CITY AS S_CITY,
s.S_NATION AS S_NATION,
s.S_REGION AS S_REGION,
s.S_PHONE AS S_PHONE,
p.P_NAME AS P_NAME,
p.P_MFGR AS P_MFGR,
p.P_CATEGORY AS P_CATEGORY,
p.P_BRAND AS P_BRAND,
p.P_COLOR AS P_COLOR,
p.P_TYPE AS P_TYPE,
p.P_SIZE AS P_SIZE,
p.P_CONTAINER AS P_CONTAINER
FROM ssb.lineorder AS l
INNER JOIN ssb.customer AS c ON c.C_CUSTKEY = l.LO_CUSTKEY
INNER JOIN ssb.supplier AS s ON s.S_SUPPKEY = l.LO_SUPPKEY
INNER JOIN ssb.part AS p ON p.P_PARTKEY = l.LO_PARTKEY;
clickhouse 默认内存大小是1G。在做 SSB 的星型转平面模型的时,如果没有增加最大内存限制,就会报如下错误(DB::Exception: Memory limit (total) exceeded)
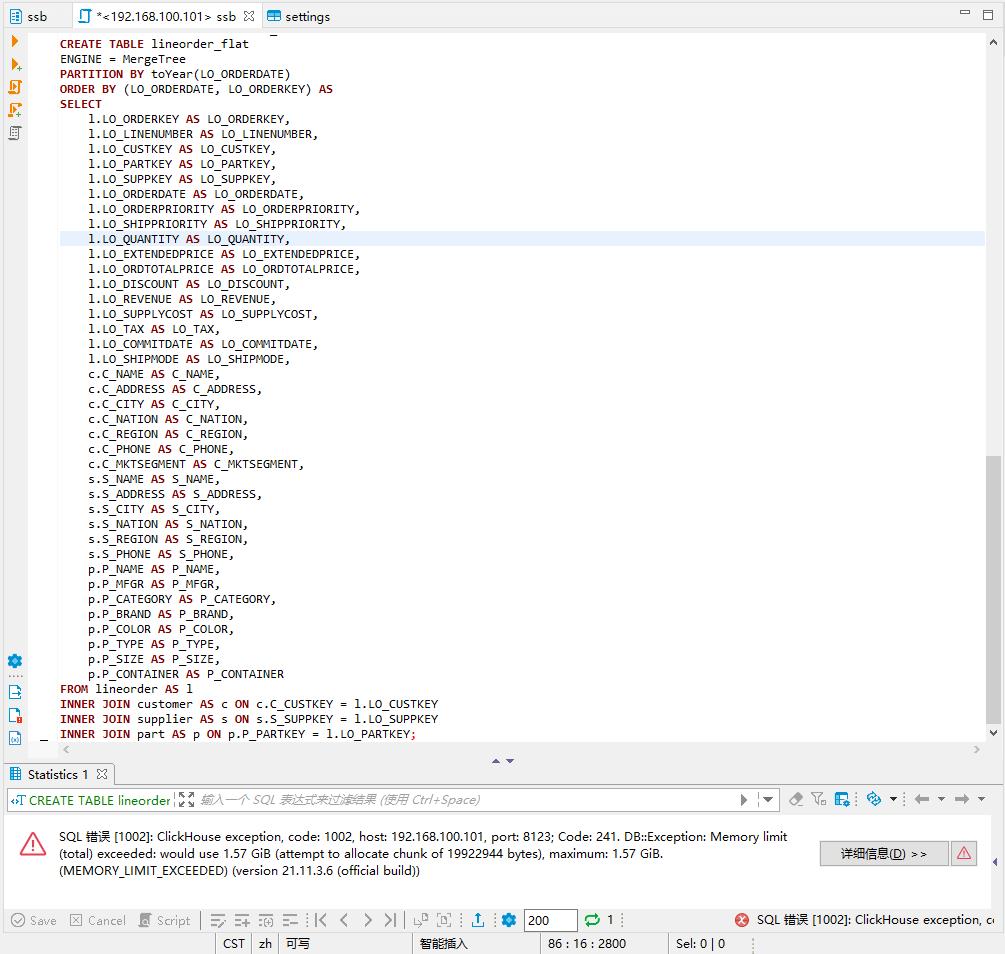
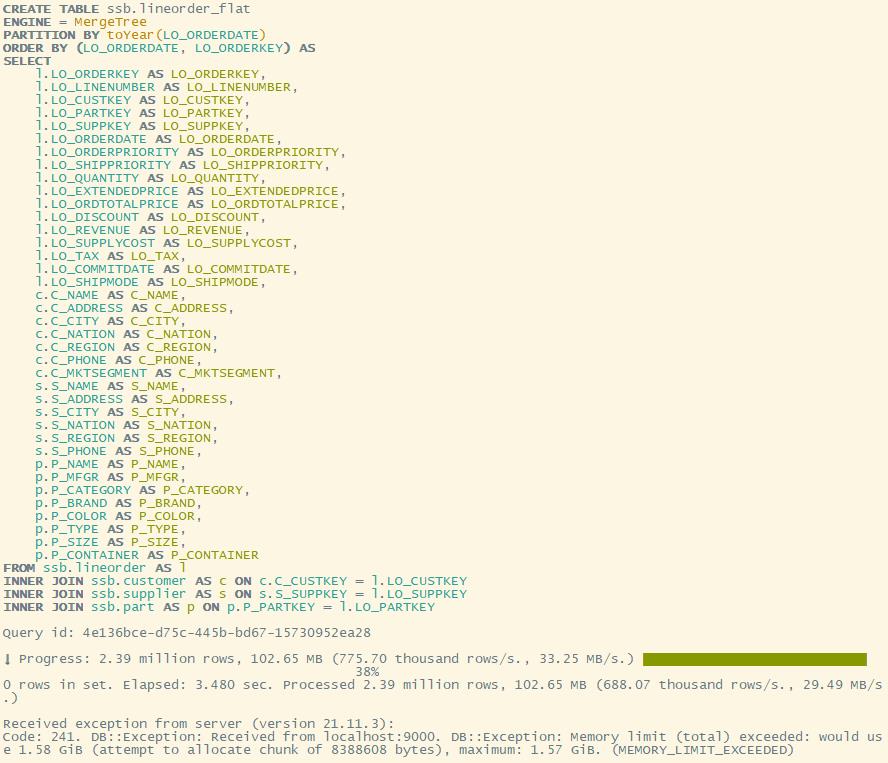
