沃趣科技漫游Linux块IO
Posted woqutechteam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了沃趣科技漫游Linux块IO相关的知识,希望对你有一定的参考价值。
前言
在计算机的世界里,我们可以将业务进行抽象简化为两种场景——计算密集型和IO密集型。这两种场景下的表现,决定这一个计算机系统的能力。数据库作为一个典型的基础软件,它的所有业务逻辑同样可以抽象为这两种场景的混合。因此,一个数据库系统性能的强悍与否,往往跟操作系统和硬件提供的计算能力、IO能力紧密相关。
除了硬件本身的物理极限,操作系统在软件层面的处理以及提供的相关机制也尤为重要。因此,想要数据库发挥更加极限的性能,对操作系统内部相关机制和流程的理解就很重要。
本篇文章,我们就一起看下Linux中一个IO请求的生命周期。Linux发展到今天,其内部的IO子系统已经相当复杂。每个点展开都能自成一篇,所以本次仅是对块设备的写IO做一个快速的漫游,后续再对相关专题进行详细分解。
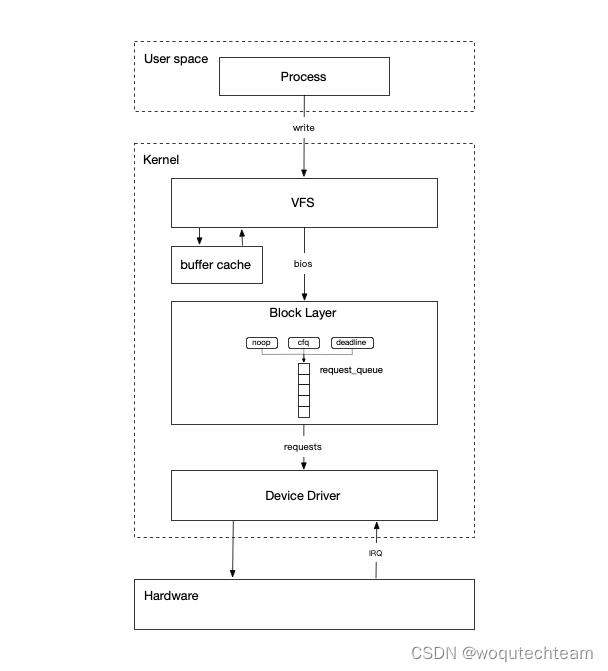
从用户态程序出发
首先需要明确的是,什么是块设备?我们知道IO设备可以分为字符设备和块设备,字符设备以字节流的方式访问数据,比如我们的键盘鼠标。而块设备则是以块为单位访问数据,并且支持随机访问,典型的块设备就是我们常见的机械硬盘和固态硬盘。
一个应用程序想将数据写入磁盘,它需要通过系统调用来完成:open打开文件 —> write写入文件 —> close关闭文件。
下面是write系统调用的定义,我们可以看到,应用程序只需要指定三个参数:
- 想要写入的文件
- 写入数据所在的内存地址
- 写入数据的长度
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file)
loff_t pos = file_pos_read(f.file);
ret = vfs_write(f.file, buf, count, &pos);
if (ret >= 0)
file_pos_write(f.file, pos);
fdput_pos(f);
return ret;
而剩下的工作就进入到内核中的虚拟文件系统(VFS)中进行处理。
虚拟文件系统(VFS)
在Linux中一切皆文件,它提供了虚拟文件系统vfs的机制,用来抽象各种资源,使应用程序无需关心底层细节,只需要通过open、read/write、close这几个通用接口便可以管理各种不同的资源。不同的文件系统通过实现各自的通用接口来满足不同的功能。
devtmpfs
挂载在/dev目录,devtmpfs中的文件代表各种设备。因此,对devtmpfs文件的读写操作,就是直接对相应设备的操作。
应用程序如果打开的是一个块设备文件,则说明它直接对一个块设备进行读写,调用块设备的write函数:
const struct file_operations def_blk_fops =
.open = blkdev_open,
... ...
