纳米光刻与Nvidia冲击光刻技术分析
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了纳米光刻与Nvidia冲击光刻技术分析相关的知识,希望对你有一定的参考价值。
纳米光刻与Nvidia冲击光刻技术分析
英伟达杀入光刻领域,DPU和GPU重磅更新,首次详谈云服务!
在昨晚的GTC演讲中,英伟达CEO宣布了一系列的重磅芯品,当中不但包括了为中国专门准备的,基于H100改版而来的H800芯片。同时,公司还宣布了为生成式AI而准备的产品。
在这次演讲中,黄仁勋还带来了加速2nm设计的计算光刻等一系列产品,现在我们综合如下,与读者分享。
将旗舰 H100 调整为H800,出口到中国
据路透社报道,主导人工智能芯片市场的美国半导体设计公司Nvidia 已将其旗舰产品修改为可以合法出口到中国的版本。
美国监管机构去年制定了规则,禁止Nvidia 向中国客户销售其两款最先进的芯片,即 A100 和更新的 H100。此类芯片对于开发生成式人工智能技术(如 OpenAI 的 ChatGPT 和类似产品)至关重要。
路透社在 11 月报道称,Nvidia设计了一款名为 A800 的芯片,该芯片降低了 A100 的某些功能,使 A800 可以合法出口到中国。
周二,该公司证实它已经开发出类似的 H100 芯片的中国出口版本。阿里巴巴集团控股、百度公司和腾讯控股等中国科技公司的云计算部门正在使用这款名为 H800 的新芯片,英伟达发言人说。
美国监管机构去年秋天实施了规则,以减缓中国在半导体和人工智能等关键技术领域的发展。
围绕人工智能芯片的规则强加了一项测试,禁止那些具有强大计算能力和高芯片到芯片数据传输率的芯片。在使用大量数据训练人工智能模型时,传输速度非常重要,因为较慢的传输速度意味着更多的训练时间。
中国一位芯片行业消息人士告诉路透社,H800 主要将芯片到芯片的数据传输速率降低到旗舰 H100 速率的一半左右。
Nvidia 发言人拒绝透露面向中国的 H800 与 H100 有何不同,只是“我们的 800 系列产品完全符合出口管制法规”。
突破计算光刻,为2nm芯片制造奠定基础
在英伟达这次GTC大会上,下手ASML、TSMC 和 Synopsys突破计算光刻,助力行业跨越物理极限是另一个值得关注的亮点。
NVIDIA 表示,将加速计算带入计算光刻领域,使 ASML、台积电和 Synopsys 等半导体领导者能够加速下一代芯片的设计和制造,正如当前的生产流程已接近物理学的极限一样使成为可能。
英伟达在新闻稿中指出,用于计算光刻的全新 NVIDIA cuLitho 软件库被世界领先的晶圆代工厂台积电和电子设计自动化领导者Synopsys集成到其最新一代 NVIDIA Hopper™ 架构 GPU 的软件、制造流程和系统中。设备制造商 ASML 在 GPU 和 cuLitho 方面与 NVIDIA 密切合作,并计划将对 GPU 的支持集成到其所有计算光刻软件产品中。
这一进步将使芯片具有比现在更细的晶体管和电线,同时加快上市时间并提高 24/7 全天候运行以驱动制造过程的大型数据中心的能源效率。
“芯片行业是世界上几乎所有其他行业的基础,”NVIDIA 创始人兼首席执行官黄仁勋表示。“随着光刻技术达到物理极限,NVIDIA 推出 cuLitho 并与我们的合作伙伴 TSMC、ASML 和 Synopsys 合作,使晶圆厂能够提高产量、减少碳足迹并为 2nm 及更高工艺奠定基础。”
在 GPU 上运行,cuLitho 比当前光刻技术(在硅晶圆上创建图案的过程)提供高达 40 倍的性能飞跃,加速目前每年消耗数百亿 CPU 小时的大量计算工作负载。
它使 500 个 NVIDIA DGX H100 系统能够完成 40,000 个 CPU 系统的工作,并行运行计算光刻过程的所有部分,有助于减少电力需求和潜在的环境影响。
在短期内,使用 cuLitho 的晶圆厂可以帮助每天多生产 3-5 倍的光掩模——芯片设计的模板——使用比当前配置低 9 倍的功率。需要两周才能完成的光掩模现在可以在一夜之间完成。
从长远来看,cuLitho 将实现更好的设计规则、更高的密度、更高的产量和 AI 驱动的光刻。
“cuLitho 团队通过将昂贵的操作转移到 GPU,在加速计算光刻方面取得了令人钦佩的进展,”台积电首席执行官 CC Wei 博士说。“这一发展为台积电在芯片制造中更广泛地部署逆光刻技术和深度学习等光刻解决方案开辟了新的可能性,为半导体规模的持续发展做出了重要贡献。”
“我们计划将对 GPU 的支持集成到我们所有的计算光刻软件产品中,”ASML 首席执行官 Peter Wennink 说。“我们与 NVIDIA 在 GPU 和 cuLitho 方面的合作应该会给计算光刻带来巨大好处,从而给半导体微缩带来好处。在High NA 极紫外光刻时代尤其如此。”
Synopsys 董事长兼首席执行官 Aart de Geus 表示:“计算光刻,特别是光学邻近校正 (OPC),正在突破最先进芯片的计算工作负载界限。“通过与我们的合作伙伴 NVIDIA 合作,在 cuLitho 平台上运行 Synopsys OPC 软件,我们将性能从数周大幅提升至数天!我们两家领先公司的合作将继续推动该行业取得惊人的进步。”
英伟达表示,近年来,由于较新节点中的晶体管数量更多以及更严格的精度要求,半导体制造中最大工作负载所需的计算时间成本已超过摩尔定律。未来的节点需要更详细的计算,并非所有这些都可以适用于当前平台提供的可用计算带宽,从而减缓了半导体创新的步伐。
晶圆厂流程变更通常需要 OPC 修订,从而造成瓶颈。cuLitho 有助于消除这些瓶颈,并使新颖的解决方案和创新技术成为可能,例如曲线掩模、High NA EUV 光刻和新技术节点所需的亚原子光刻胶建模。
Nvidia 宣布 BlueField-3 GA
Nvidia 今天宣布全面推出其 BlueField-3 数据处理单元 (DPU) 以及令人印象深刻的早期部署,包括 Oracle Cloud Infrastructure。BlueField-3 于 2021 年首次描述,现已交付,是 Nvidia 的第三代 DPU,拥有大约 220 亿个晶体管。与上一代 BlueField 相比,新的 DPU 支持以太网和 InfiniBand 连接,速度高达每秒 400 吉比特,计算能力提高 4 倍,加密加速提高 4 倍,存储处理速度提高 2 倍,内存带宽提高 4 倍。”
Nvidia 首席执行官黄仁勋在 GTC 23 主题演讲中表示:“在现代软件定义的数据中心中,执行虚拟化、网络、存储和安全性的操作系统会消耗数据中心近一半的 CPU 内核和相关功率。数据中心必须加速每个工作负载以回收功率并释放 CPU 用于创收工作负载。Nvidia BlueField 卸载并加速了数据中心操作系统和基础设施软件。”
早在 2020 年,Nvidia 就制定了 DPU 战略,认为 CPU 正因诸如 Huang 所引用的内务杂务而陷入困境。Nvidia 认为,DPU 将吸收这些任务,从而释放 CPU 用于应用程序。其他芯片供应商——尤其是英特尔和 AMD——似乎同意并已跳入 DPU 市场。