注意:set_memory_usage = 20000000000 这个函数在外部的数据库管理工具,比如DBeaver中是无法设置的。但在 clickhouse-client 中设置却有效(本地或远程均可)。这是因为,该函数仅支持在 TCP 模式下被调用,即 port=9000
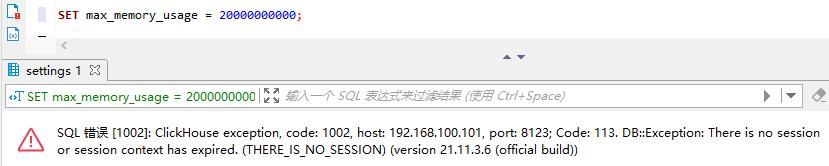
另外,set 函数是针对当前会话的,只要一退出,立马又会还原成之前的样子。
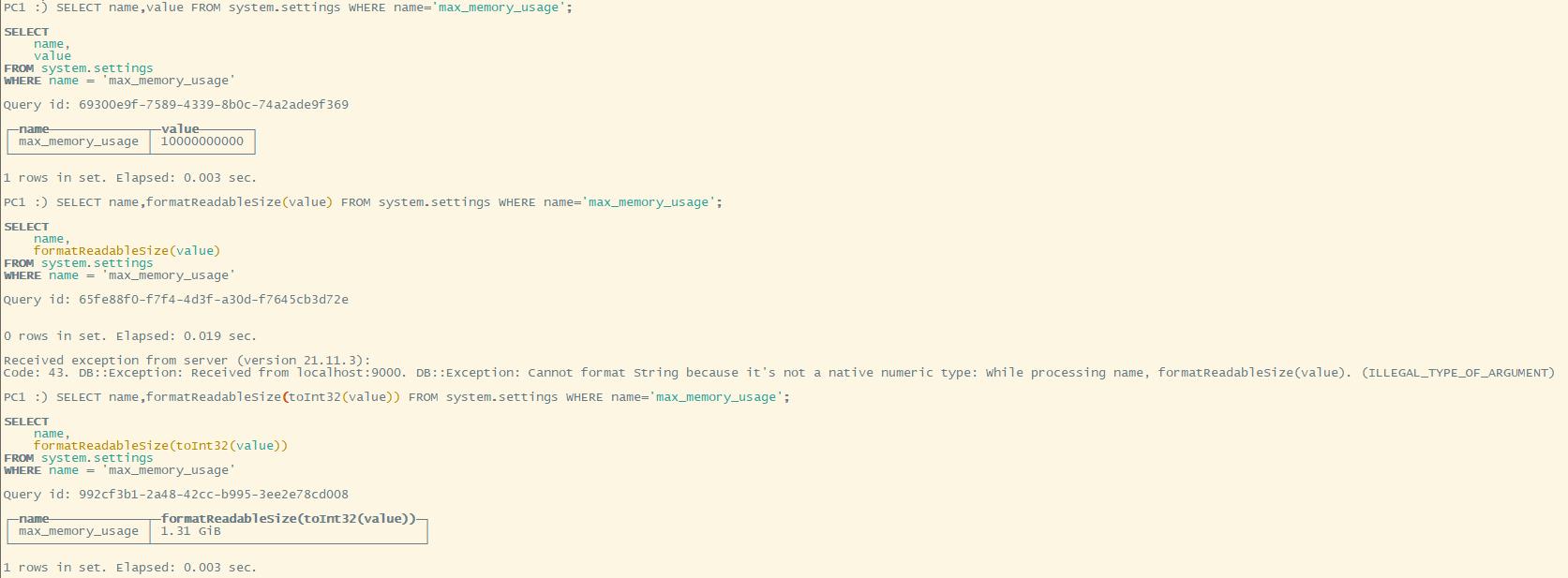
查看变量值的命令为:SELECT name,value FROM system.settings WHERE name = 'max_memory_usage'
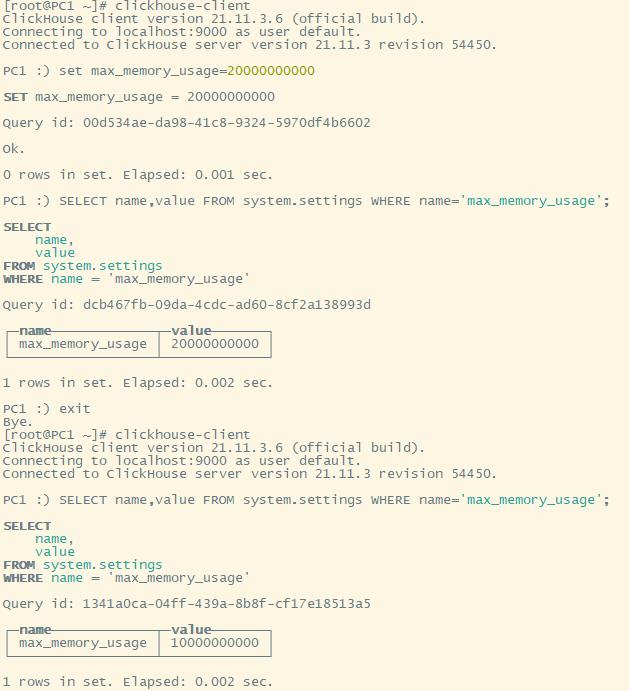
由于0太多,不好数。我们可以使用 formatReadableSize 函数将其格式化。但由于 system.settings 这个表中的 value 是字符串类型的,因此我们必须将起转为 Int 类型,这就要用到 toInt64 函数了(Int32长度不够,会导致数值溢出)
完整的命令如下:SELECT name,formatReadableSize(toInt64(value)) FROM system.settings WHERE name = 'max_memory_usage';
接着先将可用内存增大后,再删除之前创建后转化失败的表,然后进行测试
SET max_memory_usage = 20000000000
DROP TABLE IF EXISTS ssb.lineorder_flat
