Java爬虫QQ空间?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java爬虫QQ空间?相关的知识,希望对你有一定的参考价值。
用Java+Selenium模拟用户登录QQ空间,输入账号,密码都通过了,然后验证码这里好复杂,弄了好久,网上找了好多解决方案,基本上都是失效的,求大佬解决验证码,自己爬自己空间说说来做数据分析的
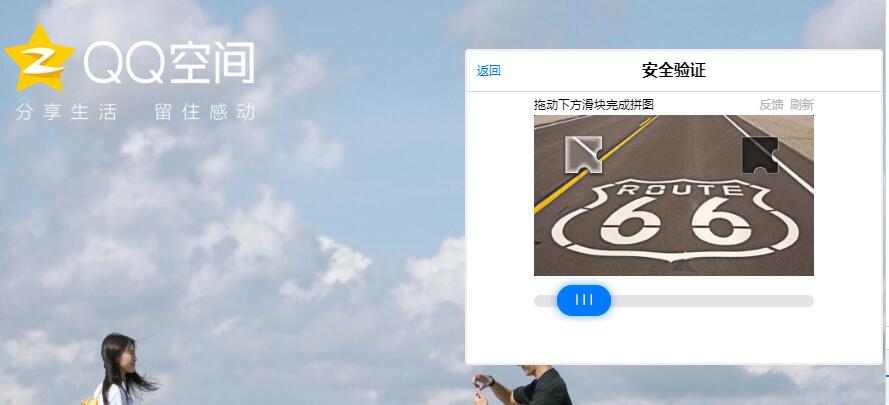
你直接保存某次登录后的cookie信息设置到请求头里,应该就不用验证了;别模拟手动手动输入账号密码去登录
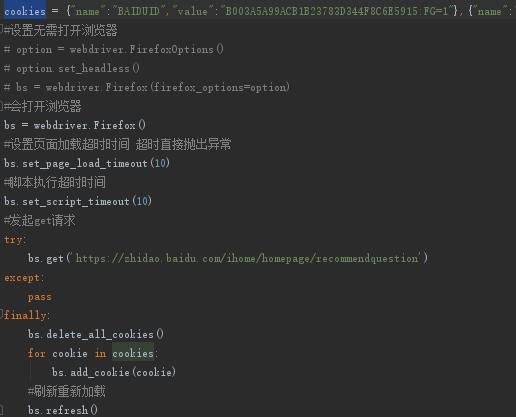
下图是我用python筛选百度知道有金币问题代码中的登录设置
你说cookie失效,你一次性爬取完呗,我就不行你页面没关闭他也给你失效,而且爬完也用不了多久
追问我还是想解决验证码,我想爬空间说说做成一个api接口,只要输入qq号就可以爬说说
追答那你就别怕麻烦用@亚宝1314520的第二种方法,或者你自己想个更牛逼的
参考技术A 如题,用selenium操作浏览器登录网站,验证码是个头疼的问题,翻遍了网上,大概两种方法,第一种手动登录,然后用找到浏览器中登录的cookie,将cookie添加到chromedriver里,跳过登录页面,参考文章:https://blog.csdn.net/ab_2016/article/details/78427084这里说明的第二种,把验证码拿到本地识别,然后输入网站文本框,测试了三十多个网站,测试效果比较理想,正确率高达百分85%追问
第一种试过了,Cookie过一段时间就会失效,第二种技术难度有点难搞,弄了好久
参考技术B QQ空间是需要登陆才能爬取的,所以说首先要做的事进行登陆,这里有两种思路进行模拟登陆:(1)、用selenium+Chrome 进行自动化检测登陆,接着用扫码或者账号自动输入都是可以的,然后获取cookies,再传入requests.Session().get()对要爬取好友的空间进行爬取。
(2)、用opener 和 cookielib 进行对网站cookie的获取,然后再传入requests.Session().get()
我在这里使用的是第一种方法。 参考技术C

直接用QQ登录就行了
QQ空间爬虫分享(2016年11月18日更新)
前言:
上一篇文章:《QQ空间爬虫分享(一天可抓取 400 万条数据)》
Github地址:QQSpider
Q群讨论:
很抱歉QQSpider这个爬虫过了这么久才作更新,同时也很感谢各位同学的肯定和支持!