有时被描述为类固醇的智能网卡引起了人们的兴趣,但尚未转化为广泛的销售。变化现在可能正在发生。Huang 列举了“超过 20 个生态系统合作伙伴”,其中包括现在使用 BlueField 技术的 Cisco、DDN、Dell EMC 和 Juniper。
在媒体/分析师预简报会上,英伟达网络副总裁 Kevin Deierling 表示:“BlueField-3 已全面投入生产并可供使用。它的 Arm 处理器内核数量是 BlueField-2 的两倍,加速器更多,并且运行工作负载的速度比我们上一代 DPU 快八倍。BlueField-3 可跨云 HPC、企业和加速 AI 用例卸载、加速和隔离工作负载。”
Nvidia 的 DPU 瞄准超级计算机、数据中心和云提供商。在 GTC 上,Nvidia 吹捧了 Oracle 云部署,其中 BlueField-3 是Nvidia更大的 DGX-in-the-Cloud 胜利的一部分。
“正如你所听到的,我们宣布Oracle Cloud Infrastructure率先运行 DGX Cloud 和 AI 超级计算服务,使企业能够立即访问为生成 AI 训练高级模型所需的基础设施和软件。OCI [还] 选择了 BlueField-3 以实现更高的性能、效率和安全性。与 BluField-2 相比,BlueField-3 通过从 CPU 卸载数据中心基础设施任务,将虚拟化实例增加了八倍,从而提供了巨大的性能和效率提升,”Deierling 说。

在官方公告中,英伟达引用了 OCI 执行副总裁 Clay Magouyrk 的话说:“Oracle 云基础设施为企业客户提供了几乎无与伦比的人工智能和科学计算基础设施的可访问性,并具有改变行业的能力。Nvidia BlueField-3 DPU 是我们提供最先进、可持续的云基础设施和极致性能战略的关键组成部分。”
BlueField-3 在 CSP 中的其他胜利包括百度、CoreWeave。京东、微软 Azure 和腾讯。
Nvidia 还报告称,BlueField-3 具有“通过DOCA软件框架”的完全向后兼容性。

