文献阅读——The Augmented Image Prior Distilling 1000 Classes by Extrapolating from a Single Image
Posted tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献阅读——The Augmented Image Prior Distilling 1000 Classes by Extrapolating from a Single Image相关的知识,希望对你有一定的参考价值。
Y. M. Asano and A. Saeed, ‘THE AUGMENTED IMAGE PRIOR: DISTILLING 1000 CLASSES BY EXTRAPOLATING FROM A SINGLE IMAGE’, 2023.
ICLR2023,阿姆斯特丹大学和埃因霍芬理工大学两位共同作者
如题目所示,作者探究神经网络如何从单个数据中进行泛化。结合了数据增广DA和知识蒸馏KD的相关算法。没有提出较新颖的方法或结构,而是引出一个较新的应用场景,并且做了详尽的实验。
Introduction
作者希望探究神经网络学习语义信息的最小数据要求是什么。这一研究来源于婴儿早期视觉发展的启发——婴儿前几个月接触到的视觉多样性很少,却可以发展出一套视觉系统。本文中,作者以最简单的形式研究这个问题,即,神经网络能不能从单个数据中学习extrapolate。
然而解决这个问题遇到了以下困难:
- 当前深度学习方法很多是为大数据集量身定制的,比如BN或SGD。
- 需要单个数据之外的自然图像的空间信息的语义类别信息来帮助推断
对于第一点,作者使用数据增广解决,当然,这里的增强与其在普通情况下的使用是不同的,普通应用场景下的DA是为了“implicitly encode desirable invariances during training”,算是一种不破坏数据流形而让网络对数据分布了解更好的正则化方法。
对于第二点,本文方法选择使用有监督训练模型的输出和知识蒸馏算法。使用知识蒸馏算法提供训练过程中需要的语义类别信息(感觉这下任务有点像Data-Free Knowledge Distillation啊)

Method
这是我目前见过method占比例最低的论文,算上Appendix三十页的论文,method只有半页。主要也是因为没有提出新的框架。作者自己也说,就是将一篇工作的DA方法和另一篇工作的蒸馏方法结合在一起
1. Dataset generation
Y. M. Asano, C. Rupprecht, and A. Vedaldi, ‘A critical analysis of self-supervision, or what we can learn from a single image’
ICLR 2020,三位作者都是牛津大学视觉几何组的
这貌似是自监督一篇有不错知名度的工作,截至目前被引量119。如论文标题,作者在文中对现在的自监督学习方法能否有效学习到图像的特征表示了怀疑
