Python--开发简单爬虫
Posted 艾里_Smiple
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python--开发简单爬虫相关的知识,希望对你有一定的参考价值。
简单爬虫架构
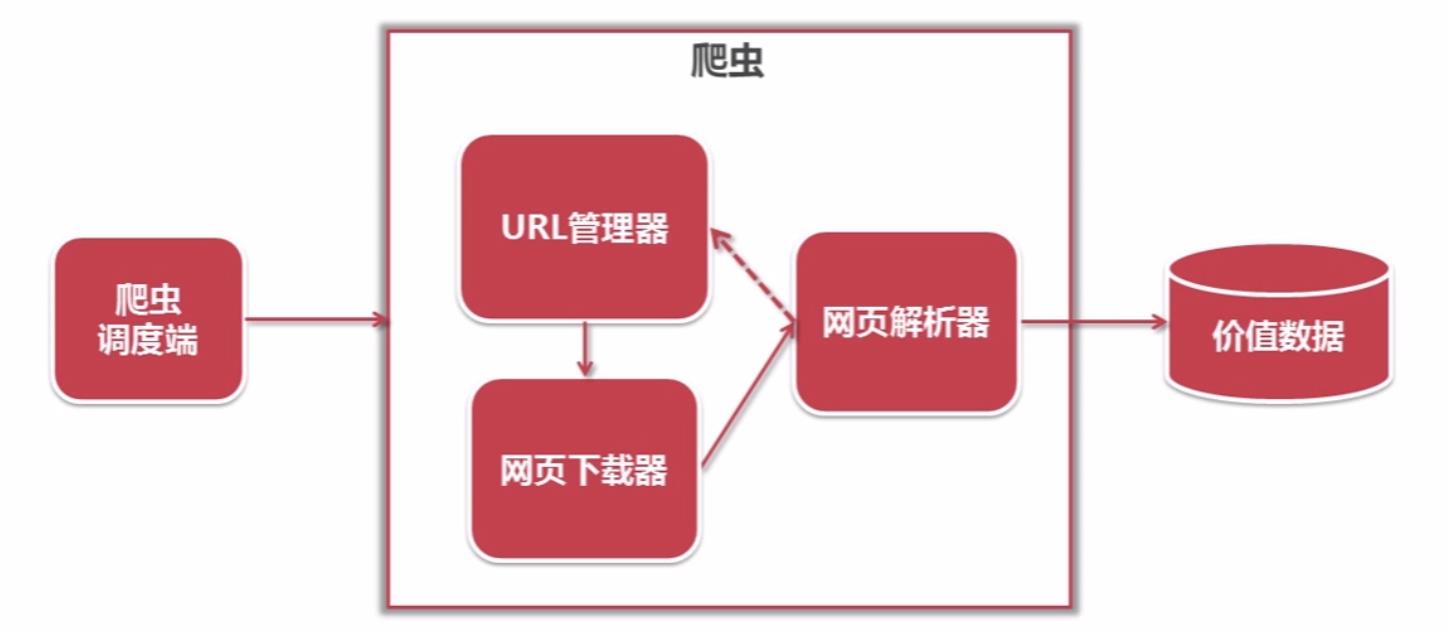
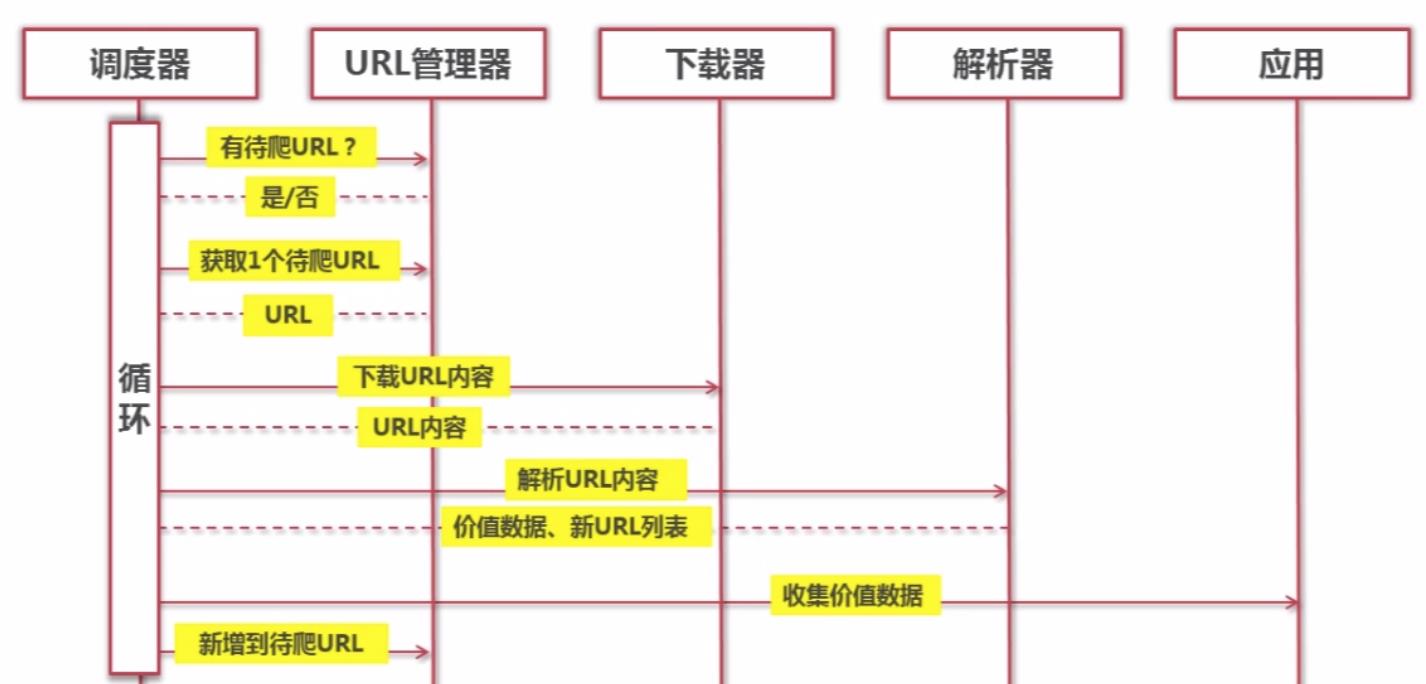
动态运行流程
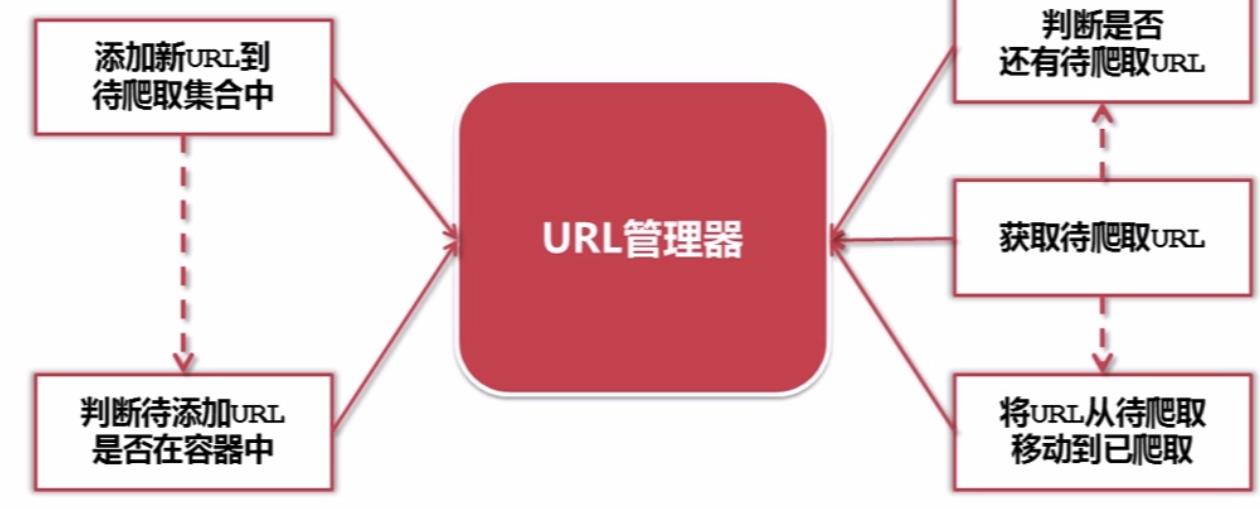
URL管理器的作用
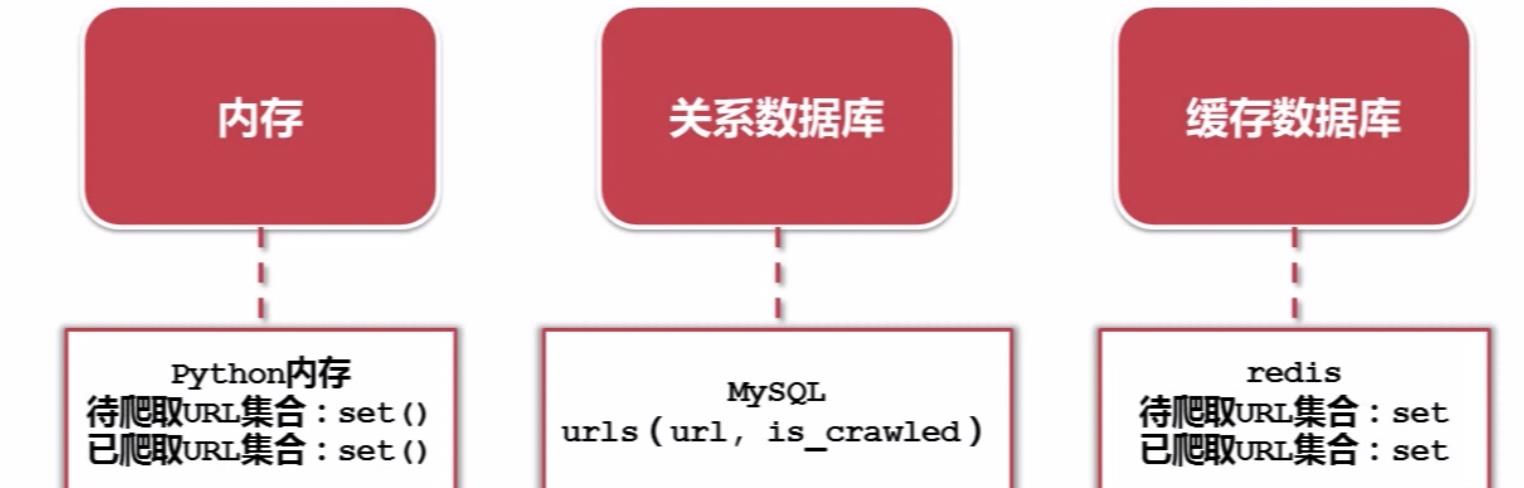
URL管理器的3种实现方式
网页下载器的作用
