Python基础day04:内置函数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础day04:内置函数相关的知识,希望对你有一定的参考价值。
一、内置函数表格
1、表格

二、内置函数详情
1、abs(x)
功能:取数的绝对值
|
1
2
|
>>> abs(-1) #取-1的绝对值1 |
2、all(iterable)
功能:如果这个可迭代的元素都为真,则返回真(非0的就为真,负数也是为真)
|
1
2
3
4
|
>>> all([0,1,3]) #有0,说明为假False>>> all([1,-5,6]) #负数也是为真True |
3、any(iterable)
功能:可迭代的元素中,有一个为真,则返回真,空列表返回假。
|
1
2
3
4
|
>>> any([0,1,2]) #有一个为真,则为真True>>> any([]) #空列表为假False |
4、ascii(object)
功能:把内存对象变成一个可打印的字符串格式
|
1
2
|
>>> ascii([1,2,3,4])‘[1, 2, 3, 4]‘ |
5、bin(x)
功能:把一个整数转换成二进制
|
1
2
3
4
|
>>> bin(300) #把300转换成二进制‘0b100101100‘>>> bin(1)‘0b1‘ |
6、bool([x])
功能:返回一个布尔值,空列表为假,不为空为真
|
1
2
3
4
5
6
|
>>> bool([]) #空列表False>>> bool([1,2]) #不为空列表True>>> bool([0])True |
7、bytearray[source[, encoding[, errors]]]
功能:字节数组,并且可以修改二进制的字节
|
1
2
3
4
5
6
|
>>> b = bytearray("abcd",encoding="utf-8") #声明一个字节数组>>> b[0] #打印第一个元素的ascii值,也就是‘a‘对应的ascii值97>>> b[0] = 100 #修改时,只能赋值对应字符的ascii值>>> bbytearray(b‘dbcd‘) #发现字节数组值被修改 |
8、bytes([source[, encoding[, errors]]])
功能:把字符串转换成字节
|
1
2
3
4
5
6
7
8
9
|
>>> b = bytes("abcd",encoding="utf-8") #声明字节>>> bb‘abcd‘>>> b[0] #访问到‘a‘字符对应的ASCII值97>>> b[0]=100 #不可以修改里面的值,不然会报错Traceback (most recent call last): File "<input>", line 1, in <module>TypeError: ‘bytes‘ object does not support item assignment |
9、callable(object)
功能:判断一个对象是否可以被调用,只有在后面有括号的,表示可以调用,比如:函数,类。
|
1
2
3
4
5
|
>>> callable([]) #列表后面不加括号False>>> def sayhi():pass #定义一个函数>>> callable(sayhi) #函数调用,后面需要加括号True |
10、chr(i)
功能:通过ascii的值,找到对应的字符
|
1
2
|
>>> chr(97)‘a‘ |
11、ord(c)
功能:根据字符,找到对应的ascii值
|
1
2
|
>>> ord(‘a‘)97 |
12、classmethod(function)
功能:类方法,这个到后续谈到类的时候再说。
13、compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1)
功能:用于把代码编译的一个过程,这个基本用不到
|
1
2
3
4
|
>>> code = """1+3/2*6""" >>> py_object = compile(code,‘‘,‘eval‘) #把代码转换为字符串>>> eval(py_object) #执行10.0 |
14、complex([real[, imag]])
功能:返回一个复数,我们几乎用不到。
|
1
2
|
>>> complex(‘1+2j‘)(1+2j) |
15、delattr(object, name)
功能:类那边使用的,先不care。
16、dict(**kwarg)、dict(mapping, **kwarg)、dict(iterable, **kwarg)
功能:返回一个字典
|
1
2
3
4
5
6
7
8
|
>>> dict() #定义一个字典{}>>> dict(name=‘zhangqigao‘,age=18) #传入非固定关键字参数{‘name‘: ‘zhangqigao‘, ‘age‘: 18}>>> dict([(‘name‘,‘zhangqigao‘),(‘age‘,18)]) #传入一个列表{‘name‘: ‘zhangqigao‘, ‘age‘: 18}>>> dict([[‘name‘,‘zhangqigao‘],[‘age‘,18]]) #传入一个列表{‘name‘: ‘zhangqigao‘, ‘age‘: 18} |
17、dir([object])
功能:看一个对象有哪些方法
|
1
2
3
4
5
6
7
8
|
>>> name = []>>> dir(name) #显示name下的所有的方法[‘__add__‘, ‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__delitem__‘, ‘__dir__‘, ‘__doc__‘,‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__gt__‘, ‘__hash__‘,‘__iadd__‘, ‘__imul__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__mul__‘, ‘__ne__‘,‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__reversed__‘, ‘__rmul__‘,‘__setattr__‘, ‘__setitem__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘append‘, ‘clear‘,‘copy‘, ‘count‘, ‘extend‘, ‘index‘, ‘insert‘, ‘pop‘, ‘remove‘, ‘reverse‘, ‘sort‘] |
18、divmod(a,b)
功能:地板除,获得一个元组,元组第一个元素是商,第二个元素是余数。
|
1
2
|
>>> divmod(5,2)(2, 1) #2是商,1是余数 |
19、enumerate(iterable,start=0)