DOCA 是 BlueField 的编程工具,DOCA 2.0 是最新版本。Nvidia 一直在稳步为其 DPU 产品线添加功能。例如,最近,它加强了内联 GPU 数据包处理,“以实施高数据率解决方案:数据过滤、数据放置、网络分析、传感器信号处理等。” 新的 DOCA GPUNetIO 库可以克服以前 DPDK 解决方案中发现的一些限制。
按照英伟达所说,Nvidia 实时 GPU 网络数据包处理是一种对多个不同应用领域有用的技术,包括信号处理、网络安全、信息收集和输入重建。这些应用程序的目标是实现内联数据包处理管道以在 GPU 内存中接收数据包(无需通过 CPU 内存暂存副本);与一个或多个 CUDA 内核并行处理它们;然后运行推理、评估或通过网络发送计算结果。
推出H100 NVL,用于大模型的内存服务器卡
Anandtech表示,虽然今年的春季 GTC 活动没有采用 NVIDIA 的任何新 GPU 或 GPU 架构,但该公司仍在推出基于去年推出的 Hopper 和 Ada Lovelace GPU 的新产品。但在高端市场,该公司今天宣布推出专门针对大型语言模型用户的新 H100 加速器变体:H100 NVL。
H100 NVL 是NVIDIA H100 PCIe 卡的一个有趣变体,它是时代的标志和 NVIDIA 在 AI 领域取得的广泛成功,其目标是一个单一的市场:大型语言模型 (LLM) 部署。有一些东西使这张卡与 NVIDIA 通常的服务器票价不同——其中最重要的是它的 2 个 H100 PCIe 板已经桥接在一起——但最大的收获是大内存容量。组合的双 GPU 卡提供 188GB 的 HBM3 内存——每张卡 94GB——提供比迄今为止任何其他 NVIDIA 部件更多的每个 GPU 内存,即使在 H100 系列中也是如此。

驱动此 SKU 的是一个特定的利基市场:内存容量。像 GPT 系列这样的大型语言模型在许多方面都受到内存容量的限制,因为它们甚至会很快填满 H100 加速器以保存它们的所有参数(在最大的 GPT-3 模型的情况下为 175B)。因此,NVIDIA 选择拼凑出一个新的 H100 SKU,它为每个 GPU 提供的内存比他们通常的 H100 部件多一点,后者最高为每个 GPU 80GB。
在封装的盖下,我们看到的本质上是放置在 PCIe 卡上的GH100 GPU的特殊容器。所有 GH100 GPU 都配备 6 个 HBM 内存堆栈(HBM2e 或 HBM3),每个堆栈的容量为 16GB。然而,出于良率原因,NVIDIA 仅在其常规 H100 部件中提供 6 个 HBM 堆栈中的 5 个。因此,虽然每个 GPU 上标称有 96GB 的 VRAM,但常规 SKU 上只有 80GB 可用。

而H100 NVL 是神话般的完全启用的 SKU,启用了所有 6 个堆栈。通过打开第 6个HBM 堆栈,NVIDIA 能够访问它提供的额外内存和额外内存带宽。它将对产量产生一些实质性影响——多少是 NVIDIA 严密保守的秘密——但 LLM 市场显然足够大,并且愿意为近乎完美的 GH100 封装支付足够高的溢价,以使其值得 NVIDIA 光顾。
即便如此,应该注意的是,客户无法访问每张卡的全部 96GB。相反,在总容量为 188GB 的内存中,它们每张卡的有效容量为 94GB。在今天的主题演讲之前,NVIDIA 没有在我们的预简报中详细介绍这个设计,但我们怀疑这也是出于良率原因,让 NVIDIA 在禁用 HBM3 内存堆栈中的坏单元(或层)方面有一些松懈。最终结果是新 SKU 为每个 GH100 GPU 提供了 14GB 的内存,内存增加了 17.5%。同时,该卡的总内存带宽为 7.8TB/秒,单个板的总内存带宽为 3.9TB/秒。
除了内存容量增加之外,更大的双 GPU/双卡 H100 NVL 中的各个卡在很多方面看起来很像放置在 PCIe 卡上的 H100 的 SXM5 版本。虽然普通的 H100 PCIe 由于使用较慢的 HBM2e 内存、较少的活动 SM/张量核心和较低的时钟速度而受到一些限制,但 NVIDIA 为 H100 NVL 引用的张量核心性能数据与 H100 SXM5 完全相同,这表明该卡没有像普通 PCIe 卡那样进一步缩减。我们仍在等待产品的最终、完整规格,但假设这里的所有内容都如所呈现的那样,那么进入 H100 NVL 的 GH100 将代表当前可用的最高分档 GH100。