如果机子内存没有这么大,上述语句无效。但可以通过 SET min_insert_block_size_rows=8192; 减小单次插入块的行大小(默认值为 1048545)这样就能安全通过了。
可以看到在虚拟机3G内存(VMware限制,最大只能3G)下,的速度为:每秒71万行,30MB/S

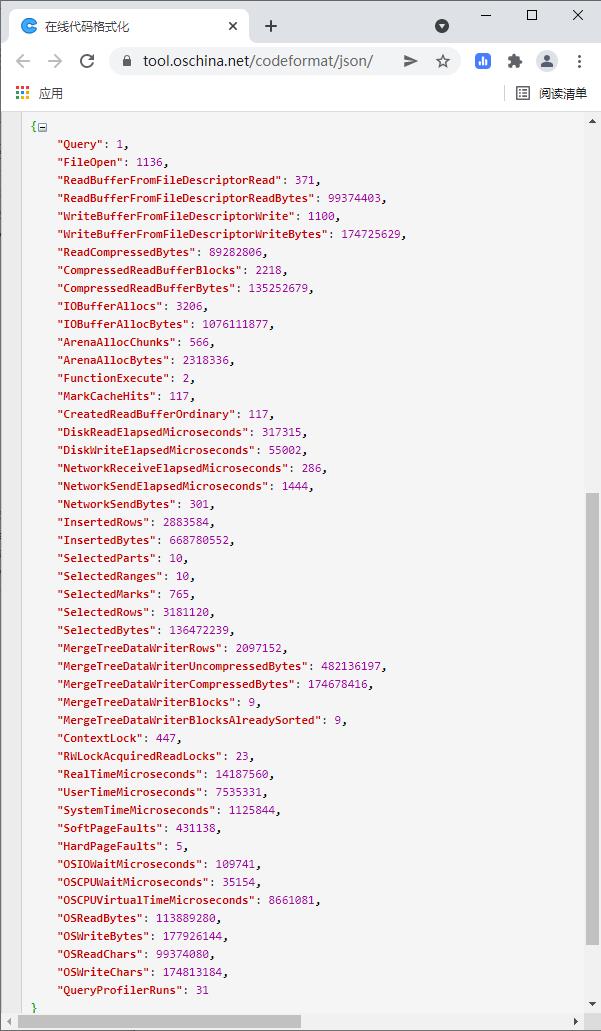
在执行时,打开另一个终端,在clickhouse-client 中执行 SHOW PROCESSLIST 会打印当前执行的进度

将字符串复制出来,把单引号替换成双引号。放在在线JSON格式化页面进行转义
运行下面查询语句(使用 USE ssb; 设置默认数据库)
Q1.1
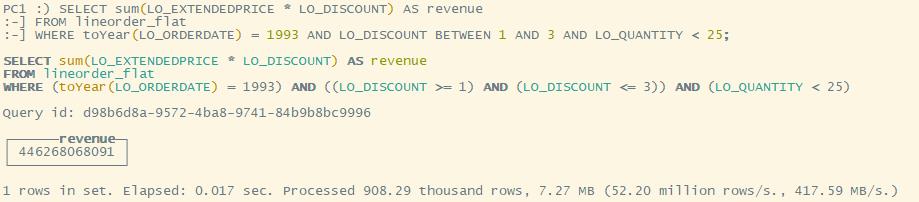
SELECT sum(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue
FROM lineorder_flat
WHERE toYear(LO_ORDERDATE) = 1993 AND LO_DISCOUNT BETWEEN 1 AND 3 AND LO_QUANTITY < 25;
Q1.2
SELECT sum(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue
FROM lineorder_flat
WHERE toYYYYMM(LO_ORDERDATE) = 199401 AND LO_DISCOUNT BETWEEN 4 AND 6 AND LO_QUANTITY BETWEEN 26 AND 35;

Q1.3