功能:获取一个列表,列表中的每个元素都是一个元组,元组的第一个数是iterable的索引,第二个数是iterable的元素。
|
1
2
3
4
5
|
>>> seasons = [‘Spring‘, ‘Summer‘, ‘Fall‘, ‘Winter‘]>>> list(enumerate(seasons))[(0, ‘Spring‘), (1, ‘Summer‘), (2, ‘Fall‘), (3, ‘Winter‘)]>>> list(enumerate(seasons, start=1))[(1, ‘Spring‘), (2, ‘Summer‘), (3, ‘Fall‘), (4, ‘Winter‘)] |
20、eval(expression, globals=None, locals=None)
功能:把字典类型的字符串变成字典,把一个整数类型的字符变成int类型,或者加减乘除这种简单转换成表达式。
|
1
2
3
4
|
>>> eval(‘1‘) #字符类型转换成int类型1>>> eval("1+3/2*6") #字符串转换为表达式10.0 |
21、exec(object[, globals[, locals]])
功能:有语句的和复杂的语句的字符串转换成表达式
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
code = ‘‘‘def timmer(func): #timmer(test1) func=test1 def deco(*args,**kwargs): res = func(*args,**kwargs) #run test1() return res return deco@timmerdef test1(): print("in the test1") return "from the test1"res = test1()print(res)‘‘‘exec(code) #输出in the test1from the test1 |
22、filter(function, iterable)
功能:通过function过滤条件,去获取iterable中你想要的数据。
|
1
2
3
4
5
6
7
8
9
|
>>> res = filter(lambda n:n>5,range(10)) >>> res #得到一个迭代器<filter object at 0x0000000003093BE0>>>> for i in res: print(i)6789 |
23、map(function, iterable)
功能:对传入的每一个值进行处理,处理完了再返回,再把原来的结果覆盖掉。
|
1
2
3
4
5
6
7
8
9
10
|
>>> res = map(lambda n:n*2,range(5)) #n*2是处理方式>>> res<map object at 0x00000000031B4BE0>>>> for i in res: print(i)02468 |
24、reduce(function,iterable)
功能:把一组可迭代序列通过function函数操作,元素之间相加或者相乘操作。
|
1
2
3
4
5
6
7
|
>>> from functools import reduce>>> res = reduce(lambda x,y:x+y,range(10)) #x+y的值赋给x,rang(10)中的每个元素赋给y>>> res45>>> res = reduce(lambda x,y:x*y,range(1,10)) #x*y的值赋给x,rang(10)中的每个元素赋给y>>> res362880 |
25、float([x])
功能:把一个浮点类型的字符串转换为浮点类型的数据。
|
1
2
3
4
5
6
7
8
9
10
|
>>> float(‘+1.23‘)1.23>>> float(‘ -12345\\n‘)-12345.0>>> float(‘1e-003‘)0.001>>> float(‘+1E6‘)1000000.0>>> float(‘-Infinity‘)-inf |
26、format(value[, format_spec])
27、frozenset([iterable])
功能:把集合变成一个不可变的集合
|
1
2
3
4
5
6
7
8
9
10
|
>>> res = frozenset([1,2,3,4,3])>>> resfrozenset({1, 2, 3, 4}) #去重的,不可变的集合>>> dir(res) #没有可变的方法[‘__and__‘, ‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__dir__‘, ‘__doc__‘, ‘__eq__‘,‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__ne__‘, ‘__new__‘, ‘__or__‘, ‘__rand__‘, ‘__reduce__‘, ‘__reduce_ex__‘,‘__repr__‘, ‘__ror__‘, ‘__rsub__‘, ‘__rxor__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__str__‘, ‘__sub__‘,‘__subclasshook__‘, ‘__xor__‘, ‘copy‘, ‘difference‘, ‘intersection‘, ‘isdisjoint‘, ‘issubset‘,‘issuperset‘, ‘symmetric_difference‘, ‘union‘] |
注:set()是可变的
28、getattr(object, name[, default])
功能:这边是类那边的,后续再讲。
29、globals()
功能:返回当前这个python文件中的所有变量的key-value,变量是key,值是value
|
1
2
3
4
5
6
7
|
print(globals())#输出{‘__spec__‘: None, ‘__name__‘: ‘__main__‘, ‘__file__‘: ‘D:/PycharmProjects/pyhomework/day4/内置函数/内置函数.py‘, ‘__doc__‘: None, ‘__package__‘: None, ‘__loader__‘:<_frozen_importlib_external.SourceFileLoader object at 0x0000000000695B00>,‘__cached__‘: None, ‘__builtins__‘: <module ‘built |
注:可以判断一个文件中的变量是否存在,而globals()只能打印全局变量
30、hash(object)
功能:反射出一个对象的对应的hash值。
|
1
2
3
4
5
6
|
>>> hash(‘zhangqigao‘)2313972277536963491>>> hash(255)255>>> hash(‘a‘)6806508886604307842 |
这个有什么用呐?
