文献学习Conformer: Convolution-augmented Transformer for Speech Recognition
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献学习Conformer: Convolution-augmented Transformer for Speech Recognition相关的知识,希望对你有一定的参考价值。
目录
1 引言
Transformer 模型擅长捕捉基于内容的全局交互,而 CNN 则有效地利用了局部特征。
2 介绍
Transformer 擅长对远程全局上下文进行建模,但它们提取细粒度局部特征模式的能力较差。本文提出将self-Attention与卷积有机结合的方法,自注意力学习全局交互,而卷积有效地捕获基于相对偏移的局部相关性。
3 Conformer模型
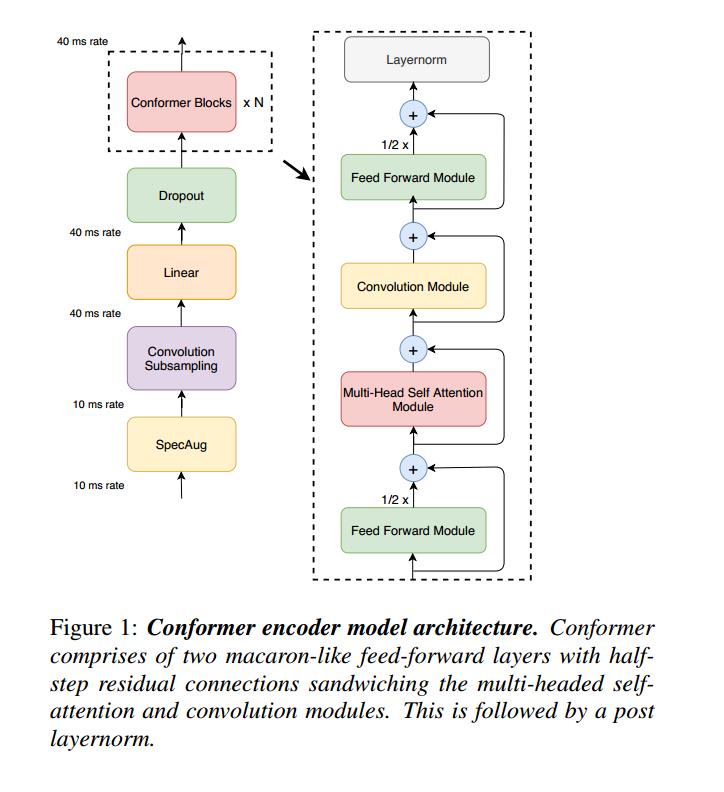
Conformer 模块由四个模块堆叠在一起组成,即前馈模块、自注意力模块、卷积模块和最后的第二前馈模块。实验对比,在 Conformer 架构中使用单个前馈模块相比,拥有两个前馈层将注意力和卷积模块夹在中间效果更好。在 self-attention 模块之后堆叠的卷积模块最适合语音识别。
3.1 Muti-Headed Self-Attention 模块
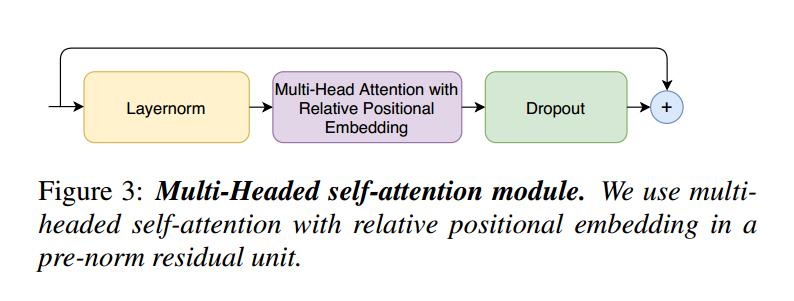
这种self-attention 来源于Transformer-XL ,相对正弦位置编码方案。 相对位置编码允许自注意力模块在不同的输入长度上更好地泛化,并且得到的编码器对话语长度的变化更加鲁棒。 使用带有 dropout 的 prenorm 残差单元 ,这有助于训练和规范更深的模型。在 pre-norm 残差单元中使用具有相对位置嵌入的多头自注意力。
3.2 卷积模块

卷积模块包含一个扩展因子为 2 的pointwise卷积,通过 GLU 激活层投影通道数,然后是一维depthwise 卷积后面是 Batchnorm,然后是 swish 激活层。Batchnorm 在卷积之后立即部署,以帮助训练深度模型
3.3 Feed forward 前馈模块

由两个线性变换和中间的非线性激活组成。 在前馈层上添加一个残差连接,然后是layernorm。
4 实验分析
略:本人只对模型感兴趣,只阅读了模型部分
5 疑问和思考
● 代码是Pytorch写的,不知道Keras能不能使用。https://github.com/lucidrains/conformer?utm_source=catalyzex.com
● 如何把该模型应用到信号处理领域,是我需要研究的问题。
以上是关于文献学习Conformer: Convolution-augmented Transformer for Speech Recognition的主要内容,如果未能解决你的问题,请参考以下文章
国科大提出CNN和Transformer基网模型,Conformer准确率84.1%!