python爬虫之初始Selenium
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫之初始Selenium相关的知识,希望对你有一定的参考价值。
1、初始
Selenium[1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
2、使用方法
案例:
需求:
公司购买了一一批优科无线AP,本人刚涉足python爬虫行业,需要实现的功能就是,对好几十台优科无线AP进行定时重启。原来做过TP-LINK941n的无线路由器定时重启,按照原来的思路进行寻找方法-------抓包。通过抓取重启路由器的链接,对无线路由器进行定时重启(定时的事情就交给操作系统自带的任务计划)。然后就开始了抓包操作,然而最终还是以失败告终---也许因为我对抓包工具不太熟练。但是功能还是要必须实现,偶然听到朋友们之前提起的selenium可以模仿人的操作,进行爬虫操作。所以我就开始了对selenium的研究。
1、路由器的登录界面
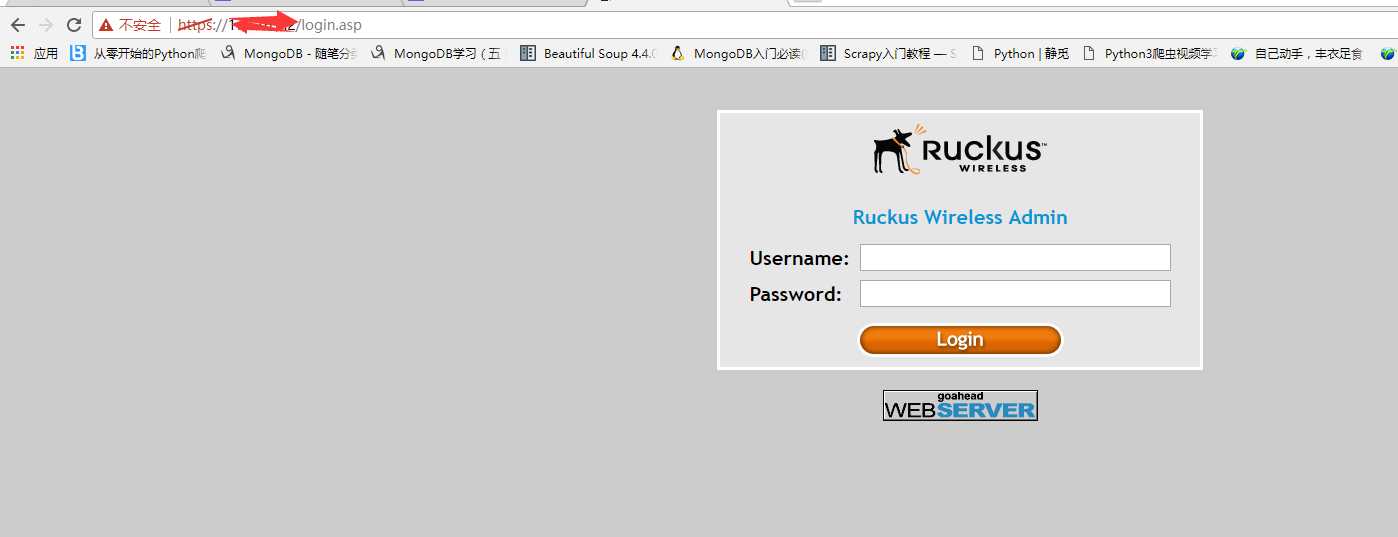
2、首先环境准备。
python3.5.2
pip9.0.1
pip3 install selenium
最新版谷歌浏览器(FQ升级的事情就不再熬述)
最新版的webdriver(http://chromedriver.storage.googleapis.com/index.html)
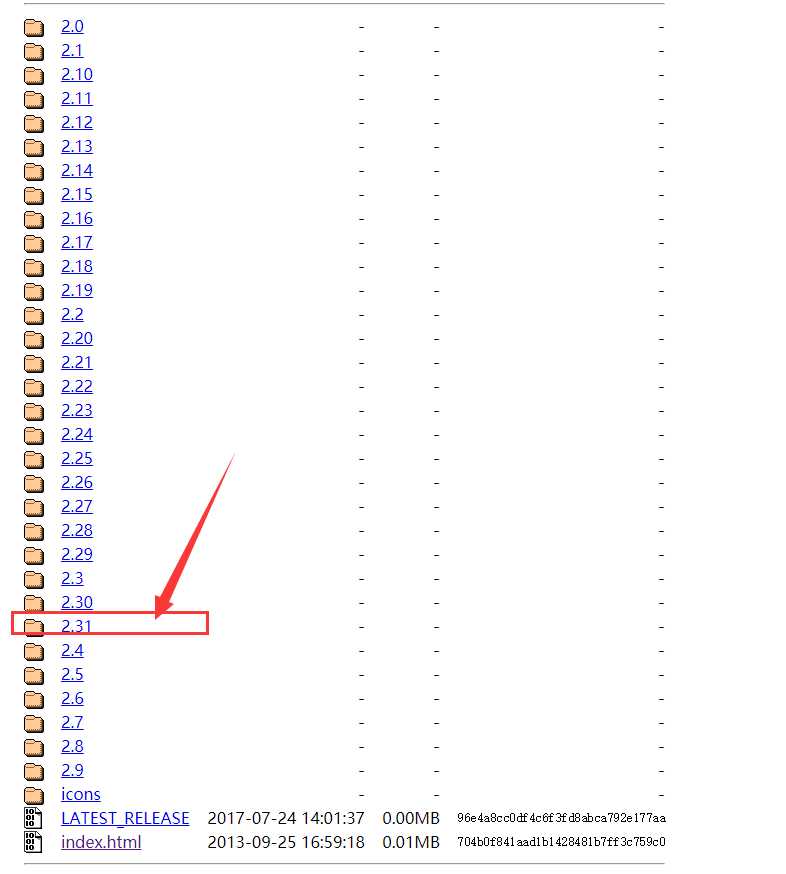
注意:3.31才是最新版,可以打开文件夹进去看驱动的具体时间。
谷歌浏览器需要加上环境变量,将驱动文件放到谷歌浏览器的安装路径下面。
3、首先进行用户名和密码登录
导入模块
from selenium import webdriver
让程序打开浏览器,当然你也可以用其它浏览器,我在这里使用的是谷歌浏览器。
browser = webdriver.Chrome()
4、找到输入用户名和密码的地方。
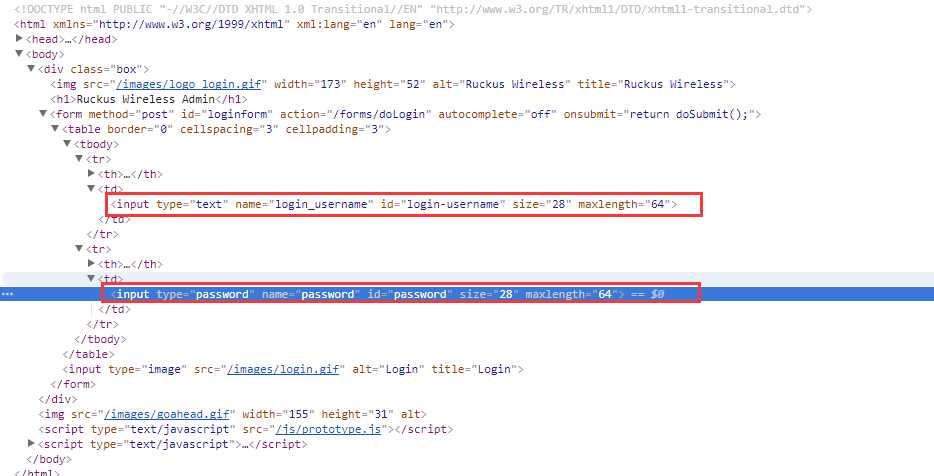
5、复制这个标签的selector和XPath路径,哪个都可以的。在这里我用的是xpath。
