python cookbook第三版学习笔记二:字典
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python cookbook第三版学习笔记二:字典相关的知识,希望对你有一定的参考价值。
一般来说字典中是一个键对应一个单值的映射,如果想一个键值映射多个值,那么就需要将这些值放到另外的容器中,比如列表或者集合。
比如d={‘a‘:[1,2]}
Collections中的defaultdict模块会自动创建这样的字典。如下
d=defaultdict(list)
d[‘a‘].append(1)
d[‘a‘].append(2)
d[‘b‘].append(3)
defaultdict(<type ‘list‘>, {‘a‘: [1, 2], ‘b‘: [3]})
下面再来看下字典的排序
d={}
d[‘foo‘]=1
d[‘bar‘]=2
d[‘span‘]=3
d[‘grok‘]=4
print d
for key in d:
print key,d[key]
输出:
{‘span‘: 3, ‘foo‘: 1, ‘bar‘: 2, ‘grok‘: 4}
span 3
foo 1
bar 2
grok 4
可以看到无论是直接打印d还是遍历d,输出的值都是无序的。和数据的写入的顺序无关。那么OrderedDict可以生成根据键插入顺序的字典。
d=OrderedDict()
d[‘foo‘]=3
d[‘bar‘]=2
d[‘spam‘]=4
print d
for key in d:
print key,d[key]
输出:
OrderedDict([(‘foo‘, 3), (‘bar‘, 2), (‘spam‘, 4)])
foo 3
bar 2
spam 4
可以看到遍历字典的时候是根据键值生成顺序来排序的。是因为OrderedDict内部是生成一个链表的形式,新增加的元素都放到链表末端
字典的最大值最小值计算
a={}
a[‘foo‘]=3
a[‘bar‘]=2
a[‘spam‘]=4
print max(a)
这个比较结果是将字段的键值进行比较,然后输出一个最大值。如果要根据值来取最大,最小值,可以用max(a.values())的方法。如果要进一步反馈出对应的键值。可以用zip函数先将字典的键和值进行反转。
max(zip(a.values(),a.keys()))
zip函数的作用是将括号的参数形成一个tuple列表。通过翻转以后。列表中value在前,键值在后。因此进行比较的时候首先比较值。输出如下:
(4, ‘spam‘)
找到一个序列中出现次数最多的元素:
经常在字符处理和文本处理中会遇到找次数最多的元素。如果一个个的去遍历太耗时间。这里可以用collections.Counter来达到这个目的
words=[‘look‘,‘info‘,‘my‘,‘look‘,‘into‘,‘eys‘,‘my‘,‘eyes‘,‘the‘,‘look‘,‘around‘,‘eyes‘,‘the‘,‘eys‘]
word_count=Counter(words)
print word_count
print word_count[‘look‘]
结果如下:
Counter({‘look‘: 3, ‘eyes‘: 2, ‘eys‘: 2, ‘the‘: 2, ‘my‘: 2, ‘info‘: 1, ‘into‘: 1, ‘around‘: 1})
3
从结果中可以看出,Counter就是将字符串做成了一个字典的形式,依次列出了各个元素出现的次数,并且是降序排列。从Counter的定义来看,可以看出也是继承自dict的
class Counter(dict):
另外可以认为的改变出现的次数word_count[‘look‘]+=1。这个时候look的次数就会变成4次,但是实际打印原字符串还是原来的字符串。
words=[‘look‘,‘info‘,‘my‘,‘look‘,‘into‘,‘eys‘,‘my‘,‘eyes‘,‘the‘,‘look‘,‘around‘,‘eyes‘,‘the‘,‘eys‘]
c=word_count=Counter(words)
word_count[‘look‘]+=1
print words
print word_count[‘look‘]