作者训练了三类涨点效果比较好自监督方法:
- 生成模型,使用BiGAN。
- 旋转,使用RotNet,通过旋转图像产生伪标签。
- 聚类,使用DeepCluster,通过图像聚类产生伪标签。
我们更关注的是作者用了怎样的DA手段:
对于训练数据,假设共有d张图像,作者对其进行了修改,挑选其中N张图像(N远远小于d),对这N张图像进行数据增广,增广为d-N张,连同之前的N张图,又组成一个d张图的数据集。这样,通过控制N的大小,就可以控制训练数据中图像的数量。注意这里生成的增强的图像其实相对原图是小patch
具体的增广技术细节是:给定一个 \\(W\\times H\\) 的图像,取一个 \\(w\\times h\\) 的patch,有面积比约束 \\(\\beta\\leq\\fracwhWH\\) 和长宽比约束 \\(\\gamma\\leq\\frac hw\\leq\\gamma^-1\\) ,作者这里取 \\(\\beta=10^-3,\\gamma=\\frac34\\) ,图像被旋转角度也有限制 \\(\\alpha\\in(-35,35)度\\) 且有一半的概率被左右镜像。
作者选择从浅到深的五层卷积神经网络特征通过预训练产生特征后使用linear probes来测试这些特征的好坏。由于linear probes是一个线性分类模型,其模型复杂度低,因此分类结果主要取决于特征。
作者通过实验发现,对于卷积网络的浅层特征,使用单张图像的自监督学习学到的特征表示要优于使用大量图像的自监督学习,甚至超过了监督学习的结果;随着网络层数的加深,学习到的特征表示越来越差
由此作者得到了以下结论:
深度网络浅层的权重包含有限的自然图像的统计信息;
浅层的统计信息可以通过自监督学习,和监督学习获得的效果是类似的;
浅层的统计信息能够从单张图像及其合成转换(数据增强)中获得,而不需要大量数据集。
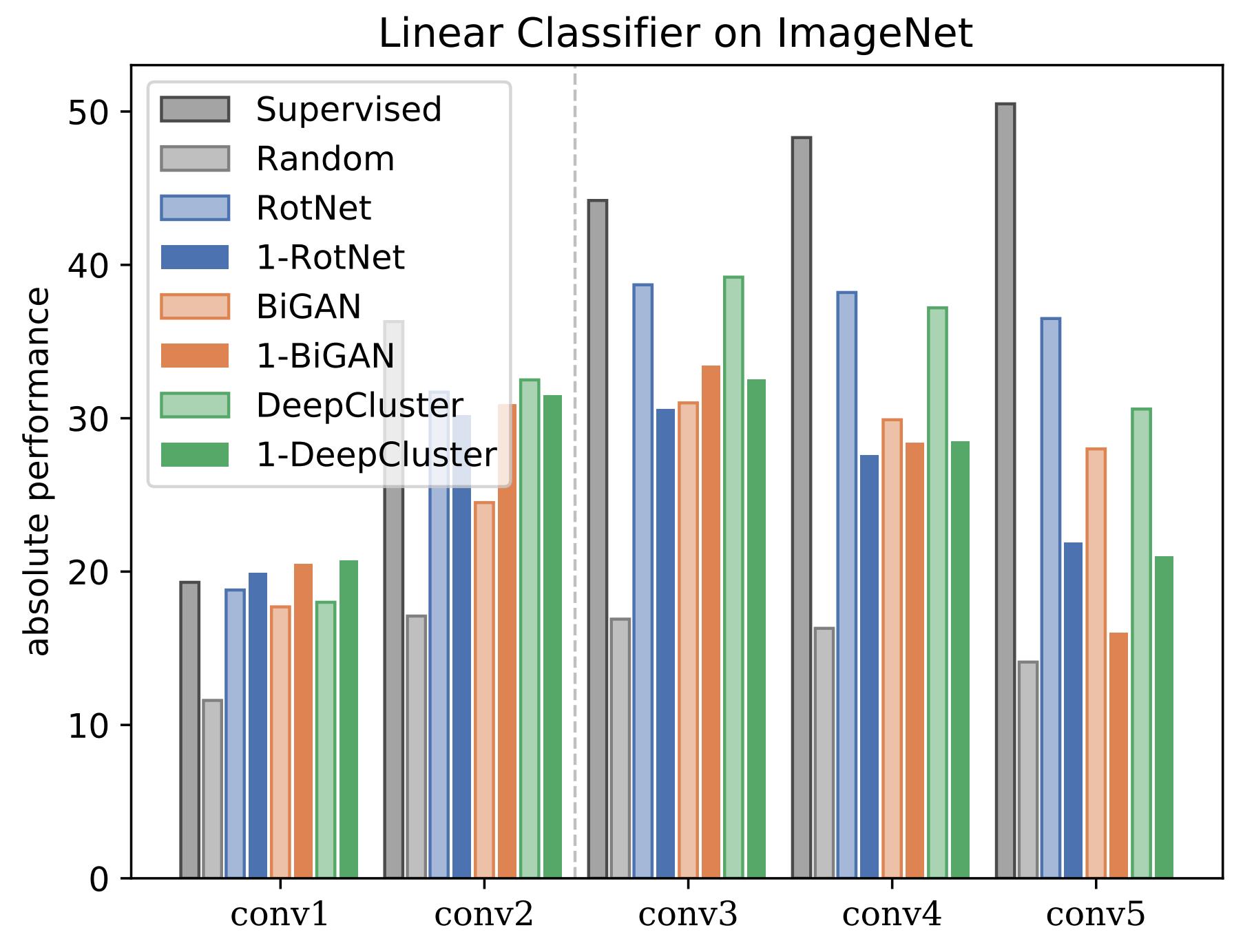
上面引用的那篇工作 A critical analysis of self-supervision, or what we can learn from a single image 和本篇都是从单一图像中进行数据增广生成单一尺寸的静态数据集,因此本文作者采用了前者作者的方法,连超参都没改。(作者还做了音频的数据增强,略去不表)
2. Knowledge distillation
L. Beyer, X. Zhai, A. Royer, L. Markeeva, R. Anil, and A. Kolesnikov, ‘Knowledge distillation: A good teacher is patient and consistent’, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA: IEEE, Jun. 2022, pp. 10915–10924. doi: 10.1109/CVPR52688.2022.01065.
