python爬虫之中文编码问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫之中文编码问题相关的知识,希望对你有一定的参考价值。
python编码是个博大精深的知识,而我还是出血python,所以我目前所要求自己的仅仅是在自己的爬取网页获取中文信息时不会出错,仅此而已,对于其他更深层次的内容随着知识的积累想必有更深刻的理解。以下并不是我的原创理解,而是在网上查阅很多博主有想法更直观的表达后自己才能对这些编码有更直认识,感谢他们
首先附上中文编码比较,更直观的显示出不同编码对文字输出的影响
编译环境是wingide win8.1
输入#-*- coding:utf-8 -*-
s=‘ab我是中文字符串‘
ss=u‘ab我是中文字符串‘
u=s.decode(‘utf-8‘)
print s
print repr(s)
print ss
print repr(ss)
print u
print repr(u)
输出
ab鎴戞槸涓枃瀛楃涓?‘ab\\xe6\\x88\\x91\\xe6\\x98\\xaf\\xe4\\xb8\\xad\\xe6\\x96\\x87\\xe5\\xad\\x97\\xe7\\xac\\xa6\\xe4\\xb8\\xb2‘
ab我是中文字符串
u‘ab\\u6211\\u662f\\u4e2d\\u6587\\u5b57\\u7b26\\u4e32‘
ab我是中文字符串
u‘ab\\u6211\\u662f\\u4e2d\\u6587\\u5b57\\u7b26\\u4e32‘
由上可以知道当输入时utf-8格式编码的时候,输出文字为乱码,而输入时unicode时输出不会乱码
而且decode是解码,而decode(utf-8(源网页的编码格式))的目的就是将原网页的编码格式转化成unicode然后输入,使中文不会乱码
而encode是解码,跟上面的作用相反
另外介绍一个chardet命令,使用这个命令可以让你知道源网页的编码是什么,然后再进行解码就好了,问题完美解决。
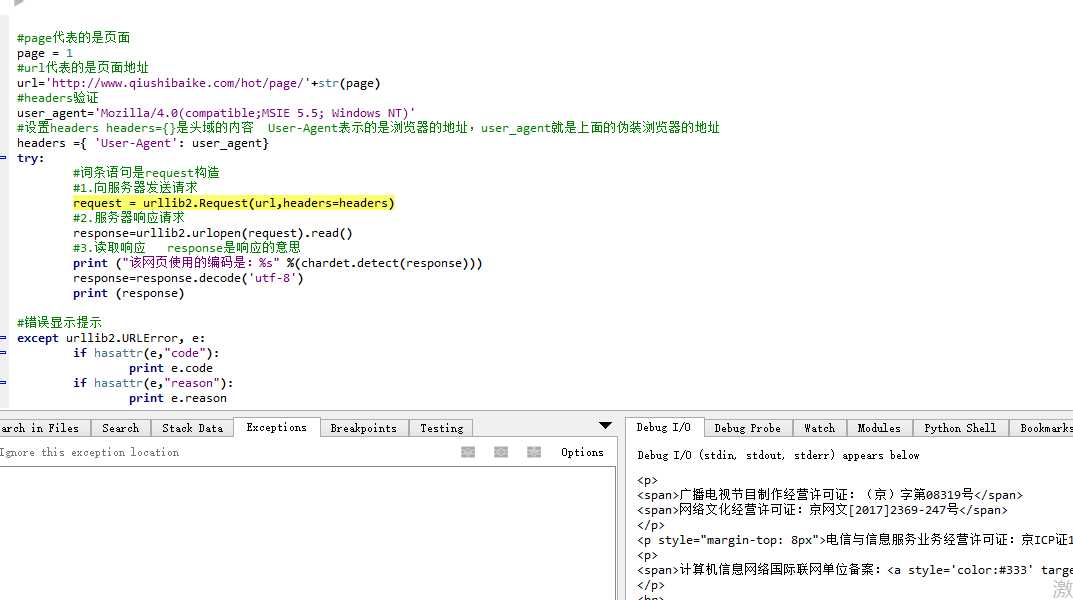
以上是关于python爬虫之中文编码问题的主要内容,如果未能解决你的问题,请参考以下文章