传统关系型数据库与MapReduce的比较中,横向扩展的非线性和线性是怎样的含义?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了传统关系型数据库与MapReduce的比较中,横向扩展的非线性和线性是怎样的含义?相关的知识,希望对你有一定的参考价值。
线性扩展的意思,简单的理解,就是:获得的扩展能力和增加的资源成比例。
例如:原有2个tasktracker节点,每个可以运行20个task。现在计算能力不够了,新增加一个节点,资源相当于增加了50%,那么,你获得的扩展了的计算能力,也增加到原来的150%。这是MapReduce的扩展能力。
对于传统关系型数据库来说,都是单节点的,例如原来用一个mysql来处理,当你觉得计算能力不够的时候,你没办法说我新增一台同样配置的机器,就把计算能力提高到原来的200%。一般需要更换原来的硬件,才能提高计算能力,那样就是不是横向扩展了。 参考技术A 非线性是指在横向扩展的前提下,如:你原有一个mysql数据库,现在再增加一个数据库,你的数据处理能力增加到原有的两倍,然后在再增加两台,如果是线性增长,数据处理能力应该是原来的四倍,但是实际情况却不是四倍,如果用平面图来表示,x轴表示增加数量,y轴表示性能,那么mapreduce画出来是一条直线,关系型数据库画出来是一条曲线~
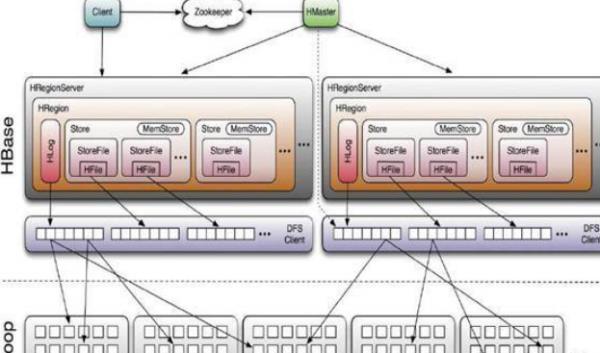
MapReduce 与 HBase 的关系?
参考技术AMapReduce与HBase没有关系:
MapReduce:
MapReduce是一种编程模型,用于大规模数据集的并行运算。概念"Map"和"Reduce",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
HBase:
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。
就像Bigtable利用了Google文件系统所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。
扩展资料:
MapReduce集群中使用大量的低端服务器,因此,节点硬件失效和软件出错是常态,因而一个良好设计、具有高容错性的并行计算系统不能因为节点 失效而影响计算服务的质量。
任何节点失效都不应当导致结果的不一致或不确定性;任何一个节点失效时,其他节点要能够无缝接管失效节点的计算任务;当失效节 点恢复后应能自动无缝加入集群,而不需要管理员人工进行系统配置。
MapReduce并行计算软件框架使用了多种有效的错误检测和恢复机制,如节点自动重 启技术,使集群和计算框架具有对付节点失效的健壮性,能有效处理失效节点的检测和恢复。
参考资料来源:百度百科—MapReduce
参考资料来源:百度百科—HBase
以上是关于传统关系型数据库与MapReduce的比较中,横向扩展的非线性和线性是怎样的含义?的主要内容,如果未能解决你的问题,请参考以下文章