这里需要强调复数。如前所述,H100 NVL 不是单个 GPU 部件,而是双 GPU/双卡部件,它以这种方式呈现给主机系统。硬件本身基于两个 PCIe 外形规格的 H100,它们使用三个 NVLink 4 桥接在一起。从物理上讲,这实际上与 NVIDIA 现有的 H100 PCIe 设计完全相同——后者已经可以使用 NVLink 桥接器进行配对——所以区别不在于两板/四插槽庞然大物的结构,而是内部芯片的质量。换句话说,您今天可以将普通的 H100 PCIe 卡捆绑在一起,但它无法与 H100 NVL 的内存带宽、内存容量或张量吞吐量相匹配。
令人惊讶的是,尽管有出色的规格,但 TDP 几乎保持不变。H100 NVL 是一个 700W 到 800W 的部件,分解为每块板 350W 到 400W,其下限与常规 H100 PCIe 的 TDP 相同。在这种情况下,NVIDIA 似乎将兼容性置于峰值性能之上,因为很少有服务器机箱可以处理超过 350W 的 PCIe 卡(超过 400W 的更少),这意味着 TDP 需要保持稳定。不过,考虑到更高的性能数据和内存带宽,目前还不清楚 NVIDIA 如何提供额外的性能。Power binning 在这里可以发挥很大的作用,但也可能是 NVIDIA 为卡提供比平常更高的提升时钟速度的情况,因为目标市场主要关注张量性能并且不会点亮整个 GPU一次。
否则,鉴于 NVIDIA 对 SXM 部件的普遍偏好,NVIDIA 决定发布本质上最好的 H100 bin 是一个不寻常的选择,但在 LLM 客户的需求背景下,这是一个有意义的决定。基于 SXM 的大型 H100 集群可以轻松扩展到 8 个 GPU,但任何两个 GPU 之间可用的 NVLink 带宽量因需要通过 NVSwitch 而受到限制。对于只有两个 GPU 的配置,将一组 PCIe 卡配对要直接得多,固定链路保证卡之间的带宽为 600GB/秒。
但也许比这更重要的是能够在现有基础设施中快速部署 H100 NVL。LLM 客户无需安装专门为配对 GPU 而构建的 H100 HGX 载板,只需将 H100 NVL 添加到新的服务器构建中,或者作为对现有服务器构建的相对快速升级即可。毕竟,NVIDIA 在这里针对的是一个非常特殊的市场,因此 SXM 的正常优势(以及 NVIDIA 发挥其集体影响力的能力)可能不适用于此。
总而言之,NVIDIA 宣称 H100 NVL 提供的 GPT3-175B 推理吞吐量是上一代 HGX A100 的 12 倍(8 个 H100 NVL 对比 8 个 A100)。对于希望尽快为 LLM 工作负载部署和扩展系统的客户来说,这肯定很有吸引力。如前所述,H100 NVL 在架构特性方面并没有带来任何新的东西——这里的大部分性能提升来自 Hopper 架构的新变压器引擎——但 H100 NVL 将作为最快的 PCIe H100 服务于特定的利基市场选项,以及具有最大 GPU 内存池的选项。
总结一下,根据 NVIDIA 的说法,H100 NVL 卡将于今年下半年开始发货。该公司没有报价,但对于本质上是顶级 GH100 的产品,我们预计它们会获得最高价格。特别是考虑到 LLM 使用量的激增如何转变为服务器 GPU 市场的新淘金热。
Nvidia 的“云”,服务起价 37,000 美元
如果你是 Nvidia 的忠实拥护者,请准备好花大价钱使用它在云端的 AI 工厂。
Nvidia 联合创始人兼首席执行官黄仁勋上个月在谈到这家GPU 制造商的季度收益时,提出了 Nvidia DGX Cloud 的计划,本质上是呼吁将公司的 DGX AI 超级计算机硬件和配套软件——尤其是其广泛的企业 AI一套软件——放到公有云平台上供企业使用。
我们必须申明,Nvidia 还不够富有,或者说不够愚蠢,他们无法构建云来与 Amazon Web Services、Microsoft Azure 或 Google Cloud 等公司竞争。但他们足够聪明,可以利用这些庞大的计算和存储实用程序为自己谋利,并在它们构建的基础设施之上销售服务赚钱,而基础设施又基于自己的组件。
DGX Cloud 的巧妙之处不在于有经过认证的本地和云堆栈来运行 Nvidia 的 AI 硬件和软件。您需要向 Nvidia 支付费用,才能以一种 SaaS 模式这样做——Nvidia 可以向您或云出售构建基础设施的部件。
就其本身而言,这是使AI 民主化的最新尝试,将其带出 HPC 和研究机构的领域,并将其置于主流企业的范围内,这些企业非常渴望利用新兴技术可以带来的业务优势递送。
对于 Nvidia 而言,DGX Cloud 的人工智能即服务代表着向云优先战略的强烈转变,以及一种理解——与其他组件制造商一样——它现在既是一家硬件制造商,也是一家软件公司,而公共云是一个使该软件易于访问并且更重要的是将其货币化的自然途径。
对于十多年前将 AI 置于其前进战略中心、构建以 AI 为核心的路线图的公司而言,这是重要的下一步。Nvidia 在 2016 年推出了 DGX-1,这是其第一台深度学习超级计算机。第四代系统于去年推出。2020 年出现了第一批DGX SuperPOD,一年后 Nvidia 推出了 AI Enterprise,这是一个包含框架、工具和相当大剂量的 VMware vSphere 的软件套件。
AI Enterprise 强调了软件对 Nvidia 日益增长的重要性——反映了其他组件制造商的类似趋势——这家公司现在从事软件工作的员工多于硬件。
借助 DGX Cloud,Nvidia 现在可以通过另一种方式将所有这些交付给那些希望在其工作流程中利用生成式 AI 工具(例如来自 OpenAI 的广受欢迎的 ChatGPT)的企业(通过 Microsoft),但没有资源在其内部扩展基础设施数据中心来支持它。他们现在可以通过云访问它,享受它所有的可扩展性和即用即付的好处。