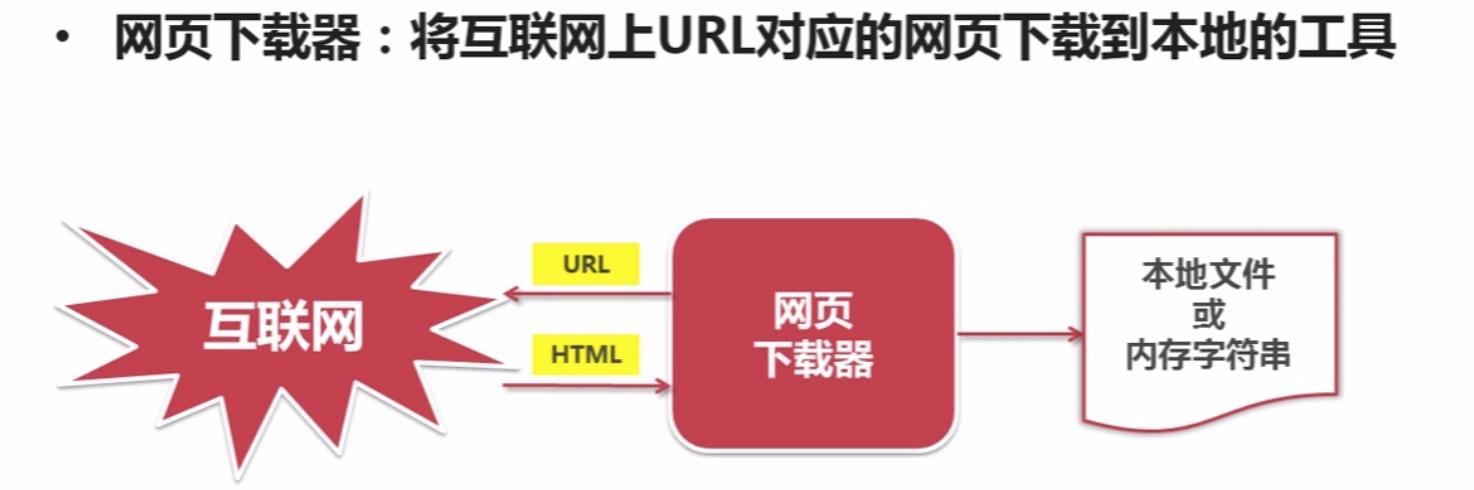
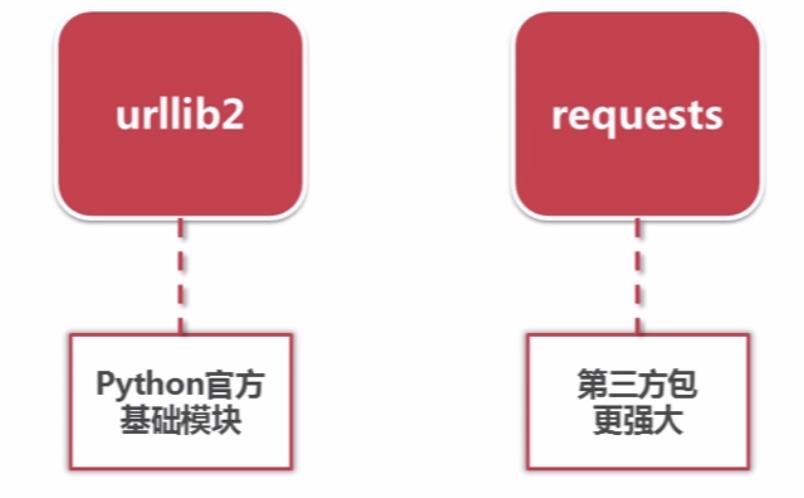
Python网页下载器的种类
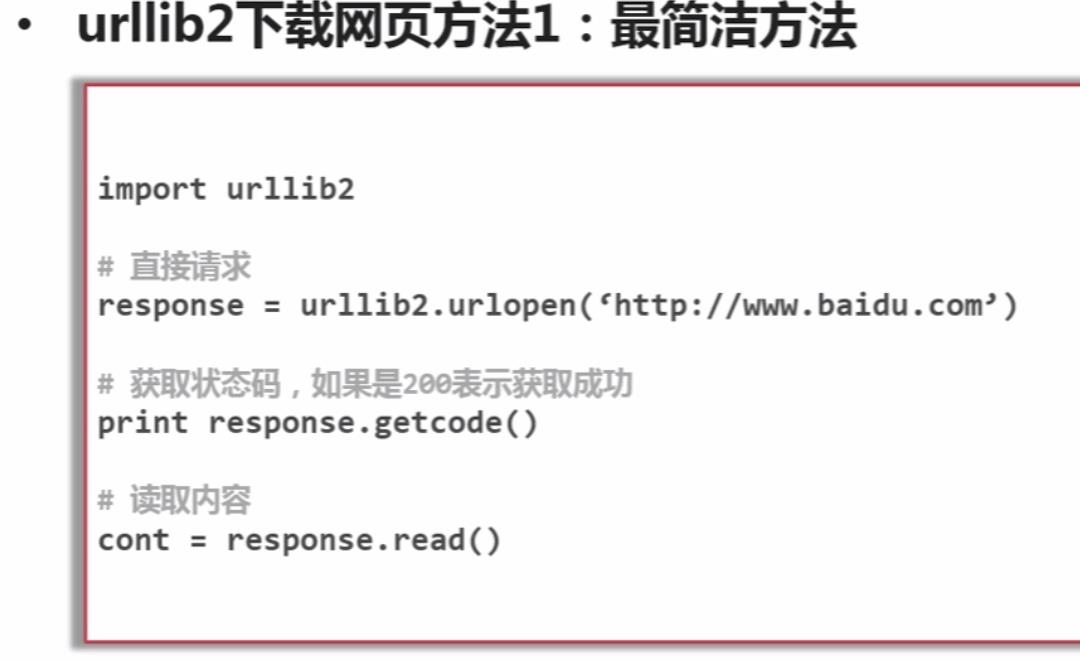
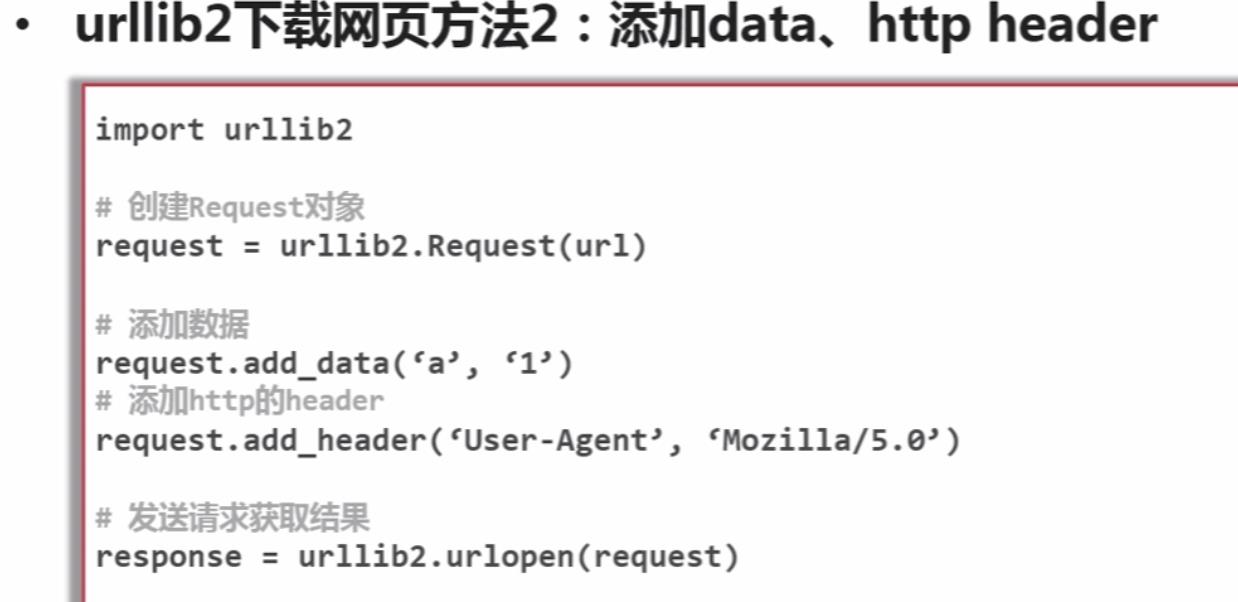
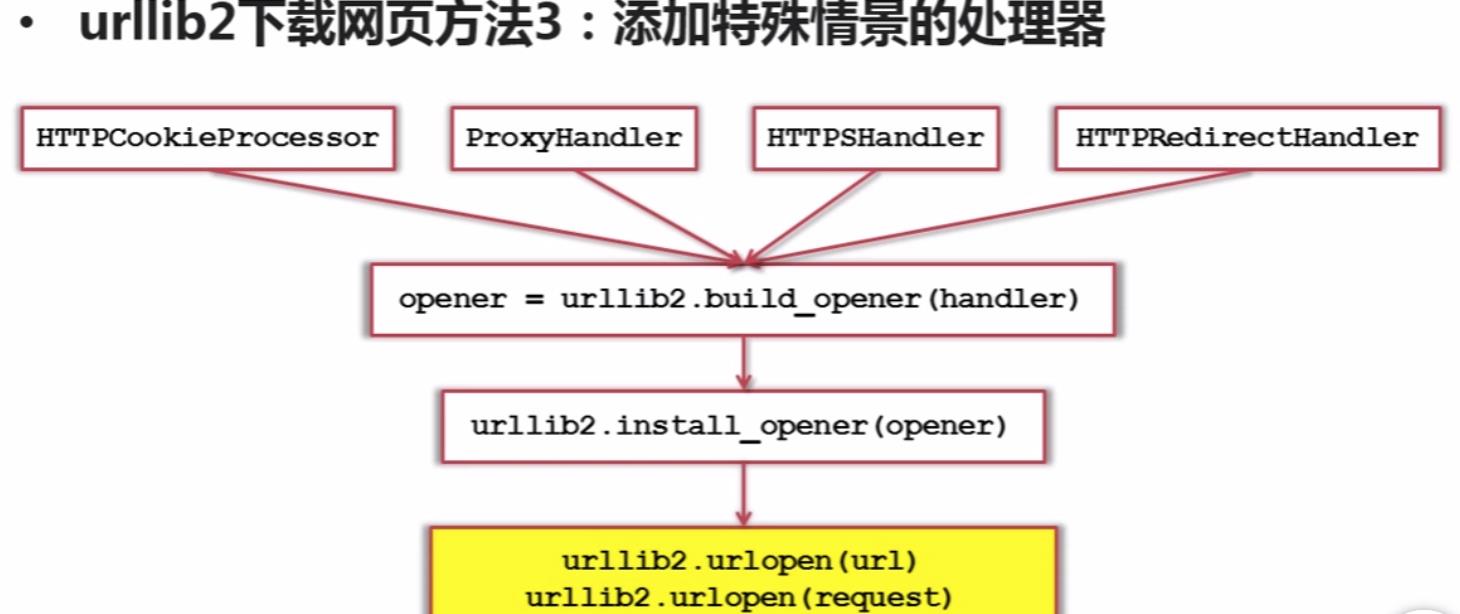
urllib2下载网页的3种方法

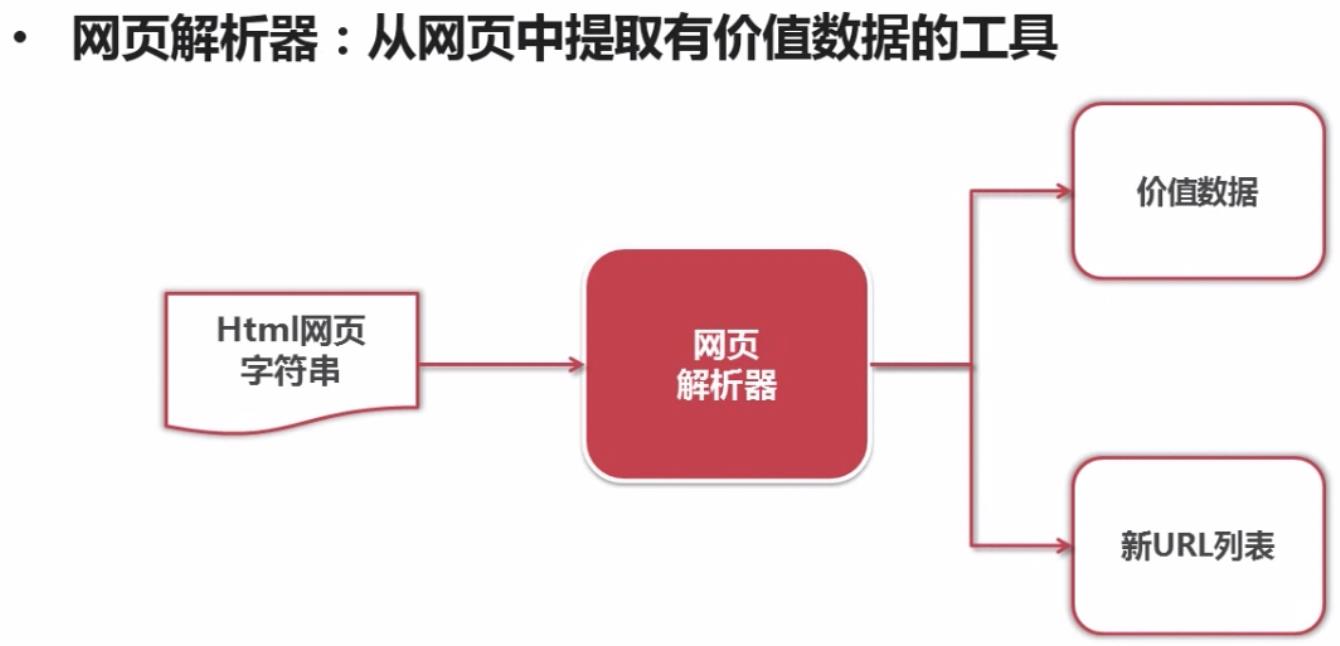
网页解析器的作用
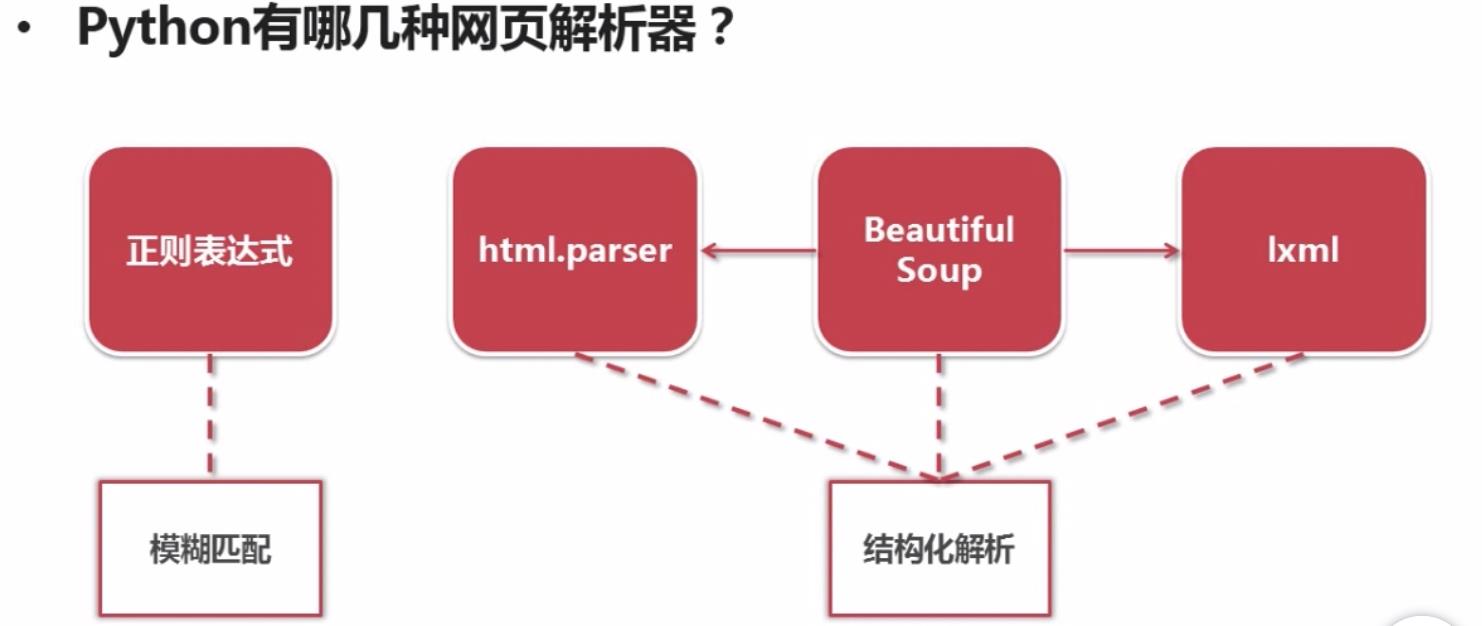