# 获取用户名输入框 login_name = browser.find_element_by_xpath(‘//*[@id="login-username"]‘) # 获取输入密码的输入框 login_pwd = browser.find_elements_by_xpath(‘//*[@id="password"]‘)[0] #获取登录的按钮 button = browser.find_elements_by_xpath(‘//*[@id="loginform"]/input‘)[0]
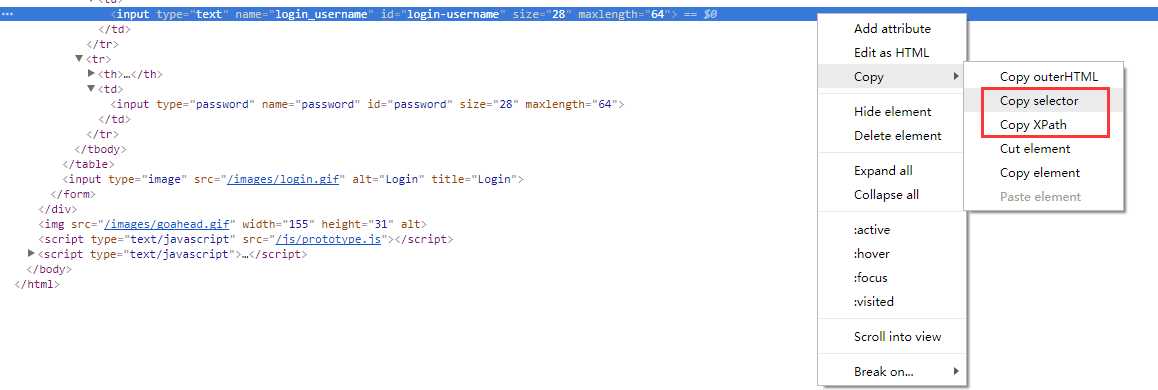
6、拿到用户名和密码和点击登录的按钮,后我们需要给用户名和密码赋值和点击登录的按钮
#在输入用户名的位置输入用户名 login_name.send_keys(‘super‘) #在输入密码的输入框输入密码 login_pwd.send_keys(‘gaosiedu.com‘) #点击登录按钮 button.click()
7、登录成功后我们发现一个问题,无线AP后台页面用的是frame标签(涉及到了各种切,不过不要头疼看下面)
A是左边菜单栏,B是右边的内容栏,我们首先得进去A里面找到左边的点击重启的按钮,然后在切出来,再进去B的frame标签切进去拿到重启的按钮,点击操作。
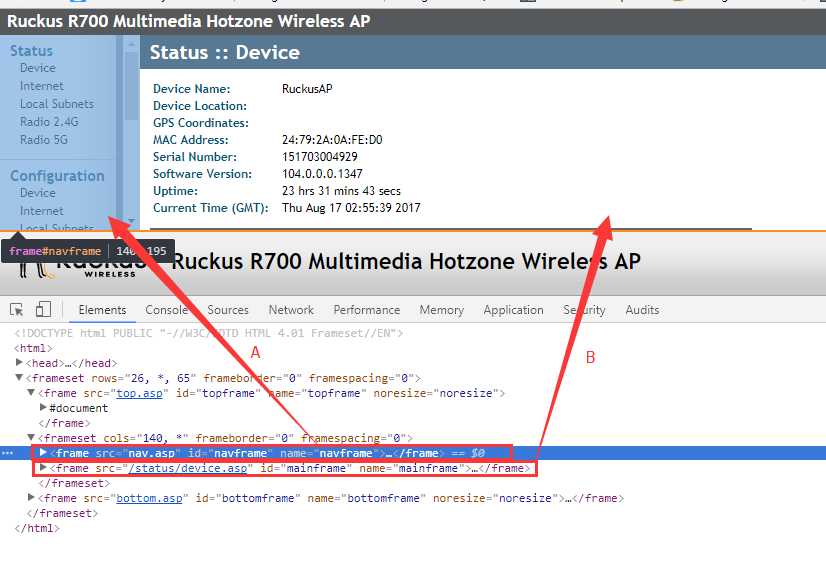
#找到第一个frame标签(左侧栏)
browser.switch_to.frame("navframe")
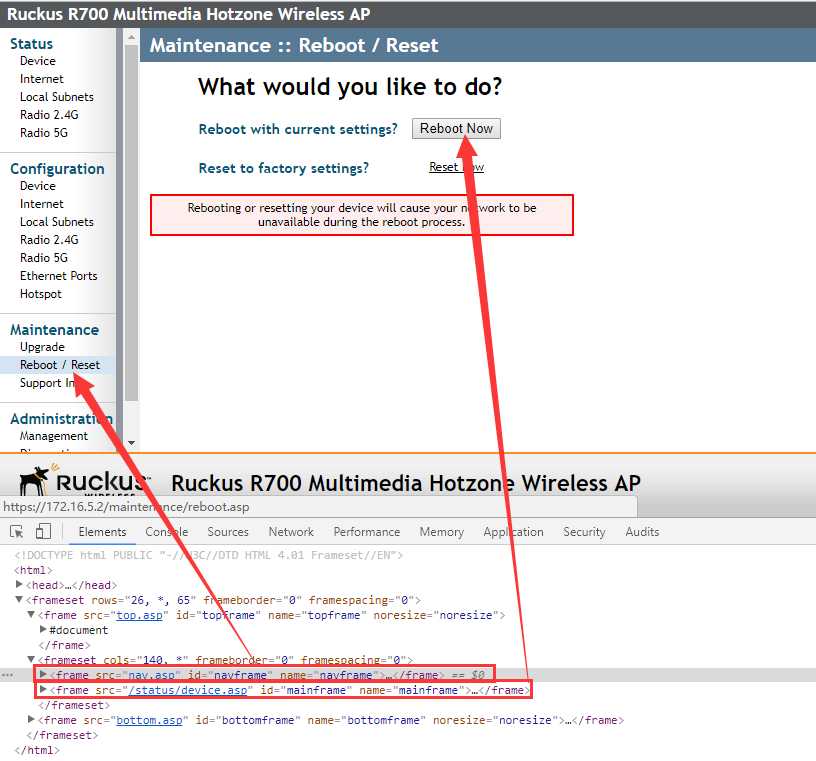
#切换进去,执行Reboot Now这个按钮,
reboot_bo = browser.find_element_by_xpath(‘/html/body/dl[3]/dd/ul/li[2]/a‘)
#执行操作,得到右边Reboot Now的重启按钮
reboot_bo.click()
#跳出当前的frame标签
browser.switch_to.default_content()
#找到执行完后右边的frame标签
browser.switch_to.frame(‘mainframe‘)
#进入标签后找到重启的按钮
reboot_boot = browser.find_element_by_xpath(‘//*[@id="adminform"]/table/tbody/tr[1]/td/input[2]‘)
#执行重启的操作
reboot_boot.click()
8、大功告成,如果有60台无线AP的话还需要优化的地方很多。完整代码如下


