如何快速掌握Python数据采集与网络爬虫技术
Posted 天善大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何快速掌握Python数据采集与网络爬虫技术相关的知识,希望对你有一定的参考价值。
点击上图开始学习韦玮老师最新网络爬虫课程
畅销书《精通Python网络爬虫》作者,阿里云社区技术专家
本文详细讲解了python网络爬虫基础入门,并介绍抓包分析等技术,实战训练三个网络爬虫案例,并简单补充了常见的反爬策略与反爬攻克手段。通过本文的学习,可以快速掌握网络爬虫基础,结合实战练习,写出一些简单的爬虫项目。
本次的分享主要围绕以下五个方面:
一、数据采集与网络爬虫技术简介
二、网络爬虫技术入门
三、抓包分析
四、挑战案例
五、推荐博文
一、数据采集与网络爬虫技术简介
网络爬虫是用于数据采集的一门技术,可以帮助我们自动地进行信息的获取与筛选。
从技术手段来说,网络爬虫有多种实现方案,如php、Java、Python ...。那么用python 也
会有很多不同的技术方案(Urllib、requests、scrapy、selenium...),每种技术各有各的特点,只需掌握一种技术,其它便迎刃而解。同理,某一种技术解决不了的难题,用其它技术或方依然无法解决。网络爬虫的难点并不在于网络爬虫本身,而在于网页的分析与爬虫的反爬攻克问题。希望在本次课程中大家可以领会爬虫中相对比较精髓的内容。
二、网络爬虫技术入门
在本次课中,将使用Urllib技术手段进行项目的编写。同样,掌握了该技术手段,其他的技术手段也不难掌握,因为爬虫的难点不在于技术手段本身。
本知识点包括如下内容:
·Urllib基础
·浏览器伪装
·用户代理池
·糗事百科爬虫实战
需要提前具备的基础知识:正则表达式
1)Urllib基础
爬网页
打开python命令行界面,两种方法:ulropen()爬到内存,urlretrieve()爬到硬盘文件。
>>> import urllib.request
#open百度,读取并爬到内存中,解码(ignore可忽略解码中的细微错误), 并赋值给data
>>> data=urllib.request.ulropen("http://www.baidu.com").read().decode("utf-8”, “ignore")
#判断网页内的数据是否存在,通过查看data长度
>>> len(data)
提取网页标题
#首先导入正则表达式, .*?代表任意信息,()代表要提取括号内的内容
>>> import re
#正则表达式
>>> pat="<title>(.*?)</title>"
#re.compile()指编译正则表达式
#re.S是模式修正符,网页信息往往包含多行内容,re.S可以消除多行影响
>>> rst=re.compile(pat,re.S).findall(data)
>>> print(rst)
[‘百度一下,你就知道’]
#同理,只需换掉网址可爬取另一个网页内容
>>> data=urllib.request.ulropen("http://www.jd.com").read().decode("utf-8", "ignore")
>>> rst=re.compile(pat,re.S).findall(data)
>>> print(rst)上面是将爬到的内容存在内存中,其实也可以存在硬盘文件中,使用urlretrieve()方法
>>> urllib.request.urlretrieve("http://www.jd.com",filename="D:/我的教学/Python/阿里云系列直播/第2次直播代码/test.html")之后可以打开test.html,京东网页就出来了。由于存在隐藏数据,有些数据信息和图片无法显示,可以使用抓包分析进行获取。
2)浏览器伪装
尝试用上面的方法去爬取糗事百科网站url="https://www.qiushibaike.com/",会返回拒绝访问的回复,但使用浏览器却可以正常打开。那么问题肯定是出在爬虫程序上,其原因在于爬虫发送的请求头所导致。
打开糗事百科页面,如下图,通过F12,找到headers,这里主要关注用户代理User-Agent字段。User-Agent代表是用什么工具访问糗事百科网站的。不同浏览器的User-Agent值是不同的。那么就可以在爬虫程序中,将其伪装成浏览器。