CVPR 2022,作者都是谷歌的(这里面好几位都是VIT的作者)
我们先把谷歌最擅长的
财大气粗力大砖飞的详尽实验放到一边,主要搞清楚作者在做什么。就如题目所说,作者要求一个teacher必须 patient 并且 consistent。
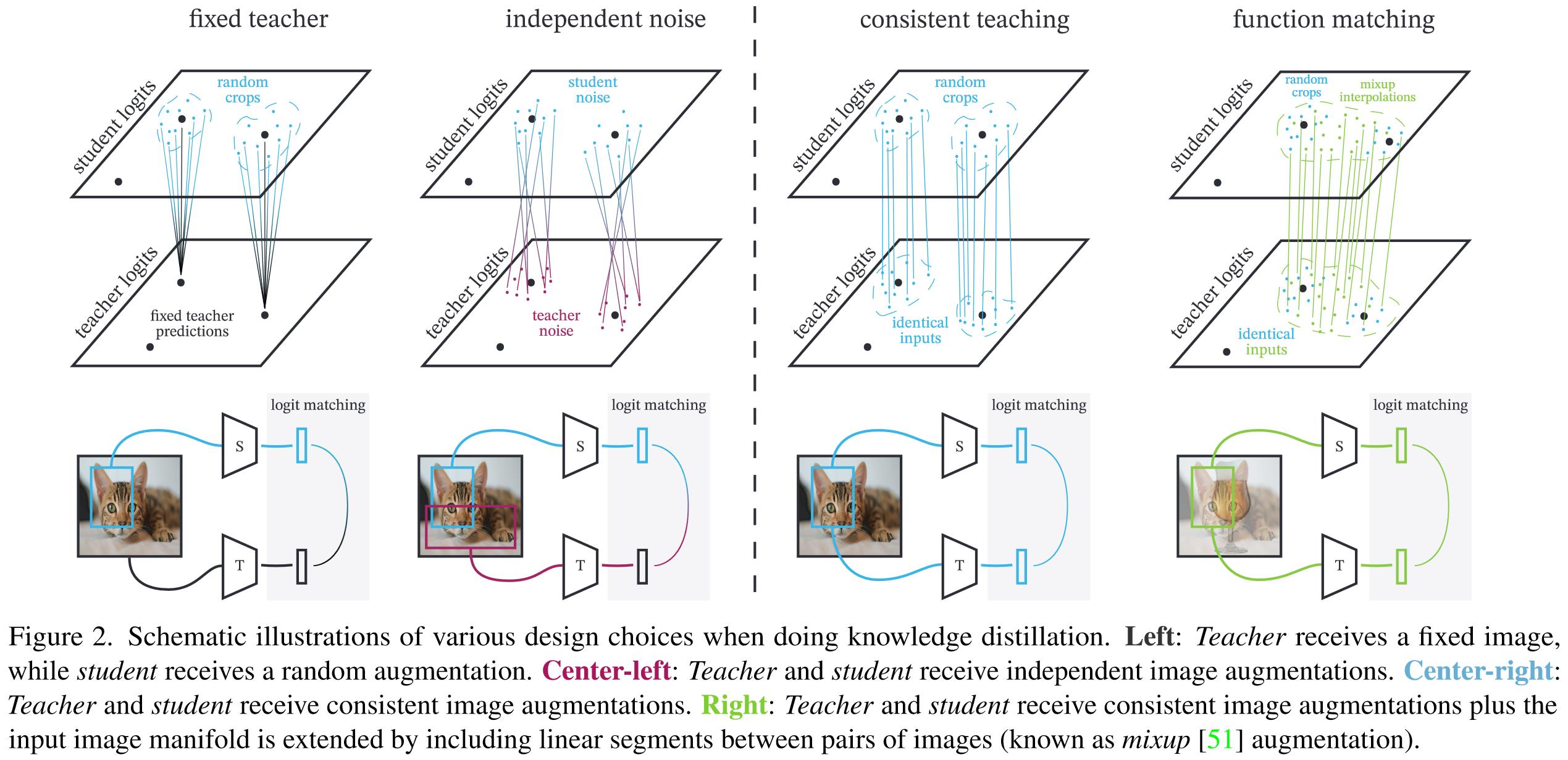
patient来自作者的实验,即,输入整张图片的蒸馏不如将图片进行crop后用小patch进行蒸馏(我觉得这可以用
Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning的理论解释,因为一张图片有识别度的视图特征可能会有很多,比如车窗车灯轮胎都能用来识别一辆车。直接用全图蒸馏可能会导致学生记住较少的视图特征,而辨别其他视图特征的能力在蒸馏过程中减弱或流失)。但是用小patch蒸馏需要的epoch肯定要更多,所以需要teacher更patient。consistent的思路也很清晰,就是我们将神经网络视作一个映射,那么知识蒸馏的目的就是尽可能让学生的这个映射函数和老师一致
那么我们由此就consistent可以想到以下几点(一家之言,没有按照论文思路叙述)