Nvidia 企业计算副总裁 Manuvir Das 在 GTC 前会议上告诉记者:“多年来,我们一直在与企业公司合作,创建他们自己的模型来训练他们自己的数据。” “过去几个月,像 ChatGPT 这样基于非常非常大的 GPT 模型的服务越来越受欢迎,每天有数百万人使用一个模型。当我们与企业公司合作时,他们中的许多人有兴趣使用自己的数据为自己的目的创建模型。”
据最新介绍,租用 GPU 公司包罗万象的云端 AI 超级计算机的DGX Cloud起价为每个实例每月 36,999 美元。租金包括使用带有八个 Nvidia H100 或 A100 GPU 和 640GB GPU 内存的云计算机。价格包括用于开发 AI 应用程序和大型语言模型(如 BioNeMo)的 AI Enterprise 软件。
“DGX Cloud 有自己的定价模型,因此客户向 Nvidia 付费,他们可以根据他们选择使用它的位置通过任何云市场购买它,但这是一项由 Nvidia 定价的服务,包括所有费用,” Nvidia 企业计算副总裁 Manuvir Das 在新闻发布会上说。
DGX Cloud 的起始价格接近 Microsoft Azure 每月收取的 20,000 美元的两倍,用于满载的 A100 实例,该实例具有 96 个 CPU 内核、900GB 存储空间和 8 个 A100 GPU 每月。
甲骨文在其 RDMA 超级集群中托管 DGX 云基础设施,可扩展到 32,000 个 GPU。微软将在下个季度推出 DGX Cloud,随后将推出 Google Cloud。
客户将不得不为最新的硬件支付额外费用,但软件库和工具的集成可能会吸引企业和数据科学家。
Nvidia 声称它为 AI 提供了最好的可用硬件。它的 GPU 是高性能和科学计算的基石。但是 Nvidia 专有的硬件和软件就像使用 Apple iPhone 一样——你得到了最好的硬件,但一旦你被锁定,就很难脱身,而且在它的生命周期中会花费很多钱。
但为 Nvidia 的 GPU 支付溢价可能会带来长期利益。例如,Microsoft 正在投资 Nvidia 硬件和软件,因为它通过 Bing with AI 提供了成本节约和更大的收入机会。
人工智能工厂的概念是由首席执行官黄仁勋提出的,他将数据设想为原材料,工厂将其转化为可用数据或复杂的人工智能模型。Nvidia的硬件和软件是AI工厂的主要组成部分。
“你只需提供你的工作,指向你的数据集,然后点击开始,所有的编排和下面的一切都在 DGX Cloud 中得到处理。现在,相同的模型可以在托管在各种公共云上的基础设施上使用,”Nvidia 企业计算副总裁 Manuvir Das 在新闻发布会上说。
Das 说,数百万人正在使用 ChatGPT 风格的模型,这需要高端人工智能硬件。
DGX Cloud 进一步推动了 Nvidia 将其硬件和软件作为一套产品销售的目标。Nvidia 正在进军软件订阅业务,该业务的长尾涉及销售更多硬件,从而产生更多软件收入。Base Command Platform 软件界面将允许公司管理和监控 DGX 云培训工作负载。
Oracle Cloud 拥有多达 512 个 Nvidia GPU 的集群,以及每秒 200 GB 的 RDMA 网络。该基础设施支持包括 Lustre 在内的多个文件系统,吞吐量为每秒 2 TB。
Nvidia 还宣布有更多公司采用了其 H100 GPU。Amazon 宣布他们的 EC2“UltraClusters”和 P5 实例将基于 H100。“这些实例可以使用他们的 EFA 技术扩展到 20,000 个 GPU,”Nvidia 超大规模和 HPC 计算副总裁 Ian Buck 在新闻发布会上说。
EFA 技术是指 Elastic Fabric Adapter,它是由 Nitro 编排的网络实现,它是一种处理网络、安全和数据处理的通用定制芯片。
Meta Platforms 已开始在Grand Teton中部署 H100 系统,这是社交媒体公司下一代 AI 超级计算机的平台。
在GTC上,英伟达还带来了多样化的产品,例如用于特定推理的的英伟达 L4 GPU。据报道,这款 GPU 可以提供比 CPU 高 120 倍的人工智能视频性能。它提供增强的视频解码和转码功能、视频流、增强现实和生成 AI 视频。
此外,英伟达还联合客户打造由 16 个 DGX H100 系统组成,每个系统配备八个 H100 GPU的生成式AI超级计算机Tokyo-1。根据 Nvidia 的 AI 触发器数学计算,这相当于大约一半的 exaflop AI 能力;由于每个 H100(一开始将有 128 个)提供 30 teraflops 的峰值 FP64 功率,因此它应该达到大约 3.84 petaflops 的峰值。
由此可见,黄仁勋正在带领英伟达走向一个新阶段。
纳米压印光刻,能让国产绕过ASML吗?
自从国产替代概念兴起,很少关注半导体行业的人都对光刻机有所耳闻。目前,全世界最先进的芯片,几乎都绕不开ASML(阿斯麦)的DUV(深紫外)和EUV(极紫外)光刻机,但它又贵又难造,除了全力研发光刻机,国产有没有其它的路可以走?
事实上,光刻技术本身存在多种路线,离产业最近的,当属纳米压印光刻(Nano-Imprint Lithography,简称NIL)。
日本最寄望于纳米压印光刻技术,并试图靠它再次逆袭,日经新闻网也称,对比EUV光刻工艺,使用纳米压印光刻工艺制造芯片,能够降低将近四成制造成本和九成电量,铠侠 (KIOXIA)、佳能和大日本印刷等公司则规划在2025年将该技术实用化。
像盖章一样造芯片
纳米压印是一种微纳加工技术,它采用传统机械模具微复型原理,能够代替传统且复杂的光学光刻技术。
虽然从名字上来看,纳米压印概念非常高深,但实际上它的原理并不难理解。压印是古老的图形转移技术,活字印刷术便是最初的压印技术原型,而纳米压印则是图形特征尺寸只有几纳米到几百纳米的一种压印技术。
打个比方来说,纳米压印光刻造芯片就像盖章一样,把栅极长度只有几纳米的电路刻在印章上,再将印章盖在橡皮泥上,得到与印章相反的图案,经过脱模就能够得到一颗芯片。在行业中,这个章被称为模板,而橡皮泥则被称为纳米压印胶。

