深度学习——用简单的线性模型构建识别鸟与飞机模型
Posted zh-jp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习——用简单的线性模型构建识别鸟与飞机模型相关的知识,希望对你有一定的参考价值。
本文仅为深度学习的入门学习,故采用线性模型而非CNN处理图像数据集。
一、准备工作
1. 下载CIFAR-10数据集
这是一个\\(32\\times32\\)像素的RGB图像集合,用于学习使用。
from torchvision import datasets
data_path = "./data/"
cifar10 = datasets.CIFAR10(root=data_path, train=True,
download=False) # 下载训练集
cifar10_val = datasets.CIFAR10(
root=data_path, train=False, download=False) # 下载验证集
数据集共有10个类别,用一个整数对应10个级别中的一个:
class_names = 0: "飞机", 1: "汽车", 2: "鸟", 3: "猫",
4: "鹿", 5: "狗", 6: "青蛙", 7: "马", 8: "船", 9: "卡车"
查看数据集的父类,注意Dataset类,后面会提到!
type(cifar10).__mro__
(torchvision.datasets.cifar.CIFAR10,
torchvision.datasets.vision.VisionDataset,
torch.utils.data.dataset.Dataset,
typing.Generic,
object)
2. Dataset类
Dataset类中实现了2种函数的对象:__len__()和__getitem__(),前者返回数据项的总数,后者返回样本和与之对应的整数索引。
len(cifar10)
50000
img, label = cifar10[111]
img, label, class_names[label]
(<PIL.Image.Image image mode=RGB size=32x32>, 8, \'船\')
import matplotlib.pyplot as plt
plt.imshow(img)
plt.show()

3. Dataset变换
在transform中提供了ToTensor对象,它将Numpy数组和PIL图像变换为张量。并将输出张量的尺寸设置为:\\(C\\times H\\times W\\)(分别代表通道、高度和宽度)
from torchvision import transforms
to_tensor = transforms.ToTensor()
img_t = to_tensor(img)
img_t.shape
torch.Size([3, 32, 32])
图像已经转变为 \\(3\\times 32\\times 32\\)的张量。但是,它的标签并不会改变。
回到第一步,在数据集加载时,可以将ToTensor()作为一个参数
tensor_cifar10 = datasets.CIFAR10(
data_path, train=True, download=False, transform=transforms.ToTensor())
此时,访问数据集的元素将返回一个张量,而不是PIL图像
img_t, _ = tensor_cifar10[111]
type(img_t)
torch.Tensor
img_t.shape, img_t.dtype
(torch.Size([3, 32, 32]), torch.float32)
原始PIL图像,中的值0-255(每个通道8位),而ToTensor变换将数据变换为每个通道32位浮点数,将值缩小为0.0~1.0
img_t.min(), img_t.max()
(tensor(0.0588), tensor(0.8039))
验证下图片是否一致,在这之前需要更改下通道以符合matplotlib的期望,将\\(C\\times H \\times W\\)改为\\(H\\times W \\times C\\)
plt.imshow(img_t.permute(1, 2, 0))
plt.show()

4. 数据归一化
由于CIFAR-10数据集较小,可将数据集返回的所有张量并沿着一个额外的维度进行堆叠
import torch
imgs = torch.stack([img_t for img_t, _ in tensor_cifar10], dim=3)
imgs.shape
torch.Size([3, 32, 32, 50000])
view(3, -1)保留了3个通道,并将剩余的维度合并为一个维度,从而计算适当的尺寸大小。这里\\(3\\times 32\\times32\\)图像被转换了\\(3\\times 1024\\)的向量,然后对每个通道的1024个向量求平均值
imgs.view(3, -1).mean(dim=1)
tensor([0.4914, 0.4822, 0.4465])
同理,计算标准差
imgs.view(3, -1).std(dim=1)
tensor([0.2470, 0.2435, 0.2616])
现在可进行Normalize变换了
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))
Normalize(mean=(0.4914, 0.4822, 0.4465), std=(0.247, 0.2435, 0.2616))
再次更改第3步中的tensor_cifar10:
transformed_cifar10 = datasets.CIFAR10(
data_path, train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2470, 0.2435, 0.2616))
])
)
重新调整下维度,显示图片
img_t, _ = transformed_cifar10[111]
plt.imshow(img_t.permute(1, 2, 0))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
可见颜色与原来不同,这是因为归一化对RGB超出0.0-1.0的数据进行了转化,并调整了通道的总体大小,数据存在,但matplotlib渲染不同。
二、区分鸟与飞机
1. 构建数据集
label_map = 0: 0, 2: 1
class_names = [\'airplane\', \'bird\']
cifar2 = [(img, label_map[label]) for img, label in cifar10 if label in [0, 2]]