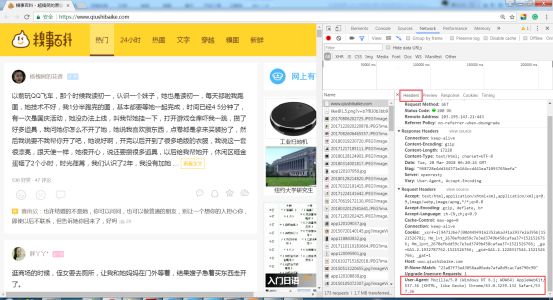
将User-Agent设置为浏览器中的值,虽然urlopen()不支持请求头的添加,但是可以利用opener进行addheaders,opener是支持高级功能的管理对象。代码如下:
#浏览器伪装
url="https://www.qiushibaike.com/"
#构建opener
opener=urllib.request.build_opener()
#User-Agent设置成浏览器的值
UA=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
#将UA添加到headers中
opener.addheaders=[UA]
urllib.request.install_opener(opener)
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")3)用户代理池
第一步,收集大量的用户代理User-Agent
#用户代理池
uapools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
第二步,建立函数UA(),用于切换用户代理User-Agent
def UA():
opener=urllib.request.build_opener()
#从用户代理池中随机选择一个
thisua=random.choice(uapools)
ua=("User-Agent",thisua)
opener.addheaders=[ua]
urllib.request.install_opener(opener)
print("当前使用UA:"+str(thisua))
for循环,每访问一次切换一次UA
for i in range(0,10):
UA()
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
每爬3次换一次UA
for i in range(0,10):
if(i%3==0):
UA()
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
(*每几次做某件事情,利用求余运算)
4)第一项练习-糗事百科爬虫实战
目标网站:https://www.qiushibaike.com/
需要把糗事百科中的热门段子爬取下来,包括翻页之后内容,该如何获取?
第一步,对网址进行分析,如下图所示,发现翻页之后变化的部分只是page后面的页面数字。

第二步,思考如何提取某个段子?查看网页代码,如下图所示,可以发现<div>的数量和每页段子数量相同,可以用<div>这个标识提取出每条段子信息。
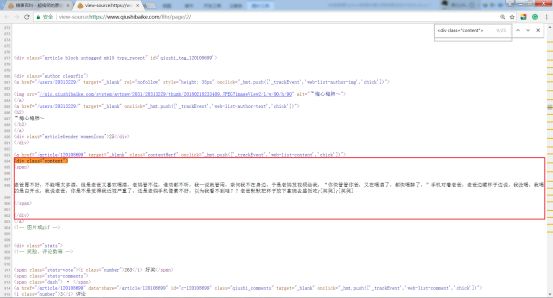
第三步,利用上面所提到的用户代理池进行爬取。首先建立用户代理池,从用户代理池中随机选择一项,设置UA。
import urllib.request
import re
import random
#用户代理池
uapools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
def UA():
opener=urllib.request.build_opener()
thisua=random.choice(uapools)
ua=("User-Agent",thisua)
opener.addheaders=[ua]
urllib.request.install_opener(opener)
print("当前使用UA:"+str(thisua))
for循环,爬取第1页到第36页的段子内容
for i in range(0,35):
UA()
#构造不同页码对应网址
thisurl="http://www.qiushibaike.com/8hr/page/"+str(i+1)+"/"
data=urllib.request.urlopen(thisurl).read().decode("utf-8","ignore")
#利用<div>提取段子内容
pat='<div>.*?<span>(.*?)</span>.*?</div>'