SELECT sum(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue
FROM lineorder_flat
WHERE toISOWeek(LO_ORDERDATE) = 6 AND toYear(LO_ORDERDATE) = 1994
AND LO_DISCOUNT BETWEEN 5 AND 7 AND LO_QUANTITY BETWEEN 26 AND 35;

Q2.1
SELECT
sum(LO_REVENUE),
toYear(LO_ORDERDATE) AS year,
P_BRAND
FROM lineorder_flat
WHERE P_CATEGORY = 'MFGR#12' AND S_REGION = 'AMERICA'
GROUP BY
year,
P_BRAND
ORDER BY
year,
P_BRAND;
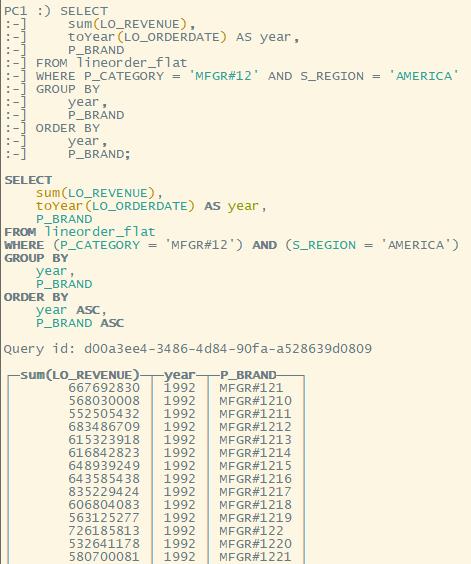
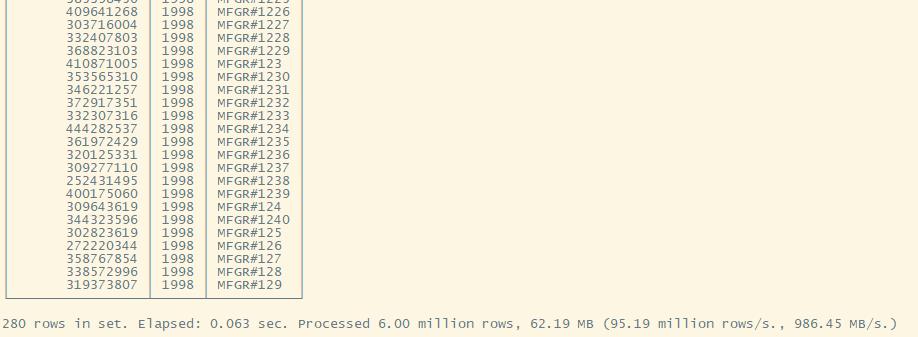
Q2.2
SELECT
sum(LO_REVENUE),
toYear(LO_ORDERDATE) AS year,
P_BRAND
FROM lineorder_flat
WHERE P_BRAND >= 'MFGR#2221' AND P_BRAND <= 'MFGR#2228' AND S_REGION = 'ASIA'
GROUP BY
year,
P_BRAND
ORDER BY
year,
P_BRAND;