from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait import time import threading import os browser = webdriver.Chrome() #加载ip列表 def Ip(): with open(‘ip_list.txt‘,‘r‘) as file: for ip in file.readlines(): ip = ip.strip() reboot_spiders(ip) #重启方法 def reboot_spiders(arg): if len(arg) > 0: try: browser.get("https://" + arg + "/login.asp") # 获取用户名输入框 login_name = browser.find_element_by_xpath(‘//*[@id="login-username"]‘) # 获取输入密码的输入框 login_pwd = browser.find_elements_by_xpath(‘//*[@id="password"]‘)[0] #获取登录的按钮 button = browser.find_elements_by_xpath(‘//*[@id="loginform"]/input‘)[0] time.sleep(2) #在输入用户名的位置输入用户名 login_name.send_keys(‘super‘) #在输入密码的输入框输入密码 login_pwd.send_keys(‘gaosiedu.com‘) #点击登录按钮 button.click() #停2秒 time.sleep(2) #分析已经登录的页面 #登录成功,开始分析页面! #找到第一个frame标签(左侧栏) browser.switch_to.frame("navframe") #切换进去,执行Reboot Now这个按钮, reboot_bo = browser.find_element_by_xpath(‘/html/body/dl[3]/dd/ul/li[2]/a‘) #执行操作,得到右边Reboot Now的重启按钮 reboot_bo.click() #跳出当前的frame标签 browser.switch_to.default_content() #找到执行完后右边的frame标签 browser.switch_to.frame(‘mainframe‘) #进入标签后找到重启的按钮 reboot_boot = browser.find_element_by_xpath(‘//*[@id="adminform"]/table/tbody/tr[1]/td/input[2]‘) #执行重启的操作 reboot_boot.click() #关闭浏览器 time.sleep(2) #生成重启成功日志 timee = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) s_log = "时间 %s ip地址[%s]重启成功" %(timee,arg) #写入文件 Success(s_log) except Exception as e: #生成失败错误日志 timeee = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) r_log = "时间 %s ip地址[%s]重启失败" %(timeee,arg) #写入文件 Error(r_log) pass else: pass #错误日志 def Error(args): with open(‘error.txt‘,‘a+‘,encoding=‘utf-8‘) as file: file.write(‘\\n%s‘%args) file.close() #成功日志 def Success(args): with open(‘success.txt‘,‘a+‘,encoding=‘utf-8‘) as file: file.write(‘\\n%s‘%args) file.close() if __name__ == ‘__main__‘: t1 = threading.Thread(target=Ip(),args=(),) t1.start() browser.quit()
1、建立ip_list.txt文件,把ip地址如下面写进去。 172.16.5.2 172.16.5.1 172.16.5.5 172.16.5.50 172.16.5.51 2、本脚本提供了成功日志和错误日志 3、如果上线windows任务计划还需要有多地方需要注意,如有需要可以发邮件给我[email protected]。
Selenium操作:
详细操作可以看我的好朋友凡哥的博客,这里我就不再重述。
http://www.pythonsite.com/?p=188
以上是关于python爬虫之初始Selenium的主要内容,如果未能解决你的问题,请参考以下文章
爬虫之动态HTML处理(Selenium与PhantomJS )动态页面模拟点击