Python的几种网页解析器
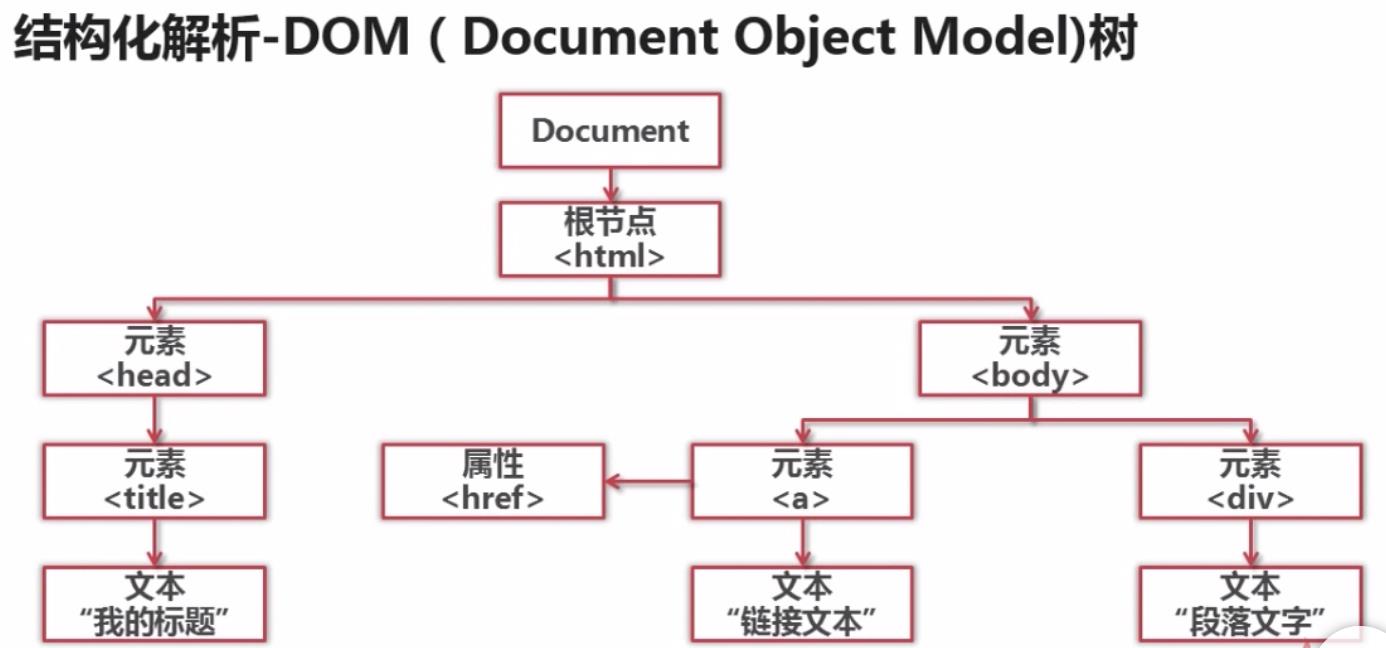
结构化解析依赖DOM树
Beautiful Soup语法
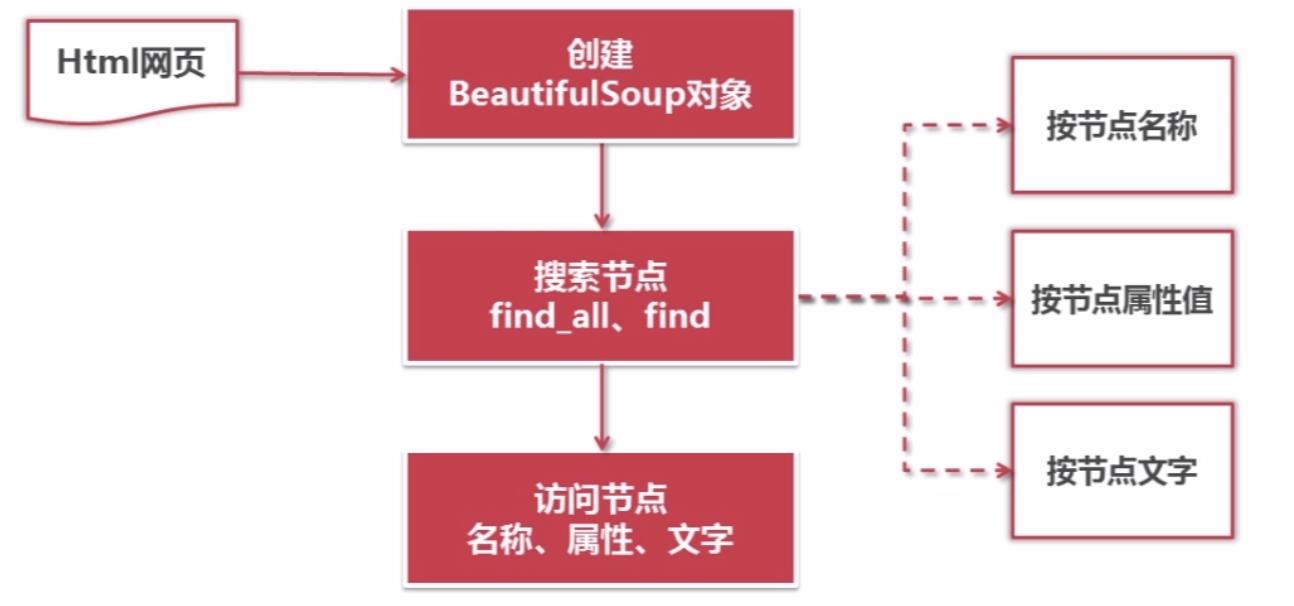

代码举例:
1.创建Beautiful Soup对象
1 from bs4 import BeautifulSoup 2 3 soup = BeautifulSoup( 4 html_doc, #HTML文档字符串 5 \'heml.parser\', #HTML解析器 6 from_encoding=\'utf-8\' #HTML文档的编码 7 )
2.find_all find方法的使用