这次主要替换了程序里一些不可用的链接,对登录时的验证码作了处理,对去重队列作了优化。并且可以非常简单地实现爬虫分布式扩展。
使用说明:
启动前配置:
- 需要安装的软件:python、Redis、MongoDB(Redis和MongoDB都是NoSQL,服务启动后能连接上就行,不需要建表什么的)。
- 需要安装的Python模块:requests、BeautifulSoup、multiprocessing、selenium、itertools、redis、pymongo。
- 我们登陆QQ要使用到phantomJS(下载地址:http://phantomjs.org/download.html),下载完将里面的 phantomjs.exe 解压到python目录下即可。
启动程序:
- 进入 myQQ.txt 写入QQ账号和密码(不同QQ换行输入,账号密码空格隔开)。如果你只是测试一下,则放三两个QQ足矣;但如果你开多线程大规模抓取的话就要用多一点QQ号(thread_num_QQ的2~10倍),账号少容易被检测为异常行为。
- 进入 init_messages.py 进行爬虫参数的配置,例如线程数量的多少、设置爬哪个时间段的日志,哪个时间段的说说,爬多少个说说备份一次等等。
- 运行 launch.py 启动爬虫。
代码说明:
- mongodb用来存放数据,redis用来存放待爬QQ和Cookie。
- 爬虫之前使用的是BitVector去重,有一部分人反映经常会报错,所以现在使用基于Redis的位去重,内存占用不超过512M,能容纳45亿个QQ号瞬间去重,而且方便分布式扩展。
- 爬虫使用phantomJS模拟登陆QQ空间,有时候会出现验证码。我使用的是云打码(自行百度),准确率还是非常高的,QQ验证码是4位纯英文,5元可以识别1000个验证码。如果需要请自行去注册购买,将账号、密码、appkey填入 yundama.py,再将 public_methods.py 里的
dama=False改成dama=True即可。 - 分布式。现在已经将种子队列和去重队列都放在了Redis上面,如果需要几台机器同时爬,只需要将代码复制一份到另外一台机子,将连Redis时的
localhost改成同一台机器的IP即可。如果想要将爬下来的数据保存到同一台机,也只需要将连MongoDB时的localhost改成该机器的IP即可。 - 为了让程序不那么复杂难懂,此项目只用了多线程,即只用到了一个CPU。如果实际生产运行的话可以考虑将程序稍作修改,换成多进程+协程,或者异步。速度会快很多。
- 最后提醒一下,爬虫无非就是模仿人在浏览器上网的行为,你在浏览器上无法查看的信息爬虫一般也是无法抓取。所以,就不要再问我能不能破解别人相册的这种问题了,空间加了访问权限的也无法访问。程序输出的日志中
2016-11-19 01:05:33.010000 failure:484237103 (None - http://user.qzone.qq.com/484237103)这种,一般就是无法访问的QQ。还有,我们是无法查看一个QQ的所有好友的,所以爬下来的好友信息也只是部分好友。爬虫不是黑客,希望理解。
结语:
- 爬虫是偏后台型的任务,以抓取效率为主,并没有很好的用户界面,并且需要不断地维护。所以对于完全没有编程基础的人来说,可能会遇到各种各样的问题。此项目最初的目的是为大家提供QQ空间爬虫的一种架构,并不保证程序一直能跑。只要腾讯服务器端稍有变动,例如某一个链接变了,可能程序就抓不到数据了,此时程序也要相应地将链接换成新的,如果网页结构变了,解析规则也要相应地修改。
- 有同学反映,爬QQ空间的很多都是学生想爬一些数据做统计研究的,本不是计算机专业,爬起来比较困难,希望有现成的数据出售。但是因为工作变动,其实今年3月份 程序开发完后我就没有跑过了,所以手上也没有数据。不过接下来我会开一两台机器跑这个爬虫,如果需要数据可以邮件联系我(bone_ace@163.com)。
- 有什么问题请尽量留言,方便后来遇到同样问题的同学查看。
转载请注明出处,谢谢!(原文链接:http://blog.csdn.net/bone_ace/article/details/53213779)
以上是关于Java爬虫QQ空间?的主要内容,如果未能解决你的问题,请参考以下文章