Python 爬虫-BeautifulSoup
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 爬虫-BeautifulSoup相关的知识,希望对你有一定的参考价值。
2017-07-26 10:10:11
Beautiful Soup可以解析html 和 xml 格式的文件。
Beautiful Soup库是解析、遍历、维护“标签树”的功能库。使用BeautifulSoup库非常简单,只需要两行代码,就可以完成BeautifulSoup类的创建,这里命名为soup,接下来就可以对soup进行相关处理了。一个BeautifulSoup类对应html或者xml的全部内容。
BeautifulSoup库将任意html文件转换成utf-8格式

一、解析器
BeautifulSoup类创建的时候第二个参数是解析器,上面的代码中用的解析器为‘html.parser’,BeautifulSoup支持的解析器有:

二、BeautifulSoup类的基本元素


- 使用soup.tag来访问一个标签的内容,如:soup.title;soup.a等,这里的返回值为访问标签的第一个出现的值
- 使用soup.tag.name可以得到当前标签的名字,返回值为字符串,如:soup.a.name 会返回字符串 ‘a’,也可以使用soup.a.parent.name来查看 a 标签父母的名字
- 使用soup.tag.attrs可以得到当前标签的属性,返回值为一个字典,如果没有属性会返回一个空字典,如:soup.a.attrs 会返回 a 标签的属性信息
- 使用soup.tag.string可以得到当前标签的字符串,如:soup.a.string 会返回 a 标签的内容字符串
- 内容字符串有两种类型一是NavigableString类型,一种是Comment类型,Comment类型的格式是<p> <!-- This is an comment --></p>,在调用soup.p.string是会返回This is an comment,但是其类型是Comment类型。
三、soup的内容遍历
标签树的遍历有三种方式,即下行遍历,上行遍历和平行遍历。
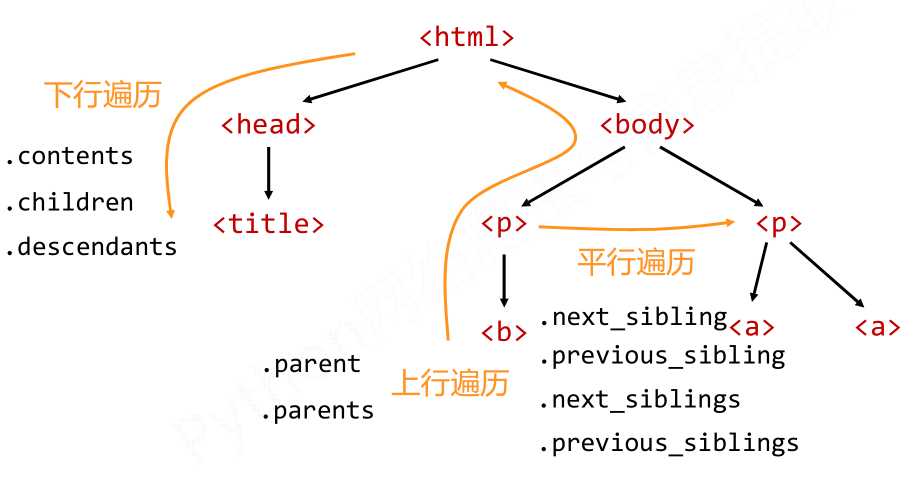
(1)下行遍历属性

举例:
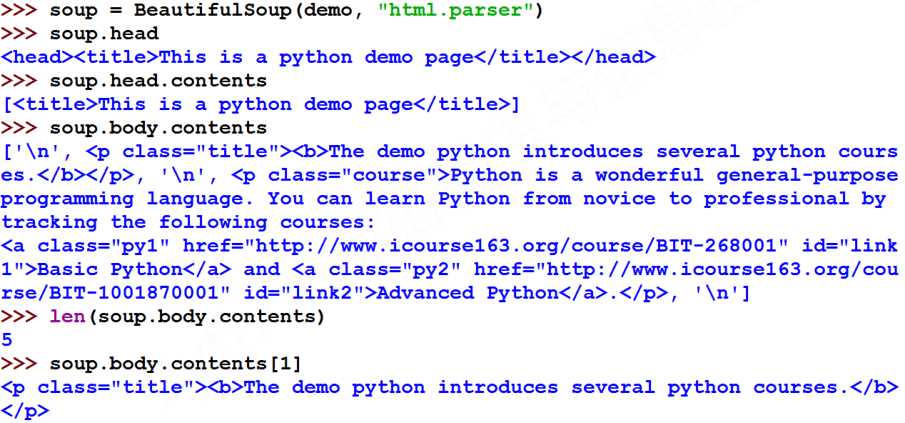
#遍历儿子节点 for child in soup.body.children: print(child) #遍历子孙节点 for child in soup.body.descendants: print(child)
值得注意的是子孙节点不仅包含标签,还包含标签之间的字符串类型,这点需要注意与排除。
(2)上行遍历的属性

