python 使用ElementTree解析xml
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 使用ElementTree解析xml相关的知识,希望对你有一定的参考价值。
以country.xml为例,内容如下:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
1.解析
1)调用parse()方法,返回解析树
python3.3之后ElementTree模块会自动寻找可用的C库来加快速度
try: import xml.etree.cElementTree as ET except ImportError: import xml.etree.ElementTree as ET tree = ET.parse("country.xml") # <class ‘xml.etree.ElementTree.ElementTree‘> root = tree.getroot() # 获取根节点 <Element ‘data‘ at 0x02BF6A80>
2)调用from_string(),返回解析树的根元素
import xml.etree.ElementTree as ET data = open("country.xml").read() root = ET.fromstring(data) # <Element ‘data‘ at 0x036168A0>
3)调用ElementTree类ElementTree(self, element=None, file=None)
import xml.etree.ElementTree as ET tree = ET.ElementTree(file="country.xml") # <xml.etree.ElementTree.ElementTree object at 0x03031390> root = tree.getroot() # <Element ‘data‘ at 0x030EA600>
2.遍历
1)简单遍历
import xml.etree.ElementTree as ET tree = ET.parse("country.xml") root = tree.getroot() print(root.tag, ":", root.attrib) # 打印根元素的tag和属性 # 遍历xml文档的第二层 for child in root: # 第二层节点的标签名称和属性 print(child.tag,":", child.attrib) # 遍历xml文档的第三层 for children in child: # 第三层节点的标签名称和属性 print(children.tag, ":", children.attrib)
可以通过下标的方式直接访问节点
# 访问根节点下第一个country的第二个节点year,获取对应的文本 year = root[0][1].text # 2008
2)ElementTree提供的方法
find(match) # 查找第一个匹配的子元素, match可以时tag或是xpaht路径findall(match) # 返回所有匹配的子元素列表findtext(match, default=None) #iter(tag=None) # 以当前元素为根节点 创建树迭代器,如果tag不为None,则以tag进行过滤iterfind(match) #
例子:
# 过滤出所有neighbor标签 for neighbor in root.iter("neighbor"): print(neighbor.tag, ":", neighbor.attrib)
# 遍历所有的counry标签 for country in root.findall("country"): # 查找country标签下的第一个rank标签 rank = country.find("rank").text # 获取country标签的name属性 name = country.get("name") print(name, rank)
3.修改xml结构
1) 属性相关
# 将所有的rank值加1,并添加属性updated为yes for rank in root.iter("rank"): new_rank = int(rank.text) + 1 rank.text = str(new_rank) # 必须将int转为str rank.set("updated", "yes") # 添加属性 # 再终端显示整个xml ET.dump(root) # 注意 修改的内容存在内存中 尚未保存到文件中 # 保存修改后的内容 tree.write("output.xml")
import xml.etree.ElementTree as ET tree = ET.parse("output.xml") root = tree.getroot() for rank in root.iter("rank"): # attrib为属性字典 # 删除对应的属性updated del rank.attrib[‘updated‘] ET.dump(root)
小结: 关于class xml.etree.ElementTree.Element 属性相关
- attrib 为包含元素属性的字典
keys() 返回元素属性名称列表- items() 返回(name,value)列表
get(key, default=None) 获取属性set(key, value) # 跟新/添加 属性- del xxx.attrib[key] # 删除对应的属性
2) 节点/元素 相关
删除子元素remove()
import xml.etree.ElementTree as ET tree = ET.parse("country.xml") root = tree.getroot() # 删除rank大于50的国家 for country in root.iter("country"): rank = int(country.find("rank").text) if rank > 50: # remove()方法 删除子元素 root.remove(country) ET.dump(root)
添加子元素
代码:
import xml.etree.ElementTree as ET tree = ET.parse("country.xml") root = tree.getroot() country = root[0] last_ele = country[len(list(country))-1] last_ele.tail = ‘\\n\\t\\t‘ # 创建新的元素, tag为test_append elem1 = ET.Element("test_append") elem1.text = "elem 1" # elem.tail = ‘\\n\\t‘ country.append(elem1) # SubElement() 其实内部调用的时append() elem2 = ET.SubElement(country, "test_subelement") elem2.text = "elem 2" # extend() elem3 = ET.Element("test_extend") elem3.text = "elem 3" elem4 = ET.Element("test_extend") elem4.text = "elem 4" country.extend([elem3, elem4]) # insert() elem5 = ET.Element("test_insert") elem5.text = "elem 5" country.insert(5, elem5) ET.dump(country)
效果:

添加子元素方法总结:
append(subelement)extend(subelements)insert(index, element)
4.创建xml文档
想创建root Element,然后创建SubElement,最后将root element传入ElementTree(element),创建tree,调用tree.write()方法写入文件
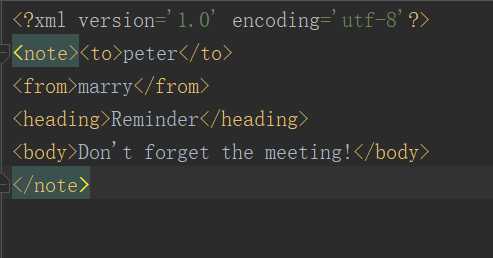
import xml.etree.ElementTree as ET def subElement(root, tag, text): ele = ET.SubElement(root, tag) ele.text = text ele.tail = ‘\\n‘ root = ET.Element("note") subElement(root, "to", "peter") subElement(root, "from", "marry") subElement(root, "heading", "Reminder") subElement(root, "body", "Don‘t forget the meeting!") tree = ET.ElementTree(root) tree.write("note.xml", encoding="utf-8", xml_declaration=True)
效果:
以上是关于python 使用ElementTree解析xml的主要内容,如果未能解决你的问题,请参考以下文章
使用 ElementTree 示例在 Python 中解析 XML
python解析xml文件之xml.etree.cElementTree和xml.etree.ElementTree区别