TSDB
Posted mikevictor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TSDB相关的知识,希望对你有一定的参考价值。
版权说明: 本文章版权归本人及博客园共同所有,转载请在文章前标明原文出处( https://www.cnblogs.com/mikevictor07/p/17258452.html ),以下内容为个人理解,仅供参考。
一、前言
在监控领域,通常需要指标存储组件TSDB,目前开源的TSDB组件比较多,各个组件性能、高可用性、维护成本等等各有差异。本文不分析选型问题,重点讲解VictoriaMetrics(后面简称为vm)。
有兴趣的朋友建议结合源码进行分析,由于源码不断变更,此分析基于 v1.80.0,后续版本变化理论上不会很大。
二、架构与能力
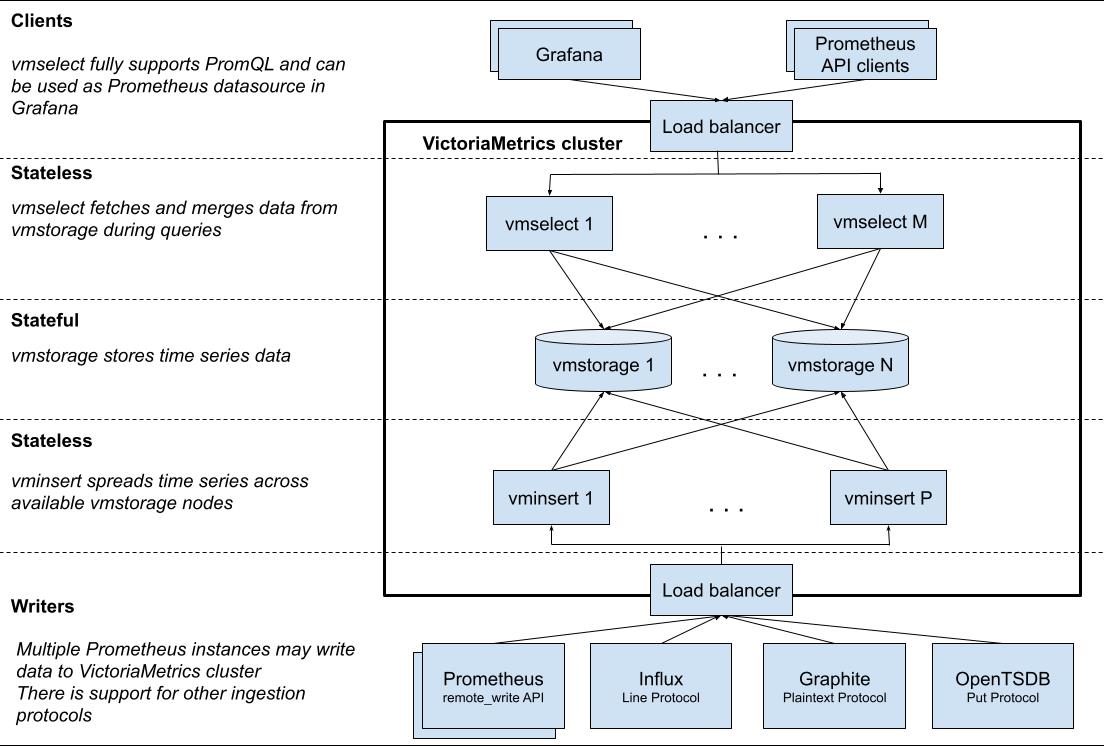
vm开源版本分为single-server(all in one)的单节点模式和cluster模式,单点模式合适本地调试或测试使用,生产使用的cluster模式分为vmselect、vminsert、vmstorage三个主要模块:
(1)vmselect:查询模块,可无状态部署,客户端发送请求到查询模块后,查询模块会把请求分发到所有storage模块(由于没有元数据中心节点,固数据存储在哪无法感知,类似clickhouse的设计模式),得到原始的block数据后在select模块进行合并,再得到一个总结果。
(2)vminsert:写入模块,可无状态部署,写入数据的请求发到此模块后,根据labels通过一定的hash计算出一个值,根据这个值确定此条数据发往哪个storage节点。因此相同的时间线会往同一个点节点发送,如果有某个时间线数据量特别大则会出现数据倾斜问题后某个storage写入和查询压力都会增大。在扩容货缩容后,由于节点的列表变更,固计算出的hash发往的storage节点也会变更。
