aliyun-ons (node版)之 集群模式下模拟广播消费
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了aliyun-ons (node版)之 集群模式下模拟广播消费相关的知识,希望对你有一定的参考价值。
参考技术A MQ 是基于发布订阅模型的消息系统。 消息的订阅方订阅关注的 Topic,以获取并消费消息。 由于订阅方应用一般是分布式系统,以集群方式部署有多台机器。 因此 MQ 约定以下概念。集群:MQ 约定使用相同 Consumer ID 的订阅者属于同一个集群。同一个集群下的订阅者消费逻辑必须完全一致(包括 Tag 的使用),这些订阅者在逻辑上可以认为是一个消费节点。
集群消费:当使用集群消费模式时,MQ 认为任意一条消息只需要被集群内的任意一个消费者处理即可。
广播消费:当使用广播消费模式时,MQ 会将每条消息推送给集群内所有注册过的客户端,保证消息至少被每台机器消费一次
https://github.com/XadillaX/aliyun-ons
https://github.com/ali-sdk/ali-ons
我觉得看 aliyun-ons 这个就可以了
当集群的某个消费者接收到消息时,把消息的内容通过 redis 发布到某个频道, 集群中所有订阅到这个频道的,都会接收到消息, 从而实现了自己业务系统内的广播消费
湿货|大数据测试之hadoop单机环境搭建(超级详细版)
转发是对小编的最大支持
推荐
友情提示:本文超级长,请备好瓜子
Hadoop的运行模式
单机模式是Hadoop的默认模式,在该模式下无需任何守护进程,所有程序都在单个JVM上运行,该模式主要用于开发和调试mapreduce的应用逻辑;
伪分布式模式下,Hadoop守护进程运行在一台机器上,模拟一个小规模的集群。该模式在单机模式的基础上增加了代码调试的功能,允许你检查NameNode,DataNode,Jobtracker,Tasktracker等模拟节点的运行情况;
单机模式和伪分布式模式均用于开发和调试的目的,真实Hadoop集群的运行采用的是完全分布式模式
单机模式安装步骤
一个干净的linux基础环境(重要,这个环境如果有问题后续就全是问题了)
为了方便大家我已经安装好了一个,大家只需下载导入到vm里即可使用。
链接:https://pan.baidu.com/s/1qXRjaK8 密码:xjfk
关闭防火墙(适用于centos7,低版本不适用)
分别执行如下两条命令:
systemctl stop firewalld.service
systemctl disable firewalld.service
修改host name
vi /etc/hosts
然后把自己虚机的名字追加到两行的末尾,如果用的是我们提供的虚机,名字就是linux,追加之后的效果如图
重启网络:/etc/rc.d/init.d/network restart
设置无密码登录(用于hadoop启动)
cd ~ #进入当前用户的目录
mkdir -p /root/.ssh #我们用的root用户
cd ~/.ssh/
ssh-keygen -t rsa #如有提示,直接按回车 cat id_rsa.pub >> authorized_keys # 加入授权
安装jdk1.8并配置环境变量
tar解压
cp解压后的包到/usr/lib/java/(如果没有java目录就创建一下)
vi /etc/profile,末尾添加如下内容:
export JAVA_HOME=/usr/lib/java/jdk1.8.0_11
export JRE_HOME=/usr/lib/java/jdk1.8.0_11/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
执行source /etc/profile使得环境变量生效
验证是否成功,如下图

安装hadoop2.7.4
tar解压
cp解压后的包到/usr/lib/hadoop/(如果没有hadoop目录就创建一下)
设置hadoop-env.sh
vi /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/hadoop-env.sh
找到# The java implementation to use.这句话,在下面添加如下内容:
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/java/jdk1.8.0_11
export HADOOP_HOME=/usr/lib/hadoop/hadoop-2.7.4
export PATH=$PATH:/usr/lib/hadoop/hadoop-2.7.4/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
执行source /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/hadoop-env.sh,使得环境变量生效
验证是否成功,如下图