[‘look‘, ‘info‘, ‘my‘, ‘look‘, ‘into‘, ‘eys‘, ‘my‘, ‘eyes‘, ‘the‘, ‘look‘, ‘around‘, ‘eyes‘, ‘the‘, ‘eys‘]
4
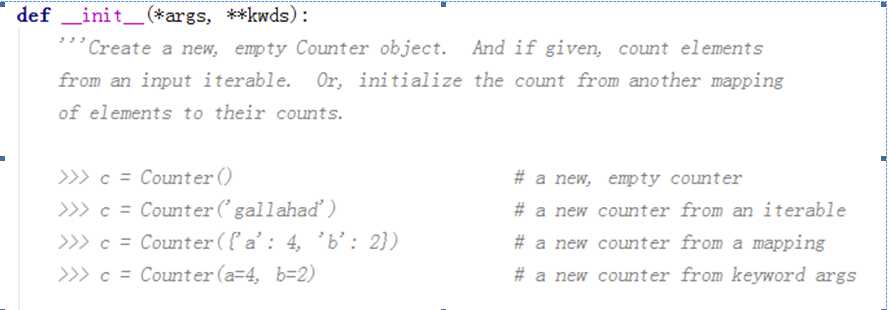
这是怎么回事呢。我们首先来看下Counter的初始化说明:可以看到__init__是创建一个新的空的counter对象。如果有输入则通过输入进行元素的初始化
words=[‘look‘,‘info‘,‘my‘,‘look‘,‘into‘,‘eys‘,‘my‘,‘eyes‘,‘the‘,‘look‘,‘around‘,‘eyes‘,‘the‘,‘eys‘]
c=word_count=Counter(words)
d=[e for e in c.elements()]
print d
print words
wo打印如下,可以看到除了顺序被改变之外,元素都一样的
[‘info‘, ‘eyes‘, ‘eyes‘, ‘look‘, ‘look‘, ‘look‘, ‘into‘, ‘eys‘, ‘eys‘, ‘the‘, ‘the‘, ‘my‘, ‘my‘, ‘around‘]
[‘look‘, ‘info‘, ‘my‘, ‘look‘, ‘into‘, ‘eys‘, ‘my‘, ‘eyes‘, ‘the‘, ‘look‘, ‘around‘, ‘eyes‘, ‘the‘, ‘eys‘]
现在回到我们之前的问题word_count[‘look‘]+=1 后words并没有被改变。那么被改变的肯定是新生成的对象。那么测试一下:
words=[‘look‘,‘info‘,‘my‘,‘look‘,‘into‘,‘eys‘,‘my‘,‘eyes‘,‘the‘,‘look‘,‘around‘,‘eyes‘,‘the‘,‘eys‘]
c=word_count=Counter(words)
word_count[‘look‘]+=1
d=[e for e in c.elements()]
print d
输出结果如下,可以看到确实增加了一个look。证明了后续的操作都是新增对象上进行操作的。
[‘info‘, ‘eyes‘, ‘eyes‘, ‘look‘, ‘look‘, ‘look‘, ‘look‘, ‘into‘, ‘eys‘, ‘eys‘, ‘the‘, ‘the‘, ‘my‘, ‘my‘, ‘around‘]
我们再来看另外一个update的用法。同样的我们首先看下这个函数的定义说明
Add counts instead of replace them。意思是将一个元素增加到新增的元素上面

word_count.update(words)
d=[e for e in c.elements()]
print d
print c
结果如下。可以看到是将words添加到了c这个新对象中去。因此计数也在之前的基础上增加了2倍
[‘info‘, ‘info‘, ‘eyes‘, ‘eyes‘, ‘eyes‘, ‘eyes‘, ‘look‘, ‘look‘, ‘look‘, ‘look‘, ‘look‘, ‘look‘, ‘into‘, ‘into‘, ‘eys‘, ‘eys‘, ‘eys‘, ‘eys‘, ‘the‘, ‘the‘, ‘the‘, ‘the‘, ‘my‘, ‘my‘, ‘my‘, ‘my‘, ‘around‘, ‘around‘]
Counter({‘look‘: 6, ‘eyes‘: 4, ‘eys‘: 4, ‘the‘: 4, ‘my‘: 4, ‘info‘: 2, ‘into‘: 2, ‘around‘: 2})
在看Counter的源代码的时候,注意到还有下面的数学运算功能:
def __add__(self, other):
def __sub__(self, other):
这意味着可以在对象上进行加,减操作
words1=[‘abc‘,‘def‘]
words2=[‘ghi‘,‘jkm‘,‘abc‘]
a=Counter(words1)
b=Counter(words2)
print a+b
print a-b
输出结果如下:想减则意味着去掉重复的元素
Counter({‘abc‘: 2, ‘jkm‘: 1, ‘ghi‘: 1, ‘def‘: 1})