(3)vmstorage:存储模块,有状态,存储模块的移除须先从select和insert的配置中移除才不会有异常,此模块压力最大,非常消耗内存和IO,固推荐使用SSD和比较大的内存,宁愿用大规格的机器也不用量多但规格较小的机器(缓存不命中则会造成较多的IO,性能下降严重)。
三、vmstorage 存储模块
本文重点讲难度最高的 storage 模块,也只是属于个人理解,如有错误或偏差,望指正。
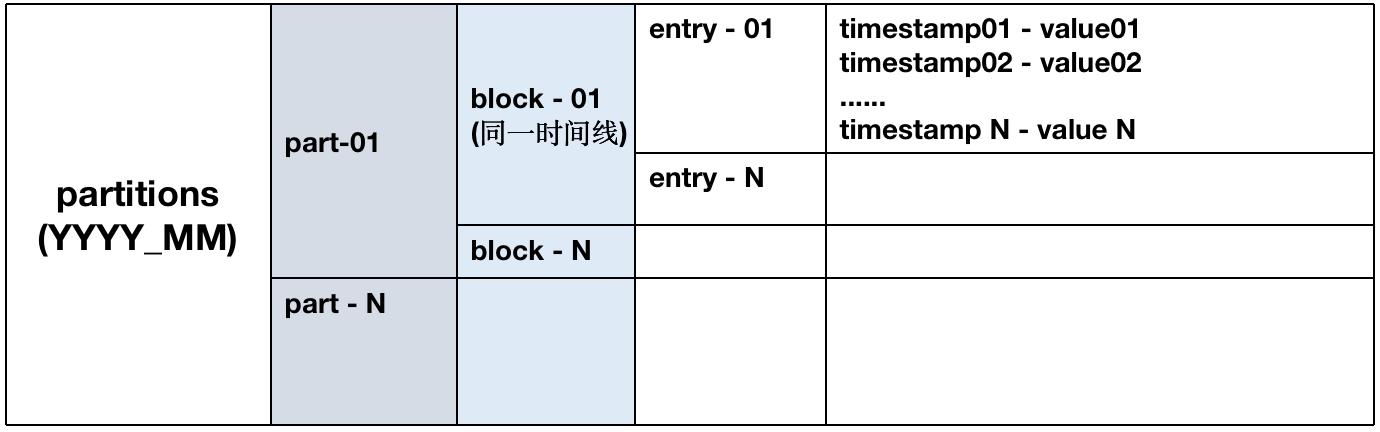
1、存储目录结构

/data 数据目录的逻辑结构如下:
(1)每个block只包括一个时间线,内部根据时间排序。
(2) 每个block最大容纳8000个sample,不同block可并发处理。
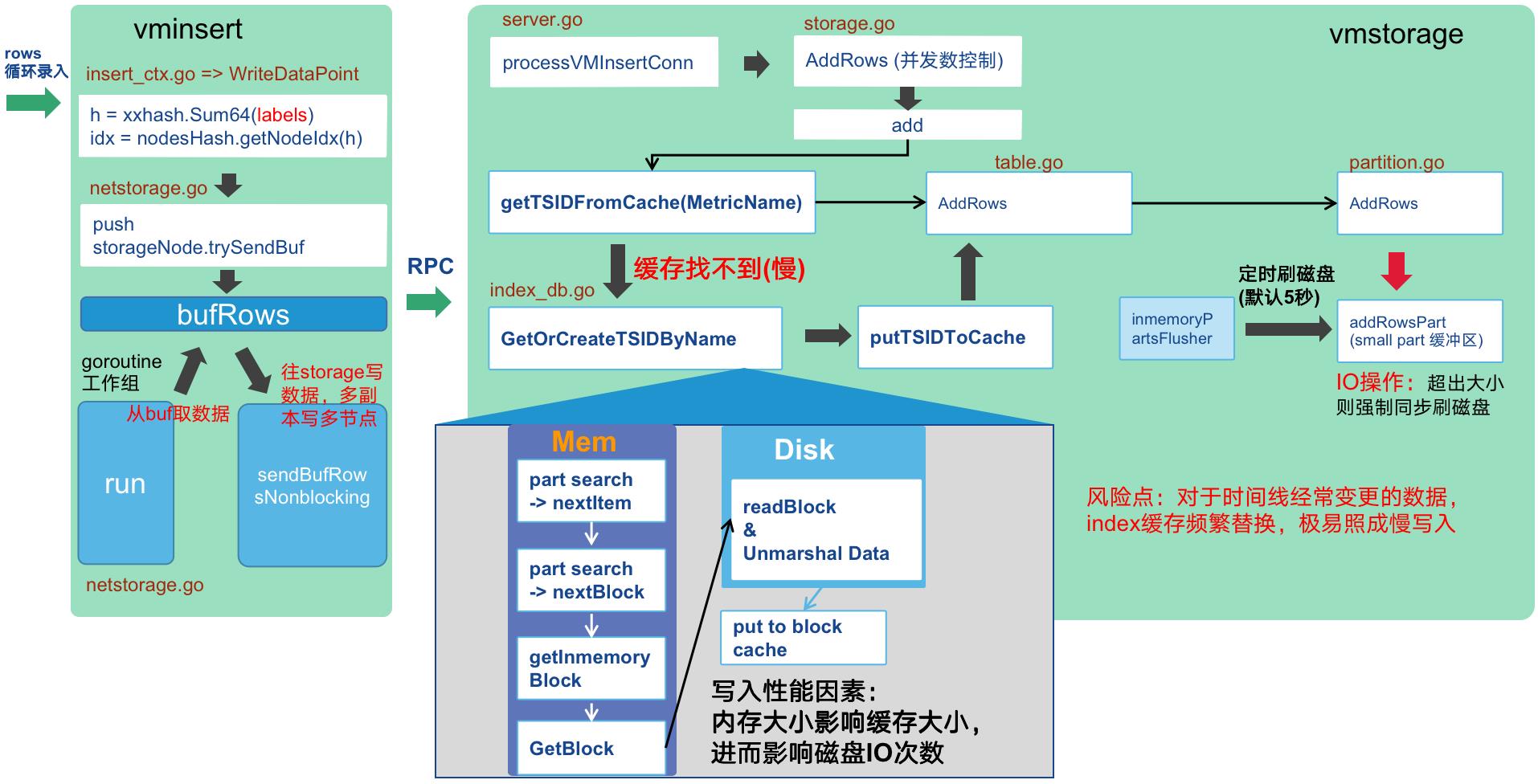
2、 写入流程与风险点
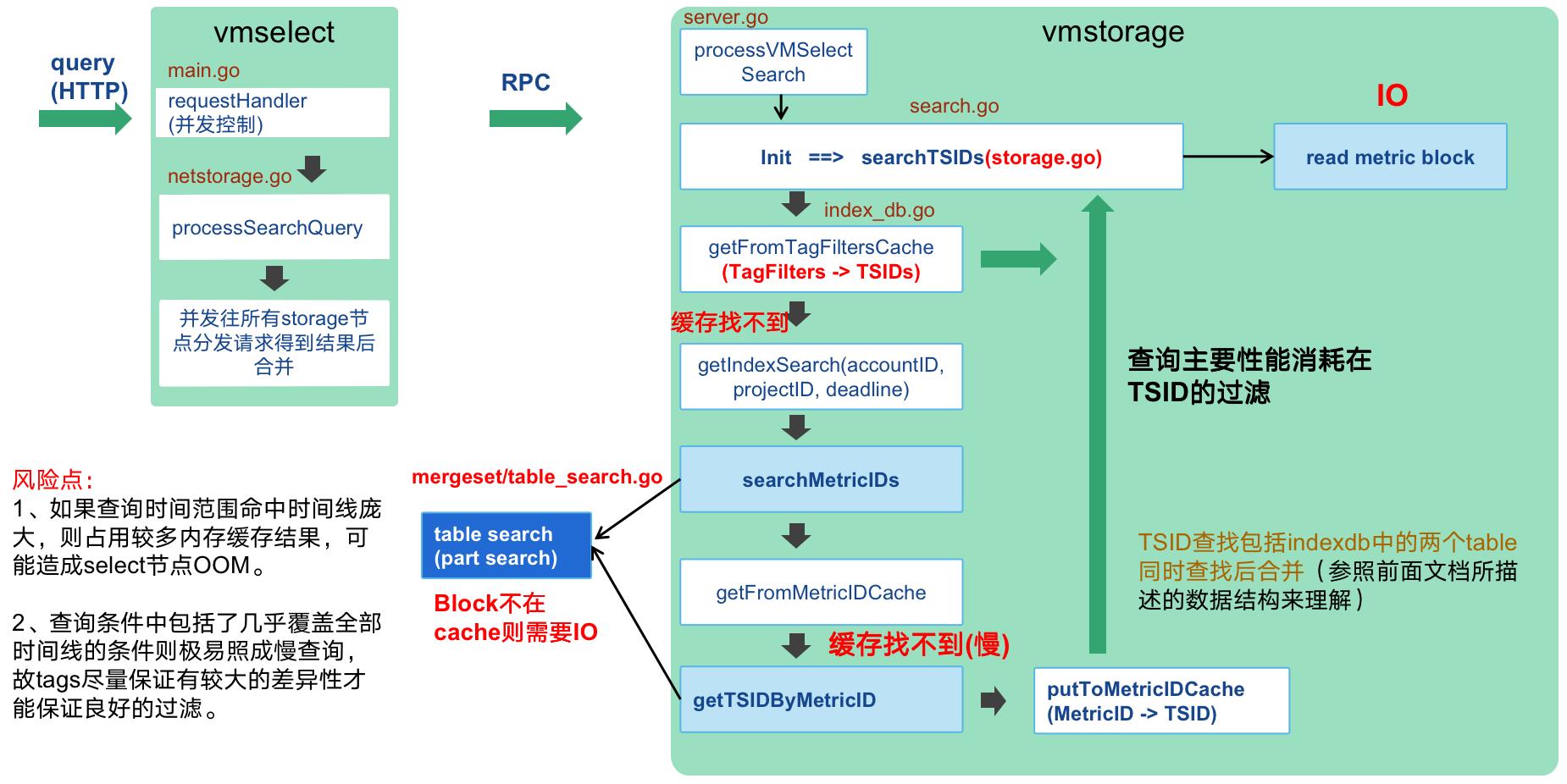
3、查询流程与风险点
4、数据过期机制
开源的cluster版本只能针对租户使用全局的统一过期时间,收费的企业版才能支持租户单独设置过期时间。


5、数据安全性保障
(1)VictoriaMetrics 并未使用WAL,而是直接写入类似SSTable的内存结构中,定时刷写磁盘,这是此模块能表现出极高的写入性能的一个原因,如果是单副本则宕机时有可能照成最近的少量数据丢失,如果是数据安全性要求极高的场景,则建议开启双副本模式。