纳米压印光刻(紫外纳米压印)与光学光刻对比
图源丨佳能官网[4],果壳硬科技译制
纳米压印技术本身的应用范围就非常广泛,包括集成电路、存储、光学、生命科学、能源、环保、国防等领域。
在芯片领域,纳米压印光刻不仅擅长制造各种集成电路,更擅长制造3D NAND、DRAM等存储芯片,与微处理器等逻辑电路相比,存储制造商具有严格的成本限制,且对缺陷要求放宽,纳米压印光刻技术与之非常契合。[6]

纳米压印技术应用不完全统计,制表丨果壳硬科技
参考资料丨《光学精密工程》[5]
对一颗芯片来说,可以说光刻是制造过程中最重要、最复杂也最昂贵的工艺步骤,其成本占总生产成本的30%以上,且占据了将近50%的生产周期。[7]
制程节点正遵循着摩尔定律向前推进,迭代至今,行业正走向纳米的极限,而业界依赖的光学光刻也存在其局限性[8][9][10]:
- 第一,SDAP、SAQP工艺是一维图案化解决方案,严重限制了设计布局;
- 第二,光刻后的额外处理步骤大大增加了晶圆加工的成本(包括额外的光刻、沉积、刻蚀步骤);
- 第三,提高光学光刻分辨率主要通过缩短光刻光源波长来实现,尽管光源已从紫外的436nm、365nm缩短到深紫外(DUV)的193nm和极紫外(EUV)的13.5 nm,但在光学衍射极限限制下,分辨率极限约为半个波长;
- 第四,光刻光源波长缩短使得光刻设备研制难度和成本成倍增长,其成本与规模化能力已无法与过去25年建立的趋势相匹配。
DUV/EUV光刻机使用门槛和成本都很高,自由度和定制化能力不强[11],那改用其它路线是否可行?
残酷的事实是新兴的光刻技术千千万,大部分却都不能满足大规模生产需求,没有任何一种技术是全能的。
对市场体量较为庞大的芯片行业来说,只要技术的优势能贴合需求即可,而理想的光刻技术应具备低成本、高通量、特征尺寸小、材料和基材独立等特点。
目前来看,纳米压印是距离光学光刻最近的那一个。

光刻技术不完全盘点及优劣势对比,制表丨果壳硬科技
参考资料丨《应用化学》[7]《纳米压印技术》[13],中国光学[12]
纳米压印光刻不仅可以制造分辨率5nm以下的高分辨率图形,还拥有相对简单的工艺(相比光学曝光复杂的系统或电子束曝光复杂的电磁聚焦系统)、较高的产能(可大面积制造)、较低的成本(国际权威机构评估同制作水平的纳米压印比传统光学投影光刻至少低一个数量级)[14]、较低的功耗[15]、压印模板可重复使用等优势。
佳能的研究显示,其设备在每小时80片晶圆的吞吐量和80片晶圆的掩模寿命下,纳米压印光刻相对ArF光刻工艺可降低28%的成本,随着吞吐量增加至每小时90片,掩模寿命超过300批次,成本可降低52%。此外,通过改用大场掩模来减少每片晶圆的拍摄次数,还可进一步降低成本。

