R语言独立成分分析fastICA谱聚类支持向量回归SVR模型预测商店销量时间序列可视化
Posted 大数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言独立成分分析fastICA谱聚类支持向量回归SVR模型预测商店销量时间序列可视化相关的知识,希望对你有一定的参考价值。
全文链接:http://tecdat.cn/?p=31948
原文出处:拓端数据部落公众号
本文利用R语言的独立成分分析(ICA)、谱聚类(CS)和支持向量回归 SVR 模型帮助客户对商店销量进行预测。首先,分别对商店销量的历史数据进行了独立成分分析,得到了多个独立成分;其次,利用谱聚类方法将商店销量划分成了若干类,并将每个类的特征进行了提取;最后,利用 SVR模型对所有的商店销量进行预测。实验结果表明,利用 FastICA、 CS和 SVR模型能够准确预测商店销量。
读取数据
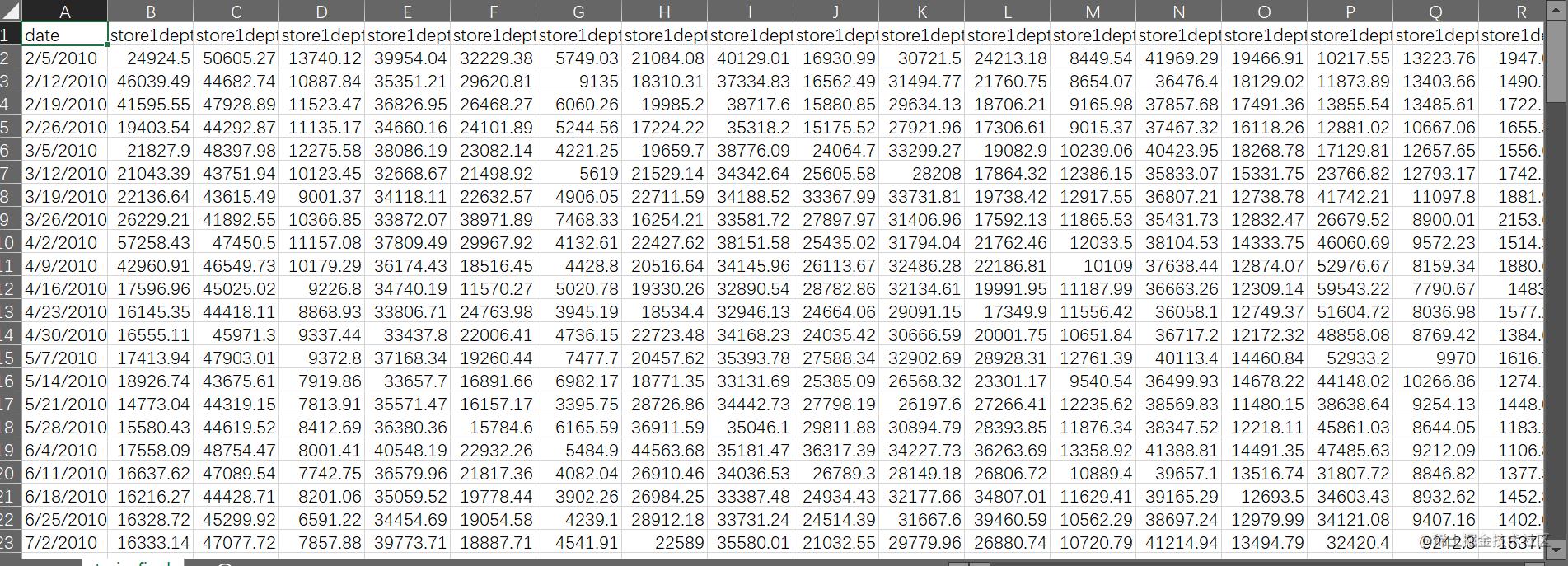
read.csv("train_final.csv")
head(data)

独立成分分析方法(fastICA)
首先对于d维的随机变量 x∈Rd×1 ,我们假设他的产生过程是由相互独立的源 s∈Rd×1 ,通过 A∈Rd×d 线性组合产生的x=As