- 蒸馏过程中,应该尽可能排除数据增强带来的独立性噪声,比如同一张图片,分别为老师和学生进行两种独立的random crop操作再输入,这会导致可能两个patch中特征视图差异很大,但是我们却强制teacher和student有相同的输出,这显然对一致性时有害的。因此,我们应当用完全相同的DA策略(same input)来蒸馏(same output),作者称之为consistent teaching
- 训练时输入的可以不是真实存在的数据,扩展到实际数据之外的流形也未尝不可。因此我们可以采用其他的正则化和增强手段以进一步约束蒸馏使得一致性更好,比如mixup,作者称之为function matching。
理论分析示意图如下图:
篇幅原因,实验略
上面介绍的工作没有复杂的trick,拿来即用。作者采用了Mixup和cutmix来增广,然后用KL散度来蒸馏
Experiment
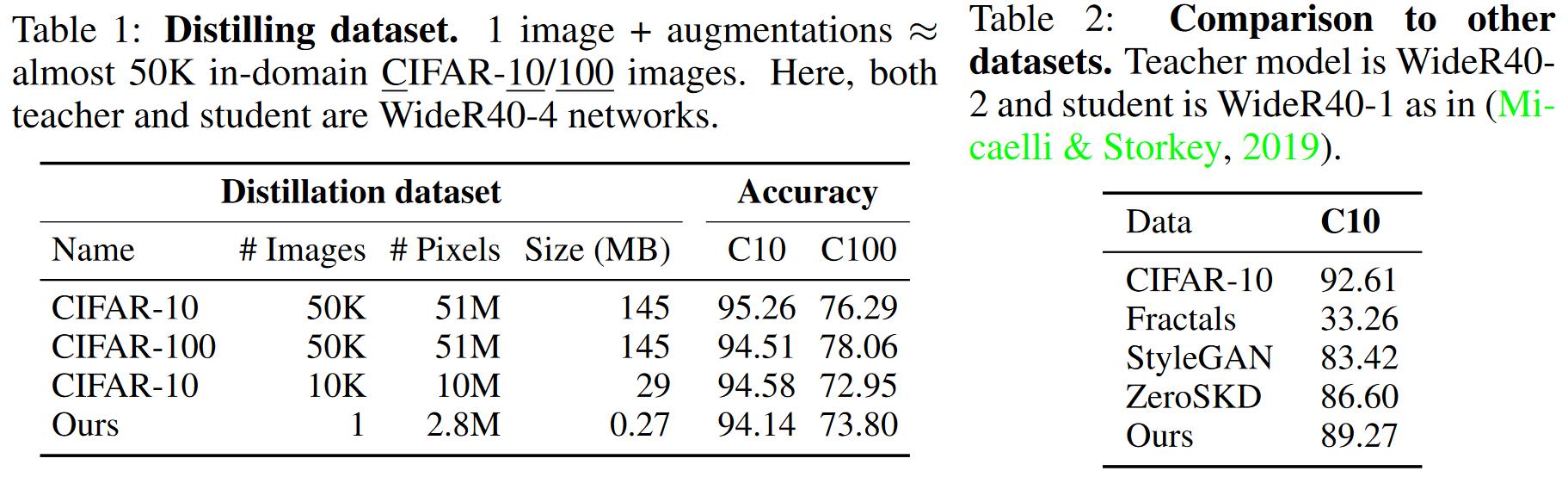
这里检查从单一图像推断到小尺寸数据集的能力。表1给出了在CIFAR10和CIFAR100数据集上的实验结果。使用源数据集在源数据集达到最高的精度,但使用单个图像得到的模型也可以达到下界。另外单一图像蒸馏甚至超过了使用CIFAR-10的10K图像指导CIFAR-100训练即使两个数据集相似。
单一图像的选择 这里发现单一图像选择是重要的。随机噪声或稀疏的图像与密集标签bridge和Animal图像性能差很多。
