Python爬虫与反爬虫大战
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫与反爬虫大战相关的知识,希望对你有一定的参考价值。
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家?
重新理解爬虫中的一些概念
爬虫:自动获取网站数据的程序
反爬虫:使用技术手段防止爬虫程序爬取数据
误伤:反爬虫技术将普通用户识别为爬虫,这种情况多出现在封ip中,例如学校网络、小区网络再或者网络网络都是共享一个公共ip,这个时候如果是封ip就会导致很多正常访问的用户也无法获取到数据。所以相对来说封ip的策略不是特别好,通常都是禁止某ip一段时间访问。
成本:反爬虫也是需要人力和机器成本
拦截:成功拦截爬虫,一般拦截率越高,误伤率也就越高
反爬虫的目的
初学者写的爬虫:简单粗暴,不管对端服务器的压力,甚至会把网站爬挂掉了
数据保护:很多的数据对某些公司网站来说是比较重要的不希望被别人爬取
商业竞争问题:这里举个例子是关于京东和天猫,假如京东内部通过程序爬取天猫所有的商品信息,从而做对应策略这样对天猫来说就造成了非常大的竞争
爬虫与反爬虫大战
上有政策下有对策,下面整理了常见的爬虫大战策略
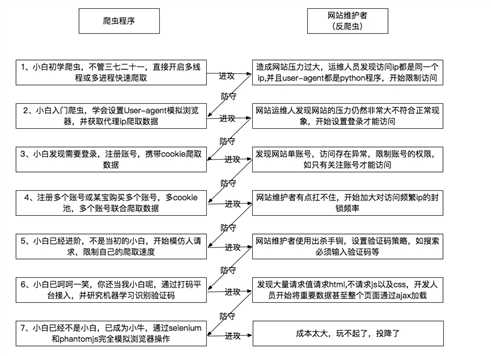
以上是关于Python爬虫与反爬虫大战的主要内容,如果未能解决你的问题,请参考以下文章