python集合文件处理字符编码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python集合文件处理字符编码相关的知识,希望对你有一定的参考价值。
1. 集合操作 : 去重
{1, 2, 3, 4, 5, 6, 7, 8, 9}


1 list1 = [1,2,3,4,5,5,6,7,8,9] 2 list1 = set(list1) 3 print(list1)
1.1
集合语法里有个intersection是求两个集合之间的交集
1 list1 = [1,2,3,4,5,5,6,7,8,9] 2 list1 = set(list1) 3 print(list1) 4 5 list2 = set([0,1,2,3,44,44,55,555,666,7777]) 6 print(list1,list2) 7 8 list1.intersection(list2)#交集 9 print(list1.intersection(list2)) 10 11 结果是:{1, 2, 3}
1.2
集合语法里还有union并集的操作
1 list1.union(list2) 2 print(list1.union(list2)) 3 4 {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 7777, 555, 44, 55, 666} 5 结果讲两个集合中都打印出来了
1.3
集合中的差集
print(list1.difference(list2))#差集 意思是list1中有,但是list2中没有 {4, 5, 6, 7, 8, 9}
1.4
集合中的子集
1 #子集 2 print(list1.issubset(list2))#判断list1是不是list2的子集 3 False
1.5
集合的父集
1 print(list1.issuperset(list2))#判断list2是不是list1的父集 2 False
1.6
集合的对称差集
1 print(list1.symmetric_difference(list2))#反向差集 2 3 {0, 7777, 4, 5, 6, 7, 8, 9, 555, 44, 55, 666}#将两个集合中交集取反了
1.7若两个集合间没有交集
1 print(list1.isdisjoint(list2))#判断两个集合没有交集返回真
1.8
集合删除
1 print(list1.pop())#删除任意一个内容
1.9
discard
1 list1.discard(10)#删除元素时若不存在则不报错 2 {2, 3, 4, 5, 6, 7, 8, 9}
2.文件操作
1 You were the shadow to my light 2 你是我生命之光中的一道暗影 3 Did you feel us 4 你能理解我们吗 5 Another Star 6 另一颗行星 7 You fade away 8 你逐渐消失 9 Afraid our aim is out of sight 10 恐惧我们的目标迷失在视野 11 Wanna see us 12 希望我们互相理解 13 Alive 14 活着 15 Where are you now 16 你身在何方? 17 Where are you now 18 你身在何方? 19 Where are you now 20 你身在何方? 21 Was it all in my fantasy 22 难道这一切都在我的幻想里 23 Where are you now 24 你身在何方? 25 Were you only imaginary 26 你只是虚幻的不存在吗? 27 Where are you now 28 你身在何方? 29 Atlantis 30 亚特兰蒂斯 31 Under the sea 32 在海底 33 Under the sea 34 在海底 35 Where are you now 36 你身在何方? 37 Another dream 38 另外的梦想 39 The monster‘s running wild inside of me 40 狂野的怪兽驰聘在我心深处 41 I‘m faded 42 我憔悴不堪 43 I‘m faded 44 我憔悴不堪 45 So lost, I‘m faded 46 所以迷失,憔悴不堪 47 I‘m faded ~~~ 48 我憔悴不堪 49 So lost, I‘m faded 50 所以迷失,憔悴不堪 51 These shallow waters never met 52 那些从未见过的水中之影 53 What i needed 54 我需要的 55 I‘m letting go 56 只是顺其自然 57 A deeper dive 58 深沉海底 59 Eternal silence of the sea 60 无尽的沉默于海中 61 I‘m breathing 62 我的呼吸声 63 Alive. 