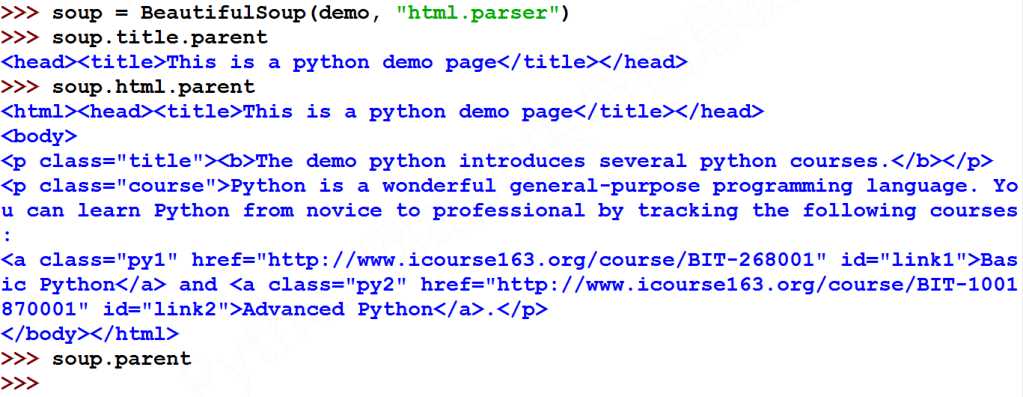
soup.parent为空,需要进行区分,可以使用for循环对parents进行遍历:

(3)平行遍历的属性
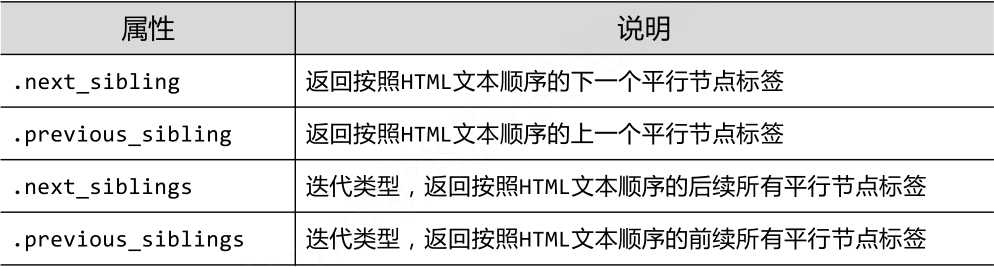
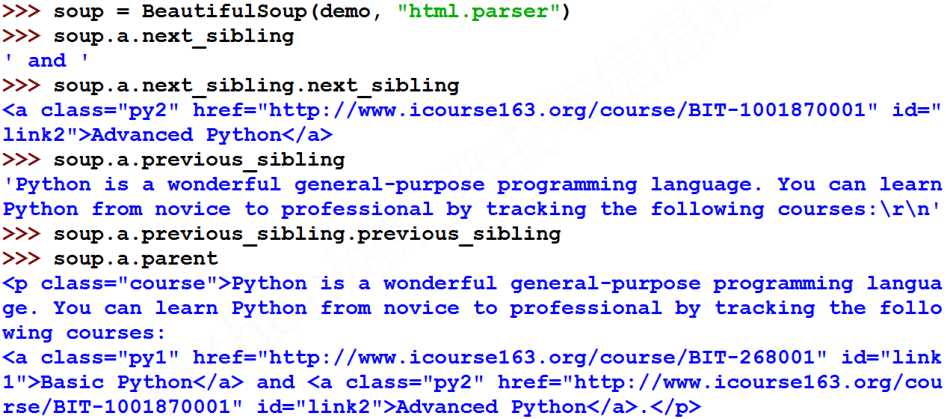
#遍历后续节点 for sibling in soup.a.next_sibling: print(sibling) #遍历前续节点 for sibling in soup.a.previous_sibling: print(sibling)
以上是关于Python 爬虫-BeautifulSoup的主要内容,如果未能解决你的问题,请参考以下文章