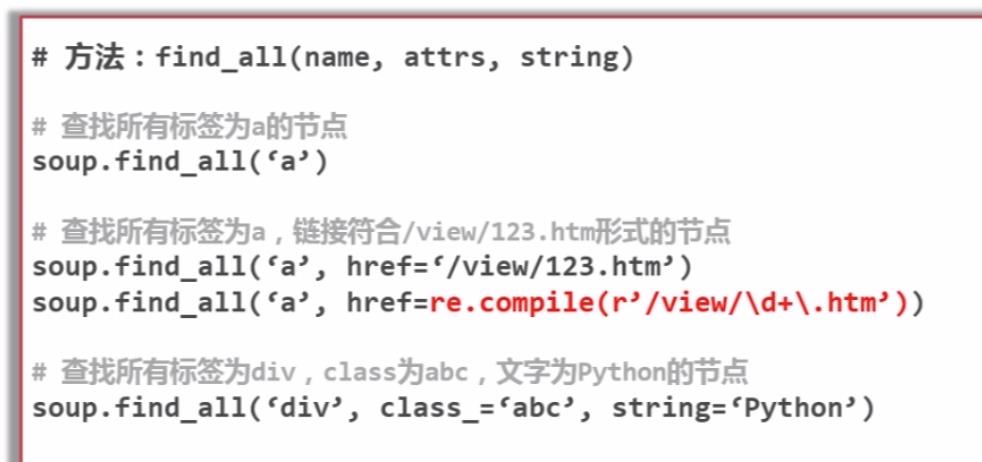
3.访问节点信息

4.Beautiful Soup处理html文档举例
1 from bs4 import BeautifulSoup 2 import re 3 4 html_doc = """ 5 <html><head><title>The Dormouse\'s story</title></head> 6 <body> 7 <p class="title"><b>The Dormouse\'s story</b></p> 8 9 <p class="story">Once upon a time there were three little