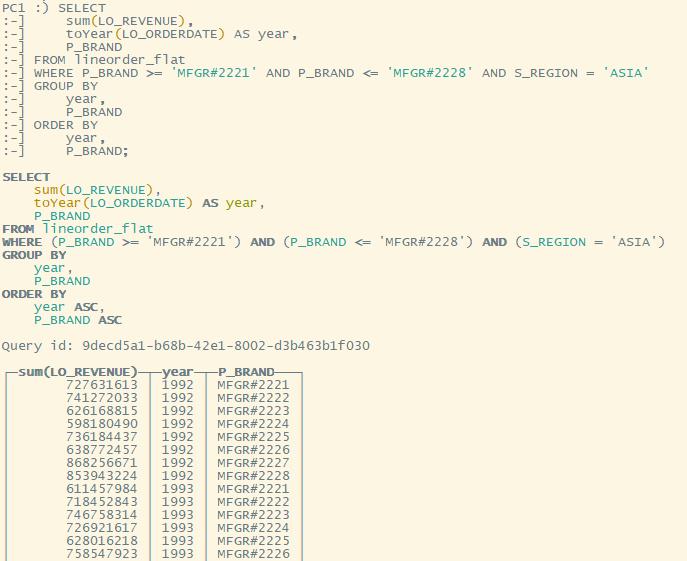
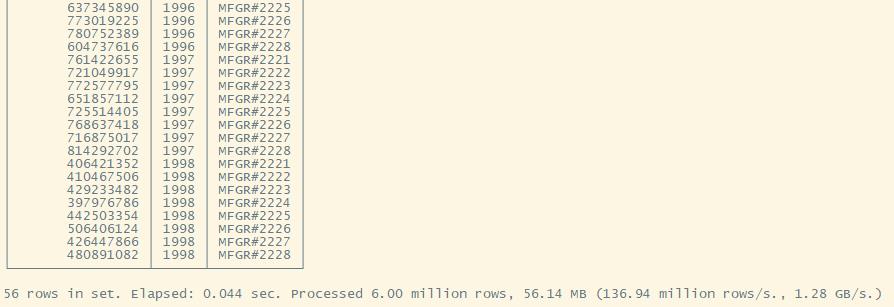
Q2.3
SELECT
sum(LO_REVENUE),
toYear(LO_ORDERDATE) AS year,
P_BRAND
FROM lineorder_flat
WHERE P_BRAND = 'MFGR#2239' AND S_REGION = 'EUROPE'
GROUP BY
year,
P_BRAND
ORDER BY
year,
P_BRAND;
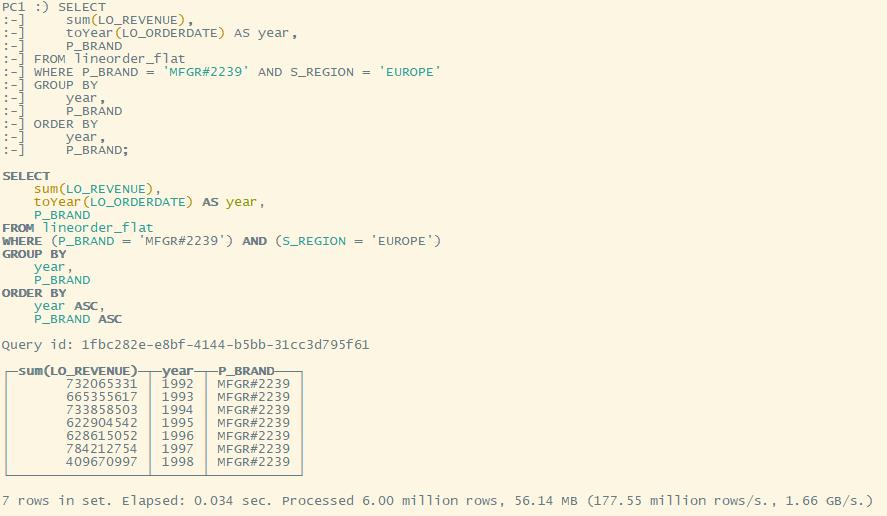
Q3.1
SELECT
C_NATION,
S_NATION,
toYear(LO_ORDERDATE) AS year,
sum(LO_REVENUE) AS revenue
FROM lineorder_flat
WHERE C_REGION = 'ASIA' AND S_REGION = 'ASIA' AND year >= 1992 AND year <= 1997
GROUP BY
C_NATION,
S_NATION,
year
ORDER BY
year ASC,
revenue DESC;
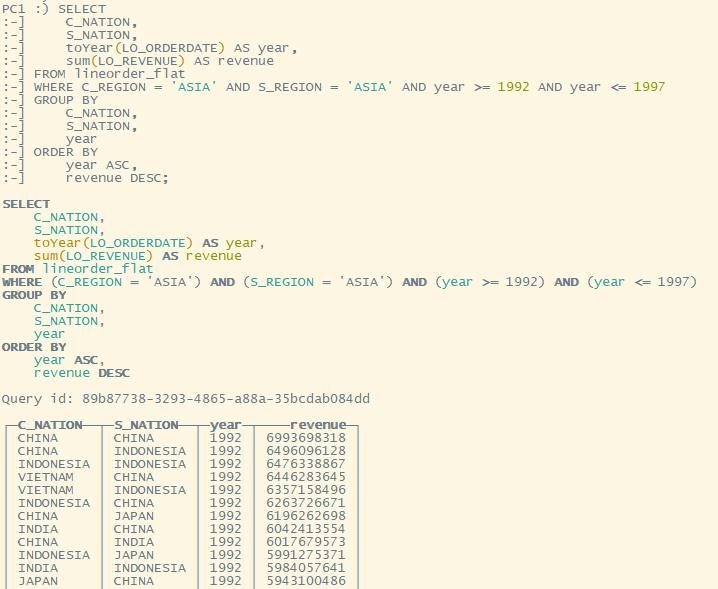
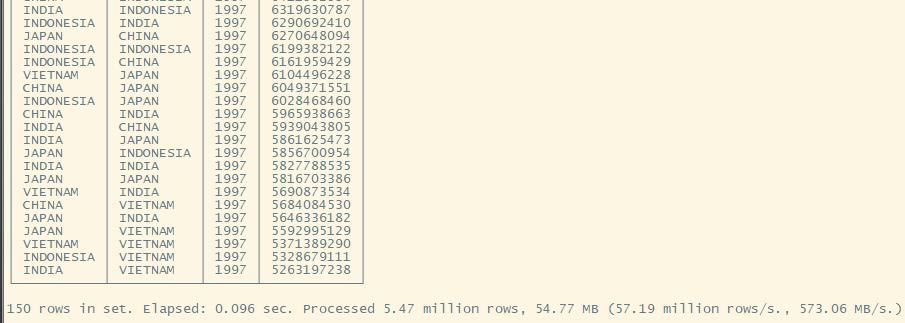
Q3.2
SELECT
C_CITY,
S_CITY,
toYear(LO_ORDERDATE) AS year,
sum(LO_REVENUE) AS revenue