rst=re.compile(pat,re.S).findall(data)
for j in range(0,len(rst)):
print(rst[j])
print("-------")
还可以定时的爬取:
import time
然后在后面调用time.sleep()方法
换言之,学习爬虫需要灵活变通的思想,针对不同的情况,不同的约束而灵活运用。
三、抓包分析
抓包分析可以将网页中的访问细节信息取出。有时会发现直接爬网页时是无法获取到目标数据的,因为这些数据做了隐藏,此时可以使用抓包分析的手段进行分析,并获取隐藏数据。
1)Fiddler简介
抓包分析可以直接使用浏览器F12进行,也可以使用一些抓包工具进行,这里推荐Fiddler,具体配置方法可参考下面的博文:
简单配置:
https://weibo.com/ttarticle/p/show?id=2309404157790875745313&mod=zwenzhang
出现问题终极解决方案:https://weibo.com/ttarticle/p/show?id=2309404103263770292716&mod=zwenzhang
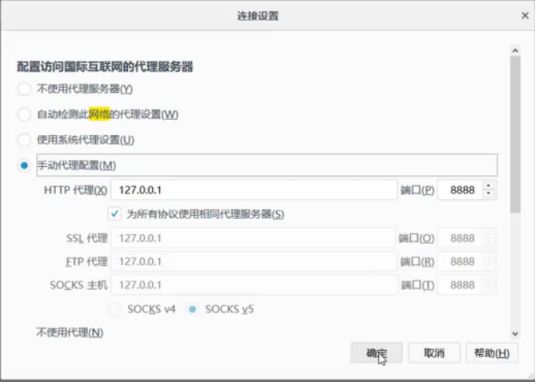
Fiddler下载安装。假设给Fiddler配合的是火狐浏览器,打开浏览器,如下图,找到连接设置,选择手动代理设置并确定。
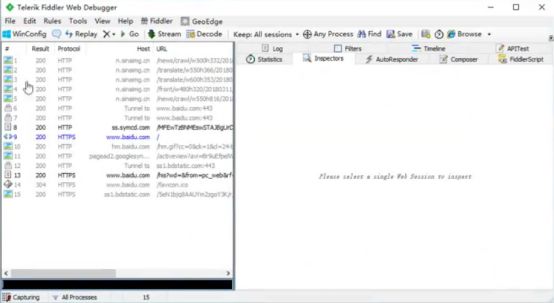
假设打开百度,如下图,加载的数据包信息就会在Fiddler中左侧列表中列出来,那么网站中隐藏相关的数据可以从加载的数据包中找到。
2)第二项练习-腾讯视频评论爬虫实战
目标网站:https://v.qq.com/
需要获取的数据:某部电影的评论数据,实现自动加载。
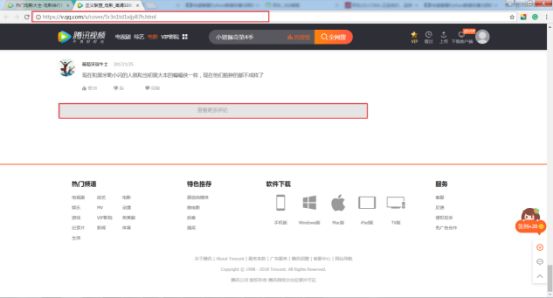
第一步,分析腾讯视频评论网址变化规律。点击”查看更多评论”,同时打开Fiddler,第一条信息的TextView中,TextView中可以看到对应的content内容是unicode编码,刚好对应的是某条评论的内容。
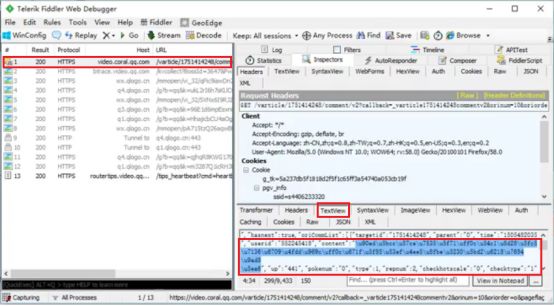
解码出来可以看到对应评论内容。
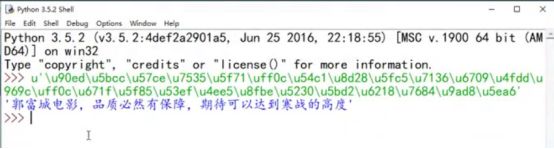
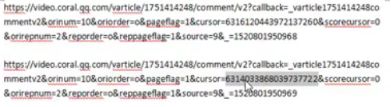
第二步,查找网址中变化的cursor字段值。从上面的第一条评论信息里寻找,发现恰好在last字段值与后一条评论的cursor值相同。即表示cursor的值是迭代方式生成的,每条评论的cursor信息在其上一条评论的数据包中寻找即可。
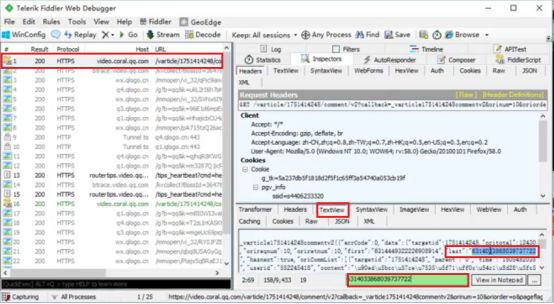
第三步,完整代码
a.腾讯视频评论爬虫:获取”深度解读”评论内容(单页评论爬虫)
#单页评论爬虫
import urllib.request
import re
#https://video.coral.qq.com/filmreviewr/c/upcomment/[视频id]?commentid=[评论id]&reqnum=[每次提取的评论的个数]
#视频id
vid="j6cgzhtkuonf6te"
#评论id
cid="6233603654052033588"
num="20"
#构造当前评论网址
url="https://video.coral.qq.com/filmreviewr/c/upcomment/"+vid+"?commentid="+cid+"&reqnum="+num
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Content-Type":"application/javascript",
}
opener=urllib.request.build_opener()
headall=[]
for key,value in headers.items():
item=(key,value)
headall.append(item)
opener.addheaders=headall
urllib.request.install_opener(opener)
#爬取当前评论页面
