python之路-----MySql操作三
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之路-----MySql操作三相关的知识,希望对你有一定的参考价值。
mysql 概述
一.主要内容:
视图 create view name (select * from user where id>5);
触发器
函数
存储过程
索引
二.各模块详细说明
1.视图
加速有临时表:(select * from user where id>5) as B 需要再100个sql语句中使用,如果按照临时表的写法,需要再100个sql语句里重复写:(select * from user where id>5) as B.
这无疑增加了代码量。这时候可以将临时表存为视图,供sql语句使用。(某个查询语句设置别名,日后方便使用)
定义:视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】,用户使用时只需使用【名称】即可获取结果集,并可以将其当作表来使用。
视图的命令:
新增:
create view viem_name as sql语句; e.g:CREATE VIEW user_view AS (SELECT * FROM userinfo WHERE id>1); 修改: ALTER VIEW view_name as sql语句; e.g:ALTER VIEW user_view as (SELECT * FROM userinfo WHERE id>2);
删除:
drop view view name;
视图的特点:
1.由于视图是虚拟表,所以不能对视图的数据进行增删改
2.视图的内容随着物理表的变化而变化,如user表新增一个id为10的数据,则视图也会同时将该数据加入。
2.触发器
当我们在对每一行数据进行增删改前后(查询不会触发触发器),可以定义一系列其他动作。如:往user表新增数据时,则在资产表新增对应的用户信息等。
定义:对某个表进行【增/删/改】操作的前后如果希望触发某个特定的行为时,可以使用触发器,触发器用于定制用户对表的行进行【增/删/改】前后的行为。
触发器的命令
新增:
插入前: delimiter // --定义结束符为 // ,结束符可自定义 CREATE TRIGGER trigger_name BEFORE INSERT ON tb_name FOR EACH ROW BEGIN sql语句1; sql语句2; .... END // ---根据自己定义的结束符结束创建触发器命令 delimiter ; ---将结束符改回;,避免影响其他sql语句执行 插入后: delimiter // --定义结束符为 // ,结束符可自定义 CREATE TRIGGER trigger_name AFTER INSERT ON tb_name FOR EACH ROW BEGIN sql语句1; sql语句2; .... END // ---根据自己定义的结束符结束创建触发器命令 delimiter ; ---将结束符改回;,避免影响其他sql语句执行 删除前,删除后,更改前,更改后只需要将insert改为delete,update即可。命令结构是一样的。
修改:
触发器无法修改,只能删除重建
删除:
DROP TRIGGER trigger_name;
触发器的使用:
触发器无法由用户直接调用,而知由于对表的【增/删/改】操作被动引发的。


1.old new old表示表中的旧数据,new表示为用户新增的数据。我们可以使用new,old来完成一些数据操作。 ps: new相当于Python中的对象类型,里面还有多个属性,调用时,插入值时,需要具体的属性名称. 例如插入表 a(id,name,gender) values(1,‘test‘,‘man‘),则 new.id=1,new.name=‘test‘,new.gender=‘man‘ old跟new同理 e.g: new:将a表新插入的数据同时插入b表 delimiter // CREATE TRIGGER tr_a_b AFTER INSERT ON a FOR EACH ROW BEGIN insert into b(name) values(new.name); END // delimiter ; old:删除a表前将删除的数据插入b表 delimiter // CREATE TRIGGER tr_a_b_del1 BEFORE DELETE ON a FOR EACH ROW BEGIN INSERT INTO b(id,name,gender) VALUES(old.id,old.name,old.gender); END // delimiter ; 补充说明:在删除前触发器中,我们将 old改为new,发现命令报错,说明old代表表中已存在的数据,而new表示用户新增加的数据。且old,new都是跟 操作表有关,示例中的a表,与b表是无关的。
3.函数
函数分为内置函数和自定义函数
3.1 内置函数
CHAR_LENGTH(str) 返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。 对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 CONCAT(str1,str2,...) 字符串拼接 如有任何一个参数为NULL ,则返回值为 NULL。 CONCAT_WS(separator,str1,str2,...) 字符串拼接(自定义连接符) CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base) 进制转换 例如: SELECT CONV(‘a‘,16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D) 将数字X 的格式写为‘#,###,###.##‘,以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。 例如: SELECT FORMAT(12332.1,4); 结果为: ‘12,332.1000‘ INSERT(str,pos,len,newstr) 在str的指定位置插入字符串 pos:要替换位置其实位置 len:替换的长度 newstr:新字符串 特别的: 如果pos超过原字符串长度,则返回原字符串 如果len超过原字符串长度,则由新字符串完全替换 INSTR(str,substr) 返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len) 返回字符串str 从开始的len位置的子序列字符。 LOWER(str) 变小写 UPPER(str) 变大写 LTRIM(str) 返回字符串 str ,其引导空格字符被删除。 