损失函数的选择 表3(b)发现本文方法的学生模型甚至能从下降质量的学习信号下学习。即使受到的是TOP-5的预测或者最大预测(硬标签),学生模型也能在很大意义上进行推断(>91%/60%)。
增广策略选择 表3(c)给出了不同的增广策略,除了之前指出的策略:更多的增广更好。本文发现在本文的单一图像蒸馏任务上CutMix比MixUp性能更好。
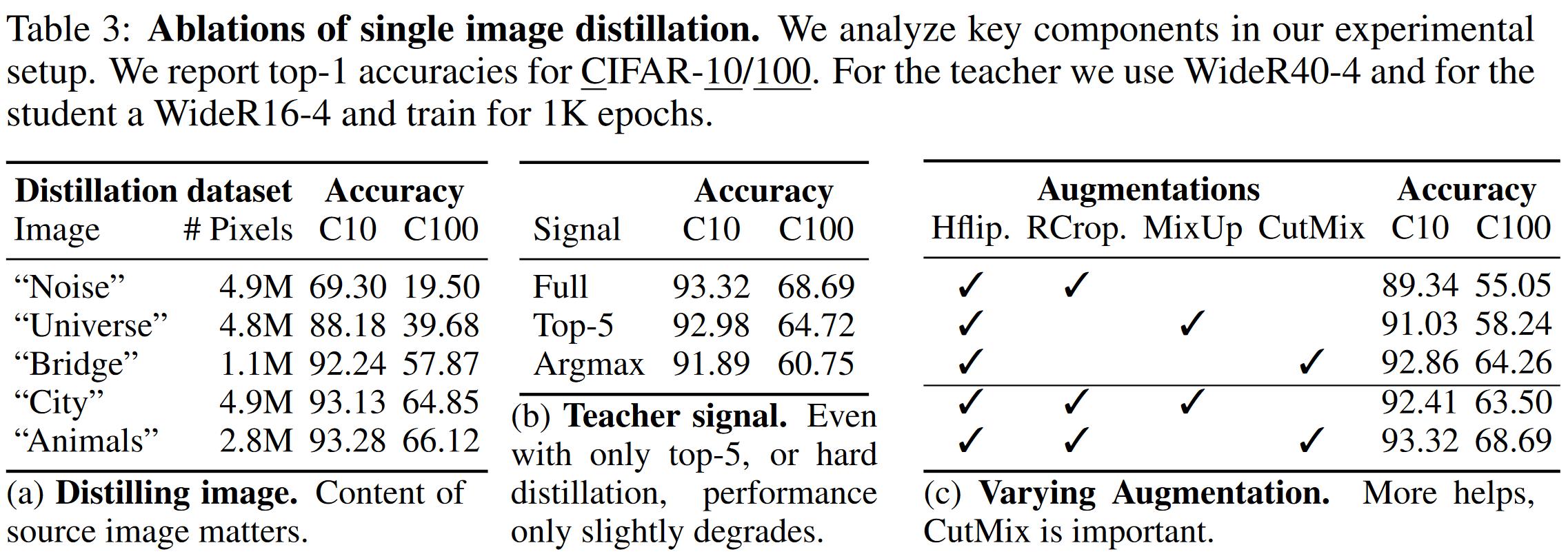
表4给出了在CIFAR-10和CIFAR100数据集上使用常用架构上的蒸馏实验比较。CIFAR10数据集上看到几乎所有的架构上性能都有相似表现,除了ResNet-56到ResNet-20的蒸馏精度下降较多,可能原因是学生模型学习能力较小。
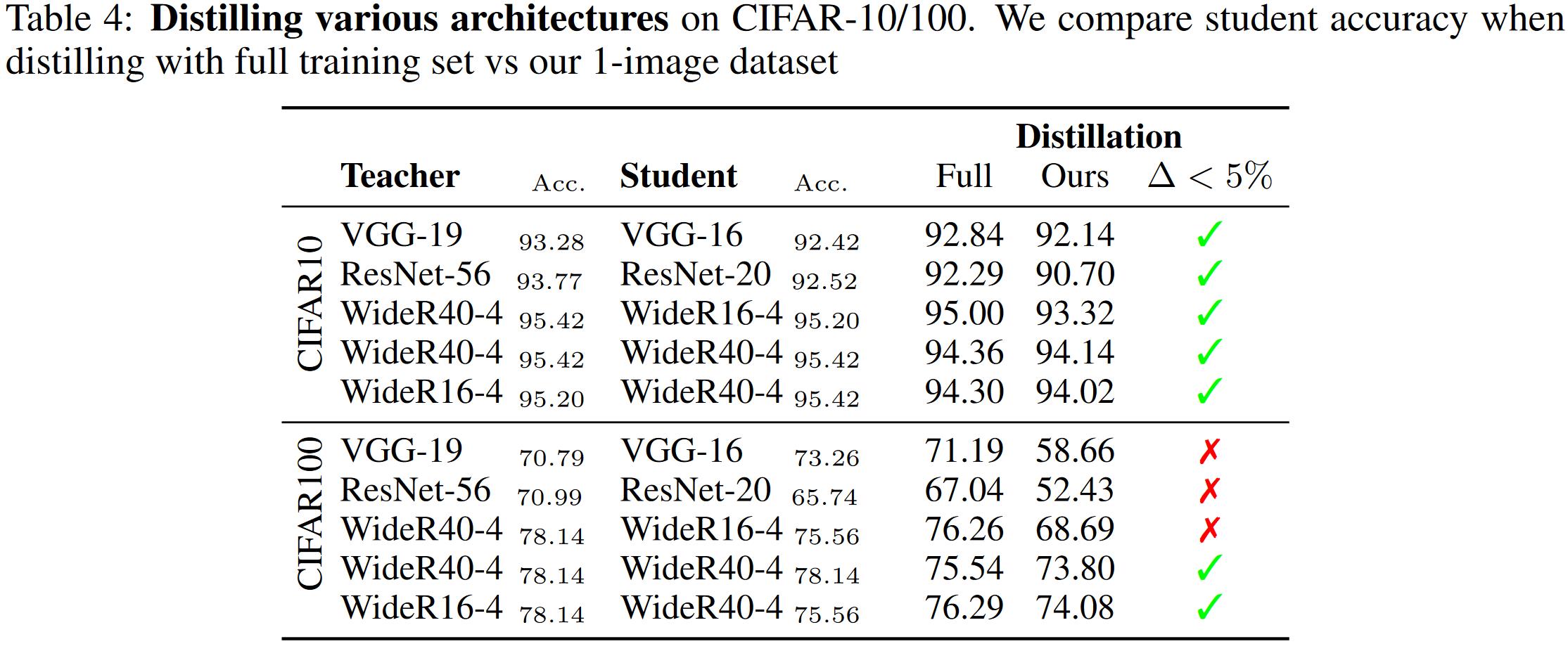
本文也给出了本文方法在其他模态上的性能比较,在50K随机生成的端音频中蒸馏。表5给出了实验结果。比较模型是直接使用源数据集的教师模型。实验结果发现在音频模态中,单一的音频数据也能给学生模型足够的监督信号。
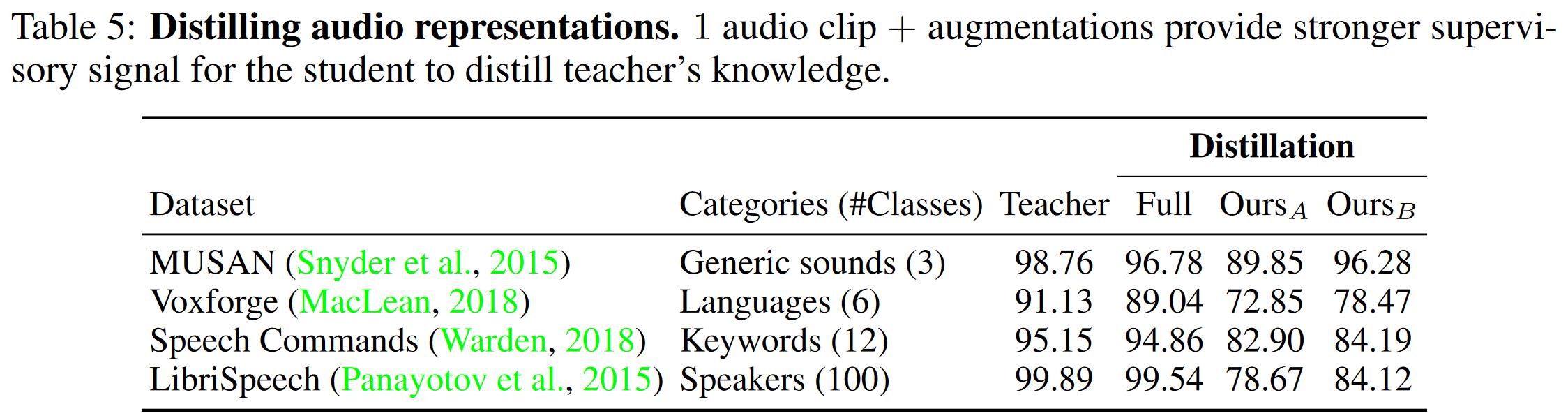
表6给出了视频模态上的实验结果。实验结果也显示单一数据也能给学生模型足够监督信号。
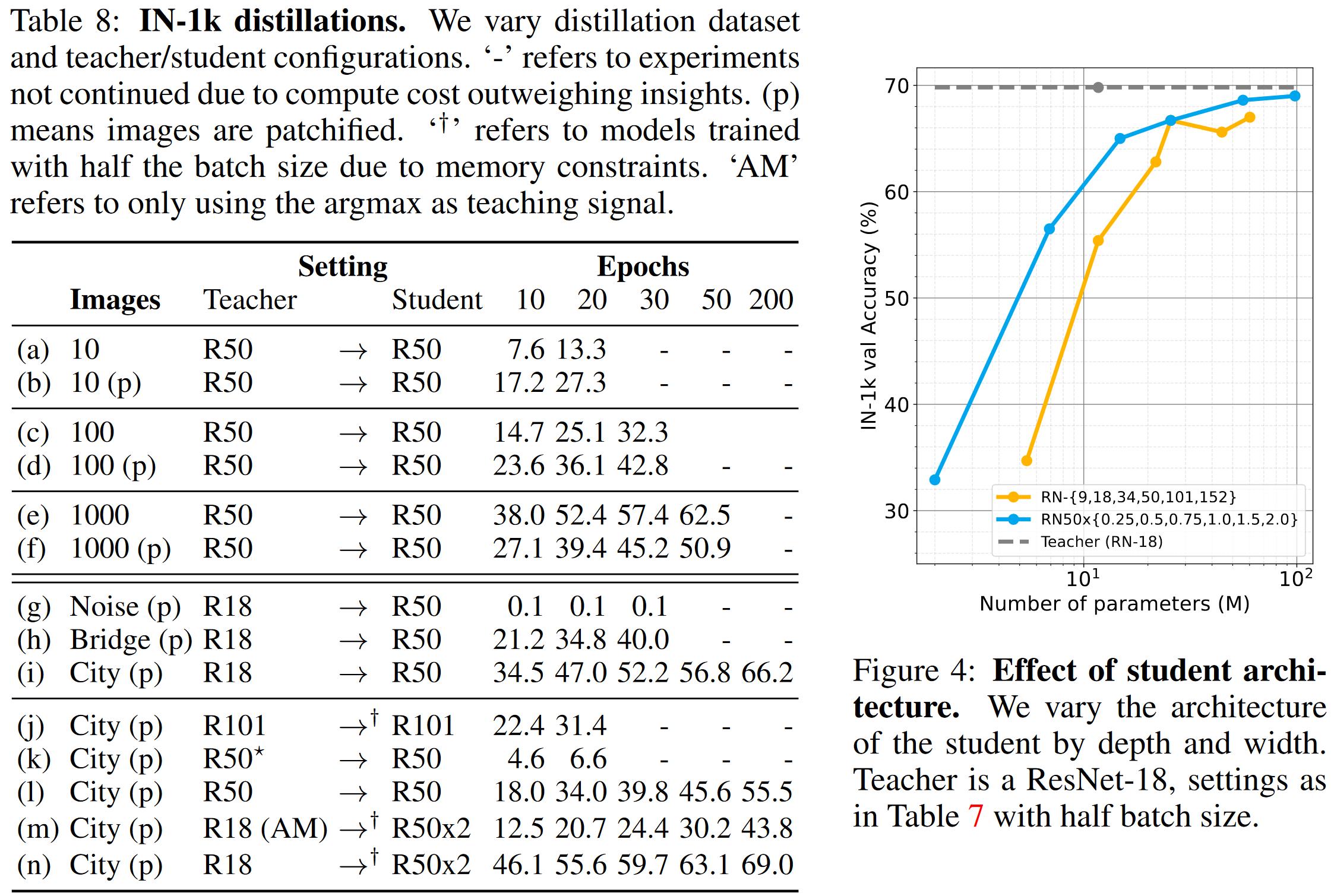