cifar2_val = [(img, label_map[label])
for img, label in cifar10_val if label in [0, 2]]
构建一个线性模型
import torch.nn as nn
n_out = 2
model = nn.Sequential(
nn.Linear(
3072, # 输入特征
512, # 隐藏层大小
),
nn.Tanh(),
nn.Linear(
512, # 隐藏层大小
n_out, # 输出类
)
)
3. 用概率表示输出
softmax函数,获取一个向量并生成另一个相同维度的向量,表达式如下所示:
def softmax(x):
return torch.exp(x) / torch.exp(x).sum()
x = torch.tensor([1.0, 2.0, 3.0])
softmax(x)
tensor([0.0900, 0.2447, 0.6652])
它满足概率的约束条件,即各个概率相加为1
softmax(x).sum()
tensor(1.)
当然,nn模块将Softmax作为一个可用模块。在使用时,要求指定用来编码概率的维度。
softmax = nn.Softmax(dim=1)
x = torch.tensor([[1., 2., 3.],
[1., 2., 3.]])
softmax(x)
tensor([[0.0900, 0.2447, 0.6652],
[0.0900, 0.2447, 0.6652]])
在建立模型时,添加softmax函数,这样网络便可产生概率。
model = nn.Sequential(
nn.Linear(3072, 512),
nn.Tanh(),
nn.Linear(512, 2),
nn.Softmax(dim=1)
)
在正式训练模型前,尝试运行下,看看结果
img, _ = cifar2[0]
img_t = to_tensor(img)
plt.imshow(img_t.permute(1, 2, 0))
plt.show()
在使用模型时需要输入正确的维度。在输入中,期望是3072个特征,而nn处理的是沿着第0维成批组织的数据。因此我们需要将\\(3\\times 32\\times 32\\)图像变量一个一维张量。
img_batch = img_t.view(-1).unsqueeze(0)
out = model(img_batch)
out
tensor([[0.4620, 0.5380]], grad_fn=<SoftmaxBackward0>)
再通过torch.max()返回该维度上最大元素以及该值出现的索引。在这里,我们需要沿着概率向量取最大值,因此维度为1:
_, index = torch.max(out, dim=1)
index
tensor([1])
虽然完全没有训练,但是意外的猜中了。
3. 分类的损失
分类损失可以按以下步骤计算:
- 运行正向传播,并从最后的线性层获取输入值。
- 计算它们的Softmax以获取概率。
- 取与目标类别对应的预测概率(参数的可能性)。在有监督学习中,我们当然知道它的类别。
- 计算它的对数的相反数(LogSoftmax函数)再添加到损失中。
现在修改模型,使用nn.LogSoftmax()作为输出模块:
model = nn.Sequential(
nn.Linear(3072, 512),
nn.Tanh(),
nn.Linear(512, 2),
nn.LogSoftmax(dim=1)
)
实例化NLL损失(负对数似然,Negative Log Likelihood)
loss = nn.NLLLoss()
损失将批次的nn.LogSoftmax()的输出作为第1个参数,将索引的张量(例子中的0和1)作为第2个参数
img, label = cifar2[0]
img_t = to_tensor(img)
out = model(img_t.view(-1).unsqueeze(0))
loss(out, torch.tensor([label]))
tensor(0.6234, grad_fn=<NllLossBackward0>)
4. 训练分类器
训练数据时,加入工具类中的DataLoader,该类有助于打乱数据和组织数据。数据加载器的工作是从数据集中采样小批量,期间可以选择不同的采样策略,在这里,是在每个迭代周期洗牌后进行均匀采样。
import torch
import torch.nn as nn
from torch import optim
from torch.utils.data import DataLoader
cifar2_ = []
to_tensor = transforms.ToTensor()
for img, label in cifar2:
cifar2_.append((to_tensor(img), label),)
# pin_memory=True 表示启用GPU加速,num_workers=4 表示使用4个子进程来加速数据加载
train_loader = DataLoader(cifar2_, batch_size=64, pin_memory=True,
shuffle=True, num_workers=4, drop_last=True)
model = nn.Sequential( # 建立模型
nn.Linear(3072, 512),
nn.Tanh(),
nn.Linear(512, 2),
nn.LogSoftmax(dim=1)
)
learning_rate = 1e-2 # 学习率
optimizer = optim.SGD(model.parameters(), lr=learning_rate) # 使用随机梯度下降的优化器
loss_fn = nn.NLLLoss()
n_epochs = 100
for epoch in range(n_epochs):
for i, (imgs, labels) in enumerate(train_loader):
batch_size = imgs.shape[0]
out = model(imgs.view(batch_size, -1))
loss = loss_fn(out, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("Epoch: %d, Loss: %f" % (epoch, float(loss)))
Epoch: 0, Loss: 0.467450
Epoch: 1, Loss: 0.442974
Epoch: 2, Loss: 0.489499
Epoch: 3, Loss: 0.501898
Epoch: 4, Loss: 0.460788
...