(2)双副本状态下,写入性能有一定的下降。即使在双副本模式下,不能同时下线两台主机,如果同时下掉两台主机则数据会丢失,为保证数据安全,建议对存储层配置RAID1、RAID5或RAID10保证数据安全性,迁移时将数据从data目录直接迁移走即可在另一主机运行。
四、运维&监控能力、Downsample
(1)vm配置有grafana的监控模板,安装即可观测各个模块的性能,需要结合代码才能比较深入的了解各个指标的作用含义(不过最前面部分的CPU/内存总量的计算貌似不正确,未深究,有兴趣可以看看什么问题)。
(2)vm写入由于没有WAL,如果出现大量缓存失效则容易出现慢写入,甚至大量超时,所以写入建议前置一个MQ(如kafka)缓解写入异常放大,写入模块做一定的异常限流防止查询也出现大量超时。
(3)vm很吃内存和磁盘,磁盘随机IO很多,建议配置SSD。
(4)vm开源版不支持存储层的downsample(企业版才支持),故会查询原始数据后通过promQL配置采样减少输出点,但总的来说不是存储层的downsample查询时间范围过大时会有很大的压力(比如一个月以上),建议上报的数据1分钟一个点位减少数据量。
五、性能见解与总结
官方写了一些英文博文对比influxdb的性能,vm的表现优异,但建议实测(官方提供的总有一些趋向性)。从个人的测试数据上看表现确实很不错,数据不方便公开,建议自测。
总之,此款基于golang的开源TSDB性能表现很好,要能驾驭这组件需要比较多的功力,不能单纯从表层去把它当做一个黑盒来运维,以免后续出现慢写入慢查询会变得手足无措。
源码层面的分析可以搜索下其他文章,在此就不再分析代码段。
Falcon 存储优化: 高性能内存 TSDB 的诞生
目录

Falcon 存储优化: 高性能内存 TSDB 的诞生
TSDB
先说 TSDB(时序数据库)是什么,下面的定义引用自 Wikipedia