FROM lineorder_flat
WHERE C_NATION = 'UNITED STATES' AND S_NATION = 'UNITED STATES' AND year >= 1992 AND year <= 1997
GROUP BY
C_CITY,
S_CITY,
year
ORDER BY
year ASC,
revenue DESC;
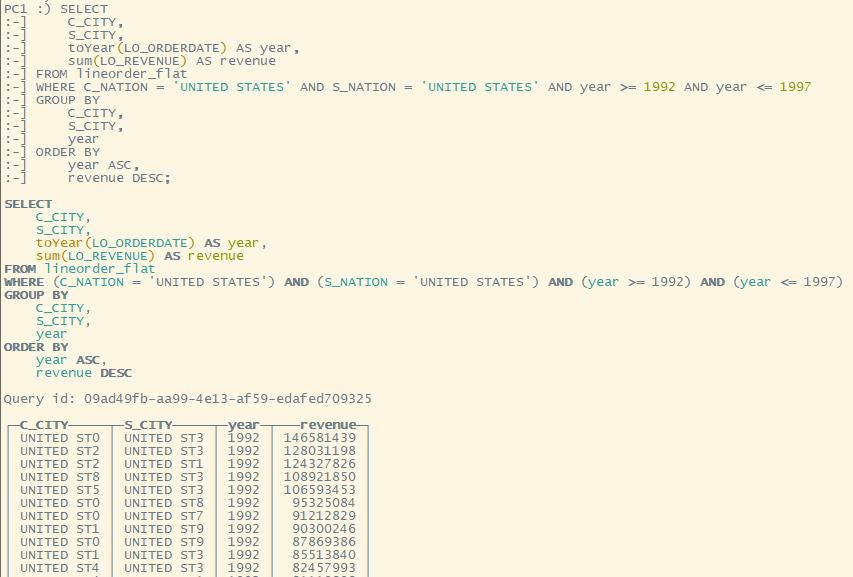
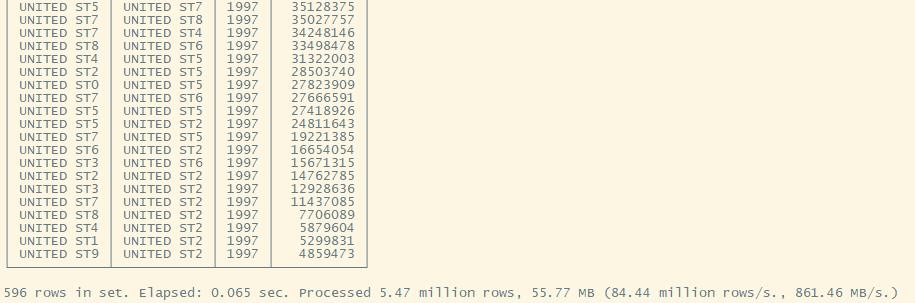
Q3.3
SELECT
C_CITY,
S_CITY,
toYear(LO_ORDERDATE) AS year,
sum(LO_REVENUE) AS revenue
FROM lineorder_flat
WHERE (C_CITY = 'UNITED KI1' OR C_CITY = 'UNITED KI5') AND (S_CITY = 'UNITED KI1' OR S_CITY = 'UNITED KI5') AND year >= 1992 AND year <= 1997
GROUP BY
C_CITY,
S_CITY,
year
ORDER BY
year ASC,
revenue DESC;
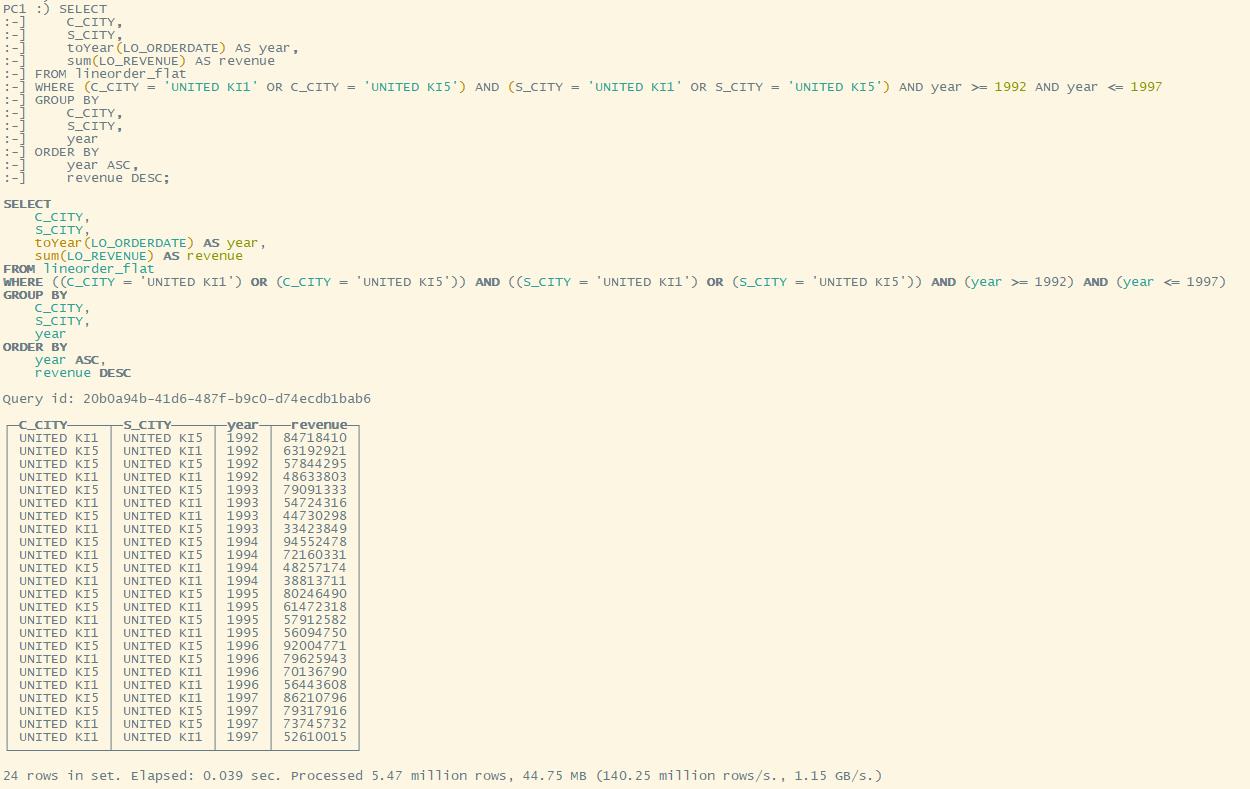
Q3.4
SELECT
C_CITY,
S_CITY,
toYear(LO_ORDERDATE) AS year,
sum(LO_REVENUE) AS revenue
