python爬虫之字体反爬
Posted 人生如梦,亦如幻
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫之字体反爬相关的知识,希望对你有一定的参考价值。
一、什么是字体反爬?
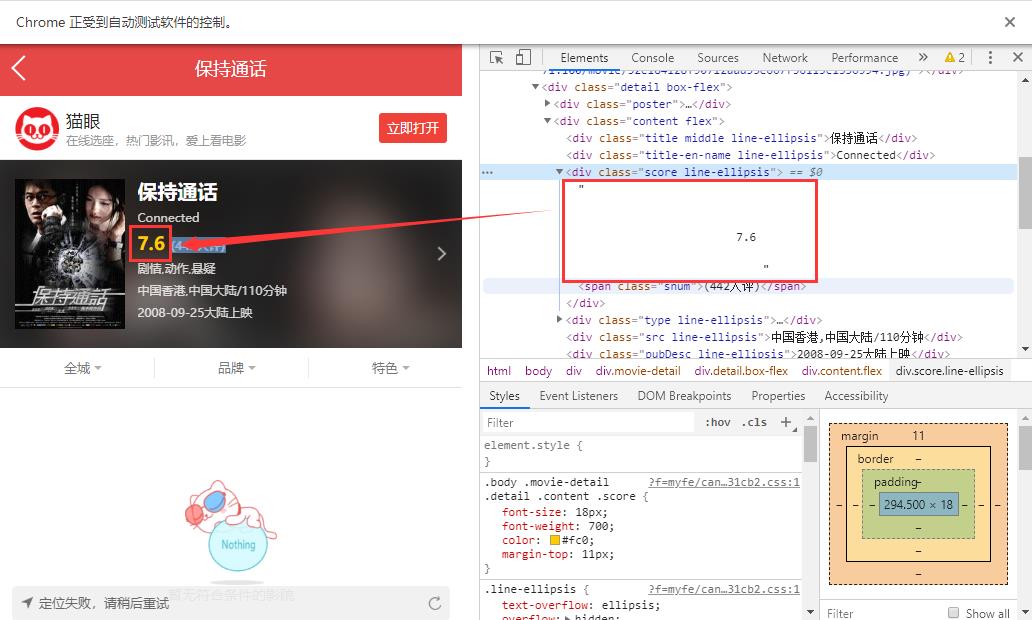
字体反爬就是将关键性数据对应于其他Unicode编码,浏览器使用该页面自带的字体文件加载关键性数据,正常显示,而当我们将数据进行复制粘贴、爬取操作时,使用的还是标准的Unicode字符映射,解析后就是干扰性数据,以猫眼电影为例:
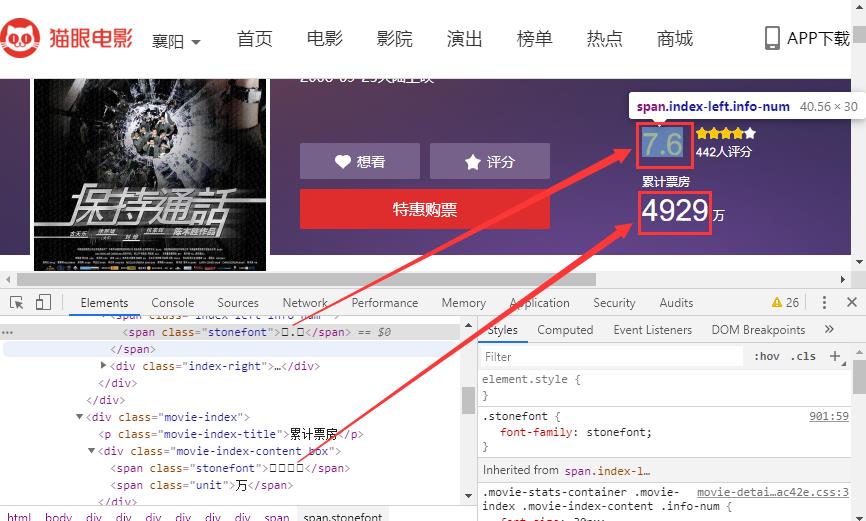
上图表明,浏览器正常渲染的数据在调试界面显示为错误的数据,即使我们复制粘贴也是这样(猜测复制粘贴的是Unicode编码)显示,这样就起到了反爬的效果。
二、解决方案
1、找到对应的字体文件
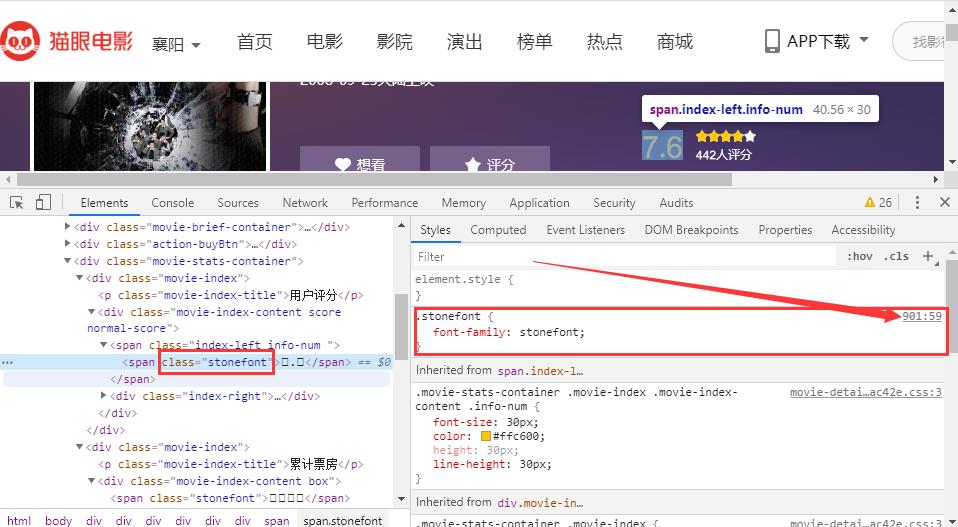
点击箭头指向的css文件
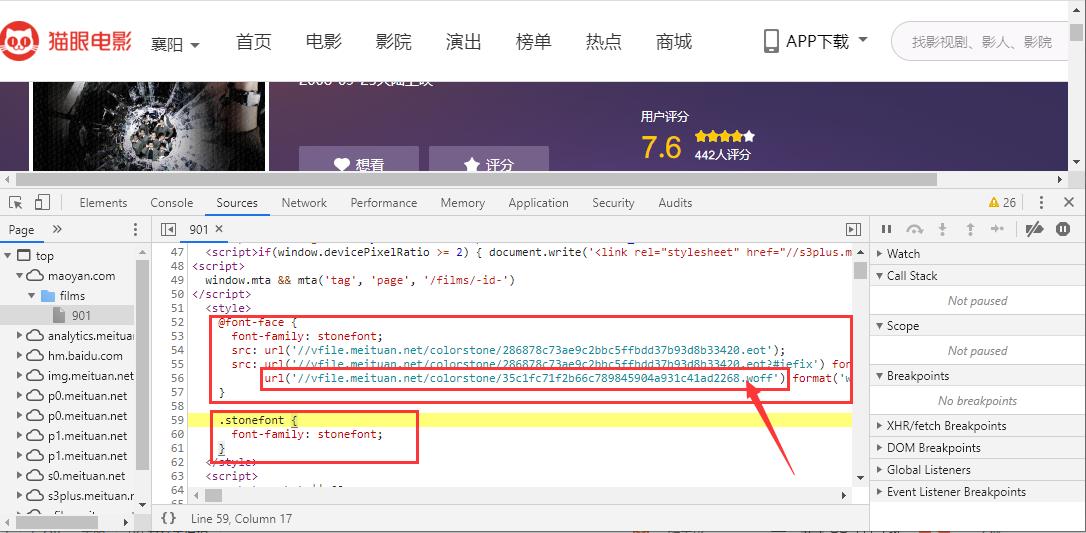
箭头指向的链接就是我们要寻找的字体文件,我们必须把这个字体文件下载下来进行分析,找到对应关系
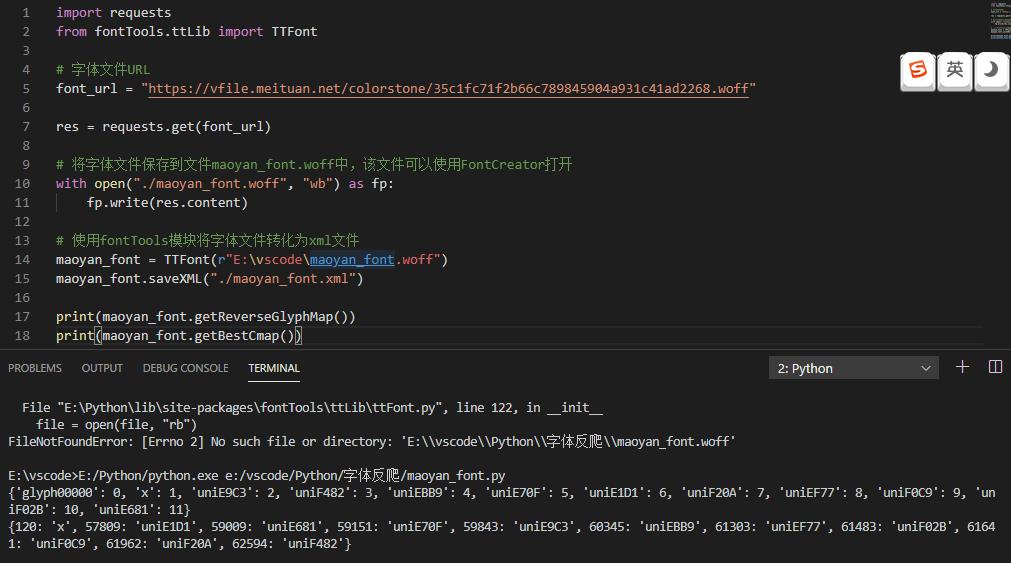