A time series database (TSDB) is a software system that is optimized for handling time series data, arrays of numbers indexed by time (a datetime or a datetime range).
Influxdb,Graphite,RRDtool,OpenTSDB等都是当下流行的TSDB实现。
TSDB 多应用于监控系统等场景。 关注我 code 杂坛,了解更多......
背景
我曾提过,滴滴的监控系统,其存储部分的核心是以 open-falcon 为蓝本开发的。
虽然对以RRDtool为核心的graph做了一些优化,但其先天的不足,实难扭转对其高资源需求,低性能产出的差评。 关注我 code 杂坛,了解更多......
graph 之殇
1. graph 的io资源需求,就滴滴的监控体量来讲,graph 实例的 iops 峰值高达50k+,在滴滴 graph 使用的机型是使用了 nvme 磁盘的最高配机型,所以经常在申请预算时被 challenge。究其根本,无非是使用了单 series 单文件的存储模型。
2. cache 的数据结构选型,graph 选用了container/list作为其核心数据结构。在小型项目中,container/list是用于队列场景的常用选型之一。但其临时内存的消耗也非常可观,参见 improving-containerlist 所述。
3. TSDB 的核心,无非就是 key + (t, v)... 这种结构,无论以何种方式组织这几者,例如行式、列式等。都必须有方法来生成key,即对series的唯一标识。在graph中大量使用sha1, md5这种加密hash来参与key的生成,这是极大的浪费,杀鸡用了牛刀。