data=urllib.request.urlopen(url).read().decode("utf-8")
titlepat='"title":"(.*?)"'
commentpat='"content":"(.*?)"'
titleall=re.compile(titlepat,re.S).findall(data)
commentall=re.compile(commentpat,re.S).findall(data)
for i in range(0,len(titleall)):
try:
print("评论标题是:"+eval('u"'+titleall[i]+'"'))
print("评论内容是:"+eval('u"'+commentall[i]+'"'))
print("------")
except Exception as err:
print(err)b.腾讯视频评论爬虫:获取”深度解读”评论内容(自动切换下一页评论的爬虫)
#自动切换下一页评论的爬虫
import urllib.request
import re
#https://video.coral.qq.com/filmreviewr/c/upcomment/[视频id]?commentid=[评论id]&reqnum=[每次提取的评论的个数]
vid="j6cgzhtkuonf6te"
cid="6233603654052033588"
num="3"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Content-Type":"application/javascript",
}
opener=urllib.request.build_opener()
headall=[]
for key,value in headers.items():
item=(key,value)
headall.append(item)
opener.addheaders=headall
urllib.request.install_opener(opener)
#for循环,多个页面切换
for j in range(0,100):
#爬取当前评论页面
print("第"+str(j)+"页")
#构造当前评论网址thisurl="https://video.coral.qq.com/filmreviewr/c/upcomment/"+vid+"?commentid="+cid+
"&reqnum="+num
data=urllib.request.urlopen(thisurl).read().decode("utf-8")
titlepat='"title":"(.*?)","abstract":"'
commentpat='"content":"(.*?)"'
titleall=re.compile(titlepat,re.S).findall(data)
commentall=re.compile(commentpat,re.S).findall(data)
lastpat='"last":"(.*?)"'
#获取last值,赋值给cid,进行评论id切换
cid=re.compile(lastpat,re.S).findall(data)[0]
for i in range(0,len(titleall)):
try:
print("评论标题是:"+eval('u"'+titleall[i]+'"'))
print("评论内容是:"+eval('u"'+commentall[i]+'"'))
print("------")
except Exception as err:
print(err)四、挑战案例
1)第三项练习-中国裁判文书网爬虫实战
目标网站:http://wenshu.court.gov.cn/
需要获取的数据:2018年上海市的刑事案件接下来进入实战讲解。
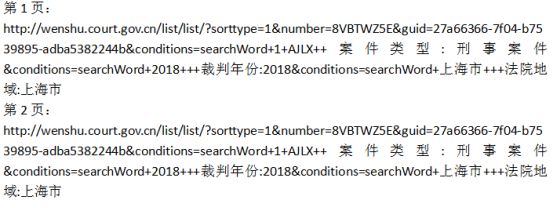
可以发现没有对应的网页变换,意味着中国裁判文书网换页是通过POST进行请求,对应的变化数据不显示在网址中。通过F12查看网页代码,再换页操作之后,如下图,查看ListContent,其中有几个字段需要了解:
Param:检索条件
Index:页码
Page:每页展示案件数量
...
