Python爬虫之selenium的使用
Posted -零
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之selenium的使用相关的知识,希望对你有一定的参考价值。
Python爬虫之selenium的使用
一、简介
二、安装
三、使用
一、简介
Selenium 是自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试。Selenium 支持这些浏览器驱动。Selenium支持多种语言开发,比如 Python,Java,C,Ruby等等。
二、安装
1.安装selenium
pip3 install selenium
2.配置驱动 (下载驱动,然后将驱动文件路径配置在环境变量)
驱动下载地址:https://sites.google.com/a/chromium.org/chromedriver/downloads
注意:你下载的驱动要和你浏览器版本能够兼容才能使用。
三、使用
1.声明浏览器对象
from selenium import webdriver browser = webdriver.Chrome() browser = webdriver.Firefox() browser = webdriver.Edge() browser = webdriver.Phantom() browser = webdriver.FirefoxJS() browser = webdriver.Safari()
2.访问页面
from selenium import webdriver
broswer = webdriver.Chrome()
#访问淘宝页面 broswer.get(\'https://www.taobao.com\')
#获取页面源代码 print(broswer.page_source)
#关闭 broswer.close()
3.查找单个元素
from selenium import webdriver # 启动配置 option = webdriver.ChromeOptions() option.add_argument(\'disable-infobars\') # 打开chrome浏览器 broswer = webdriver.Chrome() broswer.get(\'https://www.taobao.com\')
#下面三种方法都是获取同一元素 input1 = broswer.find_element_by_id(\'q\') input2 = broswer.find_element_by_css_selector(\'#q\') input3 = broswer.find_element_by_xpath(\'//*[@id="q"]\') print(input1,input2,input3) broswer.close()
运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="b26040f3a0b3810381abd8f13e513095", element="0.3260737871611288-1")> <selenium.webdriver.remote.webelement.WebElement (session="b26040f3a0b3810381abd8f13e513095", element="0.3260737871611288-1")> <selenium.webdriver.remote.webelement.WebElement (session="b26040f3a0b3810381abd8f13e513095", element="0.3260737871611288-1")>
全部获取单个元素的方法:
find_element_by_id() find_element_by_name() find_element_by_xpath() find_element_by_link_test() find_element_by_tag_name() find_element_by_class_name() find_element_by_css_selector() find_element_by_partial_link_test()
4.查找多个元素
from selenium import webdriver # 加启动配置 option = webdriver.ChromeOptions() option.add_argument(\'disable-infobars\') # 打开chrome浏览器 broswer = webdriver.Chrome() broswer.get(\'https://www.taobao.com\') input2 = broswer.find_elements_by_css_selector(\'#q\')
print(input2)
broswer.close()
运行结果如下:
[<selenium.webdriver.remote.webelement.WebElement (session="0c6d5918fff4982403777d89fd64b6bd", element="0.9184632404888653-1")>]
全部获取多个元素的方法:
find_elements_by_id() find_elements_by_name() find_elements_by_xpath() find_elements_by_link_test() find_elements_by_tag_name() find_elements_by_class_name() find_elements_by_css_selector() find_elements_by_partial_link_test()
5.添加User-Agent
使用webdriver,是可以更改User-Agent的,代码如下:
from selenium import webdriver options = webdriver.ChromeOptions() options.add_argument(\'user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"\') driver = webdriver.Chrome(chrome_options=options) driver.get(\'https://www.baidu.com/\')
6.自动化测试的时候,启动浏览器出现‘Chrome正在受到自动软件的控制’,可以隐藏
在浏览器配置里加个参数,忽略掉这个警告提示语,disable_infobars
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument(\'disable-infobars\')
driver = webdriver.Chrome(chrome_options=option)
driver.get(\'https://www.baidu.com/\')
7.启动浏览器的时候不想看的浏览器运行,那就加载浏览器的静默模式,让它在后台偷偷运行。用headless
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument(\'headless\')
driver = webdriver.Chrome(chrome_options=option)
driver.get(\'https://www.baidu.com/\')
8.获取元素信息