4. 仍然讨论key。graph 对于 tsdb series 的标识,使用了labels,所谓 labels,即 k1=v1, k2=v2... 这种键值对。而 graph 中对于 key 与 labels 的映射,是通过对 labels 进行字符串连接 + sort() + md5()生成的。这种转换(map <-> string),在整个读、写路径中,在各个模块中都大量存在。而这几种操作要么是高内存耗用,要么是 CPU 杀手。
随着监控数据的不断增长,在 series 到达3亿+的时候,graph 的内存、cpu 等指标值都很不乐观,io 更是居高不下。随之而来的,查询 latency 逐渐升高,看图、大盘等功能体验变差。
面临如上压力,我们进行了一系列分析,根据统计,我们的查询请求,有80%都是查询最近 2 小时数据的请求。这也是graph的最大压力来源。
因此,我们需要的,是一个简单、高性能、易维护的模块,一个针对短期数据的高性能读写方案。
柳暗花明
在做调研的时候,发现了 Writing a Time Series Database from Scratch 这篇文章,这是 prometheus 作者在发布 prometheus 新版存储引擎期间释出的文章。文章本身内容非常好,强烈大家多多研读。 关注我 code 杂坛,了解更多......
而这篇文章最吸引我的,却是下面这句话:
Facebook’s paper on their Gorilla TSDB describes a similar chunk-based approach and introduces a compression format that reduces 16 byte samples to an average of 1.37 bytes.