RTRIM(str) 返回字符串 str ,结尾空格字符被删去。 SUBSTRING(str,pos,len) 获取字符串子序列 LOCATE(substr,str,pos) 获取子序列索引位置 REPEAT(str,count) 返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。 若 count <= 0,则返回一个空字符串。 若str 或 count 为 NULL,则返回 NULL 。 REPLACE(str,from_str,to_str) 返回字符串str 以及所有被字符串to_str替代的字符串from_str 。 REVERSE(str) 返回字符串 str ,顺序和字符顺序相反。 RIGHT(str,len) 从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N) 返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len) 不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 mysql> SELECT SUBSTRING(‘Quadratically‘,5); -> ‘ratically‘ mysql> SELECT SUBSTRING(‘foobarbar‘ FROM 4); -> ‘barbar‘ mysql> SELECT SUBSTRING(‘Quadratically‘,5,6); -> ‘ratica‘ mysql> SELECT SUBSTRING(‘Sakila‘, -3); -> ‘ila‘ mysql> SELECT SUBSTRING(‘Sakila‘, -5, 3); -> ‘aki‘ mysql> SELECT SUBSTRING(‘Sakila‘ FROM -4 FOR 2); -> ‘ki‘ TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str) 返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。 mysql> SELECT TRIM(‘ bar ‘); -> ‘bar‘ mysql> SELECT TRIM(LEADING ‘x‘ FROM ‘xxxbarxxx‘); -> ‘barxxx‘ mysql> SELECT TRIM(BOTH ‘x‘ FROM ‘xxxbarxxx‘); -> ‘bar‘ mysql> SELECT TRIM(TRAILING ‘xyz‘ FROM ‘barxxyz‘); -> ‘barx‘ 部分内置函数
官方内置函数网址:
https://dev.mysql.com/doc/refman/5.7/en/functions.html
中文版内置函数:
http://doc.mysql.cn/mysql5/refman-5.1-zh.html-chapter/functions.html#encryption-functions
3.2 自定义函数
创建函数
delimiter // CREATE FUNCTION func_name( a INT, #声明变量和变量类型 b INT ) RETURNS INT #设置返回值类型 BEGIN DECLARE c INT; #声明变量 set c=a+b; #赋值运算 RETURN(c); #返回值 END // delimiter ;
删除函数
drop function func_name;
执行函数
# 获取返回值 declare @i VARCHAR(32); select UPPER(‘alex‘) into @i; SELECT @i; # 在查询中使用 select f1(11,nid) ,name from tb2; #直接使用 select f1(1,2);
使用pymysql调用mysql函数
cursor=conn.cursor() cursor.execute(‘select f1(6,2)‘) res=cursor.fetchone()
4.存储过程
存储过程是一个SQL语句集合,当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行。
4.1.简单存储过程
delimiter // CREATE PROCEDURE p1() BEGIN SELECT * FROM userinfo WHERE id<4; INSERT into b(name,gender) VALUES(‘test1‘,‘112‘); END // delimiter ;
4.2.带参数的存储过程(in,out,inout)
- in 仅用于传入参数用
- out 仅用于返回值用
- inout 既可以传入又可以当作返回值
创建:
delimiter // CREATE PROCEDURE p1( IN nid INT ) BEGIN SELECT * FROM userinfo WHERE id<nid; END // delimiter ; 使用: CALL p1(2);
delimiter // CREATE PROCEDURE p2( OUT nid int ) BEGIN set nid=111111; END // delimiter ; 执行: set @v1=10; --需要先定义变量,再将输出赋值给变量 call p2(@v1); SELECT @v1;
inout是in和out的结合体,用法同in和out。
补充:
为什么有结果集又有out伪造的返回值? 1.存储过程和函数不一样,并没有返回值。如果我们需要使用返回值的时候,可以定义out来伪造返回值。 2.用于标识存储过程的执行结果。我们可以在存储过程的不同阶段返回不同的返回值来标记执行结果。 用于标识存储过程的执行结果示例; delimiter // create procedure p3( in n1 int, out n2 int 用于标识存储过程的执行结果 1表示成功,2表示失败 ) BEGIN 代码监测: insert into vv(..) insert into vv(..) insert into vv(..) set n2=1; 发生异常: set n2=2; END // delimiter ;
4.3.事物
事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。
delimiter // create procedure p4( out status int ) BEGIN 1. 声明如果出现异常则执行{ set status = 1; rollback; --回滚 } 开始事务 -- 由秦兵账户减去100 -- 方少伟账户加90 -- 张根账户加10 commit; 结束 set status = 2; END // delimiter ;