先看下面的图:
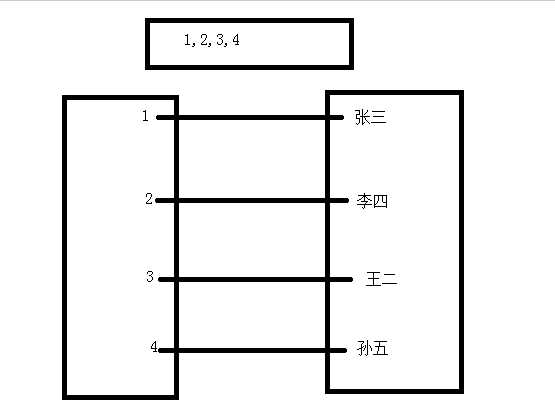
看上面的图我们知道,如果一张表中5百万个用户信息,以我们现在的知识,只能用for循环去查找,那样的话,效率会很低。那我们怎么办呢?我们可以这样,就是把每一个姓名对应有一对应的值,然后通过对应的key值去定位,key值是放在一个列表中,当我们去查找某个key值时,可以折半查找,这样大大减少了查找时间,提高效率,这种也叫二分法查找,后面会有对应的博客专门写这一块的。
内置函数三
31、help([object])
功能:显示对象的帮助信息
|
1
2
3
4
5
6
7
8
9
10
11
|
>>> res = [] #定义一个列表>>> help(res) #打印帮助信息Help on list object:class list(object) | list() -> new empty list | list(iterable) -> new list initialized from iterable‘s items | | Methods defined here: | ..... |
32、hex(x)
功能:把一个数字转成16进制
|
1
2
3
4
|
>>> hex(255)‘0xff‘>>> hex(10)‘0xa‘ |
33、id(object)
功能:返回对象的内存地址
|
1
2
|
>>> id(‘zhangqigao‘)50993136 #‘zhangqigao‘这个字符串的内存地址 |
34、input([prompt])
功能:输入字符串
|
1
2
3
4
|
>>> s = input(‘--> ‘) --> Monty Python‘s Flying Circus #输入的内容>>> s "Monty Python‘s Flying Circus" |
35、int(x)
功能:把其他数据类型强制转换成int类型
|
1
2
|
>>> int(‘10‘)10 |
36、isinstance(object, classinfo)
37、issubclass(class, classinfo)
功能:判断是否是一个子类,这个后续讲到类那边会讲
38、iter(object[, sentinel])
功能:把一个普通序列转成迭代器
|
1
2
3
|
with open(‘mydata.txt‘) as fp: for line in iter(fp.readline, ‘‘): process_line(line) |
39、len(s)
功能:计算序列或者字符串的长度
|
1
2
3
4
|
>>> len("zhangqigao") #字符串的长度10>>> len([1,2,3,4,5]) #列表的长度5 |
40、list([iterable])
功能:把其他序列转换成一个列表
|
1
2
|
>>> list((1,2,3,4,5)) #把一个元组转换为一个列表[1, 2, 3, 4, 5] |
41、locals()
功能:打印局部变量
|
1
2
3
4
5
6
7
8
9
10
11
|
def test(): locals_var = 333 print(locals()) #只打印局部变量test()print(globals().get("locals_var")) #只能打印全局变量#输出{‘locals_var‘: 333}None |
42、max(iterable, *[, key, default])
功能:返回列表重点额最大值
|
1
2
|
>>> max([1,2,3,4,5])5 |
43、min(iterable, *[, key, default])
功能:返回列表中的最小值
|
1
2
|
>>> min([1,2,3,4,5])1 |
44、memoryview(obj)
功能:先忘记它,暂时用不到,用到详细说明
45、next(iterator[, default])
功能:返回迭代器的下一个值,相当于__next__()方法,如果迭代最后一个数据之后没有值了,则会抛出一个StopIteration异常
|
1
2
3
4
5
6
7
8
9
|
>>> a = iter([1,2])>>> next(a)1>>> next(a)2>>> next(a)Traceback (most recent call last): File "<input>", line 1, in <module>StopIteration |
46、object
功能:python中一切皆对象,每一个对象都有它的属性和方法
47、oct(x)
功能:把一个数转成8进制
|
1
2
3
4
5
6
7
8
|
>>> oct(7)‘0o7‘>>> oct(8)‘0o10‘>>> oct(15)‘0o17‘>>> oct(16)‘0o20‘ |
48、open(file, mode=‘r‘, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