Counter({‘def‘: 1})
通过某个关键字对字典进行排序:
可以采用itemgetter的方法。代码如下。用sorted进行排序,并设置比较关键参数key=itemgetter()
from operator import itemgetter
rows=[{‘fname‘:‘Brian‘,‘lname‘:‘Jones‘,‘uid‘:1003},
{‘fname‘:‘David‘,‘lname‘:‘Beazley‘,‘uid‘:1002},
{‘fname‘:‘John‘,‘lname‘:‘Cleeze‘,‘uid‘:1001},
{‘fname‘:‘Big‘,‘lname‘:‘Jones‘,‘uid‘:1004}]
rows_by_uid=sorted(rows,key=itemgetter(‘uid‘))
rows_by_name=sorted(rows,key=itemgetter(‘fname‘))
print rows_by_uid
print rows_by_name

我们来看下这个函数是如何工作的。首先我们用lambda来改造下这个功能
rows_by_uid1=sorted(rows,key=lambda r:r[‘uid‘])
print rows_by_uid1。可以看到得到的结果和sorted(rows,key=itemgetter(‘uid‘))是一样的

证明可以用lambda是可以达到同样的效果。首先sorted函数是接受一个可迭代的对象,然后从rows中接受一个单一的元素.如rows[0],rows[1],rows[2],rows[3]各个字典。这个字典传入itemgetter,并根据传入的参数返回字典的值。从下面的定义可以更好的理解。

其实可以用列表本身的sort函数也是可以达到同样的效果:
rows.sort(key=lambda r:r[‘uid‘])
print rows

两种方法的速度谁更快一点呢,其实如果数据不多的话,都差不多。数据量大的话网上推荐用itemgetter。
下面来看另外一个列子,对于实例中的参数进行排序:
class user():
def __init__(self,id):
self.userid=id
def __repr__(self):
return ‘user({})‘.format(self.userid)
UE=[user(23),user(46),user(12)]
print UE
print sorted(UE,key=attrgetter(‘userid‘))
结果如下:

这里用到了attrgetter。通过下面的介绍我们可以看到这个主要是从实例中取出关键数据

下面再来看下对字典进行分类的函数:
数据如下,如果想按照date函数进行归类,也就是相同date的归为一类
rows = [
{‘address‘: ‘5412 N CLARK‘, ‘date‘: ‘07/01/2012‘},
{‘address‘: ‘5148 N CLARK‘, ‘date‘: ‘07/04/2012‘},
{‘address‘: ‘5800 E 58TH‘, ‘date‘: ‘07/02/2012‘},
{‘address‘: ‘2122 N CLARK‘, ‘date‘: ‘07/03/2012‘},
{‘address‘: ‘5645 N RAVENSWOOD‘, ‘date‘: ‘07/02/2012‘},
{‘address‘: ‘1060 W ADDISON‘, ‘date‘: ‘07/02/2012‘},
{‘address‘: ‘4801 N BROADWAY‘, ‘date‘: ‘07/01/2012‘},
{‘address‘: ‘1039 W GRANVILLE‘, ‘date‘: ‘07/04/2012‘},
]
rows.sort(key=itemgetter(‘date‘))
for date,item in groupby(rows,itemgetter(‘date‘)):
print date
for i in item:
print i
结果如下,可以看到同样的日期被归成了一类
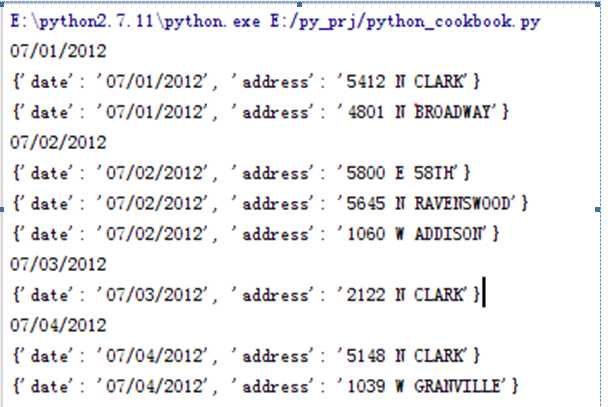