delimiter \\create PROCEDURE p5( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; START TRANSACTION; DELETE from tb1; insert into tb2(name)values(‘seven‘); COMMIT; -- SUCCESS set p_return_code = 2; END\\delimiter ;
4.4.游标(性能比较差,最好在程序级别进行操作)
4.4.1 游标使用原理:
1.声明游标
2.取操作表的数据
my_cursor select id,num from userinfo;
3.循环每行数据
for row.id,row.num in my_cursor:
#游标无法自动识别是否无数据,需要检测循环是否有数据,如果无数据,则结束循环
delimiter // create procedure p6() begin declare row_id int; -- 自定义变量1 declare row_num int; -- 自定义变量2 declare done INT DEFAULT FALSE; #设置循环结束标志为False declare temp int; declare my_cursor CURSOR FOR select id,num from A; #声明游标,my_cursor类型为cursor,并且从A表中取数据给游标my_cursor declare CONTINUE HANDLER FOR NOT FOUND SET done = TRUE; #如果游标数据取完,则设置done为True open my_cursor; #打开游标 xxoo: LOOP #xxoo为自定义循环名称 fetch my_cursor into row_id,row_num; #等于python中的for .. in ..,拿一行数据赋值给row_id,row_num if done then #如果数据取完,则结束循环 leave xxoo; END IF; set temp = row_id + row_num; insert into B(number) values(temp); end loop xxoo; close my_cursor; end // delimter ;
4.5.动态执行(防sql注入)
4.5.1 命令格式
delimiter // create procedure p7( in sql varchar(255), in arg int ) begin --1. 预检测某个东西 SQL语句合法性 --2. SQL =格式化 tpl + arg --3. 执行SQL语句 set @xo = arg; PREPARE xxx FROM ‘select * from student where sid > ?‘; -- ?是占位符 EXECUTE xxx USING @xo; DEALLOCATE prepare prod; end // delimter ;
delimiter \\CREATE PROCEDURE p8 ( in nid int ) BEGIN set @nid = nid; --需要先将出入的参数值转换为session变量(命令要求,否则会保持错) PREPARE prod FROM ‘select * from student where sid > ?‘; --预制语句,prod为自定义名称 EXECUTE prod USING @nid; --将nid传入 ‘select * from student where sid > ?‘ 的占位符?处 DEALLOCATE prepare prod; --执行sql命令 END \\delimiter ;
4.6.存储过程执行
mysql执行
-- 无参数 call proc_name() -- 有参数,全in call proc_name(1,2) -- 有参数,有in,out,inout set @t1=0; set @t2=3; call proc_name(1,2,@t1,@t2)
pymysql执行
#!/usr/bin/env python # -*- coding:utf-8 -*- import pymysql conn = pymysql.connect(host=‘127.0.0.1‘, port=3306, user=‘root‘, passwd=‘123‘, db=‘t1‘) cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 执行存储过程 cursor.callproc(‘p1‘, args=(1, 22, 3, 4)) # 获取执行完存储的参数 cursor.execute("select @_p1_0,@_p1_1,@_p1_2,@_p1_3") #固定格式 @__存储过程名称__第几个参数 result = cursor.fetchall() conn.commit() cursor.close() conn.close() print(result)
4.7.存储过程删除
drop PROCEDURE 存储过程名
5.索引
索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构。类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获取即可。
5.1 索引的作用:
1.根据索引类型的不同,有不同的越苏
2.加速查询速度。(但是会降低行修改,增加,删除的效率)
5.2 索引加速的原理:
将索引内容以某种存储格式创建额外的文件,用来加速查询。
1.hash加速
通过将索引内容hash后报存在额外的文件里,查询时如果为索引值,则优先在这张表里查询。由于hash报存时,并不是按照表内容的顺序进行报存,而是随机顺序保存,所以hash方式的索引在范围查找时效率较低,单值查找时较快。
2.btree
mysql默认的索引保存方式,使用了二叉树原理,二叉树是按照一定的规律进行排列的,所以范围查找速度较快。
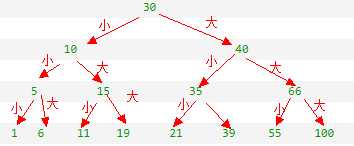
5.3 索引的分类:
1.主键索引:不能为空+不能重复,加速查找,一个表只能有一个主键索引
2.普通索引: 没有约束,加速查找
3.唯一索引: 可以为空,不能重复,加速查找
4.联合索引( 专门用于组合搜索,其效率大于索引合并):
联合唯一索引
联合普通索引
联合主键索引
5.全文索引:对文本的内容进行分词,进行搜索 (一般使用第三方工具来进行索引,不使用全文索引)
名词补充:
索引合并,使用多个单列索引组合搜索
覆盖索引,select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖.
