Kubernetes与分布式存储系统VeSpace结合实践
Posted 有容云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes与分布式存储系统VeSpace结合实践相关的知识,希望对你有一定的参考价值。
本文来自8月24日有容云Docker微信群分享整理
分享嘉宾:有容云研发总监-张朝潞
以下是分享正文:
首先介绍下有容云UFleet产品,UFleet -- 基于原生kubernetes技术,为企业打造专属的容器即服务(CaaS)平台,为企业提供应用的全生命周期管理服务和相关的资源服务,为应用的构建、部署和运行提供统一的平台,并保障应用所需的资源随需供应。
有了解决有状态应用对存储的需求,UFleet没有对接第三方存储系统,而采用的是在UFleet平台上融合有容云自主研发的分布式存储系统,从而大大提高了平台资源整合以及利用率;下面将从四个方面来讲讲UFleet平台上怎么融合存储系统?
一、Kubernetes有状态存储模型
kubernetes的存储系统大致分为三个层次:普通Volume,Persistent Volume 和StorageClass动态存储供应。
1.1 普通Volume(单节点)
普通Volume,最简单的一种是“单节点存储卷”,它和Docker的存储卷类似,使用的是Pod所在K8S节点的本地目录。具体有两种:一种是emptyDir,是一个匿名的空目录,由Kubernetes在创建Pod时创建,删除Pod时删除。 另外一种是 hostPath,与emptyDir的区别是,它在Pod之外独立存在,由用户指定路径名。
这类和节点绑定的存储卷在Pod迁移到其它节点后数据就会丢失,所以只能用于存储临时数据或用于在同一个Pod里的容器之间共享数据。

1.2 Persistent Volume(跨节点 - 静态方式)
普通Volume和使用它的Pod之间是一种静态绑定关系,我们无法单独创建一个普通volume,因为它不是一个独立的K8S资源对象。而Persistent Volume 简称PV是一个K8S资源对象,所以我们可以单独创建。它不和Pod直接发生关系,而是通过Persistent Volume Claim,简称PVC来实现动态绑定。静态方式是管理员手动创建一堆PV,组成一个PV池,供PVC来绑定。
