[实战演练]python3使用requests模块爬取页面内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[实战演练]python3使用requests模块爬取页面内容相关的知识,希望对你有一定的参考价值。
本文摘要:
1.安装pip
2.安装requests模块
3.安装beautifulsoup4
4.requests模块浅析
+ 发送请求 + 传递URL参数
+ 响应内容
+ 获取网页编码
+ 获取响应状态码
5.案例演示
后记
1.安装pip
我的个人桌面系统用的linuxmint,系统默认没有安装pip,考虑到后面安装requests模块使用pip,所以我这里第一步先安装pip。
$ sudo apt install python-pip
安装成功,查看PIP版本:
$ pip -V
2.安装requests模块
这里我是通过pip方式进行安装:
$ pip install requests
运行import requests,如果没提示错误,那说明已经安装成功了!

3.安装beautifulsoup4
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找、修改文档的方式。Beautiful Soup会帮你节省数小时甚至数天的工作时间。
$ sudo apt-get install python3-bs4
注:这里我使用的是python3的安装方式,如果你用的是python2,可以使用下面命令安装。
$ sudo pip install beautifulsoup4
4.requests模块浅析
1)发送请求
首先当然是要导入 Requests 模块:
>>> import requests
然后,获取目标抓取网页。这里我以简书为例:
>>> r = requests.get(‘http://www.cnblogs.com/chanzhi/p/7542447.html‘)
这里返回一个名为 r 的响应对象。我们可以从这个对象中获取所有我们想要的信息。这里的get是http的响应方法,所以举一反三你也可以将其替换为put、delete、post、head。
2)传递URL参数
有时我们想为 URL 的查询字符串传递某种数据。如果你是手工构建 URL,那么数据会以键/值对的形式置于 URL 中,跟在一个问号的后面。例如, cnblogs.com/get?key=val。 Requests 允许你使用 params 关键字参数,以一个字符串字典来提供这些参数。
举例来说,当我们google搜索“python爬虫”关键词时,newwindow(新窗口打开)、q及oq(搜索关键词)等参数可以手工组成URL ,那么你可以使用如下代码:
>>> payload = {‘newwindow‘: ‘1‘, ‘q‘: ‘python爬虫‘, ‘oq‘: ‘python爬虫‘}
>>> r = requests.get("https://www.google.com/search", params=payload)
3)响应内容
通过r.text或r.content来获取页面响应内容。
>>> import requests
>>> r = requests.get(‘https://github.com/timeline.json‘)
>>> r.text
Requests 会自动解码来自服务器的内容。大多数 unicode 字符集都能被无缝地解码。这里补充一点r.text和r.content二者的区别,简单说:
resp.text返回的是Unicode型的数据;
resp.content返回的是bytes型也就是二进制的数据;
所以如果你想取文本,可以通过r.text,如果想取图片,文件,则可以通过r.content。
4)获取网页编码
>>> r = requests.get(‘http://www.cnblogs.com/‘)
>>> r.encoding
‘utf-8‘
5)获取响应状态码
我们可以检测响应状态码:
>>> r = requests.get(‘http://www.cnblogs.com/‘)
>>> r.status_code
200
5.案例演示
最近公司刚引入了一款OA系统,这里我以其官方说明文档页面为例,并且只抓取页面中文章标题和内容等有用信息。
演示环境
操作系统:linuxmint
python版本:python 3.5.2
使用模块:requests、beautifulsoup4
代码如下:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 _author_ = ‘GavinHsueh‘ 4 5 import requests 6 import bs4 7 8 #要抓取的目标页码地址 9 url = ‘http://www.ranzhi.org/book/ranzhi/about-ranzhi-4.html‘ 10 11 #抓取页码内容,返回响应对象 12 response = requests.get(url) 13 14 #查看响应状态码 15 status_code = response.status_code 16 17 #使用BeautifulSoup解析代码,并锁定页码指定标签内容 18 content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml") 19 element = content.find_all(id=‘book‘) 20 21 print(status_code) 22 print(element)
程序运行返回爬去结果:
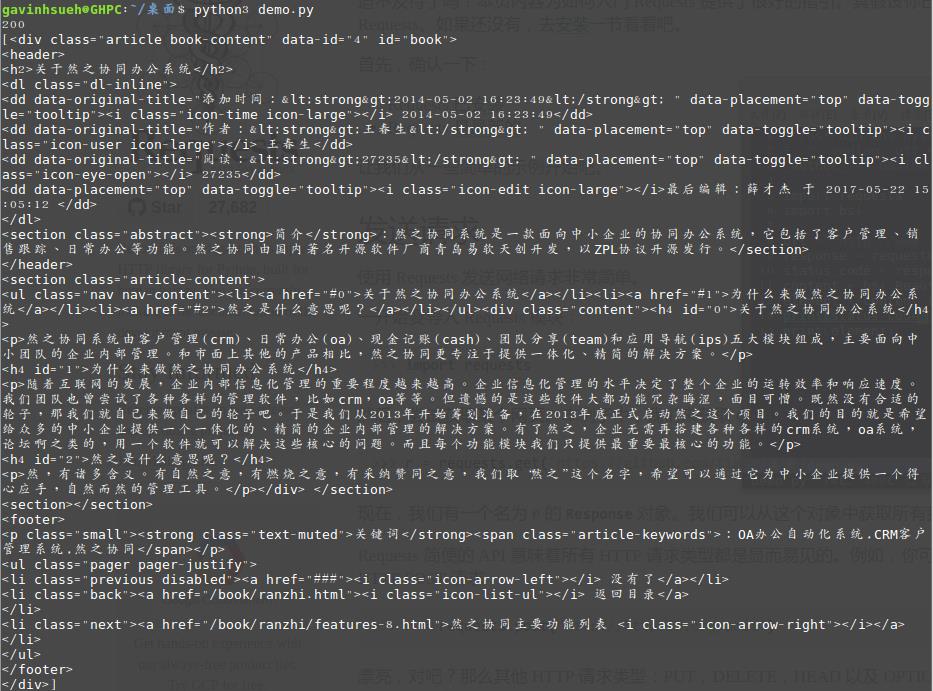
关于爬去结果乱码问题
其实起初我是直接用的系统默认自带的python2操作的,但在抓取返回内容的编码乱码问题上折腾了老半天,google了多种解决方案都无效。在被python2“整疯“之后,只好老老实实用python3了。对于python2的爬取页面内容乱码问题,欢迎各位前辈们分享经验,以帮助我等后生少走弯路。
后记
python的爬虫相关模块有很多,除了requests模块,再如urllib和pycurl以及tornado等。相比而言,我个人觉得requests模块是相对简单易上手的了。通过文本,大家可以迅速学会使用python的requests模块爬取页码内容。本人能力有限,如果文章有任何错误欢迎不吝赐教,其次如果大家有任何关于python爬去页面内容的疑难杂问,也欢迎和大家一起交流讨论。
我们共同学习,共同交流,共同进步!
参考:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#
http://cn.python-requests.org/zh_CN/latest/

以上是关于[实战演练]python3使用requests模块爬取页面内容的主要内容,如果未能解决你的问题,请参考以下文章