64 活着 65 Where are you now 66 你身在何方? 67 Where are you now 68 你身在何方? 69 Under the bright but faded lights 70 明亮的灯光却已经黯然失色 71 You set my heart on fire 72 你点燃了我的心火 73 Where are you now 74 你身在何方? 75 Where are you now 76 你身在何方? 77 ... 78 ... 79 Where are you now 80 你身在何方? 81 Atlantis 82 亚特兰蒂斯 83 Under the sea 84 在海底 85 Under the sea 86 在海底 87 Where are you now 88 你身在何方? 89 Another dream 90 另外的梦想 91 The monster‘s running wild inside of me 92 狂野的怪兽驰聘在我心深处 93 I‘m faded 94 我憔悴不堪 95 I‘m faded 96 我憔悴不堪 97 So lost, I‘m faded 98 所以迷失,憔悴不堪 99 I‘m faded ~~~ 100 我憔悴不堪 101 So lost, I‘m faded
2.1.1 f = open(‘c‘)
print(f.readlines())#默认读出所有行,且一行显示出来,每句后面有个\\n
2.1.2 f = open(‘c‘)
print(f.read())#默认读出全部行
2.1.3
print(f.readline())#默认读出第一行
2.2 打开文件模式有以下几种
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
2.3 下面看下文件的一些常见用法
2.3.1
f = open(‘c‘)
print(f.encoding)#打印出编码格式UTF-8
print(f.readable())#判断文件是否可读 返回 True
使用flush功能请看:
1 import sys 2 import time 3 4 for i in range(10): 5 sys.stdout.write("#") 6 sys.stdout.flush() 7 time.sleep(1) 8 #每间隔一秒就打印出一个#号
f.truncate(15)#默认不写数字的话,会将全部的清空
2.3.2
f = open(‘c‘,‘w+‘,encoding="utf-8")
#r+即能读又能写 又名:读写
#w+ 写读 先创建一个文件,再往里写
#a+追加读
f.write("wo 是llll\\n")
f.write("wo 是lei\\n")
f.write("wo 是Leileilei\\n")
f.write("wo 是leileilei\\n")
print(f.tell())#打印当前光标所在位置
print(f.seek(10))#光标跳会到某一位置
f.write("could i working python? tell me ? why not?")
f.close()
2.3.3文件修改
1 #以下代码实现改动文件中某一字符 2 f = open(‘c‘,‘r‘,encoding="utf-8")#首先我们从一个文件中读,相当于源文件 3 f_new = open(‘d‘,‘w‘,encoding="utf-8")#创建一个新的文件,将替换后的文件写到该文件中 4 # Old_Str 5 for line in f:#循环读源文件 6 if "多肆意的快乐" in line:#判断字符"多肆意的快乐"在不再每行中 7 line = line.replace("多肆意的快乐","多痛苦的折磨")#将源文件中字符替换, 8 f_new.write(line)#写到新创建的文件中 执行后会产生一个新的文件,且是已经替换好的字符
3. 字符编码详解
需知:
1.在python2默认编码是ASCII, python3里默认是utf-8
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-8就是unicode
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
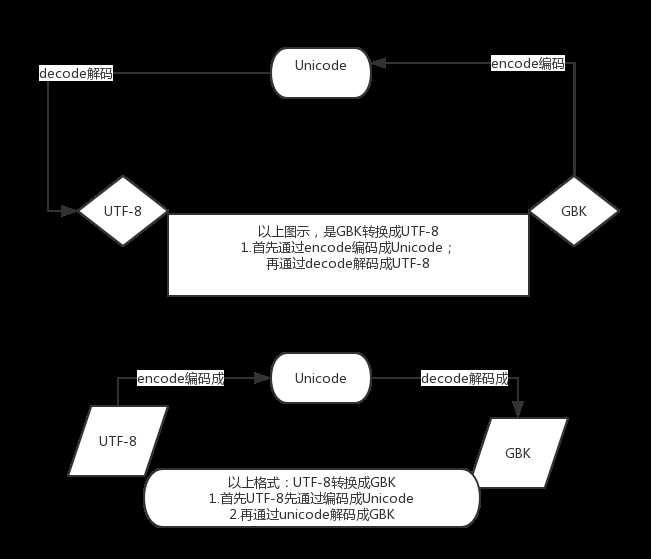
理解该图后再遇到字符编码就不用慌张了。
以上是关于python集合文件处理字符编码的主要内容,如果未能解决你的问题,请参考以下文章