如果s的服从高斯分布的,那么故事结束,我们不能恢复出唯一的s,因为不管哪个方向都是等价的。而如果s是非高斯的,那么我们希望找到w从而 s=wTx ,使得 s 之间的相互独立就可以恢复出s了,我将在后面指出,这等价于最大化每个 s 的非高斯性。
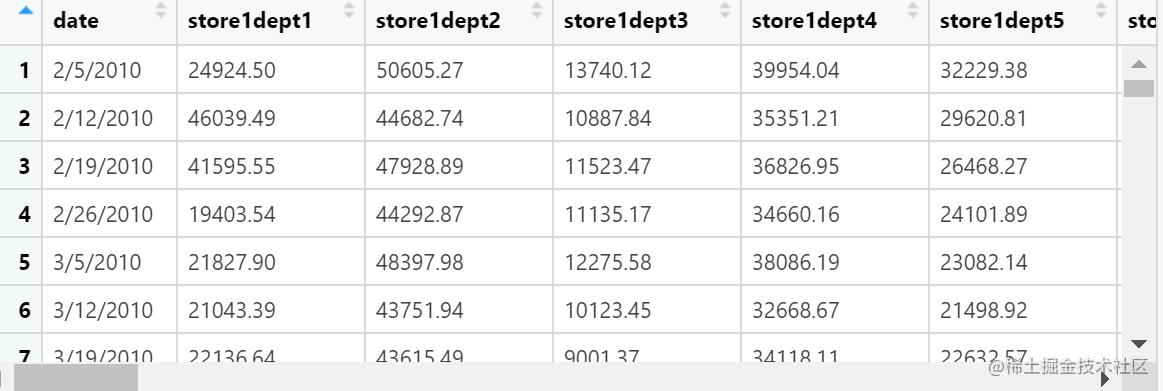
采用独立成分分析方法(fastICA),得到矩阵W,A和ICs等独立成分结果(是否需要pca降维?)。
reeplot(prcomp(

谱聚类
谱聚类(spectral cluster),这里的谱指的是某个矩阵的特征值,该矩阵是什么,什么得来的,以及在聚类中的作用将会在下文解一一道来。谱聚类的思想来源于图论,它把待聚类的数据集中的每一个样本看做是图中一个顶点,这些顶点连接在一起,连接的这些边上有权重,权重的大小表示这些样本之间的相似程度。同一类的顶点它们的相似程度很高,在图论中体现为同一类的顶点中连接它们的边的权重很大,不在同一类的顶点连接它们的边的权重很小。于是谱聚类的最终目标就是找到一种切割图的方法,使得切割之后的各个子图内的权重很大,子图之间的权重很小。
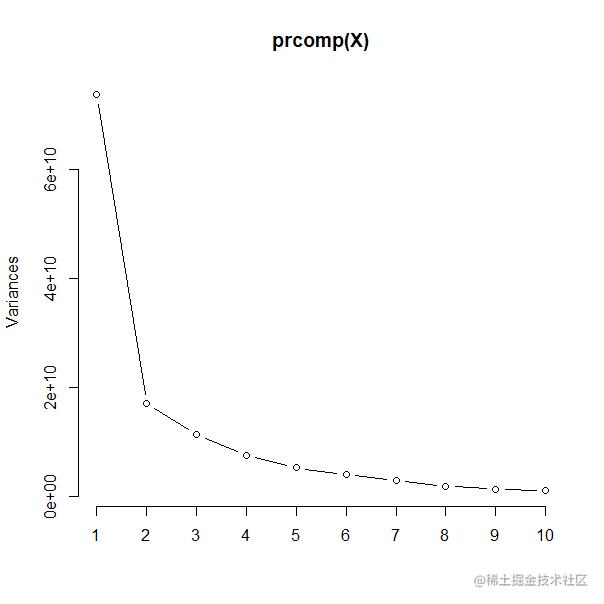
采用谱聚类方式对所有矩阵的列进行聚类,得到两到三种不同的聚类结果(如何)。
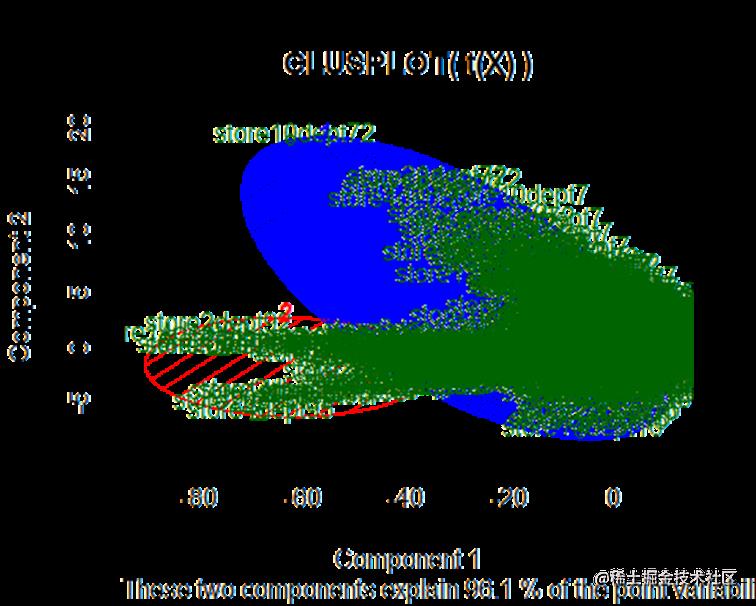
谱聚类聚成2个类别
sc <- spec
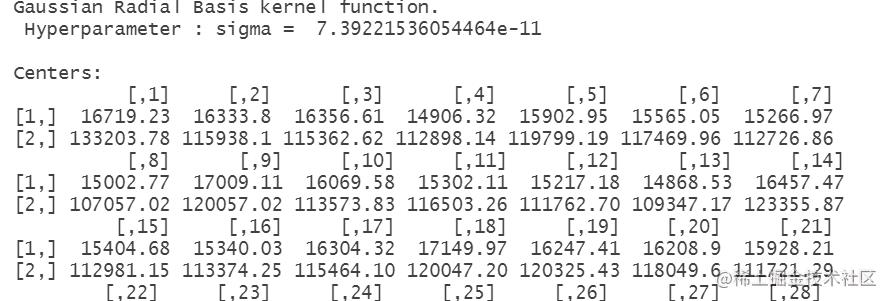
