迁移学习(CDA)《CDA:Contrastive-adversarial Domain Adaptation 》
Posted Blair
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了迁移学习(CDA)《CDA:Contrastive-adversarial Domain Adaptation 》相关的知识,希望对你有一定的参考价值。
论文信息
论文标题:CDA:Contrastive-adversarial Domain Adaptation
论文作者:Nishant Yadav, M. Alam, Ahmed K. Farahat, Dipanjan Ghosh, Chetan Gupta, A. Ganguly
论文来源:2023 ArXiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
基于域对齐的域适应方法实现了域级别的对齐,但是忽略了类级别的对齐;当源域和目标域之间的类条件数据分布存在显著差异时,可能会在类边界附近生成不明确的要素,这些要素更有可能被错误分类。
因此,本文提出了一个两阶段的领域适应模式,称为 Contrastive-adversarial Domain Adaptation (CDA)。虽然对抗性组件有助于领域级对齐,但两阶段对比学习利用类信息来实现跨领域的更高的类内紧密度,从而产生良好分离的决策边界。
2 背景
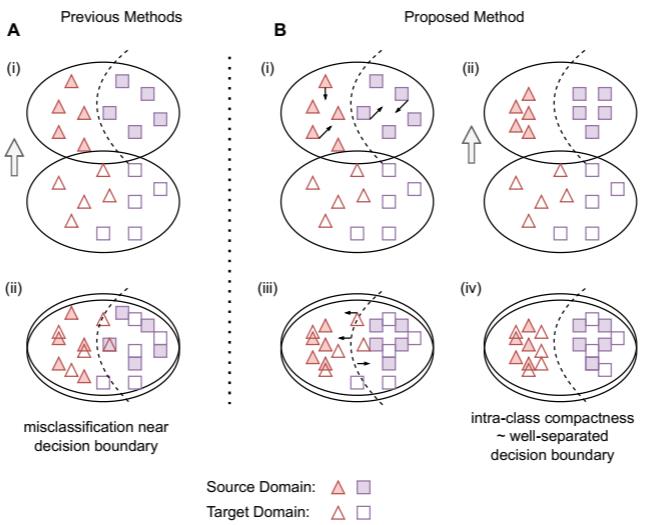
- A:基于域对抗的 UDA 在域级别对齐源和目标域,而忽略了类边界;
- B:本文方法,Step 1:CDA 在标记的源域上执行监督对比学习,从而产生更好的类内紧凑性和用于目标域对齐的良好分离的决策边界。下一步,对抗性学习导致领域级对齐,而跨域对比学习则拉动目标样本与源领域的相似样本对齐,并推开不相似的聚类;
3 方法
整体框架:
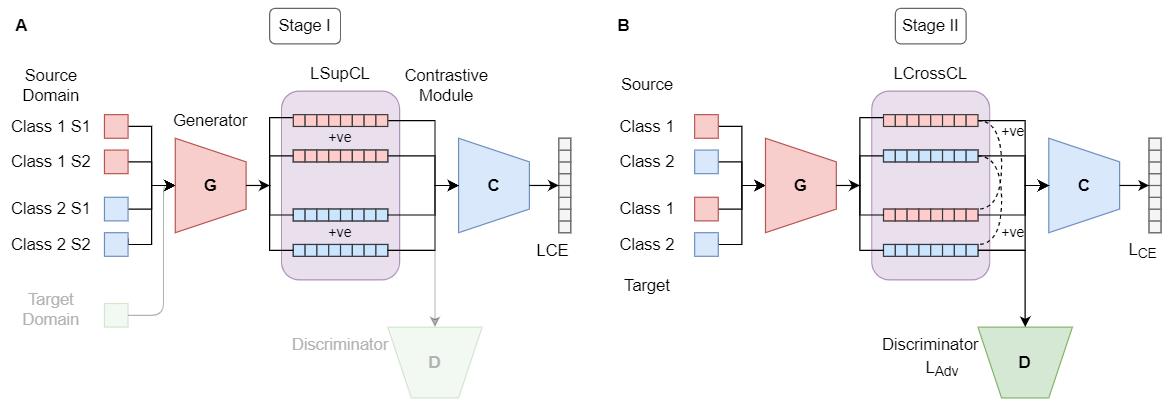
算法:

