python爬虫--模拟登录知乎
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫--模拟登录知乎相关的知识,希望对你有一定的参考价值。
1、处理登录表单
处理登录表单可以分为2步:
第一、查看网站登录的表单,构建POST请求的参数字典;
第二、提交POST请求。
打开知乎登录界面,https://www.zhihu.com/#signin,
按f12,打开开发者界面:
在这里面找到headers信息,
现在在用户名和密码处查找信息,


发现用户名的属性为account,account中的内容为我们的用户名;
同理,password中的内容为我们的密码。
在登录表单中,有些key值在浏览器中设置了hidden值,不会显示出来,这个时候我们需要去审查元素中去查找,
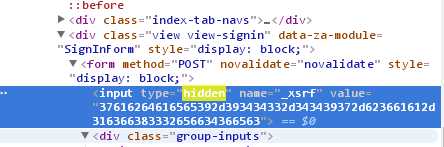
发现了,cookie中有一个_xsrf的属性,类似于token的作用。而这个东西的存在,就让我们在模拟登录的时候,必须将这个属性作为参数一起加在请求中发送出去。
而获取_xsrf则可以用之前的BeautifulSoup获取
import requests from bs4 import BeautifulSoup as bs session = requests.session() post_url = ‘https://www.zhihu.com/#signin‘ agent = ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.1.2.3000 Chrome/55.0.2883.75 Safari/537.36‘ headers = { "Host": "www.zhihu.com", "Referer":"http://www.zhihu.com/", ‘User-Agent‘:agent } postdata = { ‘password‘: ‘*****‘, ‘account‘: ‘******‘, } response = bs(requests.get(‘http://www.zhihu.com/#signin‘,headers=headers).content, ‘html.parser‘) xsrf = response.find(‘input‘,attrs={‘name‘:‘_xsrf‘})[‘value‘] postdata[‘_xsrf‘] =xsrf responed = session.post(‘http://www.zhihu.com/login/email‘,headers=headers,data=postdata) print(responed)
结果显示:
<Response [200]>;
代码做一些修改:
import requests
from bs4 import BeautifulSoup
session = requests.session()
agent = ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.1.2.3000 Chrome/55.0.2883.75 Safari/537.36‘
headers = {
"Host": "www.zhihu.com",
"Origin":"https://www.zhihu.com/",
"Referer":"http://www.zhihu.com/",
‘User-Agent‘:agent
}
postdata = {
‘password‘: ‘*****‘,
‘account‘: ‘******‘,
}
response = session.get("https://www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find(‘input‘, attrs={"name": "_xsrf"}).get("value")
postdata[‘_xsrf‘] =xsrf
login_page = session.post(‘http://www.zhihu.com/login/email‘, data=postdata, headers=headers)
print(login_page.status_code)
运行结果:200
代表响应的状态为请求成功,可以成功登录表单。
以上是关于python爬虫--模拟登录知乎的主要内容,如果未能解决你的问题,请参考以下文章