.read = do_sync_read,
.write = do_sync_write,
... ...
;
磁盘文件系统(ext4等)
这是我们最为熟悉的文件系统类型,它的文件就是我们一般理解的文件,对应实际磁盘中按照特定格式组织并管理的区域。对这类文件的读写操作,都会按照固定规则转化为对应磁盘的读写操作。
应用程序如果打开的是一个ext4文件系统的文件,则会调用ext4的write函数:
const struct file_operations_extend ext4_file_operations =
.kabi_fops =
... ...
.read = do_sync_read,
.write = do_sync_write,
... ...
.open = ext4_file_open,
... ...
;
buffer/cache
Linux提供了缓存来提高IO的性能,无论打开的是设备文件还是磁盘文件,一般情况IO会先写入到系统缓存中并直接返回,IO生命周期结束。后续系统刷新缓存或者主动调用sync,数据才会被真正写入到块设备中。有意思的是,针对块设备的称为buffer,针对磁盘文件的称为cache。
ssize_t __generic_file_aio_write(struct kiocb *iocb, const struct iovec *iov,
unsigned long nr_segs, loff_t *ppos)
... ...
if (io_is_direct(file))
... ...
written = generic_file_direct_write(iocb, iov, &nr_segs, pos,
ppos, count, ocount);
... ...
else
written = generic_file_buffered_write(iocb, iov, nr_segs,
pos, ppos, count, written);
... ...
Direct IO
当打开文件时候指定了O_DIRECT标志,则指定对文件的IO为direct IO,它会绕过系统缓存直接发送给块设备。在发送给块设备之前,虚拟文件系统会将write函数参数表示的IO转化为dio,在其中封装了一个个bio结构,接着调用submit_bio将这些bio提交到通用块层进行处理。
do_blockdev_direct_IO
-> dio_bio_submit
-> submit_bio
通用块层
通用块层对块设备进行了高度抽象,定义了一系列高效的处理块设备IO的机制,通过通用的数据结构和接口,使各种不同的磁盘等物理存储设备的驱动可以很简单的嵌入其中并使用这些机制。
核心结构
bio/request
- bio是linux通用块层和底层驱动的IO基本单位,可以看到它的最重要的几个属性,一个bio就可以表示一个完整的IO操作:
struct bio
sector_t bi_sector; //io的起始扇区
... ...
struct block_device *bi_bdev; //对应的块设备
... ...
bio_end_io_t *bi_end_io; //io结束的回调函数
... ...
struct bio_vec *bi_io_vec; //内存page列表
... ...
;
- request代表一个独立的IO请求,是通用块层和驱动层进行IO传递的结构,它容纳了一组连续的bio。通用块层提供了很多IO调度策略,将多个bio合并生成一个request,以提高IO的效率。
gendisk
每个块设备都对应一个gendisk结构,它定义了设备名、主次设备号、请求队列,和设备的相关操作函数。通过add_disk我们就真正在系统中定义一个块设备。
request_queue
这个即是日常所说的IO请求队列,通用块层将IO转化为request并插入到request_queue中,随后底层驱动从中取出完成后续IO处理。
struct request_queue
... ...
struct elevator_queue *elevator; //调度器
request_fn_proc *request_fn; //请求处理函数
make_request_fn *make_request_fn; //请求入队函数
... ...
softirq_done_fn *softirq_done_fn; //软中断处理
struct device *dev;
unsigned long nr_requests;
... ...