5.4 有索引和无索引查询速度比较
使用索引:
mysql> select * from index_pra where id=66666;
+-------+-----------+---------------+--------+
| id | name | email | gender |
+-------+-----------+---------------+--------+
| 66666 | alex66595 | [email protected] | woman |
+-------+-----------+---------------+--------+
1 row in set (0.00 sec)
不使用索引
mysql> select * from index_pra where name=‘alex66666‘;
+-------+-----------+---------------+--------+
| id | name | email | gender |
+-------+-----------+---------------+--------+
|66737 | alex66666 | [email protected] | woman |
+-------+-----------+---------------+--------+
1 row in set (5.56 sec)
5.5 各索引的创建,修改,删除
5.5.1 普通索引
普通索引只有加速查找的作用,不对数据进行约束。
create table in1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, index ix_name (name) #index 索引名 列名(可以多列) )
create index index_name on table_name(column_name)
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
show index from table_name; mysql> show keys from index_pra; +-----------+------------+--------------+--------------+-------------+---------- -+-------------+----------+--------+------+------------+---------+-------------- -+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-----------+------------+--------------+--------------+-------------+---------- -+-------------+----------+--------+------+------------+---------+-------------- -+ | index_pra | 0 | PRIMARY | 1 | id | A | 676725 | NULL | NULL | | BTREE | | | | index_pra | 1 | index_pra_ix | 1 | name | A | 699559 | NULL | NULL | YES | BTREE | | | | index_pra | 1 | index_pra_ix | 2 | email | A | 699559 | NULL | NULL | YES | BTREE | | | +-----------+------------+--------------+--------------+-------------+---------- -+-------------+----------+--------+------+------------+---------+-------------- -+ 3 rows in set (0.00 sec)
注意:对于创建索引时如果是BLOB 和 TEXT 类型,必须指定length。
create index ix_extra on in1(extra(32));
5.5.2 唯一索引
约束:不能重复,可以为空。有加速查找作用
CREATE TABLE employ( id int auto_increment PRIMARY KEY, name char(20), pc_id int, UNIQUE uq_hostinfo_employ (pc_id) );
create unique index 索引名 on 表名(列名)
drop unique index 索引名 on 表名;
如果命令报错,可以使用:
drop index 索引名 on 表名;
5.5.3 主键索引
约束:不能重复,不能为空,有加速查找作用
create table in1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, index ix_name (name) ) OR create table in1( nid int not null auto_increment, name varchar(32) not null, email varchar(64) not null, extra text, primary key(ni1), index ix_name (name) ) 创建表 + 创建主键
alter table 表名 add primary key(列名);
1.当主键没有自增时: alter table 表名 drop primary key; alter table 表名 modify 列名 int, drop primary key; 2、当主键由自增时,需要先删自增,再删除主键 Alter table tb change id id int(10);//删除自增长 Alter table tb drop primary key;//删除主建
5.5.4 组合索引
组合索引是将n个列组合成一个索引
其应用场景为:频繁的同时使用n列来进行查询,如:where username = ‘root‘ and passwd = ‘123456‘。
create table in3( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text )
create index ix_name_email on in3(name,email);
组合索引查询时,遵循最左前缀匹配原则。
如上创建组合索引之后,查询:
name and email -- 使用索引 #name为最左边索引
name -- 使用索引
email -- 不使用索引
注意:对于同时搜索n个条件时,组合索引的性能好于多个单一索引合并。
5.6 索引命中
索引可以加快查询速度,但是我们需要避免索引未命中的行为,导致无法利用到索引加速。常见的错误用法如下:
-like ‘%xx‘ select * from tb1 where name like ‘%cn‘; - 使用函数 select * from tb1 where reverse(name) = ‘wupeiqi‘; - or select * from tb1 where nid = 1 or email = ‘[email protected]‘; #nid为索引,email不为索引 特别的:当or条件中有未建立索引的列才失效,以下会走索引 select * from tb1 where nid = 1 or name = ‘seven‘; #nid和name都是索引 select * from tb1 where nid = 1 or email = ‘[email protected]‘ and name = ‘alex‘; #and会使用有索引的那列 - 类型不一致 如果列是字符串类型,传入条件是必须用引号引起来,主键除外 select * from tb1 where name = 999; - != select * from tb1 where name != ‘alex‘ 特别的:如果是主键,则还是会走索引 select * from tb1 where nid != 123 - > select * from tb1 where name > ‘alex‘ 特别的:如果是主键或索引是整数类型,则还是会走索引 select * from tb1 where nid > 123 select * from tb1 where num > 123 - order by select email from tb1 order by name desc; 当根据索引排序时候,选择的映射如果不是索引,则不走索引 特别的:如果对主键排序,则还是走索引: select * from tb1 order by nid desc; - 组合索引最左前缀 如果组合索引为:(name,email) name and email -- 使用索引 name -- 使用索引 email -- 不使用索引
5.7 其他注意点
- 避免使用select * --效率低 - count(1)或count(列) 代替 count(*) --报错 - 创建表时尽量时 char 代替 varchar --char固定长度,检索速度快 - 表的字段顺序固定长度的字段优先 - 组合索引代替多个单列索引(经常使用多个条件查询时) --组合索引效率更高 - 尽量使用短索引 --如数据后面都一样,则可以使用局部索引 create index index_eg on tb(titile(16));
指定titile前十六个字符做索引
- 使用连接(JOIN)来代替子查询(Sub-Queries) --mysql现在版本速度差不多 - 连表时注意条件类型需一致 --类型不一致也可以连表 - 索引散列值(重复少)不适合建索引,例:性别不适合
5.8 分页
每页显示十条,一共有100万条数据,如何解决分页问题: 解决方案: 1.不让看很后面的数据 2.索引表中扫描 select * from userinfo3 where id in(select id from userinfo3 limit 200000,10) 缺点: select id from userinfo3 limit 200000,10; 需要从头扫到截取的位置,数据越后面导致耗时越久,效率低。 3.正确方案: 记录当前页最大或最小ID 3.1. 页面只有上一页,下一页 # max_id # min_id 下一页: select * from userinfo3 where id > max_id limit 10; 上一页: select * from userinfo3 where id < min_id order by id desc limit 10; 3.2. 上一页 192 193 [196] 197 198 199 下一页 select * from userinfo3 where id in (select id from (select id from userinfo3 where id > max_id limit 30) as N order by N.id desc limit 10) 补充: 1.为什么不用between .. and .. 因为id不一定是连续的,用between会导致页面显示不完整 。
5.9 执行计划
执行计划可以评估下sql的执行时间,用来比较sql语句是否比较优。虽然执行计划并不是百分百可以对比sql优化程度,但是大部分情况下都适用。
命令:
explain + 查询SQL - 用于显示SQL执行信息参数,根据参考信息可以进行SQL优化
查询顺序标识 如:mysql> explain select * from (select nid,name from tb1 where nid < 10) as B; +----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+ | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 9 | NULL | | 2 | DERIVED | tb1 | range | PRIMARY | PRIMARY | 8 | NULL | 9 | Using where | +----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+ 特别的:如果使用union连接气值可能为null select_type 查询类型 SIMPLE 简单查询 PRIMARY 最外层查询 SUBQUERY 映射为子查询 DERIVED 子查询 UNION 联合 UNION RESULT 使用联合的结果 ... table 正在访问的表名 type 查询时的访问方式,性能:all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const ALL 全表扫描,对于数据表从头到尾找一遍 select * from tb1; 特别的:如果有limit限制,则找到之后就不在继续向下扫描 select * from tb1 where email = ‘[email protected]‘ select * from tb1 where email = ‘[email protected]‘ limit 1; 虽然上述两个语句都会进行全表扫描,第二句使用了limit,则找到一个后就不再继续扫描。 INDEX 全索引扫描,对索引从头到尾找一遍 select nid from tb1; RANGE 对索引列进行范围查找 select * from tb1 where name < ‘alex‘; PS: between and in > >= < <= 操作 注意:!= 和 > 符号 INDEX_MERGE 合并索引,使用多个单列索引搜索 select * from tb1 where name = ‘alex‘ or nid in (11,22,33); REF 根据索引查找一个或多个值。 