第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中相关的知识,希望对你有一定的参考价值。
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复
布隆过滤器(Bloom Filter)详解
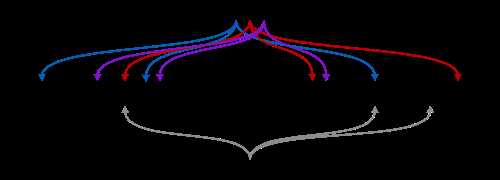
基本概念
如果想判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit Array)中的一个点。这样一来,我们只要看看这个点是不是 1 就知道可以集合中有没有它了。这就是布隆过滤器的基本思想。
Hash面临的问题就是冲突。假设 Hash 函数是良好的,如果我们的位阵列长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m/100 个元素。显然这就不叫空间有效了(Space-efficient)。解决方法也简单,就是使用多个 Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外, Hash 函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器可以表示全集,其它任何数据结构都不能;
k 和 m 相同,使用同一组 Hash 函数的两个布隆过滤器的交并差运算可以使用位操作进行。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率(False Positive)是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素. 我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
python 基于redis实现的bloomfilter(布隆过滤器),BloomFilter_imooc
BloomFilter_imooc下载
下载地址:https://github.com/liyaopinner/BloomFilter_imooc
依赖关系:
python 基于redis实现的bloomfilter
依赖mmh3
安装依赖包:
pip install mmh3
1、安装好BloomFilter_imooc所需要的依赖
2、将下载的BloomFilter_imooc包解压后,将里面的py_bloomfilter.py文件复制到scrapy工程目录
py_bloomfilter.py(布隆过滤器)源码
import mmh3 import redis import math import time class PyBloomFilter(): #内置100个随机种子 SEEDS = [543, 460, 171, 876, 796, 607, 650, 81, 837, 545, 591, 946, 846, 521, 913, 636, 878, 735, 414, 372, 344, 324, 223, 180, 327, 891, 798, 933, 493, 293, 836, 10, 6, 544, 924, 849, 438, 41, 862, 648, 338, 465, 562, 693, 979, 52, 763, 103, 387, 374, 349, 94, 384, 680, 574, 480, 307, 580, 71, 535, 300, 53, 481, 519, 644, 219, 686, 236, 424, 326, 244, 212, 909, 202, 951, 56, 812, 901, 926, 250, 507, 739, 371, 63, 584, 154, 7, 284, 617, 332, 472, 140, 605, 262, 355, 526, 647, 923, 199, 518] #capacity是预先估计要去重的数量 #error_rate表示错误率 #conn表示redis的连接客户端 #key表示在redis中的键的名字前缀 def __init__(self, capacity=1000000000, error_rate=0.00000001, conn=None, key=‘BloomFilter‘): self.m = math.ceil(capacity*math.log2(math.e)*math.log2(1/error_rate)) #需要的总bit位数 self.k = math.ceil(math.log1p(2)*self.m/capacity) #需要最少的hash次数 self.mem = math.ceil(self.m/8/1024/1024) #需要的多少M内存 self.blocknum = math.ceil(self.mem/512) #需要多少个512M的内存块,value的第一个字符必须是ascii码,所有最多有256个内存块 self.seeds = self.SEEDS[0:self.k] self.key = key self.N = 2**31-1 self.redis = conn # print(self.mem) # print(self.k) def add(self, value): name = self.key + "_" + str(ord(value[0])%self.blocknum) hashs = self.get_hashs(value) for hash in hashs: self.redis.setbit(name, hash, 1) def is_exist(self, value): name = self.key + "_" + str(ord(value[0])%self.blocknum) hashs = self.get_hashs(value) exist = True for hash in hashs: exist = exist & self.redis.getbit(name, hash) return exist def get_hashs(self, value): hashs = list() for seed in self.seeds: hash = mmh3.hash(value, seed) if hash >= 0: hashs.append(hash) else: hashs.append(self.N - hash) return hashs pool = redis.ConnectionPool(host=‘127.0.0.1‘, port=6379, db=0) conn = redis.StrictRedis(connection_pool=pool) # 使用方法 # if __name__ == "__main__": # bf = PyBloomFilter(conn=conn) # 利用连接池连接Redis # bf.add(‘www.jobbole.com‘) # 向Redis默认的通道添加一个域名 # bf.add(‘www.luyin.org‘) # 向Redis默认的通道添加一个域名 # print(bf.is_exist(‘www.zhihu.com‘)) # 打印此域名在通道里是否存在,存在返回1,不存在返回0 # print(bf.is_exist(‘www.luyin.org‘)) # 打印此域名在通道里是否存在,存在返回1,不存在返回0
将py_bloomfilter.py(布隆过滤器)集成到scrapy-redis中的dupefilter.py去重器中,使其抓取过的URL不添加到下载器,没抓取过的URL添加到下载器
scrapy-redis中的dupefilter.py去重器修改