Epoch: 95, Loss: 0.246432
Epoch: 96, Loss: 0.342604
Epoch: 97, Loss: 0.408567
Epoch: 98, Loss: 0.384299
Epoch: 99, Loss: 0.244038
保存模型
path = "./models/birdOrPlane.pth"
torch.save(model, path)
现在,我们在独立的数据集上做测试
cifar2_val_ = []
to_tensor = transforms.ToTensor()
for img, label in cifar2_val:
cifar2_val_.append((to_tensor(img), label),)
val_loader = DataLoader(cifar2_val_, batch_size=64, pin_memory=True,
shuffle=False, num_workers=4, drop_last=True)
correct = 0
total = 0
with torch.no_grad(): # 现在只关心结果,不许需要计算梯度
for imgs, labels in val_loader:
batch_size = imgs.shape[0]
outputs = model(imgs.view(batch_size, -1))
_, predicted = torch.max(outputs, dim=1)
total += labels.shape[0]
correct += int((predicted == labels).sum())
print("Accuracy: %f"%(correct / total))
Accuracy: 0.832661
可以看见,训练后的模型准确率还是比较可观的。
三、总结
在本次模型的构建和训练中,我们将二维图片当作一维来处理,这也直接导致了模型的参数巨多!
线性层的计算公式:\\(y=w\\times x+b\\),\\(x\\)的长度为\\(3072\\)(\\(3\\times32\\times32\\)),\\(y\\)的长度为\\(1024\\),可知\\(w\\)的大小为\\(1024\\times3072\\),\\(b\\)的长度为\\(102 4\\),因此参数大小为\\(1024\\times3072+1024=3,146,752\\)
试想,如果是更大的图片,参数的数量恐怕会增加地更离谱!
因此,对于图像,需要学习利用图像数据的二维特征来获取更好的结果!
参考文献
[1]Eli Stevens. Deep Learning with Pytorch[M]. 1. 人民邮电出版社, 2022.02 :144-163.