select * from tb1 where name = ‘seven‘; EQ_REF 连接时使用primary key 或 unique类型 select tb2.nid,tb1.name from tb2 left join tb1 on tb2.nid = tb1.nid; CONST 常量 表最多有一个匹配行,因为仅有一行,在这行的列值可被优化器剩余部分认为是常数,const表很快,因为它们只读取一次。 select nid from tb1 where nid = 2 ; SYSTEM 系统(覆盖索引) 表仅有一行(=系统表)。这是const联接类型的一个特例。 select * from (select nid from tb1 where nid = 1) as A; possible_keys 可能使用的索引 key 真实使用的 key_len MySQL中使用索引字节长度 rows mysql估计为了找到所需的行而要读取的行数 ------ 只是预估值 extra 该列包含MySQL解决查询的详细信息 “Using index” 此值表示mysql将使用覆盖索引,以避免访问表。不要把覆盖索引和index访问类型弄混了。 “Using where” 这意味着mysql服务器将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。有时“Using where”的出现就是一个暗示:查询可受益于不同的索引。 “Using temporary” 这意味着mysql在对查询结果排序时会使用一个临时表。 “Using filesort” 这意味着mysql会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成。 “Range checked for each record(index map: N)” 这个意味着没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的。
5.10 慢日志
DBA可以开启慢日志,看哪些sql语句查询比较慢,是否命中索引
查看慢日志配置: show variables like ‘%query%‘; +------------------------------+-----------------------------------------+ | Variable_name | Value | +------------------------------+-----------------------------------------+ | slow_query_log | ON | | slow_query_log_file | E:\\mysql-5.7.17-winx64\\data\\my_slow.log | +------------------------------+-----------------------------------------+ 参数说明: slow_query_log 是否开启慢日志 slow_query_log_file 慢日志保存文件路径 查看慢日志设置阈值 show variables like ‘%queries%‘; +----------------------------------------+-------+ | Variable_name | Value | +----------------------------------------+-------+ | long_query_time | 0.200000 | | log_queries_not_using_indexes | ON | | log_throttle_queries_not_using_indexes | 2 | +----------------------------------------+-------+ 参数说明: long_query_time 查询时间超时该阈值则记录,单位为 s log_queries_not_using_indexes 是否记录没有使用索引的sql log_throttle_queries_not_using_indexes 用来表示每分钟允许记录到slow log的且未使用索引的SQL语句次数。该值默认为0,表示没有限制
session级别修改配置参数
set global 变量名 = 值
修改配置文件
mysqld --defaults-file=‘E:\\wupeiqi\\mysql-5.7.16-winx64\\mysql-5.7.16-winx64\\my-default.ini‘ my.conf内容: slow_query_log = ON slow_query_log_file = D:/.... ... 注意:修改配置文件之后,需要重启服务
查看慢日志
mysqldumpslow -s at -a /usr/local/var/mysql/MacBook-Pro-3-slow.log
""" --verbose 版本 --debug 调试 --help 帮助 -v 版本 -d 调试模式 -s ORDER 排序方式 what to sort by (al, at, ar, c, l, r, t), ‘at‘ is default al: average lock time ar: average rows sent at: average query time c: count l: lock time r: rows sent t: query time -r 反转顺序,默认文件倒序拍。reverse the sort order (largest last instead of first) -t NUM 显示前N条just show the top n queries -a 不要将SQL中数字转换成N,字符串转换成S。don‘t abstract all numbers to N and strings to ‘S‘ -n NUM abstract numbers with at least n digits within names -g PATTERN 正则匹配;grep: only consider stmts that include this string -h HOSTNAME mysql机器名或者IP;hostname of db server for *-slow.log filename (can be wildcard), default is ‘*‘, i.e. match all -i NAME name of server instance (if using mysql.server startup script) -l 总时间中不减去锁定时间;don‘t subtract lock time from total time """
以上是关于python之路-----MySql操作三的主要内容,如果未能解决你的问题,请参考以下文章