import logging import time from scrapy.dupefilters import BaseDupeFilter from scrapy.utils.request import request_fingerprint from . import defaults from .connection import get_redis_from_settings from bloomfilter.py_bloomfilter import conn,PyBloomFilter #导入布隆过滤器 logger = logging.getLogger(__name__) # TODO: Rename class to RedisDupeFilter. class RFPDupeFilter(BaseDupeFilter): """Redis-based request duplicates filter. This class can also be used with default Scrapy‘s scheduler. """ logger = logger def __init__(self, server, key, debug=False): """Initialize the duplicates filter. Parameters ---------- server : redis.StrictRedis The redis server instance. key : str Redis key Where to store fingerprints. debug : bool, optional Whether to log filtered requests. """ self.server = server self.key = key self.debug = debug self.logdupes = True # 集成布隆过滤器 self.bf = PyBloomFilter(conn=conn, key=key) # 利用连接池连接Redis @classmethod def from_settings(cls, settings): """Returns an instance from given settings. This uses by default the key ``dupefilter:<timestamp>``. When using the ``scrapy_redis.scheduler.Scheduler`` class, this method is not used as it needs to pass the spider name in the key. Parameters ---------- settings : scrapy.settings.Settings Returns ------- RFPDupeFilter A RFPDupeFilter instance. """ server = get_redis_from_settings(settings) # XXX: This creates one-time key. needed to support to use this # class as standalone dupefilter with scrapy‘s default scheduler # if scrapy passes spider on open() method this wouldn‘t be needed # TODO: Use SCRAPY_JOB env as default and fallback to timestamp. key = defaults.DUPEFILTER_KEY % {‘timestamp‘: int(time.time())} debug = settings.getbool(‘DUPEFILTER_DEBUG‘) return cls(server, key=key, debug=debug) @classmethod def from_crawler(cls, crawler): """Returns instance from crawler. Parameters ---------- crawler : scrapy.crawler.Crawler Returns ------- RFPDupeFilter Instance of RFPDupeFilter. """ return cls.from_settings(crawler.settings) def request_seen(self, request): """Returns True if request was already seen. Parameters ---------- request : scrapy.http.Request Returns ------- bool """ fp = self.request_fingerprint(request) # 集成布隆过滤器 if self.bf.is_exist(fp): # 判断如果域名在Redis里存在 return True else: self.bf.add(fp) # 如果不存在,将域名添加到Redis return False # This returns the number of values added, zero if already exists. # added = self.server.sadd(self.key, fp) # return added == 0 def request_fingerprint(self, request): """Returns a fingerprint for a given request. Parameters ---------- request : scrapy.http.Request Returns ------- str """ return request_fingerprint(request) def close(self, reason=‘‘): """Delete data on close. Called by Scrapy‘s scheduler. Parameters ---------- reason : str, optional """ self.clear() def clear(self): """Clears fingerprints data.""" self.server.delete(self.key) def log(self, request, spider): """Logs given request. Parameters ---------- request : scrapy.http.Request spider : scrapy.spiders.Spider """ if self.debug: msg = "Filtered duplicate request: %(request)s" self.logger.debug(msg, {‘request‘: request}, extra={‘spider‘: spider}) elif self.logdupes: msg = ("Filtered duplicate request %(request)s" " - no more duplicates will be shown" " (see DUPEFILTER_DEBUG to show all duplicates)") self.logger.debug(msg, {‘request‘: request}, extra={‘spider‘: spider}) self.logdupes = False
爬虫文件
#!/usr/bin/env python # -*- coding:utf8 -*- from scrapy_redis.spiders import RedisCrawlSpider # 导入scrapy_redis里的RedisCrawlSpider类 import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import Rule class jobboleSpider(RedisCrawlSpider): # 自定义爬虫类,继承RedisSpider类 name = ‘jobbole‘ # 设置爬虫名称 allowed_domains = [‘www.luyin.org‘] # 爬取域名 redis_key = ‘jobbole:start_urls‘ # 向redis设置一个名称储存url rules = ( # 配置抓取列表页规则 # Rule(LinkExtractor(allow=(‘ggwa/.*‘)), follow=True), # 配置抓取内容页规则 Rule(LinkExtractor(allow=(‘.*‘)), callback=‘parse_job‘, follow=True), ) def parse_job(self, response): # 回调函数,注意:因为CrawlS模板的源码创建了parse回调函数,所以切记我们不能创建parse名称的函数 # 利用ItemLoader类,加载items容器类填充数据 neir = response.css(‘title::text‘).extract() print(neir)
启动爬虫 scrapy crawl jobbole
cd 到redis安装目录执行命令:redis-cli -h 127.0.0.1 -p 6379 连接redis客户端
连接redis客户端后执行命令:lpush jobbole:start_urls http://www.luyin.org 向redis添加一个爬虫起始url
开始爬取
redis状态说明:
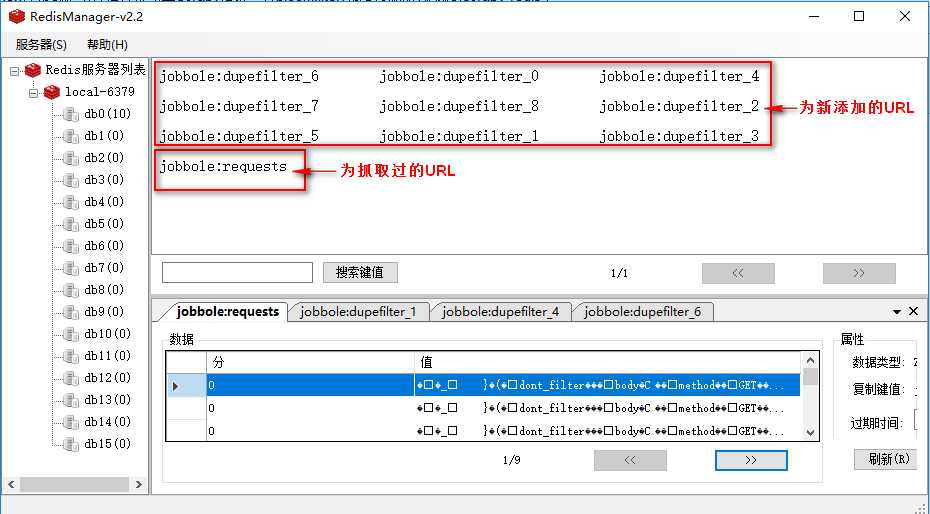
以上是关于第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中的主要内容,如果未能解决你的问题,请参考以下文章
第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能