公式:
$\\mathcalL_\\text Adv \\left(\\mathcalX_s, \\mathcalX_t\\right)=\\sum\\limits _\\substack\\mathbfx_\\mathbfs \\sim \\mathcalX_s \\\\ \\mathbfx_t \\sim \\mathcalX_t\\left(\\log \\left(\\mathcalD\\left(\\mathcalG\\left(\\mathbfx_t\\right)\\right)\\right)+\\log \\left(1-\\mathcalD\\left(\\mathcalG\\left(\\mathbfx_s\\right)\\right)\\right)\\right) \\quad\\quad\\quad(1)$
$\\underset\\mathcalG\\textmin \\; \\underset\\mathcalD\\textmax \\;\\left(\\mathcalL_A d v\\right) \\quad\\quad\\quad(2)$
$\\mathcalL_\\text StageI =\\mathcalL_\\text SupCL +\\mathcalL_C E \\quad\\quad\\quad(3)$
$\\mathcalL_S u p C L\\left(\\mathcalX_s, \\mathcalY_s\\right)=-\\sum\\limits _\\mathbfz, \\mathbfz^+ \\in D_s \\log \\frac\\exp \\left(\\mathbfz^\\top \\mathbfz^+ / \\tau\\right)\\exp \\left(\\mathbfz^\\top \\mathbfz^+ / \\tau\\right)+\\sum\\limits_\\mathbfz^- \\in D_s \\exp \\left(\\mathbfz^\\top \\mathbfz^- / \\tau\\right) \\quad\\quad\\quad(4)$
$\\mathcalL_\\text StageI =\\mathcalL_S \\text upCL +\\mathcalL_C E \\quad\\quad\\quad(5)$
$\\mathcalL_S u p C L\\left(\\mathcalX_s, \\mathcalY_s\\right)=-\\sum\\limits _\\mathbfz, \\mathbfz^+ \\in D_s \\log \\frac\\exp \\left(\\mathbfz^\\top \\mathbfz^+ / \\tau\\right)\\exp \\left(\\mathbfz^\\top \\mathbfz^+ / \\tau\\right)+\\sum_\\mathbfz^- \\in D_s \\exp \\left(\\mathbfz^\\top \\mathbfz^- / \\tau\\right) \\quad\\quad\\quad(6)$
$\\mathcalL_\\text Cross C L\\left(\\mathcalX_s, \\mathcalY_s, \\mathcalX_t\\right)=-\\sum\\limits _\\substacki=1 \\\\ \\mathbfz_s \\in D_s \\\\ \\mathbfz_t \\in D_t^N \\log \\frac\\exp \\left(\\mathbfz_s^i \\top \\mathbfz_t^i / \\tau\\right)\\exp \\left(\\mathbfz_s^i \\top \\mathbfz_t^i / \\tau\\right)+\\sum_i \\neq k=1^N \\exp \\left(\\mathbfz_s^i \\top \\mathbfz_t^k / \\tau\\right) \\quad\\quad\\quad(7)$
$\\mathcalL_\\text Total =\\mathcalL_\\text Stage 1+\\mathcalL_\\text Stage 2 \\quad\\quad\\quad(8)$
$\\mathcalL_\\text Total =\\mathcalL_\\text SupCL +\\mathcalL_C E+\\lambda * \\mathcalL_\\text Adv +\\beta * \\mathcalL_\\text CrossCL \\quad\\quad\\quad(9)$
$\\lambda=\\left\\\\beginarrayll0 & \\text for epoch 0 \\leq e<E^\\prime \\\\\\frac21+\\exp ^-\\gamma p-1 & \\text for epoch e \\geq E^\\prime\\endarray\\right. \\quad\\quad\\quad(10)$
$\\beta=\\left\\\\beginarrayll0 & \\text for epoch e \\leq E^\\prime \\prime \\\\\\min \\left(1, \\alpha *\\left(\\frace-E^\\prime \\primeE^\\prime \\prime\\right)\\right) & \\text for epoch E^\\prime \\prime<e \\leq E\\endarray\\right. \\quad\\quad\\quad(11)$
4 实验
可视化结果:

因上求缘,果上努力~~~~ 作者:加微信X466550探讨,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17277487.html
CDA承接的全球顶级机器学习Scikit-learn 中文社区上线啦!
CDA作为国内知名的全栈数据科学教育和认证品牌,一直致力于让优质的教育人人可得。Scikit-learn作为机器学习的入门工具库,深受初学者的喜爱。但是由于官方文档是英文撰写,限制了很多机器学习爱好者的学习过程。因此,专业、规范、实时的Scikit-learn中文学习社区,一直以来都是国内学习者所急需。
CDA 全国教研团队从2016年已经开始大规模使用Scikit-learn作为Python机器学习课程授课的主要工具库。无论是CDA就业班系列课程,还是周末集训课程,还是2018年推出的系列Scikit-learn课程,均深受国内数据科学爱好者的欢迎。
基于CDA全国教研团队近5年的Scikit-learn课程研发经验,为了响应越来越多的数据科学爱好者的学习需求,CDA通过一年多的Scikit-learn文档的翻译和认真校对,并在CDA研发部门的密切配合下,Scikit-learn中文社区终于上线了。从用户指南到API 、再到案例,翻译字数达一百余万字,相较与网络上流传的其他机器翻译的Scikit-learn中文资料,CDA Scikit-learn中文社区的翻译是最新的官方版本,并且内容更加全面,格式更加规范,翻译更加专业精准,努力为机器学习爱好者提供更便捷的学习途径。
点击文末原文链接,可进入CDA Scikit-learn中文社区!记得分享保存哦!
(注:scikit-learn的官网是www.scikit-learn.org,CDA承接的中文社区网址是www.scikit-learn.org.cn,这同时也标志着CDA与全球顶级深度学习和机器学习框架更进一步融合,CDA认证更加得到全球顶级技术框架的认可!