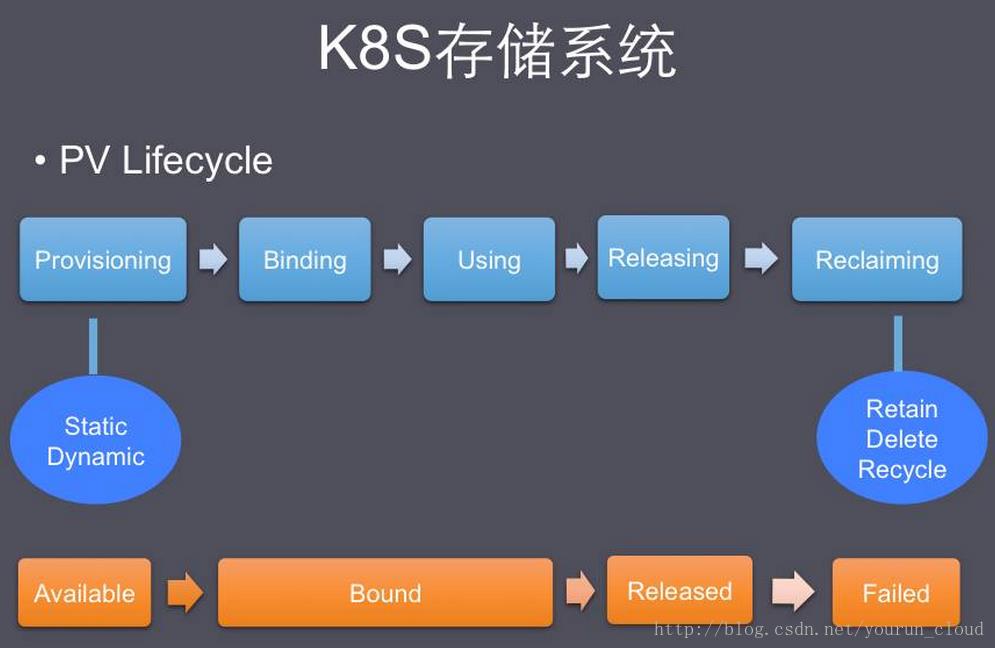
一个PV创建完后状态会变成Available,等待被PVC绑定。一旦被PVC邦定,PV的状态会变成Bound,就可以被相应的Pod使用。Pod使用完后会释放PV,PV的状态变成Released。变成Released的PV会根据定义的回收策略做相应的回收工作。有三种回收策略,Retain、Delete 和Recycle:
Retain就是保留现场,K8S什么也不做。Delete 策略,K8S会自动删除该PV及里面的数据。Recycle方式,K8S会将PV里的数据删除,然后把PV的状态变成Available,又可以被新的PVC绑定使用。
1.3 StorageClass(跨节点 – 动态方式)
动态方式是通过一个叫 storage class的对象由存储系统根据PVC的要求自动创建;使用StorageClass除了由存储系统动态创建,节省了管理员的时间,还有一个好处是可以封装不同类型的存储供PVC选用。
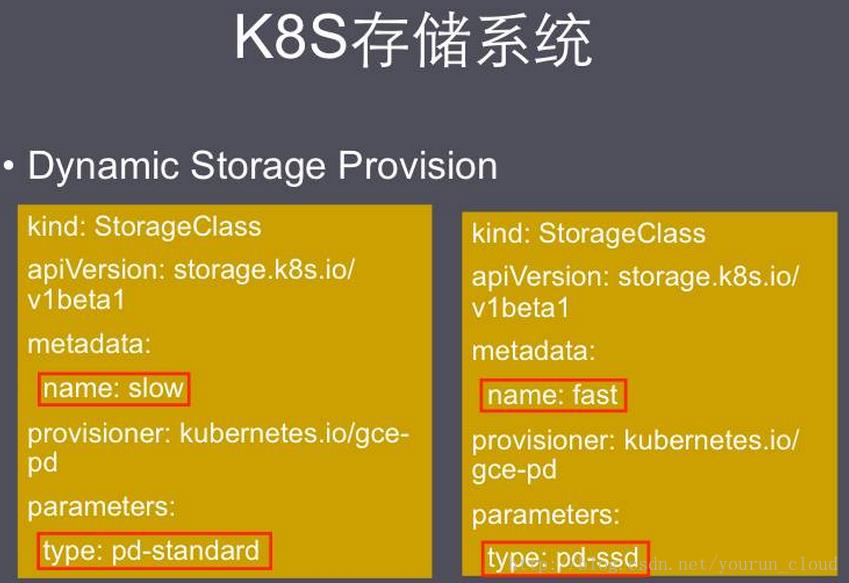
StorageClass是Dynamic Provisioning(动态配置)的基础,允许集群管理员位底层存储平台做定义抽象。用户只需在PersistentVolumeClaim(PVC)通过名字引用StorageClass即可。

二、Kubernetes平台上的分布式存储系统VeSpace
VeSpace分布式存储系统提供3种接口类型,①块接口(SCSI块设备/iSCSI)。②文件接口(NFS/SMB)。③RestFul接口。Kubernetes的存储框架已经支持iSCSI,NFS,SMB的方式整合外部存储。VeSpace的模块架构如下:
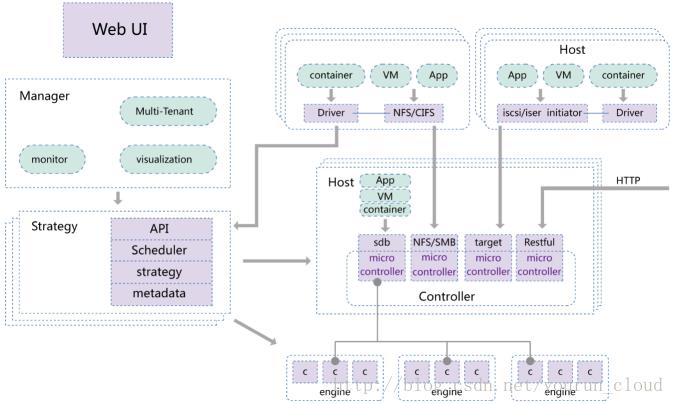
VeSpace支持副本和纠删码两种数据冗余方式,数据冗余方式以卷为单位,可以容器为粒度提供不同级别的存储服务。从数据分布角度来看三种不同类型的卷:1.线性分布;2.条带分布;3.EC分布;
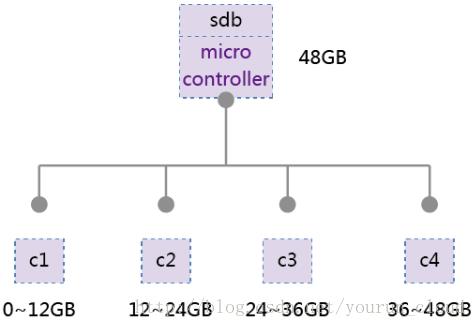