深度学习笔记:基于Keras库的MNIST手写数字识别
目录
6 训练模型:Fitting/Training the model
1 前言
本文介绍基于Keras库创建一个最简单的神经网络模型进行MNIST手写数字识别的试验。麻雀虽小五脏俱全,模型虽然简单但是这个试验基本上覆盖了一个深度学习任务的完整流程中各主要的基本步骤。这是深度学习的一个“Hello, World”式的试验。以此为基础就可以通过添枝加叶探索深度学习世界啦。
Keras最早是独立开发(Ref(1)作者正式Keras的作者)的,后来被Google收购并集成到Tensorflow中了。
2 数据加载和确认¶
MNIST数据集为Keras内置数据集,当然所谓的内置数据集并不是说数据文件本身内置于Tensorflow/Keras库,而是说其中封装了mnist数据处理相关函数,这样以以下方式导入mnist module,调用load_data()函数就会自动从网上下载MNIST数据。在同一环境中,下载后的数据会存放一个tensorflow/keras认识的数据缓存区,所以你不用担心它每次重新运行会傻傻地重新下载。它会先检查以前是不是下载过,没有的话才会去重新下载。
当然,你如果是离线作业,那你也可以先把数据下载下来,然后用另外的方式加载数据即可。这个以后在涉及到其它非内置数据使用时再来学习。
注意load_data()加载(下载)数据时顺便做完了训练集(train set)和测试集(test set)的分割。
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()通常数据加载后要做的第一件事情就是对数据做基本的确认,包括各种可视化手段。获得对数据的第一手认识。稍微看一下数据长的啥样。首先看看各个数据的维度是什么。
print(train_images.shape, train_labels.shape)
print(test_images.shape, test_labels.shape)
print(train_labels)
print(test_labels)(60000, 28, 28) (60000,) (10000, 28, 28) (10000,) [5 0 4 ... 5 6 8] [7 2 1 ... 4 5 6]
由此可以看出训练集和测试集分别包含60000个和10000个数据样本,每个数据样本是一个28*28的数组,用以表示一个768像素的图片。
然后以图片的方式看看训练数据的的长相。
import matplotlib.pyplot as plt
digit = train_images[4]
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()
train_labels[4]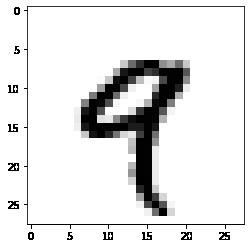
嗯嗯,确实是一个手写数字。打印出来的标签值train_labels[4]表明它是9,与图片吻合。
3 构建模型
深度神经网络的核心组件是层(layer),它是一种数据处理模块,可以理解为数据过滤器,对输入数据进行一些变化,以得到一种新的表示。深度神经网络无非就是将很多的层摞起来,从而实现渐进式的数据蒸馏(data distillation)。
以下构建了一个最简单的神经网络,只有2个Dense层,Dense层也称为密集连接层或者全连接层(是与像卷积层相对的概念,这个暂且不提,以后再说)。第1层使用relu激励函数,这是深度神经网络除了最后一层(输出层)最常用的激励函数(之一?)。当你不知道用什么激励函数时,先用RELU总不会差到哪里去。第2层也即最后一层(输出层)根据不同的深度学习任务可能采用不同的激励函数,对于像MNIST这种多分类任务来说,几乎可以肯定它的首选是softmax.
如上所述,深度神经网络无非就是将很多的层摞起来,所以构建一个深度神经网络模型就跟搭积木差不多。Keras提供了两种搭积木的方式,一种是函数API方式,另一种是使用Sequential类。这里我们采用第二种方式,第一种方式我们会在以后学到。这里不用关心Sequential类是什么东西,用多了用熟了慢慢知道它能干啥、怎么用就可以了(这类实践式技能的学习大抵都是这样的。好比学游泳,你对着游泳学习手册背怎么挥手、怎么打腿、怎么换气,把概念背熟到飞起,并没有什么卵用。得先一头扎到水里去扑腾,然后再回头来学习概念、理论性的东西)。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])4 编译模型
搭建完模型后在使用之前要先调用compile()函数进行编译,编译时要给编译器提供关于模型的参数,主要有以下三个信息:
(1) 优化器(optimizer),或者说优化算法
(2) 损失函数(loss function),模型训练过程基于什么来衡量模型是在往好的方向发展还是往坏的方向发展。损失函数也称代价函数,意思是说模型如果猜“对”了其损失/代价会小一些,猜“错”了其损失/代价会大一些,基于反馈损失函数值模型训练就可以调整模型参数往正确的方向发展。
(3) 性能度量:在训练和测试过程中需要监控的指标/度量(metric)。注意不要把这个跟损失函数混淆在一起,虽然它们都是模型优劣的度量,但是性能度量是最终的度量,而损失函数是中间度量。把最终度量用作训练的指引的话会显得过于粗糙反馈信息的精度不够,而损失函数则可以提供更精确的中间信息助力训练过程。本例为10分类问题,只要关心正确分类的比例即可,所以用"accuracy"即可。注意metrics参数的传递方法是指定一个列表,这意味着可以指定的性能度量项可以不限于一项。注意,经常可以看到有人把"accuracy"译成‘精度’,这是属于概念性错误,精度对应"precision"与accuracy好像挺像其实完全不是一回事。
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
5 数据预处理¶
上面所搭建的模型对于输入数据格式有一定的要求,比如说要求数据格式为float32类型,而原始MNIST数据集中数据是以整型int8格式存储的。所以首先需要进行格式转换。
其次,通常我们会对数据进行normalization,特别是对于存储不同类型不同scale的features时。对于像本例这样的数据范围为[0,255]的图像数据通常的做法是将其变换到[0,1]之间。
以下这段代码将数据类型转换为'float32'以及将将数据范围变换到[0,1]区间。
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype("float32") / 2556 训练模型:Fitting/Training the model
接下来就可以把数据喂给以上搭建好的模型进行训练啦!