Scikit-learn(也称为sklearn)是针对Python编程语言的免费机器学习库。2007年,Scikit-learn首次被GoogleSummer of Code项目开发使用,现在已经被广泛大众认为是最受欢迎的机器学习库。
Sklearn具有许多的优点:
支持包括分类,回归,降维和聚类四大类机器学习算法。还包括了特征提取,数据处理和模型评估三大模块,具有着丰富的API接口。
代码样式清晰一致,这使得机器学习代码易于理解和再现,大大降低了机器学习的入门门槛。
得到了大量第三方工具的支持,有非常丰富的功能,适用于各种场景等。
如果你正在学习和使用机器学习,那么Scikit-learn可能是最好的工具库。Scikit-learn拥有着完善的文档,上手容易,具有着丰富的API,在机器学习爱好者中的被广泛使用。其已经封装了大量的机器学习算法,同时Scikit-learn内置了大量数据集,节省了获取和整理数据集的时间。
下面介绍Scikit-learn工具库使用的一些便捷方法
Scikit-learn是一个开源的机器学习库,它支持有监督和无监督的学习。它还提供了用于模型拟合,数据预处理,模型选择和评估以及许多其他实用程序的各种工具。
拟合和预测:估算器基础
Scikit-learn提供了数十种内置的机器学习算法和模型,称为估算器。每个估算器可以使用其拟合方法拟合到一些数据。
这是一个简单的示例,其中我们使用一些非常基本的数据来训练

所述拟合方法通常接受2个输入:
样本矩阵(或设计矩阵)X。X的大小通常为(n_samples, n_features),这意味着样本表示为行,特征表示为列。
目标值y是用于回归任务的真实数字,或者是用于分类的整数(或任何其他离散值)。对于无监督学习,y无需指定。
虽然某些估算器可以使用其他格式(例如稀疏矩阵),但是通常,两者X和y预计都是numpy数组或等效的类似 数组的数据类型。
估算器拟合后,可用于预测新数据的目标值。而无需重新训练估算器,非常便捷:

转换器和预处理器
机器学习工作流程通常由不同的部分组成。典型的管道(Pipeline)包括一个转换或插入数据的预处理步骤,以及一个预测目标值的最终预测器。
在中scikit-learn,预处理器和转换器遵循与estimator对象相同的API(实际上它们都继承自同一 BaseEstimator类)。转换对象没有预测方法,但是需要有一个输出新转换的样本矩阵X的转换方法:

有时,如果你想要应用不同的转换器去处理不同的特征:ColumnTransformer专为这些用例而设计。
管道(Pipeline):连接预处理器和估算器
可以将转换器和估算器(预测器)组合在一起成为一个统一的对象:一个 Pipeline。这条管道提供相同的API作为常规估算器:它可以用fit和predict来训练和预测。正如我们将在后面看到的,使用管道还可以防止数据泄漏,即在训练数据中泄露一些测试数据。
在以下示例中,我们加载Iris数据集,将其分为训练集和测试集,然后根据测试数据计算管道的准确性得分:

模型评估
用一些数据来训练模型并不意味着在一些未知的数据上也能预测得很好,这需要直接评估。
将模型拟合到一些数据并不意味着它将在看不见的数据上很好地预测。这需要直接评估。我们刚刚看到了train_test_split函数可以将数据集分为训练集和测试集,但是scikit-learn提供了许多其他模型评估工具,尤其是用于交叉验证的工具。
我们在这里简要展示了如何使用cross_validate帮助程序执行5折交叉验证过程。需要注意的是,还可以使用不同的数据拆分策略以及使用自定义评分功能来手动实现遍历。有关更多详细信息,请参阅我们的用户指南:
自动参数搜索
所有估算器都有可以调整的参数(在文献中通常称为超参数)。估算器的泛化能力通常关键取决于几个参数。例如,在随机深林回归器RandomForestRegressor中,n_estimators参数 确定林中树木数量,max_depth参数确定每棵树的最大深度。通常,这些参数的确切值是多少我们都不太清楚,因为它们取决于拿到的数据。
Scikit-learn提供了自动查找最佳参数组合的工具(通过交叉验证)。在以下示例中,我们使用 RandomizedSearchCV对象随机搜索随机森林的参数空间。搜索结束后,RandomizedSearchCV的表现就像是已经训练好最佳参数集的RandomForestRegressor。在用户指南中可以阅读更多内容:
点击下方原文链接,可进入CDA Scikit-learn中文社区!
以上是关于迁移学习(CDA)《CDA:Contrastive-adversarial Domain Adaptation 》的主要内容,如果未能解决你的问题,请参考以下文章