2.1 线性分布
如下图,假设创建一个虚拟卷大小为48GB,线性切分成4个component,C1负责线性地址空间0~12GB-1,只要是对该地址范围内的访问,将请求交给C1处理。
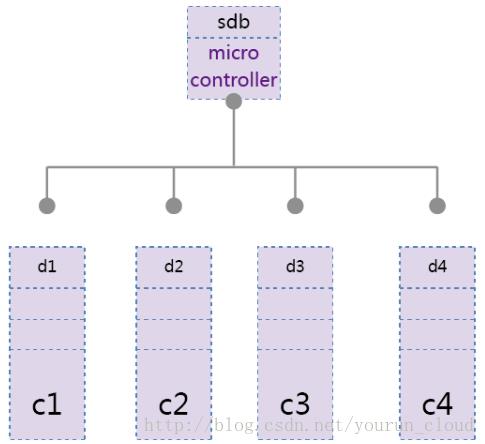
2.2 条带分布
如下图,将数据切成大小相等的数据块(chunk),所有component相同位置的数据块组成条带(stripe),类似于RAID0,跨数据块的读写,并行处理,提升IO速度,减少延迟。
2.3 EC分布
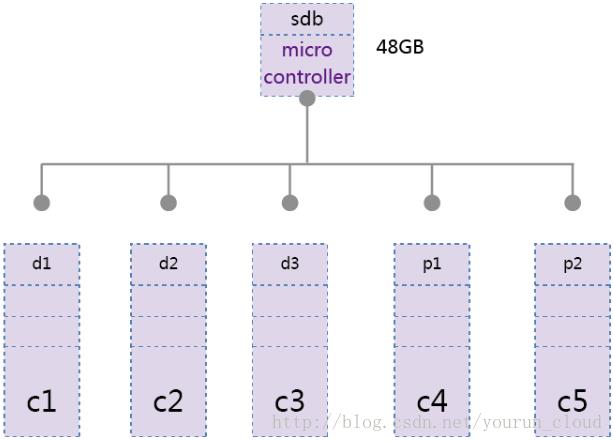
纠删码(erasurecoding,EC)是一种数据保护的方法,将数据切割成大小相同的数据块(chunk),把通过计算得到与数据块(chunk)大小相同的校验块(下图中的P1)。EC通过时间换取空间的方式,通过增加CPU计算量,而减少数据的冗余。
如下图,卷sdb(48GB)使用了3+2的纠删码,允许两个component失效,总使用空间为80GB。如果使用副本的形式则需要占用144GB的存储空间,达到允许两个component失效的目标,纠删码节省了80%的存储空间。
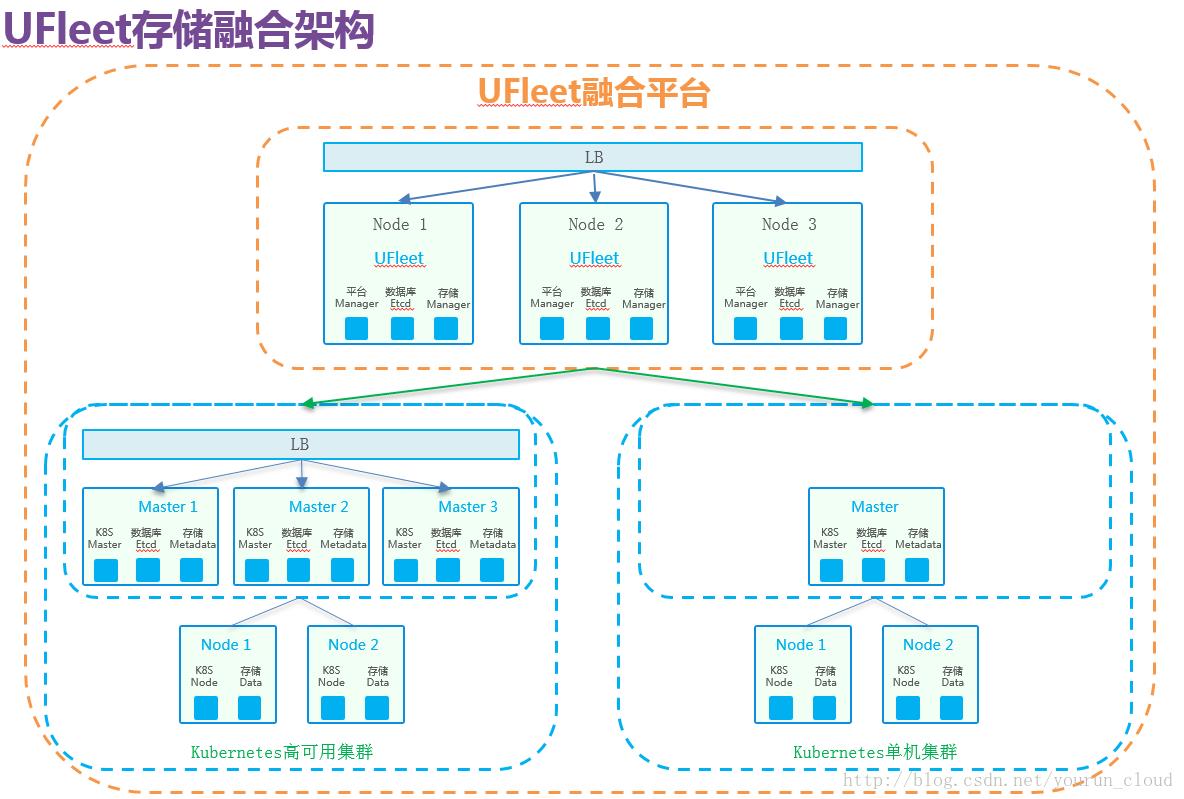
三、UFleet存储融合架构
以下是11台机器,划分了3个Kubernetes集群和1个VeSpace存储集群。VeSpace将11台机器的存储资源整合,通过命名空间隔离再将存储资源暴露给不同的Kubernetes集群。
Q&A
Q1:想请问下,你们的底层分布式存储,负载均衡能基于哪些?cpu利用率?还有啥?
A:负载均衡我们提供可以配置存储策略进行控制,CPU、内存、网络,磁盘使用率,IOPS,延迟等。
Q2:请问VeSpace相比Ceph或者Glusterfs有什么优势?
A:VeSpace是完全自主研发的,可以掌控每一行代码,每一个IO。当然设计上都有参考Ceph和Glusterfs,如果有兴趣可以看看我们提供的技术白皮书,里面有详细的技术描述。
Q3:咱们这个超融合系统的付费方式是怎么样?按照cpu个数?
A:我们的license设计成多个维度的,通常是按照容量,节点或者物理磁盘数量收费。