Groupby通过查找连续相同的值,并返回值相同的对象。这里有一点需要注意,因为groupby是查找连续的值,所以要想得到想要的结果。必须先排序,如果不排序的话,得到的结果则是错误的。下面就是未排序的结果。从结果中明显可以看出groupby是查找连续相同的值来归类的。由于未排序,导致结果是零散的。
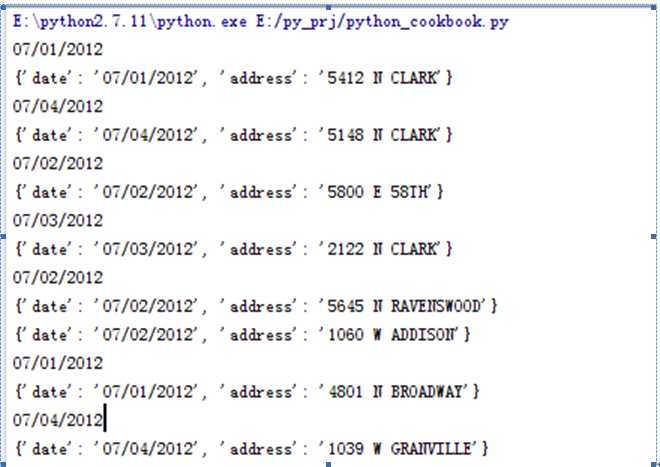
其实groupby就是一个归类函数,可以理解为同一个字典键值映射多个值。我们是否可以用前面介绍的defaultdict来构造呢。答案是可以的,因为dafaultdict可以将键值相同的值归为一类,也可以实现groupby的功能
rows_by_date=defaultdict(list)
for row in rows:
print row
rows_by_date[row[‘date‘]].append(row)
print rows_by_date
E:\\python2.7.11\\python.exe E:/py_prj/python_cookbook.py
{‘date‘: ‘07/01/2012‘, ‘address‘: ‘5412 N CLARK‘}
defaultdict(<type ‘list‘>, {‘07/01/2012‘: [{‘date‘: ‘07/01/2012‘, ‘address‘: ‘5412 N CLARK‘}]})
{‘date‘: ‘07/04/2012‘, ‘address‘: ‘5148 N CLARK‘}
defaultdict(<type ‘list‘>, {‘07/01/2012‘: [{‘date‘: ‘07/01/2012‘, ‘address‘: ‘5412 N CLARK‘}], ‘07/04/2012‘: [{‘date‘: ‘07/04/2012‘, ‘address‘: ‘5148 N CLARK‘}]})
{‘date‘: ‘07/02/2012‘, ‘address‘: ‘5800 E 58TH‘}
defaultdict(<type ‘list‘>, {‘07/02/2012‘: [{‘date‘: ‘07/02/2012‘, ‘address‘: ‘5800 E 58TH‘}], ‘07/01/2012‘: [{‘date‘: ‘07/01/2012‘, ‘address‘: ‘5412 N CLARK‘}], ‘07/04/2012‘: [{‘date‘: ‘07/04/2012‘, ‘address‘: ‘5148 N CLARK‘}]})
{‘date‘: ‘07/03/2012‘, ‘address‘: ‘2122 N CLARK‘}
defaultdict(<type ‘list‘>, {‘07/02/2012‘: [{‘date‘: ‘07/02/2012‘, ‘address‘: ‘5800 E 58TH‘}], ‘07/01/2012‘: [{‘date‘: ‘07/01/2012‘, ‘address‘: ‘5412 N CLARK‘}], ‘07/04/2012‘: [{‘date‘: ‘07/04/2012‘, ‘address‘: ‘5148 N CLARK‘}], ‘07/03/2012‘: [{‘date‘: ‘07/03/2012‘, ‘address‘: ‘2122 N CLARK‘}]})
{‘date‘: ‘07/02/2012‘, ‘address‘: ‘5645 N RAVENSWOOD‘}
defaultdict(<type ‘list‘>, {‘07/02/2012‘: [{‘date‘: ‘07/02/2012‘, ‘address‘: ‘5800 E 58TH‘}, {‘date‘: ‘07/02/2012‘, ‘address‘: ‘5645 N RAVENSWOOD‘}], ‘07/01/2012‘: [{‘date‘: ‘07/01/2012‘, ‘address‘: ‘5412 N CLARK‘}], ‘07/04/2012‘: [{‘date‘: ‘07/04/2012‘, ‘address‘: ‘5148 N CLARK‘}], ‘07/03/2012‘: [{‘date‘: ‘07/03/2012‘, ‘address‘: ‘2122 N CLARK‘}]})
{‘date‘: ‘07/02/2012‘, ‘address‘: ‘1060 W ADDISON‘}