表7给出了在大型图像数据集上的实验结果。一般来说单一图像在大型数据集不足够恢复全部信息。这里发现在ImageNet验证数据集上获得了一个惊人的69%精度。

图4给出了不同学生模型(不同的深度或宽度)下的性能比较。图中所示改变宽度是一个获得更高精度的参数更高效方式。ResNet-50x2模型精度69.0%,几乎到达了教师模型69.5%的精度。
表8给出了更多样的教师-学生组合实验。根据表格结果所示:教师模型性能与最终学生模型性能不是直接相关的,例如行i和l结果所示:ResNet-50不如ResNet-18适合于蒸馏。
文献学习Conformer: Convolution-augmented Transformer for Speech Recognition
目录
1 引言
Transformer 模型擅长捕捉基于内容的全局交互,而 CNN 则有效地利用了局部特征。
2 介绍
Transformer 擅长对远程全局上下文进行建模,但它们提取细粒度局部特征模式的能力较差。本文提出将self-Attention与卷积有机结合的方法,自注意力学习全局交互,而卷积有效地捕获基于相对偏移的局部相关性。
3 Conformer模型
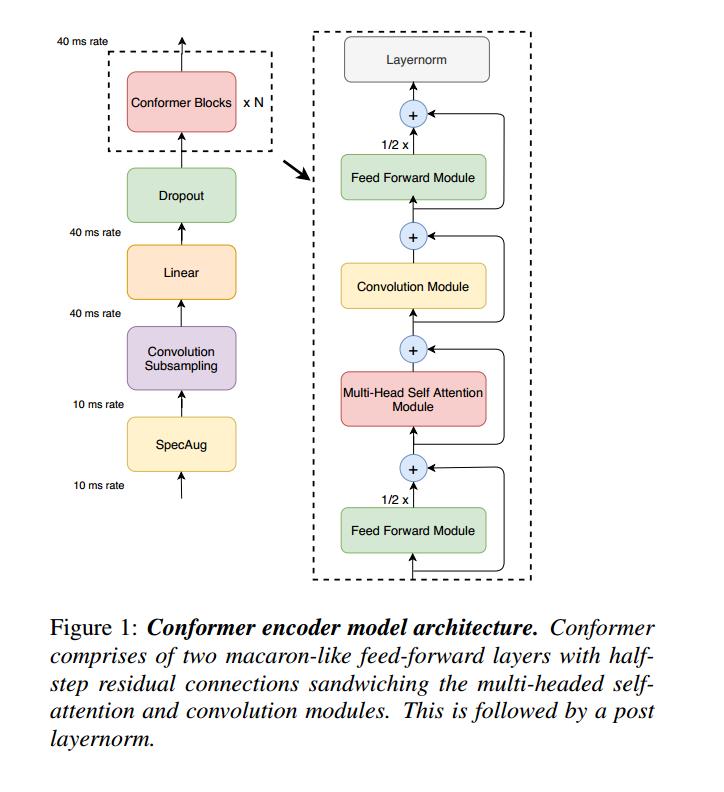