;
处理流程
在收到上层文件系统提交的bio后,通用块层最主要的功能就是根据bio创建request,并插入到request_queue中。
在这个过程中会对bio进行一系列处理:当bio长度超过限制会被分割,当bio访问地址相邻则会被合并。
request创建后,根据request_queue配置的不同elevator调度器,request插入到对应调度器队列中。在底层设备驱动程序从request_queue取出request处理时,不同elevator调度器返回request策略不同,从而实现对request的调度。
void blk_queue_bio(struct request_queue *q, struct bio *bio)
... ...
el_ret = elv_merge(q, &req, bio); //尝试将bio合并到已有的request中
... ...
req = get_request(q, rw_flags, bio, 0); //无法合并,申请新的request
... ...
init_request_from_bio(req, bio);
void blk_flush_plug_list(struct blk_plug *plug, bool from_schedule)
... ...
__elv_add_request(q, rq, ELEVATOR_INSERT_SORT_MERGE); //将request插入request_queue的elevator调度器
... ...
请求队列
Linux中提供了不同类型的request_queue,一个是本文主要涉及的single-queue,另外一个是multi-queue。single-queue是在早期的硬件设备(例如机械硬盘)只能串行处理IO的背景下创建的,而随着更快速的SSD设备的普及,single-queue已经无法发挥底层存储的性能了,进而诞生了multi-queue,它优化了很多机制,使IOPS达到了百万级别以上。至于multi-queue和single-queue的详细区别,本篇不做讨论。
每个队列都可以配置不同的调度器,常见的有noop、deadline、cfq等。不同的调度器会根据IO类型、进程优先级、deadline等因素,对request请求进一步进行合并和排序。我们可以通过sysfs进行配置,来满足业务场景的需求:
#/sys/block/sdx/queue
scheduler #调度器配置
nr_requests #队列深度
max_sectors_kb #最大IO大小
设备驱动
在IO经过通用块层的处理和调度后,就进入到了设备驱动层,就开始需要和存储硬件进行交互。
以scsi驱动为例:在scsi的request处理函数scsi_request_fn中,循环从request_queue中取request,并创建scsi_cmd下发给注册到scsi子系统的设备驱动。需要注意的是,scsi_cmd中会注册一个scsi_done的回调函数。
static void scsi_request_fn(struct request_queue *q)
for (;;)
... ...
req = blk_peek_request(q); //从request_queue中取出request
... ...
cmd->scsi_done = scsi_done; //指定cmd完成后回调
rtn = scsi_dispatch_cmd(cmd); //下发将request对应的scsi_cmd
... ...
int scsi_dispatch_cmd(struct scsi_cmnd *cmd)
... ...
rtn = host->hostt->queuecommand(host, cmd);
... ...
IO完成
软中断
每个request_queue都会注册软中断号,用来进行IO完成后的下半部处理,scsi驱动中注册的为:scsi_softirq_done
struct request_queue *scsi_alloc_queue(struct scsi_device *sdev)
... ...
q = __scsi_alloc_queue(sdev->host, scsi_request_fn);
... ...
blk_queue_softirq_done(q, scsi_softirq_done);
... ...
硬中断
当存储设备完成IO后会通过硬件中断通知设备驱动,此时设备驱动程序会调用scsi_done回调函数完成scsi_cmd,并最终触发BLOCK_SOFTIRQ软中断。
void __blk_complete_request(struct request *req)
... ...
raise_softirq_irqoff(BLOCK_SOFTIRQ);
... ...
而BLOCK_SOFTIRQ软中断的处理函数就是之前注册的scsi_softirq_done,通过自下而上层层回调,到达bio_end_io,完成整个IO的生命周期。
-> scsi_finish_command
-> scsi_io_completion
-> scsi_end_request
-> blk_update_request
-> req_bio_endio
-> bio_endio
总结
以上,我们很粗略地漫游了Linux中一个块设备IO的生命周期,这是一个很复杂的过程,其中很多机制和细节只是点到为止,但是我们有了对整个IO路径的整体的认识。当我们再遇到IO相关问题的时候,可以更加快速地找到关键部分,并深入研究解决。
以上是关于沃趣科技漫游Linux块IO的主要内容,如果未能解决你的问题,请参考以下文章