defaultdict(<type ‘list‘>, {‘07/02/2012‘: [{‘date‘: ‘07/02/2012‘, ‘address‘: ‘5800 E 58TH‘}, {‘date‘: ‘07/02/2012‘, ‘address‘: ‘5645 N RAVENSWOOD‘}, {‘date‘: ‘07/02/2012‘, ‘address‘: ‘1060 W ADDISON‘}], ‘07/01/2012‘: [{‘date‘: ‘07/01/2012‘, ‘address‘: ‘5412 N CLARK‘}], ‘07/04/2012‘: [{‘date‘: ‘07/04/2012‘, ‘address‘: ‘5148 N CLARK‘}], ‘07/03/2012‘: [{‘date‘: ‘07/03/2012‘, ‘address‘: ‘2122 N CLARK‘}]})
{‘date‘: ‘07/01/2012‘, ‘address‘: ‘4801 N BROADWAY‘}
defaultdict(<type ‘list‘>, {‘07/02/2012‘: [{‘date‘: ‘07/02/2012‘, ‘address‘: ‘5800 E 58TH‘}, {‘date‘: ‘07/02/2012‘, ‘address‘: ‘5645 N RAVENSWOOD‘}, {‘date‘: ‘07/02/2012‘, ‘address‘: ‘1060 W ADDISON‘}], ‘07/01/2012‘: [{‘date‘: ‘07/01/2012‘, ‘address‘: ‘5412 N CLARK‘}, {‘date‘: ‘07/01/2012‘, ‘address‘: ‘4801 N BROADWAY‘}], ‘07/04/2012‘: [{‘date‘: ‘07/04/2012‘, ‘address‘: ‘5148 N CLARK‘}], ‘07/03/2012‘: [{‘date‘: ‘07/03/2012‘, ‘address‘: ‘2122 N CLARK‘}]})
{‘date‘: ‘07/04/2012‘, ‘address‘: ‘1039 W GRANVILLE‘}
defaultdict(<type ‘list‘>, {‘07/02/2012‘: [{‘date‘: ‘07/02/2012‘, ‘address‘: ‘5800 E 58TH‘}, {‘date‘: ‘07/02/2012‘, ‘address‘: ‘5645 N RAVENSWOOD‘}, {‘date‘: ‘07/02/2012‘, ‘address‘: ‘1060 W ADDISON‘}], ‘07/01/2012‘: [{‘date‘: ‘07/01/2012‘, ‘address‘: ‘5412 N CLARK‘}, {‘date‘: ‘07/01/2012‘, ‘address‘: ‘4801 N BROADWAY‘}], ‘07/04/2012‘: [{‘date‘: ‘07/04/2012‘, ‘address‘: ‘5148 N CLARK‘}, {‘date‘: ‘07/04/2012‘, ‘address‘: ‘1039 W GRANVILLE‘}], ‘07/03/2012‘: [{‘date‘: ‘07/03/2012‘, ‘address‘: ‘2122 N CLARK‘}]})
这样我们可以轻松的通过下面的方式来进行查找某个日期的信息。
for i in rows_by_date[‘07/01/2012‘]:
print i

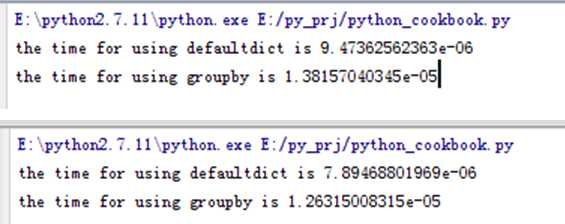
那么我们用哪一种方式更好呢。从时间效率上来看,groupby的方式更快一些,下面是做了一个时间上的对比,可以看到多次运行都是groupby占优
以上是关于python cookbook第三版学习笔记二:字典的主要内容,如果未能解决你的问题,请参考以下文章
python cookbook第三版学习笔记三:列表以及字符串
python cookbook第三版学习笔记四:文本以及字符串令牌解析
python cookbook第三版学习笔记十三:类和对象描述器