纳米压印光刻与ArF光刻对比情况[16]
2020年与2021年,极紫外光刻、导向自组装(DSA)和纳米压印光刻被列入国际器件与系统路线图(IRDS)中下一代光刻技术主要候选方案[17][18],评判标准包括分辨率、可靠性、速度和对准精度等。2022年,IRDS中更是强调了纳米压印光刻在3D NAND、DRAM与交叉点存储上应用的重要性。
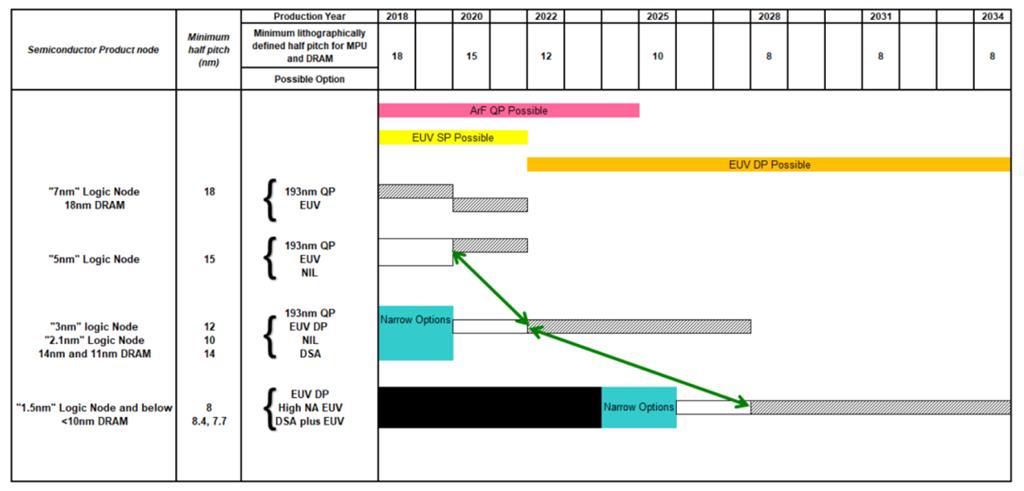
制程工艺发展路线及潜在技术[18]
虽然纳米压印光刻技术被人捧为行业的希望,但它也不是完美的技术,甚至存在许多致命的难题,不断推迟进入市场的时间。
被行业接纳前的问题
想做那个打破常规的先驱者,并没有那么容易。
纳米压印技术最终能否进入产业,取决于它的产能和所能达到的最小图形特征尺寸(Critical dimension,CD),前者由模具的图型转移面积和单次压印循环时间决定,后者由模具表面图型CD和定位系统精度决定。[2]
需要指出的是,尽管纳米压印光刻从原理上回避了投影镜组高昂的价格和光学系统的固有物理限制,但从非接触范式的光学光刻到接触式的纳米压印光刻,又衍生了许多新的技术难题。
技术分支路线多
纳米压印技术发展历史只有二十余年,但在如此短时间内,也诞生了诸多分支路线。
纳米压印发明于1970年,直到1995年,美国普林斯顿大学周郁(Stephen Y Chou)首次提出热纳米压印技术,压印作品分辨率高达10~50nm[20],该技术才引发行业大面积讨论。同年,他又公布了这项开创性技术的专利US5772905A[21],此后,纳米压印成为了划时代的精细加工技术,此起彼伏地浮现新工艺。

纳米压印光刻发展简史[4][13][22~28],制表丨果壳硬科技
发展至今,相对成熟和普遍的纳米压印加工方式包括三类:热纳米压印、紫外纳米压印和微接触印刷(软刻蚀),其它新型工艺多为此三类工艺的改进版。其中,紫外纳米压印优势最为明显,是目前产业化最常见的方式,而微接触纳米压印则主要应用在生物化学领域。
对比不同分支技术,各有其优劣势,但以目前制程节点迭代情况,要满足愈发精细的微结构制造要求,均需进一步提高和改进,多技术路线必然使得产业化之路更为曲折。

按压印方式分类的纳米压印光刻技术路线,制图丨果壳硬科技
参考资料丨《纳米压印技术》[22]
关键技术一个没少
虽然纳米压印光刻工艺另辟蹊径,但它也绕不开光刻胶、涂胶、刻蚀等技术,其中,以光刻胶尤为困难,在纳米压印光刻中的光刻胶被称为纳米压印胶。
压印胶发展整体经历从热塑性压印胶、热固性压印胶到紫外压印胶三个阶段,其中紫外压印胶是目前及将来的主流。从专利上来看,富士胶片在压印胶领域的技术储备非常雄厚,而国内掌握的专利则较少。
另外,对纳米压印来说,模板是器件成功的关键。不同于传统光学光刻使用的4X掩模,纳米压印光刻使用1X模版,会导致模具制作、检查和修复技术面临更大挑战。

纳米压印关键技术,制表丨果壳硬科技
参考资料丨《基于纳米压印技术的微纳结构制备研究》[31]
用起来也没那么简单
虽说相对光学光刻,纳米压印光刻的确简化了原理,但其中的门道却更多了。
传统的光学系统是在芯片表面均匀地形成光刻胶膜,纳米压印则需有针对地喷涂滴状压印胶,这个过程就像打印机喷墨一样,控制好力度并不容易。
压印过程中聚合物图形和掩膜间会进入空气,如同手机贴膜过程中混入气泡一般,纳米压印也会产生与掩膜不贴合的情况,一旦进入空气,就会成为残次品,无法正常工作。因此,在有些时候,压印出来的芯片看似一致,在纳米尺度却存在很大个体差异。为了解决上述问题, 会采取与光学光刻完全相反的方法,即压印瞬间对芯片局部加热,使纳米级形变过程中能严丝合缝地贴合掩膜。不过,实际生产过程更复杂,除了空气,任何细小的灰尘都会威胁产品的成品率。
多数纳米压印技术均需脱模这一工序,而模板和聚合物间具有较强粘附性,因此,行业时常会在模板表面蒸镀一层纳米级厚度的抗黏附材料,以便轻松脱模。就像是制作蛋糕过程中垫一层油纸或刷一层油一样,蛋糕脱模才会更顺利更完整。只不过,虽然这样能解决脱模的问题,但固化后的聚合物避免不了与抗黏附材料发生物理摩擦,缩短模板寿命。
此外,尽管目前纳米压印技术已在大批量生产取得巨大进步,但在模板制造、结构均匀性与分辨率、缺陷率控制、模板寿命、压印胶材料、复杂结构制备、图型转移缺陷控制、抗蚀剂选择和涂铺方式、模具材料选择和制作工艺、模具定位和套刻精度、多层结构高差、压印过程精确化控制等方面仍存在挑战。
可以说,发展纳米压印光刻需要抛弃过去固有的经验和常识,重新探索一套方法论,这需要大量的研发与市场试错。
有希望,但需要时间
现阶段,已有许多产品在使用纳米压印技术生产,包括LED、OLED、AR设备、太阳能电池、传感器、生物芯片、纳米光学器件、纳米级晶体管、存储器、微流控、抗反射涂层或薄膜、超疏水表面、超滤膜等[14],但这项技术还没有进入大规模生产阶段。
目前,日本的佳能(Canon)、奥地利的EV Group、美国得克赛斯州的Molecular Imprints Inc.、美国新泽西州的Nanonex Corp、瑞典的Obducat AB、德国的SUSS MicroTec等公司已出产纳米压印光刻设备,一些纳米压印光刻设备已支持15nm。
纳米压印市场没有想象中那样大,但整体正逐渐走强。TechNavio数据显示,2026年纳米压印市场有望达到33亿美元,2021年至2026年年复合增长率可达17.74%。
纳米压印光刻的潜力也被全球各国所认可,不仅被普林斯顿大学、德克萨斯大学、哈佛大学、密西根大学、林肯实验室、德国亚琛工业大学等知名大学和机构大力推进,ASML(阿斯麦)、台积电、三星、摩托罗拉、惠普等龙头也持续看好纳米压印光刻的前景,一直在默默加大投入。