Conformer 模块由四个模块堆叠在一起组成,即前馈模块、自注意力模块、卷积模块和最后的第二前馈模块。实验对比,在 Conformer 架构中使用单个前馈模块相比,拥有两个前馈层将注意力和卷积模块夹在中间效果更好。在 self-attention 模块之后堆叠的卷积模块最适合语音识别。
3.1 Muti-Headed Self-Attention 模块
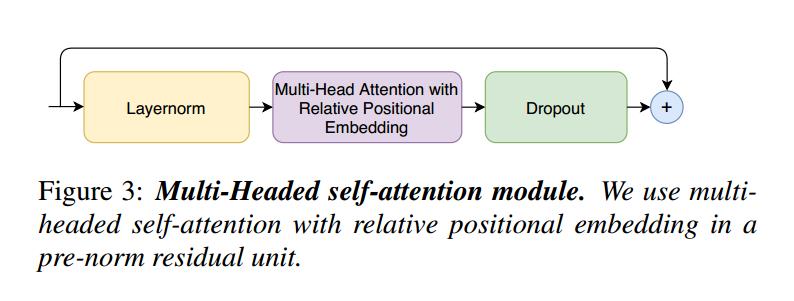
这种self-attention 来源于Transformer-XL ,相对正弦位置编码方案。 相对位置编码允许自注意力模块在不同的输入长度上更好地泛化,并且得到的编码器对话语长度的变化更加鲁棒。 使用带有 dropout 的 prenorm 残差单元 ,这有助于训练和规范更深的模型。在 pre-norm 残差单元中使用具有相对位置嵌入的多头自注意力。
3.2 卷积模块

卷积模块包含一个扩展因子为 2 的pointwise卷积,通过 GLU 激活层投影通道数,然后是一维depthwise 卷积后面是 Batchnorm,然后是 swish 激活层。Batchnorm 在卷积之后立即部署,以帮助训练深度模型
3.3 Feed forward 前馈模块

由两个线性变换和中间的非线性激活组成。 在前馈层上添加一个残差连接,然后是layernorm。
4 实验分析
略:本人只对模型感兴趣,只阅读了模型部分
5 疑问和思考
● 代码是Pytorch写的,不知道Keras能不能使用。https://github.com/lucidrains/conformer?utm_source=catalyzex.com
● 如何把该模型应用到信号处理领域,是我需要研究的问题。
以上是关于文献阅读——The Augmented Image Prior Distilling 1000 Classes by Extrapolating from a Single Image的主要内容,如果未能解决你的问题,请参考以下文章
文献学习Conformer: Convolution-augmented Transformer for Speech Recognition
文献阅读:The YouTube video recommendation system
StoryFlow: Tracking the Evolution of Stories-1.可视化文献阅读
文献阅读与想法笔记13Pre-Trained Image Processing Transformer
文献阅读与想法笔记13Pre-Trained Image Processing Transformer
文献阅读——Understanding the Role of Mixup in Knowledge Distillation: An Empirical Study