QQ空间Python爬虫---网站分析
Posted Stay hungry, Stay foolish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了QQ空间Python爬虫---网站分析相关的知识,希望对你有一定的参考价值。
闲来无事准备写一个爬虫来爬取自己QQ空间的所有说说和图片-。-
首先准备工作,进入手机版QQ空间,分析页面:
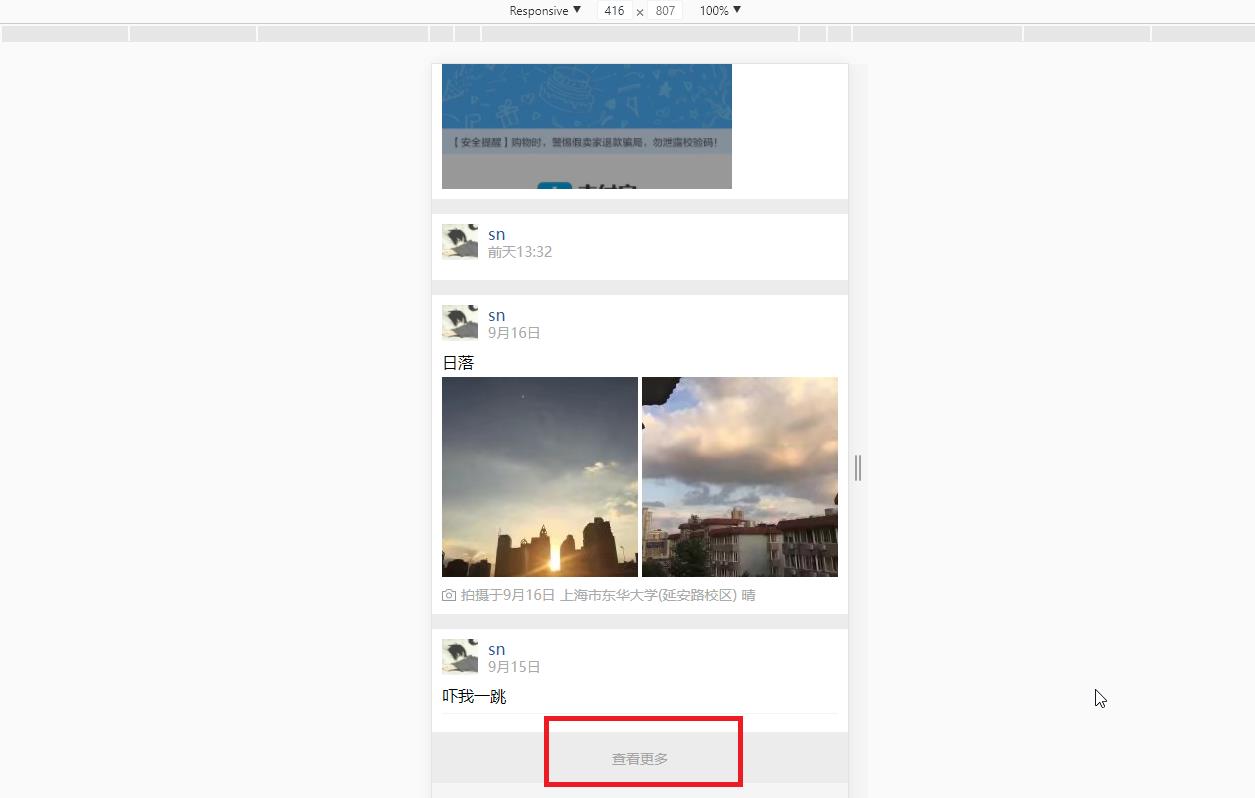
我们发现,手机版空间翻页模式是采用瀑布流翻页(查看更多),而非传统翻页模式,所以我们需要来分析一下点击“查看更多”时发送的请求:

可以发现,上面红框中的xhr就是点击“查看更多”时发送的请求,我们再进一步分析:

如图,红框中的request url和request headers是我们需要的信息,首先我们在代码中加入请求头headers:
1 headers = { 2 \'accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\', 3 \'accept-encoding\': \'gzip, deflate, br\', 4 \'accept-language\': \'zh-CN,zh;q=0.8\', 5 \'cache-control\': \'max-age=0\', 6 \'cookie\': \'xxxxxx\', 7 \'upgrade-insecure-requests\': \'1\', 8 \'user-agent\': \'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Mobile Safari/537.36\' 9 }
cookie可以用来模拟登陆,但是注意此处的cookie会过期,需要每隔一段时间更新cookie内容,比较麻烦,需要找一个更好的解决方案-。-
进一步分析Request URL:

经分析得知,关键在于红线的两个地方,%3D后面的数字代表说说条数,范围0-1758(本人一共1758条说说-。-),count代表单次请求加载的说说数,试验得知最大为count=40。
访问此url,我们发现返回了全为json数据的页面:

由此,我们可以大概确定爬虫的编写思路,访问此Url,以最大加载量40为单位,循环到1758,解析每次访问所得的json数据即可爬取我们的空间说说和图片信息了。
下一章:
以上是关于QQ空间Python爬虫---网站分析的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(103):项目实战--抓取QQ空间说说的内容