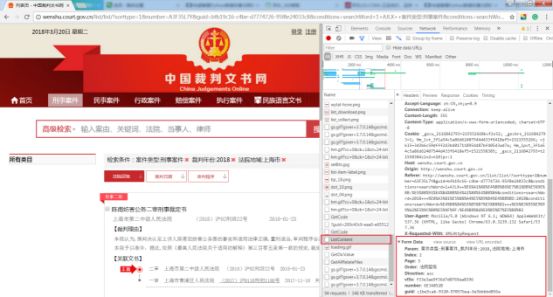
重要的是最后三个字段(vl5x,number,guid)该如何获取?首先,guid即uuid,叫全球唯一标识,是利用python中的uuid随机生成的字段。其次是number字段,找到ListContent上面的GetCode请求,恰好其Response中包含了number字段的值。而GetCode又是通过POST请求的,发现请求的字段只要guid这一项,那么问题便迎刃而解。
最后,难点在于vl5x字段如何获取?打开Fiddler,在换页操作后,查看ListContent中的vl5x的值,并在此次ListContent之前出现的数据包中的TextView里寻找这个字段或值,一般的网站可以很容易找到,但中国裁判文书网是政府网站,反爬策略非常高明,寻找的过程需要极高的耐心。
事实上,中国裁判文书网的vl5x字段可以从某个js包中获得,获取的方式是通过getKey()函数。从网页源代码中找到getKey()函数的js代码,由于代码是packed状态,用unpacked工具:http://tool.chinaz.com/js.aspx 将其进行解码,后利用js界面美观工具可以方便理解:http://jsbeautifier.org/
但无关紧要,只需直接将getKey()函数s代码复制到unpack_js.html中,就可以解出vl5x字段的值,其中需要用到Cookie中的vjkl5字段值。需要注意提前下载好base64.js和md5.js,并在unpack_js.html加载。
第三步,以下是中国裁判文书网爬虫完整代码:
import urllib.request
import re
import http.cookiejar
import execjs
import uuid
#随机生成guid
guid=uuid.uuid4()
print("guid:"+str(guid))
fh=open("./base64.js","r")
js1=fh.read()
fh.close()
fh=open("./md5.js","r")
js2=fh.read()
fh.close()
fh=open("./getkey.js","r")
js3=fh.read()
fh.close()
#将完整js代码都加载进来
js_all=js1+js2+js3
#在生成的CookieJar添加到opner中
cjar=http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar))
#Referer常用于反爬,指来源网址
opener.addheaders=[("Referer","http://wenshu.court.gov.cn/list/list/?sorttype=1&conditions=searchWord+1+AJLX++%E6%A1%88%E4%BB%B6%E7%B1%BB%E5%9E%8B:%E5%88%91%E4%BA%8B%E6%A1%88%E4%BB%B6&conditions=searchWord+2018+++%E8%A3%81%E5%88%A4%E5%B9%B4%E4%BB%BD:2018&conditions=searchWord+%E4%B8%8A%E6%B5%B7%E5%B8%82+++%E6%B3%95%E9%99%A2%E5%9C%B0%E5%9F%9F:%E4%B8%8A%E6%B5%B7%E5%B8%82")]
urllib.request.install_opener(opener)
#用户代理池
import random
uapools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
#访问首页
urllib.request.urlopen("http://wenshu.court.gov.cn/list/list/?sorttype=1&conditions=searchWord+1+AJLX++%E6%A1%88%E4%BB%B6%E7%B1%BB%E5%9E%8B:%E5%88%91%E4%BA%8B%E6%A1%88%E4%BB%B6&conditions=searchWord+2018+++%E8%A3%81%E5%88%A4%E5%B9%B4%E4%BB%BD:2018&conditions=searchWord+%E4%B8%8A%E6%B5%B7%E5%B8%82+++%E6%B3%95%E9%99%A2%E5%9C%B0%E5%9F%9F:%E4%B8%8A%E6%B5%B7%E5%B8%82").read().decode("utf-8","ignore")