# 获取属性 from selenium import webdriver broswer = webdriver.Chrome() url = \'https://www.taobao.com\' broswer.get(url) logo = broswer.find_element_by_class_name(\'logo\') print(logo) print(logo.get_attribute(\'class\'))
# 获取文本值 from selenium import webdriver broswer = webdriver.Chrome() url = \'https://www.taobao.com\' broswer.get(url) li = broswer.find_element_by_class_name(\'J_SearchTab\') print(li) print(li.text)
#获取ID、位置、标签名、大小 from selenium import webdriver broswer = webdriver.Chrome() url = \'https://www.taobao.com\' broswer.get(url) logo = broswer.find_element_by_class_name(\'logo\') print(logo.id) print(logo.location) print(logo.tag_name) print(logo.size)
9.交互操作
元素交互操作(先获取特定的元素,对获取的元素调用交互方法)
from selenium import webdriver
import time # 加启动配置 option = webdriver.ChromeOptions() option.add_argument(\'disable-infobars\') # 打开chrome浏览器 broswer = webdriver.Chrome() broswer.get(\'https://www.taobao.com\')
#获取输入框 input =broswer.find_element_by_id(\'q\')
#模拟用户输入iphone input.send_keys(\'iphone\')
time.sleep(2)
#清除输入框 input.clear()
#输入ipad input.send_keys(\'ipad\')
#获取按钮 button = broswer.find_element_by_class_name(\'btn-search\')
#点击按钮
button.click()
更多元素交互操作:http://selenium-python.readthedocs.org/locating-elements.html
交互动作(将动作附加到动作链中串行执行)
执行JavaScript代码
from selenium import webdriver
broswer = webdriver.Chrome()
broswer.get(\'https://www.zhihu.com\')
broswer.execute_script(\'window.scrollTo(0,document.body.scrollHeight)\')
broswer.execute_script(\'alert("To Bottom")\')
鼠标操作
在现实的自动化测试中关于鼠标的操作不仅仅是click()单击操作,还有很多包含在ActionChains类中的操作。如下:
- context_click(elem) 右击鼠标点击元素elem,另存为等行为
- double_click(elem) 双击鼠标点击元素elem,地图web可实现放大功能
- drag_and_drop(source,target) 拖动鼠标,源元素按下左键移动至目标元素释放
- move_to_element(elem) 鼠标移动到一个元素上
- click_and_hold(elem) 按下鼠标左键在一个元素上
- perform() 在通过调用该函数执行ActionChains中存储行为
举例如下图所示,获取通过鼠标右键另存为百度图片logo。代码:

键盘操作
参考:http://selenium-python.readthedocs.org/api.html
前面讲述了鼠标操作,现在讲述键盘操作。在webdriver的Keys类中提供了键盘所有的按键操作,当然也包括一些常见的组合键操作如Ctrl+A(全选)、Ctrl+C(复制)、Ctrl+V(粘贴)。更多键参考官方文档对应的编码。
- send_keys(Keys.ENTER) 按下回车键
- send_keys(Keys.TAB) 按下Tab制表键
- send_keys(Keys.SPACE) 按下空格键space
- send_keys(Kyes.ESCAPE) 按下回退键Esc
- send_keys(Keys.BACK_SPACE) 按下删除键BackSpace
- send_keys(Keys.SHIFT) 按下shift键
- send_keys(Keys.CONTROL) 按下Ctrl键
- send_keys(Keys.ARROW_DOWN) 按下鼠标光标向下按键
- send_keys(Keys.CONTROL,\'a\') 组合键全选Ctrl+A
- send_keys(Keys.CONTROL,\'c\') 组合键复制Ctrl+C
- send_keys(Keys.CONTROL,\'x\') 组合键剪切Ctrl+X
- send_keys(Keys.CONTROL,\'v\') 组合键粘贴Ctrl+V
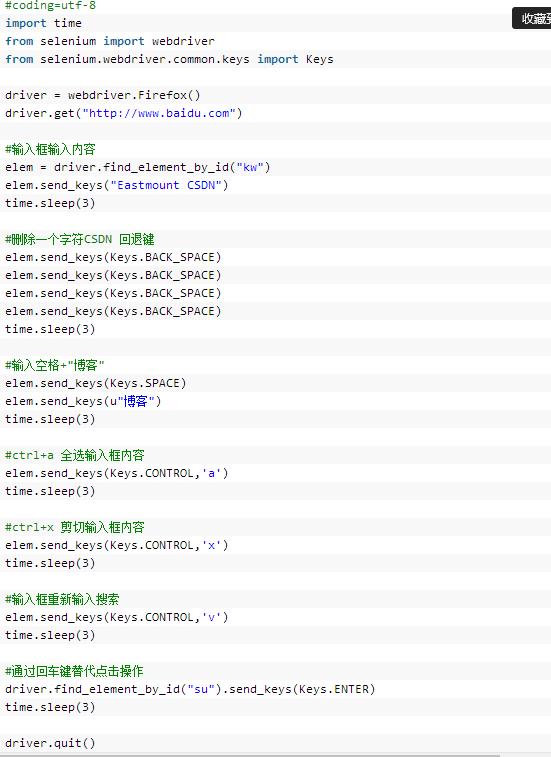
10.前进后退页面
import time from selenium import webdriver broswer = webdriver.Chrome() broswer.get(\'https://www.baidu.com\') broswer.get(\'https://www.taobao.com\')
#后退 broswer.back() time.sleep(2)
#前进 broswer.forward() broswer.close()
11.Cookies操作
添加Cookie
from selenium import webdriver broswer = webdriver.Chrome() broswer.get(\'https://www.zhihu.com\') # Now set the cookie. This one\'s valid for the entire domain cookie = {\'name\' : \'foo\', \'value\' : \'bar\'} broswer.add_cookie(cookie)
获取Cookies
from selenium import webdriver broswer = webdriver.Chrome() broswer.get(\'https://www.zhihu.com\')
#获取cookie print(broswer.get_cookies())
#添加cookie broswer.add_cookie({\'name\':\'name\',\'value\':\'germeny\'})
#再次获取cookie print(broswer.get_cookies())
12.选项卡操作
import time from selenium import webdriver broswer = webdriver.Chrome() broswer.get(\'https://www.zhihu.com\')
#打开新窗口 broswer.execute_script(\'window.open()\') print(broswer.window_handles)
#切断到第二个选项卡(窗口) broswer.switch_to_window(broswer.window_handles[1]) time.sleep(1)
#切换到第一个选项卡(窗口) broswer.switch_to_window(broswer.window_handles[0]) broswer.get(\'https://www.baidu.com\')
以上是关于Python爬虫之selenium的使用的主要内容,如果未能解决你的问题,请参考以下文章