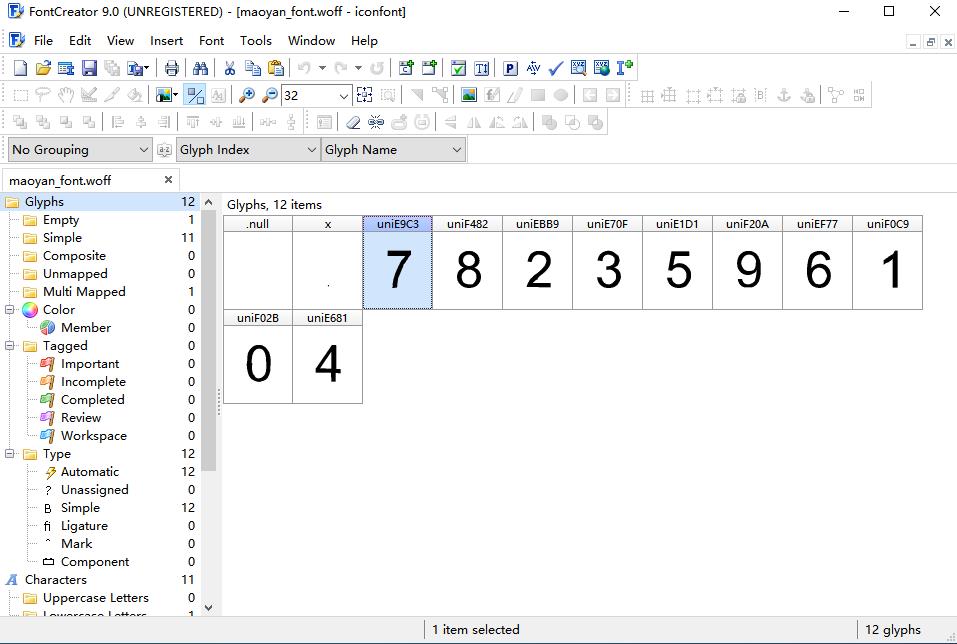
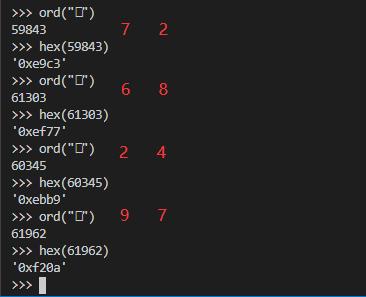
如果字体文件是固定的,我们可以手动分析,然后创建一个映射表就解决了,但是字体文件如果每请求一次就会变化,这种解决方式就不行了。
我们刷新一下链接,再下载一个字体文件对比一下,看是否变化了
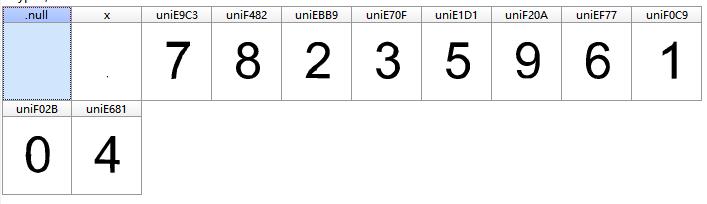
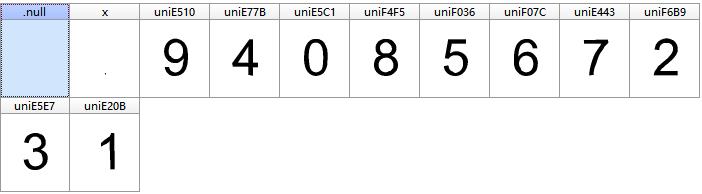
对比后,不难发现,字体文件完全不同了。
2、绕过字体反爬
目前为止,我爬过的数据从来源可以分为PC端数据、移动端Web数据和APP数据,既然PC端有字体反爬,我们可以从移动端尝试一下。
先从简单的移动端Web数据入手,可以先使用selenium,加一个手机浏览器的User-Agent,就可以在PC端浏览器显示与手机浏览器相同的效果,下图表示在移动端Web数据是没有使用字体反爬措施得。


1 from selenium import webdriver 2 from selenium.webdriver.support.wait import WebDriverWait 3 from selenium.webdriver.support import expected_conditions as EC 4 from selenium.webdriver.common.action_chains import ActionChains 5 from selenium.webdriver.common.by import By 6 import time 7 8 options = webdriver.ChromeOptions() 9 10 options.add_argument(\'User-Agent="Mozilla/5.0 (Linux; U; android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"\') 11 12 chrome = webdriver.Chrome(r"D:\\chromedriver_win32\\chromedriver.exe", options=options) 13 14 chrome.get("https://m.maoyan.com")
当我们分析完成后,我们就可以使用requests+lxml来编写爬虫了。
移动端APP数据也就是常说的手机APP爬虫,参照:https://www.cnblogs.com/loveprogramme/p/12209172.html
以上是关于python爬虫之字体反爬的主要内容,如果未能解决你的问题,请参考以下文章