2017.08.04 Python网络爬虫之Scrapy爬虫实战二 天气预报的数据存储问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2017.08.04 Python网络爬虫之Scrapy爬虫实战二 天气预报的数据存储问题相关的知识,希望对你有一定的参考价值。
1.数据存储到JSon:程序阅读一般都是使用更方便的Json或者cvs等待格式,继续讲解Scrapy爬虫的保存方式,也就是继续对pipelines.py文件动手脚
(1)创建pipelines2json.py文件:
import time
import json
import codecs
class WeatherPipeline(object):
def process_item(self, item, spider):
today=time.strftime(‘%Y%m%d‘,time.localtime())
fileName=today+‘.json‘
with codecs.open(fileName,‘a‘,encoding=‘utf8‘) as fp:
line=json.dumps(dict(item),ensure_ascii=False)+‘\\n‘
fp.write(line)
return item
(2)修改Settings.py文件,将pipelines2json加入到ITEM_PIPELINES中去:
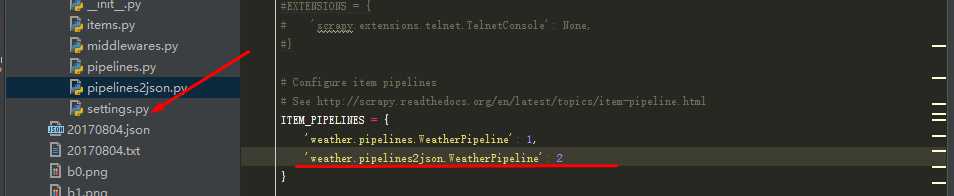
(3)执行命令:scrapy crawl HQUSpider,查看运行结果

2.数据存储到MySQL:
(1)linux安装Mysql:sudo apt-get install mysql-server mysql-client
(2)登录mysql,查看mysql的字符编码:
mysql -u root -p
mysql> SHOW VARIABLES LIKE "character%";
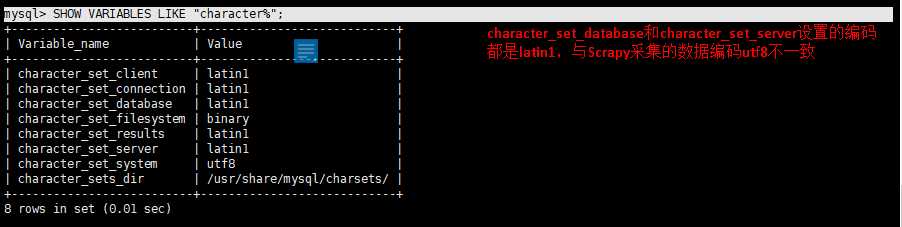
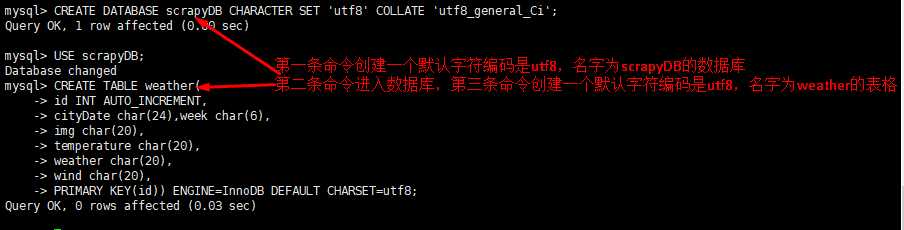
(3)不修改Mysql的环境变量,只在创建数据库和表的时候指定字符编码:
mysql>CREATE DATABASE scrapyDB CHARACTER SET ‘utf8‘ COLLATE ‘utf8_general_Ci‘;
mysql> USE scrapyDB;
mysql> CREATE TABLE weather(
-> id INT AUTO_INCREMENT,
-> cityDate char(24),week char(6),
-> img char(20),
-> temperature char(20),
-> weather char(20),
-> wind char(20),
-> PRIMARY KEY(id)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(4)创建一个普通用户,并给这个用户管理数据库的权限,在mysql环境下,执行命令:
mysql> grant all PRIVILEGES on scrapy.* to [email protected]‘%‘ identified by ‘crawl123‘;
mysql> GRANT USAGE ON scrapyDB.* TO ‘crawlUSER‘@‘localhost‘ IDENTIFIED BY ‘crawl123‘ WITH GRANT OPTION;