全球纳米压印光刻设备提供商不完全统计,制表丨果壳硬科技
参考资料丨《信息记录材料》[33]
虽然国内起步晚,但在纳米压印光刻的研发上也存在诸多玩家,其中不乏科研机构和公司,包括复旦大学、北京大学、南京大学、吉林大学、西安交通大学、上海交通大学、苏州大学、华中科技大学、中科院北京纳米能源与系统研究所、中科院苏州纳米技术与纳米仿生研究所、上海纳米技术研究发展中心、苏州苏大维格科技集团股份有限公司、苏州昇印光电(昆山)股份有限公司、苏州光舵微纳科技股份有限公司等。
对国产来说,纳米压印光刻会是可行之路吗,或许能在专利上看到一些趋势。
据智慧芽数据,以纳米压印和光刻同时作为关键词搜索,在170个国家/地区共有1660条专利。从走势来看,2007年~2011年是近20内热度最高的几年,此后在专利申请上逐步放缓。而对应的,此时纳米压印行业正处于膨胀期,此后进入低谷期,直到2020年后产业进入成熟期。

纳米压印光刻技术趋势,图源丨智慧芽
从专利国家分布上来看,美国包揽了全球45.1%的纳米压印光刻专利,共699个;而中国虽然位列第二,但专利总数却不足美国的二分之一,占比为全球专利总数的16.26%;日本和韩国则在专利数量上分别位列第三和第四,分别占全球专利总数的13.35%和10.13%。

纳米压印光刻技术来源国/地区排名,图源丨智慧芽
从中、美、欧、日、韩五大局的专利流向上来看,美国的纳米压印光刻技术布局分布全球市场,而中国的专利技术则缺乏中国以外的市场。

纳米压印光刻五局流向图,图源丨智慧芽
从公司来看,分子压模公司(Molecular Imprints Inc.)的纳米压印光刻专利数量遥遥领先,以135个专利位列第一;佳能(佳能株式会社和佳能纳米技术公司)和奥博杜卡特股份公司(Obducat AB)紧随其后,分别拥有132个和49个专利;此外,应用材料、三星、西部数据、信越化学等半导体龙头也有较强专利布局。

纳米压印光刻申请人排行图,图源丨智慧芽
需要指出的是,虽然国内专利总数较多,但整体申请较为分散,而国际上美日企业则集中度较高,单个公司专利数量大,国内后进者或面临专利墙风险。
从目前全世界进展来看,每隔几年都会有纳米压印光刻即将突破的消息,但每次又延后进入产业的时间。对国内来说,不仅要面对国际也难以解决的纳米亚印光刻在技术上的瓶颈,还要面对纳米压印光刻牵扯出来的配套工艺、设备、材料等问题。
一切信号都在诉说这项技术的不容易,但未来,当光学光刻难以向前时,纳米压印光刻将是最值得期待的路线,而那时,芯片制造或许也会迎来全新的范式,一切都会颠覆。
参考文献链接
https://mp.weixin.qq.com/s/DTfhrts1ozMzmoZsoeeLsw
https://mp.weixin.qq.com/s/MFEvHbMfAIk_hUMqJrCiYw
以上是关于纳米光刻与Nvidia冲击光刻技术分析的主要内容,如果未能解决你的问题,请参考以下文章
中国公布多项技术,光刻机和7纳米工艺都得到解决,外媒:挡不住了
日本佳能推出5纳米光刻机,国产光刻机却爆雷:弯道超车失败了?
ASML最后的倔强,不愿失去中国市场,继续供应28纳米光刻机
苹果再次舍弃3纳米,对ASML是沉重打击,ASML得靠中国救命了