Day-3: Python基础
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day-3: Python基础相关的知识,希望对你有一定的参考价值。
-
数据类型和变量
Python中直接处理的数据类型主要有以下几种:
- 整数:Python可以直接处理任意大小的整数,无论正负,都可以直接输入处理;
- 浮点数:浮点数也叫做小数。有普通写法,如:1.1,也有描述很大或者很小的科学计数法,有e代替10,有1.3e6、1.2e-5等;
- 字符串:用‘’和“”表示的都是字符串,如‘abc’,“ABC”。但是如果字符串中包含’或者”,则注意只包含’,外面用“”括起来;只包含”的,外面用‘’括起来。和c中一样,\\是转义字符,但是使用比较麻烦。如果‘和”都包含的话,可以在字符串前面加上r表示原意,内部的转义字符就都没用了。如果想表示多行内容,可以用
‘‘‘line1 line2 line3‘‘‘
4. 布尔值:两个值,分别是True和False。布尔值可以进行的运算以下几种:
- and运算。只有左右两值均为True时,结果才为True。注意:1 and 2时,如果1为False,则2没有进行计算,因为结果已经确定为False,称为短路现象;
- or运算。左右两值任一为True时,结果就为True。注意:同上,由于短路现象,只要 1 or 2中1为True,2就不会计算,结果直接为True;
- not运算。为单目运算,True变为False,False变成True。
5. None:空值,它不能理解为0,0是有意义的,而None是特殊的空值。
变量:
Python中变量没有类型的限制,定义时不用声明是什么类型,直接使用即可。
-
Python字符串和编码
Python 2.7中所有字符默认是ASCII编码,要表示Unicode编码(多国语言)时,使用:
u‘...‘
特别的由于ASCII编码中没有中文,所以字符串中有中文时,务必再前面加上u。(Python3.0改为‘....’和u‘....’都是Unicode编码了)
但是,ASCII编码使用1个字节,Unicode编码一般使用两个字节,特别的甚至4个字节。为了节省空间,Unicode编码又变成了可变的Unicode编码,即utf-8编码。下面两个图是记事本编辑和浏览网页时编码形式的转换:
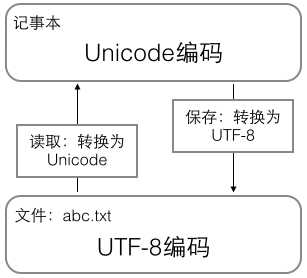
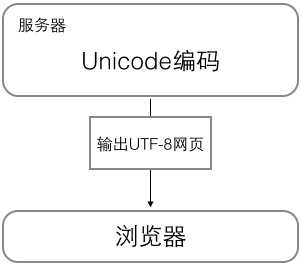
可以看出,在存储和传输时,以utf-8编码节省时间,但是使用时选择Unicode编码,保证正确地显示和编辑。
再说Python 2.7中ASCII编码加上u的前缀变成Unicode编码后用encode(‘utf-8’)方法,变成utf-8编码,反过来,utf-8编码经过decode(‘utf-8’)解码成Unicode编码。过程如下:
>>> u‘中文‘.encode(‘utf-8‘) ‘\\xe4\\xb8\\xad\\xe6\\x96\\x87‘ #注意变成了一个字节的编码格式,utf-8 >>> ‘\\xe4\\xb8\\xad\\xe6\\x96\\x87‘.decode(‘utf-8‘) u‘\\u4e2d\\u6587‘ #变成2个字节编码,Unicode >>> print ‘\\xe4\\xb8\\xad\\xe6\\x96\\x87‘.decode(‘utf-8‘) 中文 #先由utf-8变成Unicode再打印
考虑到Python的跨平台运行,通常文件开头要加上这两行:
#!/usr/bin/env python # -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
Python中格式化输出:
‘....‘ % (....)
字符串中有几个占位符,后面的括号就有几个变量或者常量。
常用的占位符有:
%d 整数
%f 浮点数
%s 字符数
%x 十六进制整数
-
三种特殊的数据类型
- list
list是一种有序的集合,可以随时增减元素。用[]表示,索引是从0开始的,最后一个是个数-1.他有如下方法:
- len():获取list元素的个数
>>> len(classmates)
3
- append():list末尾增加一个元素
>>>list1 = [1, 2, 3] >>>list1.append(4) # 将元素添加在最后 >>>list1 >>>[1, 2, 3, 4]
- insert():list插入一个元素
>>>list1 = [1, 2, 3] >>>list1.insert(2,6) # 第一个参数是插入的位置,第二个是元素 >>>print list1 >>>[1, 2, 6, 3]
>>>print list1.insert(7) # 只有一个参数时,作为元素插入在最后
>>>[1, 2, 6, 3, 7]
- pop():删除一个元素
>>> classmates.pop() # 无参数时删除最后一个元素 ‘Adam‘ >>> classmates [‘Michael‘, ‘Jack‘, ‘Bob‘, ‘Tracy‘] >>> classmates.pop(1) # 删除索引位置为该参数的元素 ‘Jack‘ >>> classmates [‘Michael‘, ‘Bob‘, ‘Tracy‘]
- tuple
tuple,名元祖。与list相似,但是tuple一旦建立,其中的元素无法更改,也没有append()等方法。它的意义在于确保元素无法改变,保证安全性。索引时,使用(),也是从0开始。
- dict
全称dictionary,使用键-值(key-value)存储,具有极快的查找速度。
>>> d = {‘Michael‘: 95, ‘Bob‘: 75, ‘Tracy‘: 85}
>>> d[‘Michael‘]
95
dict是由Hash算法通过key计算出value的存储位置,所以key的值不变的。特点是
- 查找和插入的速度极快,不会随着key的增加而增加;
- 需要占用大量的内存,内存浪费多。
有get()和pop()两种方法:
>>> d.get(‘Thomas‘) # 返回None的时候Python的交互式命令行不显示结果。 >>> d.get(‘Thomas‘, -1) -1
>>> d.pop(‘Bob‘) 75 >>> d {‘Michael‘: 95, ‘Tracy‘: 85}
- set
set和dict相似,唯一区别仅在于没有存储对应的value。
set需要提供一个list作为输入集合,显示的set([1, 2, 3])只是告诉你这个set内部有1,2,3这3个元素,显示的[]不表示这是一个list。
set中用add(key)方法添加元素到set中;
set中用remove(key)方法删除元素。
-
条件判断和循环
python中对于缩进特别严格,它是以同样的缩进来作为块执行的。
其中,python在判断和循环语句中,均是以:来作为缩进标识。
判断语句的完整形式:
if <条件判断1>: <执行1> elif <条件判断2>: <执行2> elif <条件判断3>: <执行3> else: <执行4>
循环语句有两种,一种是for...in循环,一种是while循环。
for...in循环如下:
names = [‘Michael‘, ‘Bob‘, ‘Tracy‘] for name in names: print name
把names中的每个元素带入name依次做循环。
while循环则是:只要条件满足,就不断循环,条件不满足时退出循环。
sum = 0 n = 99 while n > 0: sum = sum + n n = n - 2 print sum
最后raw_input()需要注意下,
birth = raw_input(‘birth:‘)
里面的字符串‘birth’是在运行时在终端上显示birth: ,但是实际输入年龄的数字,传递给birth的是一个字符串,如果要传输integer,应改为:
birth = int(raw_input(‘birth:‘))
以上是关于Day-3: Python基础的主要内容,如果未能解决你的问题,请参考以下文章
学习PYTHON之路, DAY 3 - PYTHON 基础 3 (函数)
Python 基础 - Day 3 Assignment - Compensation Management System 工资管理系统