FROM lineorder_flat
WHERE (C_CITY = 'UNITED KI1' OR C_CITY = 'UNITED KI5') AND (S_CITY = 'UNITED KI1' OR S_CITY = 'UNITED KI5') AND toYYYYMM(LO_ORDERDATE) = 199712
GROUP BY
C_CITY,
S_CITY,
year
ORDER BY
year ASC,
revenue DESC;

Q4.1
SELECT
toYear(LO_ORDERDATE) AS year,
C_NATION,
sum(LO_REVENUE - LO_SUPPLYCOST) AS profit
FROM lineorder_flat
WHERE C_REGION = 'AMERICA' AND S_REGION = 'AMERICA' AND (P_MFGR = 'MFGR#1' OR P_MFGR = 'MFGR#2')
GROUP BY
year,
C_NATION
ORDER BY
year ASC,
C_NATION ASC;
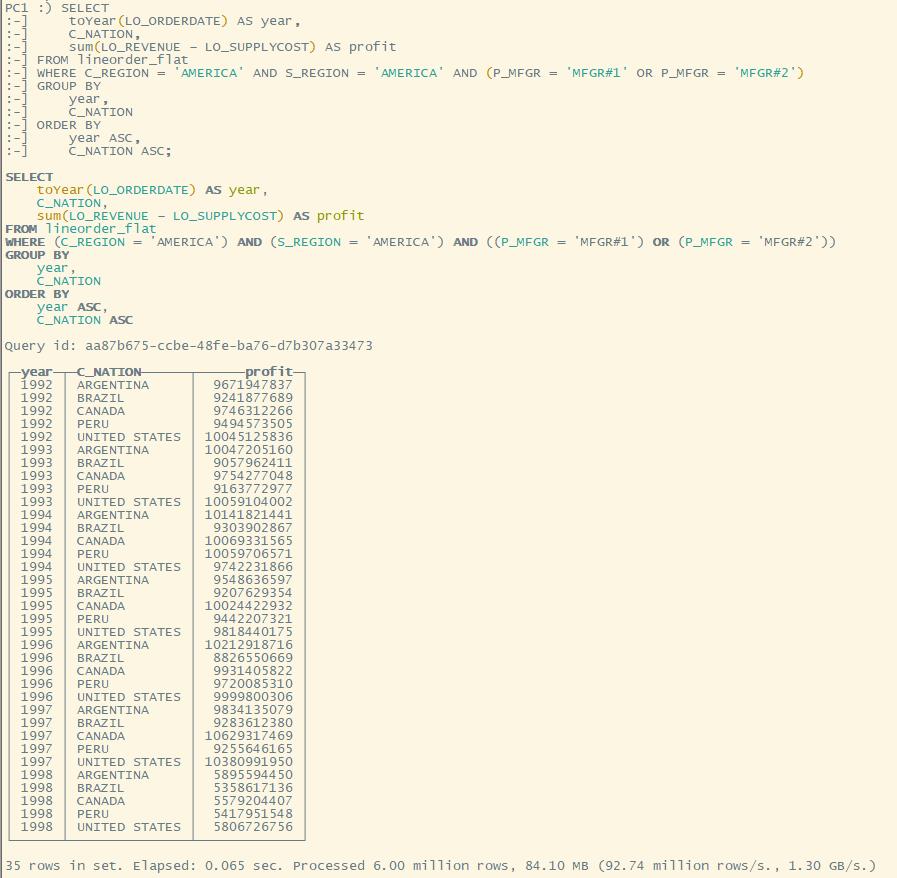
Q4.2
SELECT
toYear(LO_ORDERDATE) AS year,
S_NATION,
P_CATEGORY,
sum(LO_REVENUE - LO_SUPPLYCOST) AS profit
FROM lineorder_flat
