python爬虫--解析网页几种方法之BeautifulSoup
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫--解析网页几种方法之BeautifulSoup相关的知识,希望对你有一定的参考价值。
一.解析器概述
soup=BeautifulSoup(response.body)
对网页进行析取时,并未规定解析器,此时使用的是python内部默认的解析器“html.parser”。
解析器是什么呢? BeautifulSoup做的工作就是对html标签进行解释和分类,不同的解析器对相同html标签会做出不同解释。
举个官方文档上的例子:
BeautifulSoup("<a></p>", "lxml")
# <html><body><a></a></body></html>
BeautifulSoup("<a></p>", "html5lib")
# <html><head></head><body><a><p></p></a></body></html>
BeautifulSoup("<a></p>", "html.parser")
# <a></a>
官方文档上多次提到推荐使用"lxml"和"html5lib"解析器,因为默认的"html.parser"自动补全标签的功能很差,经常会出问题。
二、使用BeautifulSoup抓取新闻网站新闻标题。
import requests from bs4 import BeautifulSoup link = "http://tuijian.hao123.com/finance" headers = {‘User-Agent‘ : ‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6‘} r = requests.get(link, headers= headers) soup = BeautifulSoup(r.text,"html.parser") first_title = soup.find("div", class_="box-text").text print ("第一篇文章的标题是:", first_title) title_list = soup.find_all("div", class_="box-text") for i in range(len(title_list)): title = title_list[i].text.strip() print (‘第 %s 篇文章的标题是:%s‘ %(i+1, title))
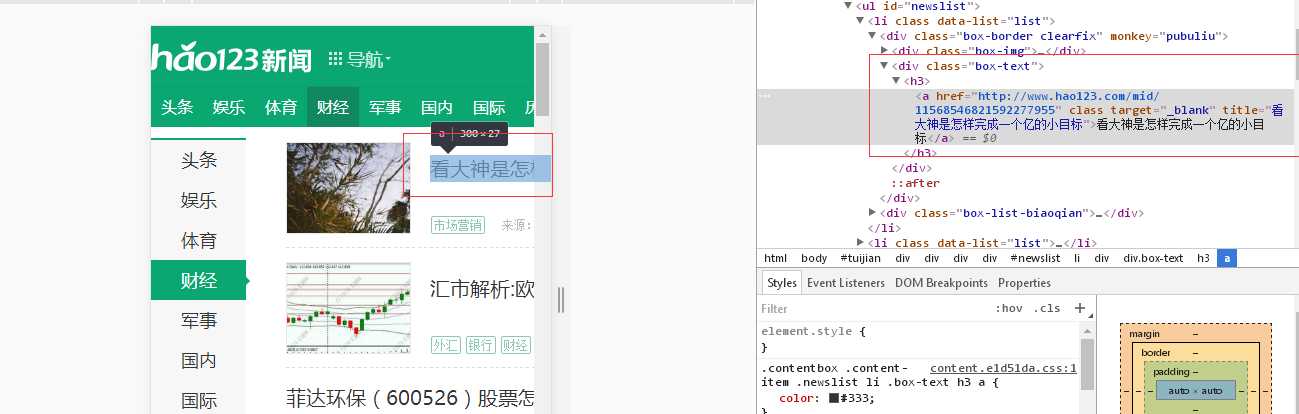
find_all找到所有结果,结果是一个列表。用一个循环,把标题列出。
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) |
|
|
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) |
|
|
| lxml XML 解析器 | BeautifulSoup(markup, [“lxml”, “xml”])BeautifulSoup(markup, “xml”) |
|
|
| html5lib | BeautifulSoup(markup, “html5lib”) |
|
|
以上是关于python爬虫--解析网页几种方法之BeautifulSoup的主要内容,如果未能解决你的问题,请参考以下文章