(5)windows下安装MySQLdb模块:
执行命令:pip install MySQL-python
安装报错:

转而安装Microsoft Visual C++ Compiler for Python 2.7,网址:https://www.microsoft.com/en-us/download/confirmation.aspx?id=44266
安装VcForPython27也遇到问题: error: command ‘C:\\\\Users\\\\\\xb4\\xba\\xcc\\xef\\\\AppData\\\\Local\\\\Programs\\\\Common\\\\Microsoft\\\\Visual C++ for Python\\\\9.0\\\\VC\\\\Bin\\\\amd64\\\\cl.exe‘ failed with exit status 2

解决方法:
解决办法:搜索或者到下面网址下载安装:MySQL-python-1.2.3.win-amd64-py2.7.exe
MySQL-python 1.2.3 for Windows and Python 2.7, 32bit and 64bit versions | codegood
http://www.codegood.com/archives/129
安装成功!!
(6)编辑pipelines2mysql.py:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don‘t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import MySQLdb
import os.path
class WeatherPipeline(object):
def process_item(self, item, spider):
cityDate=item[‘cityDate‘].encode(‘utf8‘)
week=item[‘week‘].encode(‘utf8‘)
img=os.path.basename(item[‘img‘])
temperature=item[‘temperature‘].encode(‘utf8‘)
weather=item[‘weather‘].encode(‘utf8‘)
wind=item[‘wind‘].encode(‘utf8‘)
conn=MySQLdb.connect(
host=‘远程主机ip地址‘,
port=3306,
user=‘crawlUSER‘,
passwd=‘密码‘,
db=‘scrapyDB‘,
charset=‘utf8‘
)
cur=conn.cursor()
cur.execute("INSERT weather(cityDate,week,img,temperature,weather,wind) values(%s,%s,%s,%s,%s,%s)",
( cityDate,week,img,temperature,weather,wind))
cur.close()
conn.commit()
conn.close()
return item
运行报错:

解决方法:去掉sql语句中的TO ;
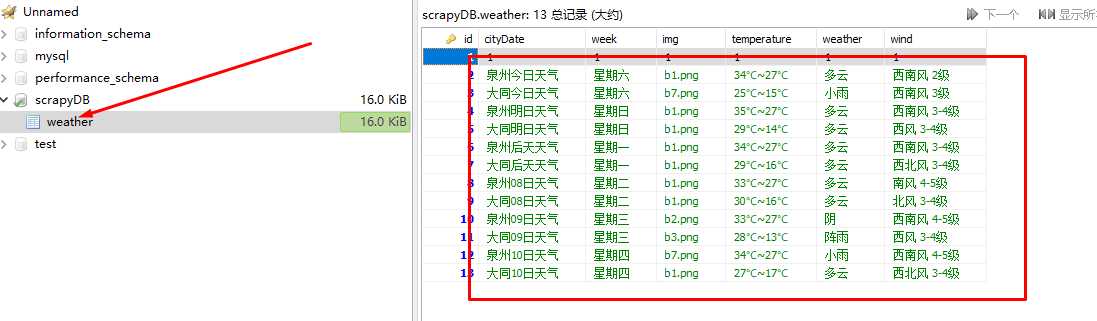
完成!!
以上是关于2017.08.04 Python网络爬虫之Scrapy爬虫实战二 天气预报的数据存储问题的主要内容,如果未能解决你的问题,请参考以下文章