配置相关的xml文件
vi /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/core-site.xml(hadoop全局配置)
内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>
vi /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop/hdfs-site.xml(hdfs配置)
内容如下:
<configuration>
<!--指定hdfs保存数据的副本数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
cd /usr/lib/hadoop/hadoop-2.7.4/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml(MapReduce的配置)
内容如下:
<configuration>
<!--告诉hadoop以后MapReduce运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml(yarn配置)
内容如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<!--nomenodeManager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
格式化hdfs文件系统
初次运行hadoop时一定要有该操作,命令如下:
/usr/lib/hadoop/hadoop-2.7.4/bin/hadoop namenode -format
执行期间可能需要确认是否继续,如果有,就输入y回车即可
当你看到如下的内容时证明成功了

如果看到的是exiting with status 1,那么请运行如下命令,之后在进行hdfs的格式化
mkdir -pv /tmp/hadoop-root/dfs/name
启动hadoop(hdfs和yarn)
sh /usr/lib/hadoop/hadoop-2.7.4/sbin/start-all.sh
sh /usr/lib/hadoop/hadoop-2.7.4/sbin/stop-all.sh #停止
如果没有报错说明就成功了
使用jps命令查看进程,如果出现下面的内容就说明确定以及肯定成功啦
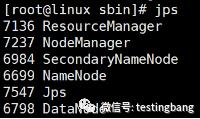
PS:如果修改了上面的xml文件需要重启服务哦
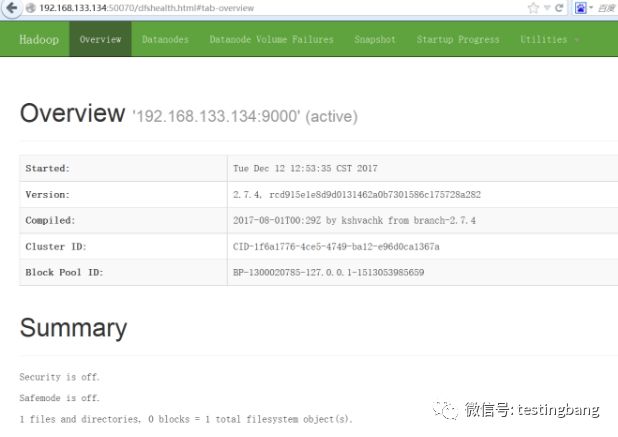
使用web查看Hadoop运行状态
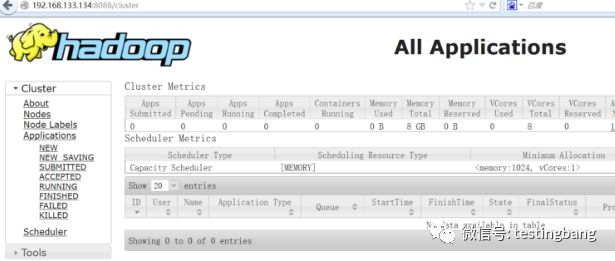
使用web查看集群状态
可能会遇到的问题
如果你多次进行了hdfs的格式化操作,可能会无法启动datanode,原因是id不一致,一般的解决方法为将namenode clusterID和datanode clusterID改成一样的就行了。修改的文件为/tmp/hadoop-root/dfs/下的name or data文件下的VERSION里的内容
小强全栈自动化测试开发班(python+接口+app+web)3月7号开课,名额不多了
所有学员享受免费、不限次数、无限重学的权利直到学会为止,拒绝限制次数、缴纳重学费的恶心规矩
课程大纲与介绍点击文末【阅读原文】
咨询QQ:2083503238或扫下方微信二维码

安装荔枝FM手机APP,搜索“挨踢脱口秀”,可收听技术、娱乐、行业、爆料等语音,播放量已经破百万了哦
以上是关于aliyun-ons (node版)之 集群模式下模拟广播消费的主要内容,如果未能解决你的问题,请参考以下文章