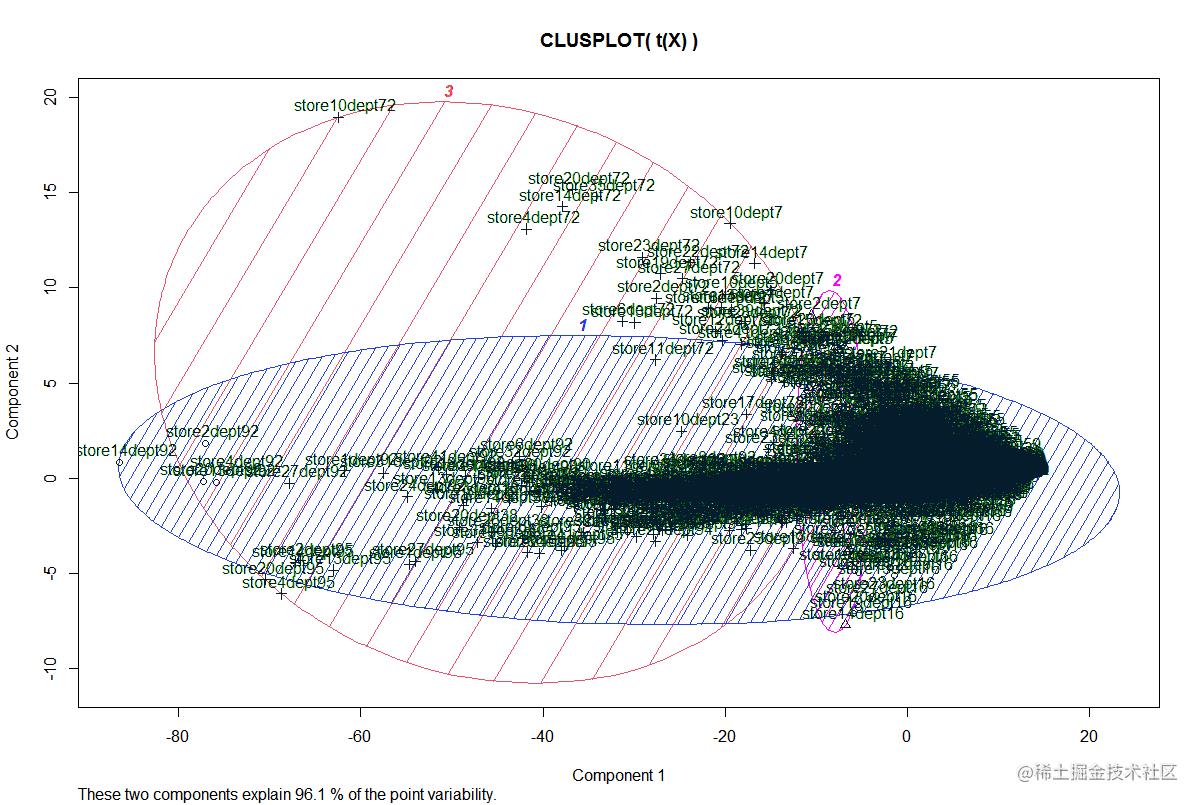
聚成3个类别
SVR模型
SVR是支持向量机(SVM)的重要应用分支。通过SVR算法,可以找到一个回归平面并使得一个集合中的所有数据距离该平面的距离最短。
使用场景
SVR是一个回归模型,主要是用于拟合数值,一般应用于特征较为稀疏且特征数较少的场景。
例如,可以使用SVR回归模型来预测某个城市的温度。输入特征有很多,例如这个城市某个时期的平均温度、绿化程度、湖泊数量以及日期等。训练数据可以是一段时间内的城市温度。
对所有数据采用log标准化处理,然后对不同的类的训练集分别采用SVR模型训练,再用测试集得到测试结果
所需结果:
k个不同模式时间序列图(分属不同类的某个部门时间序列),表征不同类之间的差异与同类之内的相似.
pre=SVRModel
不同类测试集所采用SVR模型的不同参数(C,ε,σ)。

不同类测试集所采用SVR模型之后的预测结果(RMSE,MAD,MAPE,MPE),
RMSE(test,yHat)
## [1] 0.1354805
MAE(test,yHat)
## [1] 0.1109939
MAPE(test,yHat)
## [1] 1.099158
#MPE
ftsa::error(forecast =yHat, true = test, method = "mpe")
## [1] 1.099158
预测模型
预测模型加入时间序列向前1周,2周,3周,4周时的数据作为输入变量,采用不同聚类方式所得预测结果。
向前2周

不同类测试集所采用SVR模型之后的预测结果(RMSE,MAD,MAPE,MPE)
RMSE(test,yHat)
## [1] 0.09735726
MAE(test,yHat)
## [1] 0.0655883
MAPE(test,yHat)
## [1] 0.6538239
#MPE
ftsa::error(forecast =yHat, true = test, method = "mpe")
## [1] 0.467259

最受欢迎的见解
2.R语言基于温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图
3.R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
5.Python Monte Carlo K-Means聚类实战
7.R语言KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化
8.PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯模型和KMEANS聚类用户画像
以上是关于R语言独立成分分析fastICA谱聚类支持向量回归SVR模型预测商店销量时间序列可视化的主要内容,如果未能解决你的问题,请参考以下文章