Keras模型用fit()函数表示训练其调用格式也基本上继承了scikit-learn风格。第1个参数表示训练数据,第2个参数表示标签数据(本例为监督学习),第3个参数epochs表示训练多少轮(对完整的数据集扫描一遍进行训练叫做一个epoch),第4个参数batch_size表示整个训练集分为多大的数据块进行分别处理。将整个数据集作为一个数据块训练叫batch mode(批量模式),分为多个数据块(通常是相同大小的)逐个处理的话叫做minibatch mode(小批量模式),逐个数据进行训练处理的话叫做stochastic mode。stochastic mode其实就是batch_size=1时的minibatch mode的特例。反之,如果batch_size等于训练集大小的话就是batch mode了。把batch_size传递给模型,它自动计算需要分为多少个mini-batch。如果除不尽的话,是向下取整,最后不足部分舍弃。
以下代码中指定了训练5轮,小批量训练数据块大小为128个数据样本。
model.fit(train_images, train_labels, epochs=5, batch_size=128)正常的话你将看到如下训练过程:

如上所示,在5轮训练过后,在训练集上的准确度可以达到98.9%,非常不错!而且也可以看到随着训练轮数的增加,loss在持续减小,而accuracy则持续增大。但是第5轮相比第4轮的边际增加很小,这很可能说明第5轮训练这多余的,即有可能踩到了overfit红线,这个以后再谈。
7 使用训练好的做预测/推断
从测试集中取1个数据样本看看以上训练好的模型能不能把它们正确地识别出来。
test_digits = test_images[0:10]
predictions = model.predict(test_digits)
print(predictions[2])
print(predictions[2].argmax())
test_labels[2][4.6298595e-08 9.9950302e-01 1.9649169e-04 8.8730678e-07 2.0431406e-05 9.9562667e-06 3.1885143e-06 1.3386145e-04 1.3205952e-04 1.3534594e-07] 1
注意,本模型是个十分类模型,针对每个测试数据样本,模型输出的是一个10维向量(不要与10维张量混淆!)。该向量的每个元素代表一个分类的概率,其中概率最大的项所对应的分类即为推断结果。如上所示,predictions[2]表示针对第3个测试数据的模型输出,它的第2项为0.9995,表示模型非常肯定这个数字是1。由测试集对应的标签也可以知道这个数字确实是1.
8 在测试集上评估模型
要评估模型的性能像上面这样一个一个地看肯定不行。Keras提供了evaluate()函数用于进行模型性能评估,将测试数据集测试标签集一起传递给evaluate()函数即可。
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"test_acc: test_acc")313/313 [==============================] - 1s 2ms/step - loss: 0.0698 - accuracy: 0.9802 test_acc: 0.9801999926567078
如上所示,在测试集上的分类准确度为98.1%比训练集上的98.9%略微差一丢丢。
9 Summary
以上我们用tensorflow.keras库搭建一个简单的仅基于Dense later的两层神经网络模型,用于MNIST数据集(手写体数字)的识别,达到了98%的分辨准确度!
总结一下整个过程分为以下几个步骤:
(1) 数据加载和可视化确认
(2) 搭建模型
(3) 编译模型
(4) 数据预处理
(5) 模型训练
(6) 使用训练好的模型进行预测/推断
(7) 在测试集上进行模型性能评估
期待后续更加精彩的旅程!
Ref:
(1) Francois Chollet: Deep Learning with Python-->此书中文版已出版
以上是关于深度学习——用简单的线性模型构建识别鸟与飞机模型的主要内容,如果未能解决你的问题,请参考以下文章
基于CNN卷积神经网络的TensorFlow+Keras深度学习的人脸识别