我们知道,作为时序数据库的基本组成,(t, v) 代表最基本的一个点。在内存中一般占用16 bytes,而如果能压缩到1.37 bytes,这个压缩比是非常高的。
阅读 facebook 的这篇paper,Gorilla: A Fast, Scalable, In-Memory Time Series Database。总结其实现高压缩比的主要抓手如下:
1. 使用 dod(delta of delta)编码,压缩 timestamp。原来需要存储 1551532883, 1551532890, 1551532900, 1551532910,编码后只需要存储 1551532883, 7, 3, 0 即可,压缩效果可见一斑。而在 falcon 的体系中,因为有前置模块(transfer)做了时间戳取余对齐,所以 dod 算法的效果非常好。关注我 code 杂坛,了解更多......
2. 使用 XOR 编码,压缩 value。其依据是一条 series,在相邻时间戳的value在大部分时候变化不大。XOR 编码,如果相邻时间戳的两个 value相同,那么存储 '0',只占用 1 bit,在编码前则要占用 2 个float64的空间。
除了高压缩比,gorilla描述的 In-Memory TSDB架构也非常的值得借鉴,典型的数据分片 + 多blocks轮转 的结构。建议多读几遍 paper 学习一下。
cacheserver 的诞生
压缩算法的实现
paper 也读了,原理也明白了,接下来当时就是实现。不重复造轮子,一直以来是我等的优良传统。祭出 gayhub github 来搜索现成的轮子。找到了 dgryski/go-tsz 这个库,其完整实现了 facebook 的 paper 中描述的(t, v) 编码这一部分。这位 Damian Gryski 实现过很多优秀的算法,值得 follow。但是这个库有一个小问题,由于关键的 struct 的一些字段没有导出,不满足 golang 的 rpc 规范要求。所以进行了一些小改动,放在了 devtoolkits/go-tsz 。
数据模型的实现
为了便于理解,我们自底向上描述 cacheserver 的数据模型。
series 数据流
最底层的数据,就是1个 series 的数据流(bits),是该 series 的(t, v)...经过编码得来的。
chunk/chunks
所谓chunk,就是一个时间窗口内的某个 series 的 bit 流数据,而 chunks 顾名思义,就是多个 chunk 的封装。一般来说,chunk 的时间窗口越长,产出的压缩结果越小,考虑编解码效率等因素,时间窗口的设置可参考如下原则: 关注我 code 杂坛,了解更多......
1. 测试在不同时间窗口之下,平均每个 (t, v) 的占用空间。根据facebook的测试结果,时间窗口设置为 120 分钟,平均每个(t, v)的占用空间为大概 1.37bytes。而更大的时间窗口压缩效果就不太明显了。经过简单测试后,cacheserver的 chunk 时间窗口也设置为 120 分钟。
2. 理论上,chunks 就是包含了 chunk 的 slice,但频繁进行 append 的 slice,对 gc 是不友好的。所以需要有一个机制来保证,不需要的 chunk,可以被清理掉。cacheserver 中的 chunks 使用了 Ringbuffer 结构来存储 chunk,使用固定的空间来存储多个时间窗口的 series 数据流。
这部分的实现,大部分借鉴了 grafana/metrictank,感兴趣的同学可以去看一下。
cache 结构
上面对于 1 条 series 的结构已经描述完毕。下面来说多条 series 的存储,也就是对多个 key + (t, v)... 的存储设计,这种场景,使用 golang 的map数据结构当然最合适不过。
但还有一个问题,cacheserver 的每个实例,设计目标是要能存储 1000w ~ 2000w 条 series。这个量级,使用 map 光存储没有问题,但这个 map 还要有大量的读/写操作,所以一定会用到读写锁。在我们的业务场景中,1次查询几千几万条 series 的场景有很多,再加上源源不断的写操作,这样锁的竞争会非常激烈。如何解决这个问题?