Q4:贵公司的平台可是实现每个pod的存储扩容和数据隔离吗?这个用户比较关心的。
A:存储卷和Pod是相互独立,不同存储卷的数据自然是隔离的,Pod使用不同的存储卷即可。单个存储卷是可以扩容的。
Q5:存储的访问权限是怎样的?登陆用户都可以访问?
A:存储管理是支持多集群的,集群访问需要授权,集群内部可以划分命名空间,用户可以基于命名空间授权访问
Q6:冗余数怎么设计?
A:根据数据的重要性设置。副本方式性能好,纠删码节省空间。通常两副本,三副本,3+1, 4+1
Q7:EC读写效率如何?数据丢失恢复过程对集群有何影响?
A:主要看K+M的取值,假设是3+1,并且系统负载较低,在正常情况写效率还不错。损坏一个节点的时候,性能下降15~20%。
Q8:您好,能不能分享下部署文件yaml呗,讲的好,不如操作一遍来的实际。
A:UFleet是Kubernetes和VeSpace深度整合的。并不是跑在k8s上,请持续关注UFleet,可以试用一下。
Q9:VeSpace将11台机器的存储资源整合,通过命名空间隔离再将存储资源暴露给不同的Kubernetes集群。我想了解下这里的命名空间是不是可以理解storageclass?这里存储资源整合有什么好处,存在单点问题吗?
A:命名空间指的是VeSpace的命名空间,概念与k8s的命名空间一样。VeSpace命名空间实现资源的逻辑隔离,与storageclass不同,storageclass可以指定VeSpace一个命名空间下的存储池,存在对应关系。存储资源整合有几个好处:1.对于跨k8s集群部署的容器可轻易实现共享,比如集群联邦。2.存储资源统一管理,便于数据均衡,最大限度的使用资源。VeSpace和k8s都是分布式的,并不存在单点问题。
Q10:您好,请问mysql分布式存储方案,能不能介绍下呢?用的是pxc还是什?
A:准确的说应该是mysql的集群方案,没有线上用过mysql的集群方案。以前的工作中开发大型的支付系统的时候,采用的是业务层完成分表分库和读写分离。使用多个mysql主备实例。
本文来源:http://www.youruncloud.com/blog/144.html
以上是关于Kubernetes与分布式存储系统VeSpace结合实践的主要内容,如果未能解决你的问题,请参考以下文章