WHERE C_REGION = 'AMERICA' AND S_REGION = 'AMERICA' AND (year = 1997 OR year = 1998) AND (P_MFGR = 'MFGR#1' OR P_MFGR = 'MFGR#2')
GROUP BY
year,
S_NATION,
P_CATEGORY
ORDER BY
year ASC,
S_NATION ASC,
P_CATEGORY ASC;
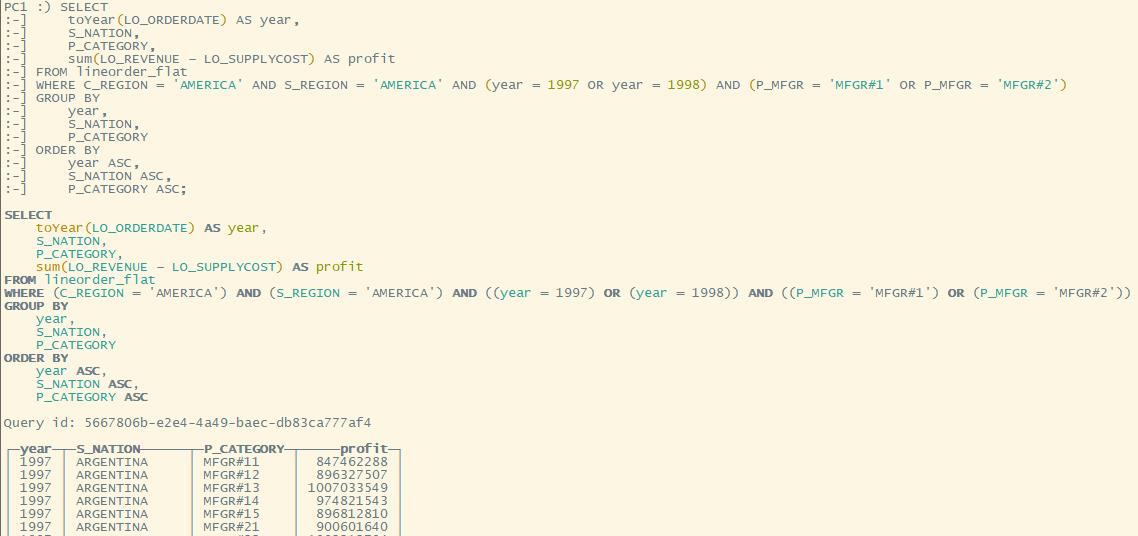
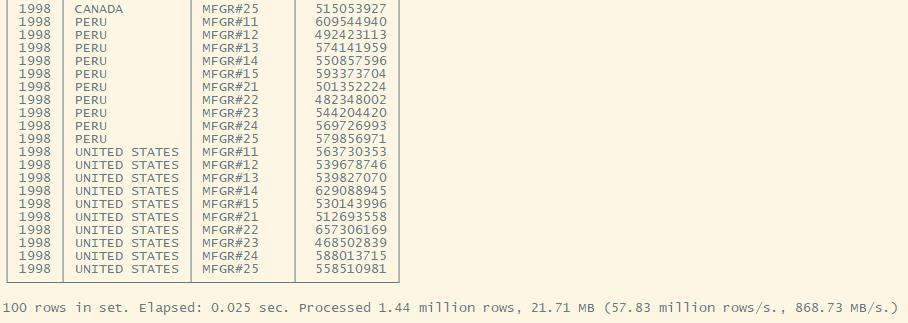
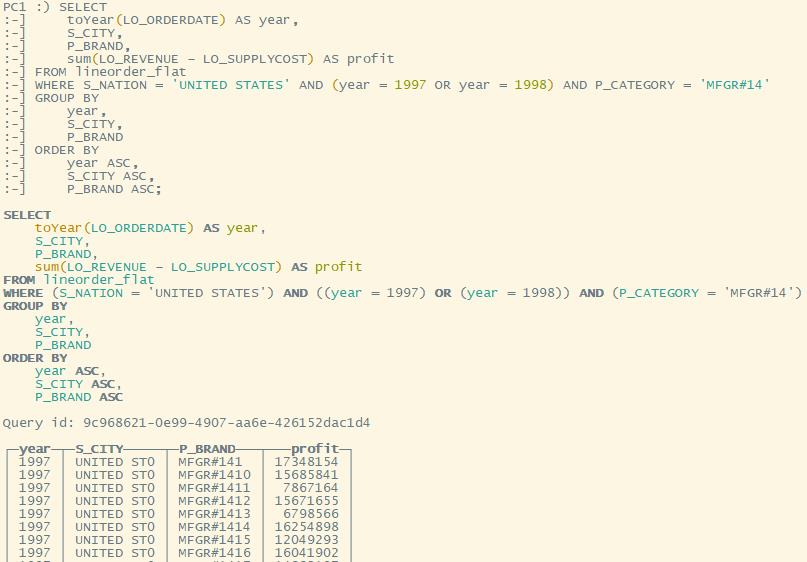
Q4.3
SELECT
toYear(LO_ORDERDATE) AS year,
S_CITY,
P_BRAND,
sum(LO_REVENUE - LO_SUPPLYCOST) AS profit
FROM lineorder_flat
WHERE S_NATION = 'UNITED STATES' AND (year = 1997 OR year = 1998) AND P_CATEGORY = 'MFGR#14'
GROUP BY
year,
S_CITY,
P_BRAND
ORDER BY
year ASC,
S_CITY ASC,
P_BRAND ASC;
以上是关于以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路的主要内容,如果未能解决你的问题,请参考以下文章
苹果芯片(M1/Apple Chip)通过UTM安装x86架构虚拟机指南/性能测试(以ubuntu18.04为例)