49、pow(x, y[, z])
功能:返回多少次幂
|
1
2
|
>>> pow(2,3) #相当于2**38 |
40、print(*objects, sep=‘ ‘, end=‘\\n‘, file=sys.stdout, flush=False)
功能:打印
|
1
2
|
>>> print("zhangqigao")zhangqigao |
41、property(fget=None, fset=None, fdel=None, doc=None)
功能:这个倒后面的类再说。
42、range(stop)、range(start, stop[, step])
功能:生成一个迭代器
|
1
2
3
4
5
6
|
>>> range(5)range(0, 5)>>> range(1,5)range(1, 5)>>> range(1,5,2)range(1, 5, 2) |
43、repr(object)
功能:把代码转成字符串对象,没什么用,这边忽略
44、reversed(seq)
功能:反转一个序列,跟列表中的reversed方法是一样的
|
1
2
3
4
5
6
7
8
9
10
|
>>> reversed([1,2,3,4,5])<list_reverseiterator object at 0x00000000030A2588> #变成一个迭代器>>> for i in reversed([1,2,3,4,5]):... print(i)... 54321 |
45、round(number[, ndigits])
功能:保留float数据类型位数
|
1
2
|
>>> round(1.23344,2) #保留两位1.23 |
46、set([iterable])
功能:集合,详细请见:猛击这里
47、setattr(object, name, value)
功能:这个是讲到类那边才用到的
48、slice(stop),slice(start, stop[, step])
功能:序列的切片
|
1
2
3
4
5
|
>>> a = [1,2,3,4,5,6]>>> a[slice(1,3)][2, 3]>>> a[1:3][2, 3] |
49、sorted(iterable[, key][, reverse])
功能:对一个序列进行排序
|
1
2
3
4
5
6
7
8
9
|
>>> sorted([5,3,2,6,8])[2, 3, 5, 6, 8]>>> a = {1:5,6:8,3:6}>>> sorted(a) #默认是按key排序[1, 3, 6]>>> sorted(a.items()) #按key排序[(1, 5), (3, 6), (6, 8)]>>> sorted(a.items(),key = lambda x:x[1]) #按value排序[(1, 5), (3, 6), (6, 8)] |
50、 str(object)
功能:把其他数据类型转换为字符串
|
1
2
|
>>> str(1)‘1‘ |
51、sum(iterable[, start])
功能:求一个列表的和
|
1
2
|
>>> sum([1,2,3,4,5,6])21 |
52、super([type[, object-or-type]])
功能:这个是类的继承,后续会讲
53、tuple([iterable])
功能:把其他序列转换为一个元组
|
1
2
|
>>> tuple([1,2,3,4,5])(1, 2, 3, 4, 5) |
54、type(object) 、type(name, bases, dict)
功能:查看一个对象的数据类型
|
1
2
3
|
>>> a = ‘zhangqigao‘>>> type(a)<class ‘str‘> |
注:一切数据类型都是有type()方法产生,它是一切数据类型的根。
55、vars([object])
功能:返回对象的所有属性
56、zip(*iterables)
功能:zip中文意思是拉链的意思,把两个序列一一对应起来。
|
1
2
3
4
5
6
7
8
9
|
>>> a = [1,2,3,4]>>> b=[‘a‘,‘b‘,‘c‘,‘d‘]>>> for i in zip(a,b):... print(i)... (1, ‘a‘)(2, ‘b‘)(3, ‘c‘)(4, ‘d‘) |
注:如果a的元素比b的多,则按照元素最少的那个来
57、__import__(name, globals=None, locals=None, fromlist=(), level=0)
功能:当导入的模块是一个字符串时,用__import__()
|
1
2
3
|
>>> import os>>> __import__(‘os‘) <module ‘os‘ from ‘D:\\\\Python\\\\Python35\\\\lib\\\\os.py‘> |
以上是关于Python基础day04:内置函数的主要内容,如果未能解决你的问题,请参考以下文章