sisters; and their names were 10 <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, 11 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and 12 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; 13 and they lived at the bottom of a well.</p> 14 15 <p class="story">...</p> 16 """ 17 18 soup = BeautifulSoup( 19 html_doc, #HTML文档字符串 20 \'html.parser\', #HTML解析器 21 from_encoding=\'utf-8\' #HTML文档的编码 22 ) 23 24 print(\'获取所有的连接\') 25 links = soup.find_all(\'a\') 26 for link in links: 27 print(link.name,link[\'href\'],link.get_text()) 28 29 print(\'获取tillie的连接\') 30 link_node = soup.find(\'a\',href=\'http://example.com/tillie\') 31 print(link_node.name,link_node[\'href\'],link_node.get_text()) 32 33 print(\'正则表达式匹配\') 34 link_node2 = soup.find(\'a\',href=re.compile(r\'lsi\')) 35 print(link_node2.name,link_node2[\'href\'],link_node2.get_text()) 36 37 print(\'获取P段落文字\') 38 p_node = soup.find(\'p\',class_=\'title\') 39 print(p_node.name,p_node.get_text())
控制台输出:
1 获取所有的连接 2 a http://example.com/elsie Elsie 3 a http://example.com/lacie Lacie 4 a http://example.com/tillie Tillie 5 获取tillie的连接 6 a http://example.com/tillie Tillie 7 正则表达式匹配 8 a http://example.com/elsie Elsie 9 获取P段落文字 10 p The Dormouse\'s story
更高级的爬虫还会涉及到“需登陆、验证码、Ajax、服务器防爬虫、多线程、分布式”等情况

以上是关于Python--开发简单爬虫的主要内容,如果未能解决你的问题,请参考以下文章