#将Cookie中的vjkl5字段提取出来
pat="vjkl5=(.*?)\s"
vjkl5=re.compile(pat,re.S).findall(str(cjar))
if(len(vjkl5)>0):
vjkl5=vjkl5[0]
else:
vjkl5=0
print("vjkl5:"+str(vjkl5))
#将js代码中的旧Cookie的值替换为新的vjkl5的值
js_all=js_all.replace("ce7c8849dffea151c0179187f85efc9751115a7b",str(vjkl5))
#使用python执行js代码,请提前安装好对应模块(在命令行中执行pip install pyexejs)
compile_js=execjs.compile(js_all)
#获得vl5x字段值
vl5x=compile_js.call("getKey")
print("vl5x:"+str(vl5x))
url="http://wenshu.court.gov.cn/List/ListContent"
#for循环,切换第1页到10页
for i in range(0,10):
try:
#从GetCode中获取number字段值
codeurl="http://wenshu.court.gov.cn/ValiCode/GetCode"
#上面提到,GetCode中,只要guid一个字段,将其获取到
codedata=urllib.parse.urlencode({
"guid":guid,
}).encode('utf-8')
codereq = urllib.request.Request(codeurl,codedata)
codereq.add_header('User-Agent',random.choice(uapools))
codedata=urllib.request.urlopen(codereq).read().decode("utf-8","ignore")
#print(codedata)
#构造请求的参数
postdata =urllib.parse.urlencode({
"Param":"案件类型:刑事案件,裁判年份:2018,法院地域:上海市",
"Index":str(i+1),
"Page":"20",
"Order":"法院层级",
"Direction":"asc",
"number":str(codedata),
"guid":guid,
"vl5x":vl5x,
}).encode('utf-8')
#直接发送POST请求
req = urllib.request.Request(url,postdata)
req.add_header('User-Agent',random.choice(uapools))
#获得ListContent中的文书ID值
data=urllib.request.urlopen(req).read().decode("utf-8","ignore")
pat='文书ID.*?".*?"(.*?)."'
allid=re.compile(pat).findall(data)
print(allid)
except Exception as err:
print(err)
如此便可批量获取中国裁判文书网中的案件信息。友情提示,如果频繁爬取该网站,需扩充用户代理池。
五、推荐博文
1)常见反爬策略与反爬攻克手段介绍
数据的隐藏可以算是一种反爬策略之一,抓包分析是该反爬策略常见的反爬攻克手段。
当然,反爬还有很多手段,比如通过IP限制、UA限制、验证码限制...等等,如果需要系统了解反爬与反爬攻克问题,可以参考以下博文:
https://weibo.com/ttarticle/p/show?id=2309404125351516226870&mod=zwenzhang
2)如何深入学习Python网络爬虫(深入学习路线介绍)
通过上述的介绍,相信对网络爬虫已经有了基础的了解,以及能够写出一些简单的爬虫项目。
以下项目可以提供练习:
淘宝商品图片爬虫项目
淘宝商品爬虫项目
…
如果想更深入学习网络爬虫,完整学习路线可参考以下博文:
https://weibo.com/ttarticle/p/show?id=2309404128731852618203&mod=zwenzhang
3)关于Python爬虫,推荐书籍
《Python程序设计基础实战教程》 . 清华大学出版社.2018年
《精通Python网络爬虫》.机械工业出版社.2017年4月

韦玮老师网络爬虫最新课程火爆促销中!
20章节只需299!
扫码下图或点击阅读原文即可试听学习
以上是关于如何快速掌握Python数据采集与网络爬虫技术的主要内容,如果未能解决你的问题,请参考以下文章