python简单爬数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python简单爬数据相关的知识,希望对你有一定的参考价值。
失败了,即使跟Firefox看到的headers,参数一模一样都不行,爬出来有网页,但是就是不给数据,尝试禁用了js,然后看到了cookie(不禁用js是没有cookie的),用这个cookie爬,还是不行,隔了时间再看,cookie的内容也并没有变化,有点受挫,但还是发出来,也算给自己留个小任务啥的
如果有大佬经过,还望不吝赐教
另外另两个网站的脚本都可以用,过会直接放下代码,过程就不说了
目标网站 http://www.geomag.bgs.ac.uk/data_service/models_compass/igrf_form.shtml
先解决一下date到decimal years的转换,仅考虑到天的粗略转换
def date2dy(year, month, day): months = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31] oneyear = 365 if year%100 == 0: if year%400 == 0: months[1] = 29 oneyear = 366 else: if year%4 == 0: months[1] = 29 oneyear = 366 days = 0 i = 1 while i < month: days = days + months[i] i = i + 1 days = days + day - 1 return year + days/366
第一个小目标是抓下2016.12.1的数据
打开FireFox的F12,调到网络一栏
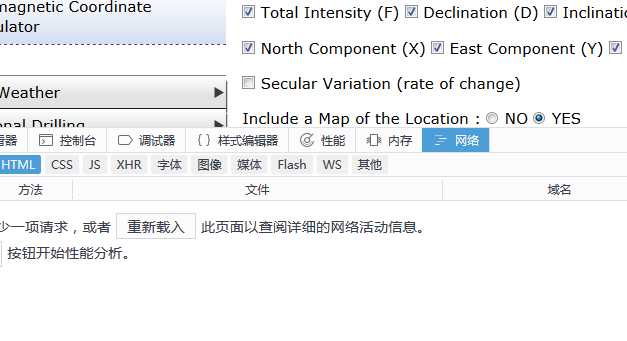
提交数据得到
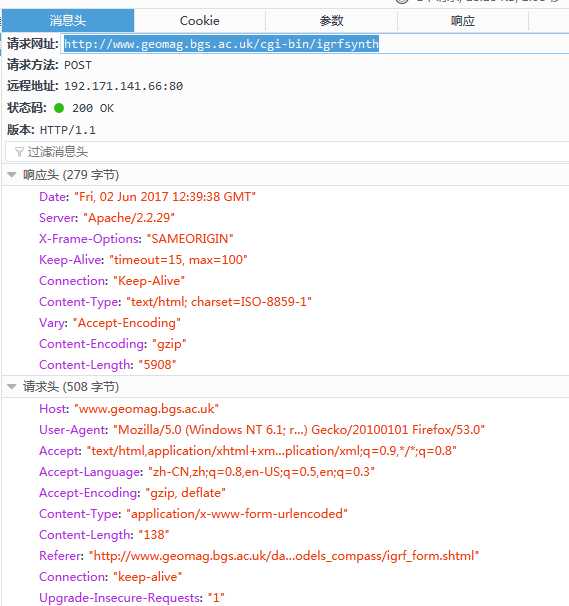
有用的信息是请求头,请求网址和参数,扒下来扔到程序里面试试
这块我试了大概一天多,抓不下来,我好菜呀.jpg
放下代码吧先,万一有大佬经过还望不吝赐教
#!usr/bin/python import requests import sys web_url = r‘http://www.geomag.bgs.ac.uk/data_service/models_compass/igrf_form.shtml‘ request_url = r‘http://www.geomag.bgs.ac.uk/cgi-bin/igrfsynth‘ filepath = sys.path[0] + ‘\\\\data_igrf_raw_‘ + ‘.html‘ fid = open(filepath, ‘w‘, encoding=‘utf-8‘) headers = { ‘Host‘: ‘www.geomag.bgs.ac.uk‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; rv:53.0) Gecko/20100101 Firefox/53.0‘, ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, ‘Accept-Language‘: ‘zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3‘, ‘Accept-Encoding‘: ‘gzip, deflate‘, ‘Content-Type‘: ‘application/x-www-form-urlencoded‘, ‘Content-Length‘: ‘136‘, ‘Referer‘: ‘http://www.geomag.bgs.ac.uk/data_service/models_compass/igrf_form.shtml‘, ‘Connection‘: ‘keep-alive‘, ‘Upgrade-Insecure-Requests‘: ‘1‘ } payload = { ‘name‘: ‘-‘, # your name and email address ‘coord‘: ‘1‘, # ‘1‘: Geodetic ‘2‘: Geocentic ‘date‘: ‘2016.92‘, # decimal years ‘alt‘: ‘150‘, # Altitude ‘place‘: ‘‘, ‘degmin‘: ‘y‘, # Position Coordinates: ‘y‘: In Degrees and Minutes ‘n‘: In Decimal Degrees ‘latd‘: ‘60‘, # latitude degrees (degrees negative for south) ‘latm‘: ‘0‘, # latitude minutes ‘lond‘: ‘120‘, # longitude degrees (degrees negative for west) ‘lonm‘: ‘0‘, # longitude minutes ‘tot‘: ‘y‘, # Total Intensity(F) ‘dec‘: ‘y‘, # Declination(D) ‘inc‘: ‘y‘, # Inclination(I) ‘hor‘: ‘y‘, # Horizontal Intensity(H) ‘nor‘: ‘y‘, # North Component (X) ‘eas‘: ‘y‘, # East Component (Y) ‘ver‘: ‘y‘, # Vertical Component (Z) ‘map‘: ‘0‘, # Include a Map of the Location: ‘0‘: NO ‘1‘: YES ‘sv‘: ‘n‘ } #如果需要Secular Variation (rate of change), 加上‘sv‘: ‘y‘ r = requests.post(request_url, data=payload, headers=headers) fid.write(r.text) fid.close();
以上是关于python简单爬数据的主要内容,如果未能解决你的问题,请参考以下文章
如何用30行代码爬取Google Play 100万个App的数据