常见的做法是使用分片锁。所谓分片锁,就是将 map 的 key 做分片,然后包括读/写等操作,都先通过分片算法,寻找 key 所在的分片,然后再对得到的分片加锁。
以读为例,从原始的 RLock -> Read -> RUnlock ,经过分片锁的优化之后,变成 getShard -> shard.RLock -> Read -> shard.RUnlock 。后者在高并发的场景下,效率会高很多。
分片的算法,也很重要,如果key是整型,那么直接按照分片数求余即可。但我们的key是字符串,字符串到整数类型的转换方法有很多,我们需要的是一个速度快、占用内存低的方式,核心代码如下:
func fnv32(key string) uint32
hash := uint32(2166136261)
const prime32 = uint32(16777619)
for i := 0; i < len(key); i++
hash *= prime32
hash ^= uint32(key[i])
return hash
以上就是 cacheserver 核心的数据模型,下面从读写路径2个角度来简要地描述一下具体的数据流。
写路径
rpc Call --> cache getshard --> chunks push --> chunk locate --> chunk push
读路径
rpc Call --> cache getshard --> chunks get --> chunk locate --> get Iters
解压 Iters 的时机
在读路径中,获取到的是 Iter,即包含(t, v)...数据的压缩包,那么这个压缩包应该在哪里解开,有2种选择:
1. 由 rpc server,即 cacheserver 解压。
2. 由 rpc client 解压。
在 server 中解压的好处是,client 可以拿到明文的 (t, v)... 数据,直观、方便。
在 client 中解压的好处是,节省 server 的资源。
再三考虑,为节省 cacheserver 的资源开销,我们采用后者,即在 rpc client 中做解压动作。后来 uber 开源的m3db,也涉及到这方面的描述,和我的想法不谋而合,以下引用自 uber blog 的文章 The Billion Data Point Challenge: Building a Query Engine for High Cardinality Time Series Data
One key insight from our evaluation process was that we shouldn’t decompress data on fetch if we are dealing with storage backends that keep data compressed internally, which is exactly how M3DB stores data. If we delay the decompression as long as possible, we might be able to reduce our memory footprint.
rpc encode/decode
gob作为 golang 默认的 rpc 编解码方案,其性能是相对低下的,在使用 pprof 生成的火焰图中,大量宽大的 gob encode/decode 调用也证明了这一点。在 cacheserver 中,使用 msgpack 编解码,看中的就是其 It's like JSON. but fast and small. 的特点。
key 的组成
上文提过,graph 的key是由labels组合计算而成,且带有业务意义。cacheserver不同,key只是标识 series,不带有任何的业务意义,只需上下游模块(transfer 和 query)达成共识即可,cacheserver 不关心。这样除了更具通用型,分离了存储与索引的耦合,也降低了在既有方案中对map <-> string的转换带来的不必要开销。
为什么不落盘
如上文描述,我们整个架构都是基于内存的,并没有涉及到持久化的任何描述。原因有几点:
1. 持久化会加大 cacheserver 的复杂度,持久化就要考虑文件读写、WAL 等,相对会比较麻烦。开发成本和时间成本都比较高。
2. 持久化后,那么 cacheserver 将成为一个完备的TSDB,这不是我们的初衷。我会在下一章节详细描述。
与graph的关系及相关统计数据
cacheserver 的设计初衷,是对 graph 的一个补充。目标是产出一个高性能,低成本,提供热数据查询的服务,降低 graph 的压力。而 graph 作为永久存储方案,实现诸如将采、归档、持久化等逻辑。
在读链路,先读 cacheserver,如果 cacheserver 数据不足或者出现异常,再从 graph 读取。
写链路则沿用 open-falcon 的设计,在 transfer 中进行双写,写入 graph 的同时,也写入 cacheserver。
我们部署了20个实例:
-
存储了
2亿活跃 series,平均每个实例存储1000w series -
共使用内存不到
1 TB,平均每个实例不到50 GB -
查询
latency(tp95)在200ms以下
结尾
关注我 code 杂坛,了解更多......
文章来自,Open-Falcon 开源社区,尊重创作。
以上是关于TSDB的主要内容,如果未能解决你的问题,请参考以下文章
TSDB的数据如何利用Hadoop/spark集群做数据分析?