项目基于负载均衡的在线OJ项目
Posted 呆呆兽学编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了项目基于负载均衡的在线OJ项目相关的知识,希望对你有一定的参考价值。
⭐️ 本博客介绍的是一个基于负载均衡的在线oj项目
⭐️ 项目源码:https://gitee.com/byte-binxin/online-judgement
目录
项目介绍
该项目是基于负载均衡的在线oj,模拟我们平时刷题网站(leetcode和牛客)写的一个在线判题系统。
项目主要分为五个模块:
- 编译运行模块:基于httplib库搭建的编译运行服务器,对用户提交的代码进行测试
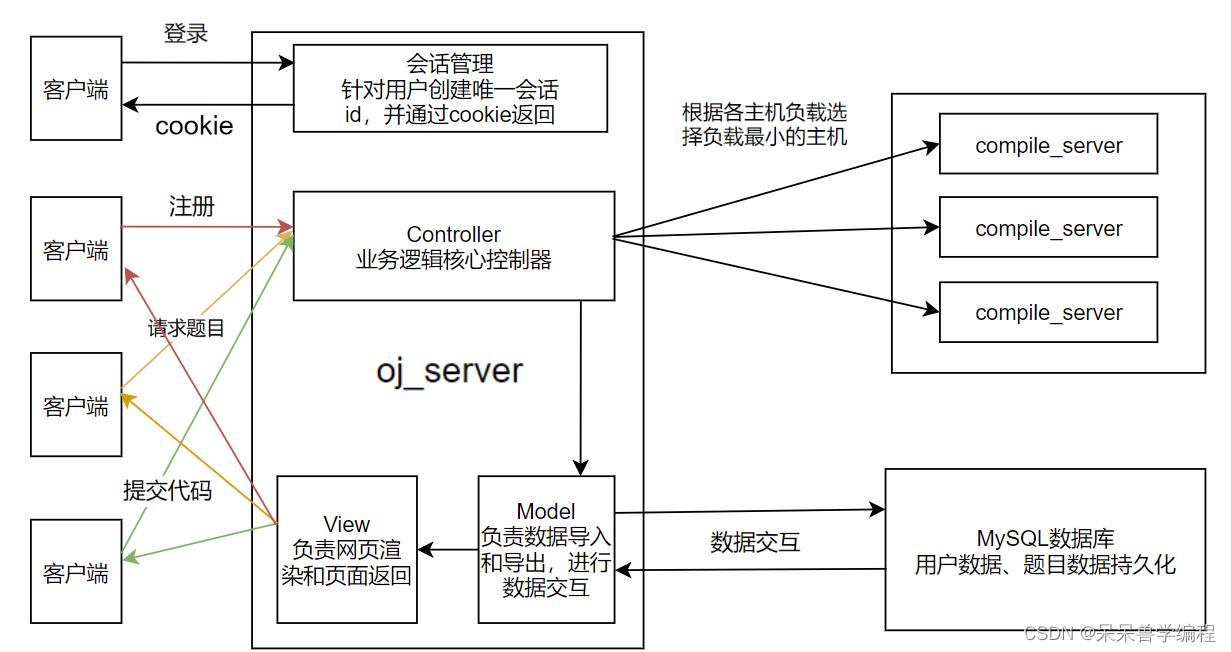
- 业务逻辑模块:基于httplib库并结合MVC模式框架搭建oj服务器,负责题目获取,网页渲染以及负载均衡地将用户提交代码发送给编译服务器进行处理
- 数据管理模块:基于mysql数据库对用户的数据、题目数据进行管理
- 会话模块:基于cookie和session针对登录用户创建唯一的会话ID,通过cookie返回给浏览器
- 公共模块:包含整个项目需要用到的第三方库以及自己编写的工具类的函数
开发环境
- Centos7.6、C/C++、vim、g++、MySQL Workbench、Postman
主要技术
- C++ STL 标准库
- cpp-httplib 第三方开源网络库
- ctemplate google第三方开源前端网页渲染库
- jsoncpp 第三方开源序列化、反序列化库
- 负载均衡设计
- MVC模式框架
- ajax
- MySQL
项目框架图
项目演示
1.普通用户登录界面
2.登录成功后,获得主界面

服务器返回的Session Id保存在浏览器的Cookie文件中

题目列表

单个题目

提交代码会发生的情况


- 管理员账号登录界面

登录成功后进入管理员界面

可以进入录题模块,进行题目录制
项目实现
公共模块
日志
为了方便后期编码调试和项目演示,这里设计了一个日志打印函数,日志打印的格式如下:

日志的五个级别:
- INFO:正常信息
- DEBUG:调试信息
- WARNING:警告信息
- ERROR:错误信息
- FATAL:致命信息
实现如下:
#define INFO 1
#define DEBUG 2
#define WARNING 3
#define ERROR 4
#define FATAL 5
#define LOG(level, msg) Log(#level, msg, __FILE__, __LINE__)
void Log(const std::string level, const std::string msg, std::string filename, int line)
std::cout << "[" + level + "][" + msg + "][" << time(nullptr) << "][" + filename + "][" << line << "]" << std::endl;
工具类
工具类模块中存放着四个工具类:
- 时间工具类:包含了毫秒级时间戳的获取的方法
- 路径工具类:包含了对不同文件添加后缀和拼接临时文件路径的方法
- 文件工具类:包含了对文件读写、判断文件是否存在等文件操作方法
- 字符串工具类:包含了对字符串进行切割等操作字符串的方法
编译运行模块
介绍
该模块负责编译运行oj_server上传过来的代码,并将结果返回给oj_server。oj_server会向编译服务器发送json串,格式如下:
code:用户代码
input:用户自己提交的代码的输入
cpu_limit:时间限制
mem_limit:内存限制
"code":"xxx",
"input":"xxx",
"cpu_limit":"xxx",
"mem_limit":"xxx"
编译服务器需要将代码提取出来,并进行编译,结果以json串格式返回,如下:
status:代码运行状态码
reason:原因
stderr:代码运行完报错信息
stdout:代码运行完的结果
"status":"xxx",
"reason":"xxx",
"stderr":"xxx",
"stdout":"xxx"
编译服务器是基于第三方库cpp-httplib进行搭建的,需要注意的是,编译此库需要用安装新版本gcc,需要是7以上即可。compile_server注册了两种请求方式——/check_net和/compile_run,oj_server可以通过请求/check_net,根据响应来判断compile_server是否上线,可以给上线主机发起/compile_run请求对代码进行编译,并将结果响应给oj_server
Server svr;
// 用来给oj_server检测compile_server网络是否上线
svr.Get("/check_net", [](const Request &req, Response &rep)
rep.set_content("ok", "text/html;charset=utf-8"); );
// 注册POST方法
svr.Post("/compile_run", [](const Request &req, Response &rep)
std::string in_json = req.body;
std::string out_json;
CompileRun::Start(in_json, out_json);
rep.set_content(out_json, "application/json;charset=utf-8"); );
简单的描述框图:
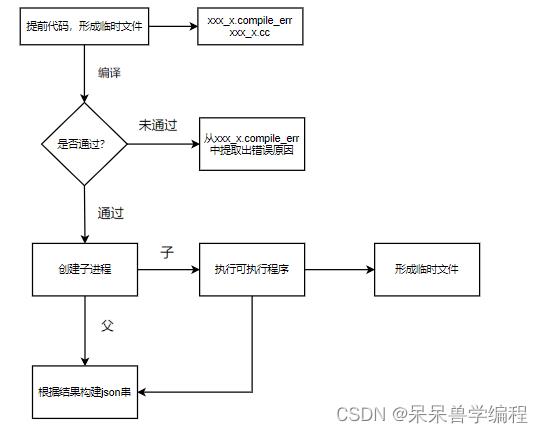
编译
用户的代码可以写入到文件中,并保存在我们项目设置的temp目录下。对应每一个用户的代码的文件,我们都需要给它设置一个唯一的文件名,这个文件名我们通过毫秒级时间戳+原子性递增id生成唯一的一个文件名
毫秒级时间戳获取方法:可以通过gettimeofday这个函数先获取到当前时间信息,从struct timeval这个结构体中提取,如下
int gettimeofday(struct timeval *tv, struct timezone *tz);
struct timeval
time_t tv_sec; /* seconds */
suseconds_t tv_usec; /* microseconds */
;
我们可以将tv_sec除以1000,tv_usec乘以1000,二者都转为毫秒,再相加,这样就可以得到当前的毫秒级时间戳
单单靠一个毫秒级时间戳还不能够完全保证唯一性,所以这里再拼接一个原子性递增id,这里使用atomic_uint,从0开始递增,这样即便时间戳相同,id也不是相同的,这样就保证了文件名的唯一性,实现如下:
// 毫秒级时间戳的获取
static std::string GetMsTimeStamp()
struct timeval tv;
gettimeofday(&tv, nullptr);
return std::to_string(tv.tv_sec * 1000 + (int)(tv.tv_usec / 1000));
// 生成唯一文件名
static std::string UniqueFilename()
// 毫秒级时间戳+原子性递增得出唯一文件名
static std::atomic_uint id(0);
++id;
return TimeUtil::GetMsTimeStamp() + "_" + std::to_string(id);
获取到了唯一的文件名之后,就可以给不同的文件添加不同的后缀,我们的项目有这么几个文件:
// 编译 如果编译成功,会生成可执行,编译失败,错误信息会被记录到xxx_x.compile_err文件中
xxx_x.cc
xxx_x.compile_err
xxx_x.exe
// 运行
xxx_x.stdin
xxx_x.stdout
xxx_x.stderr
编译开始,我们可以打开xxx_x.compile_err,并对标准错误进行重定向,如果编译错误,那么错误信息会被写入到该文件中,编译成功,该文件将为空。这个项目我们通过创建子进程并进行程序替换的方式来编译源文件,编译完成之后,我们只需要让父进程检查temp目录下是否存在可执行程序文件,如果有则说明编译成功,否则编译失败
运行
编译成功后,就要开始对可执行程序进行执行了,执行之前,需要打开三个文件,也就是上面谈到的xxx_x.stdin、xxx_x.stdout和
xxx_x.stderr三个文件,并将标准输入、标准输出和标准错误分别重定向到三个文件中。执行可执行程序的方式和上面的一样,也是通过创建子进程并进行程序替换的方式运行可执行程序,通过退出码分析出运行结果。
我们这个项目对每道题题目的代码运行时间和内存大小都有限制,所以我们执行可执行程序之前我们需要对内存和时间进行限制,这里使用setrlimit系统函数来进行设置,接口如下:
int setrlimit(int resource, const struct rlimit *rlim);
struct rlimit结构体(描述软硬限制),原型如下:
struct rlimit
rlim_t rlim_cur;
rlim_t rlim_max;
;
这里我们需要设置的两个参数分别是RLIMIT_AS和RLIMIT_CPU,如下:
RLIMIT_AS // 进程的最大虚内存空间,字节为单位。
RLIMIT_CPU // 最大允许的CPU使用时间,秒为单位。当进程达到软限制,内核将给其发送SIGXCPU信号,这一信号的默认行为是终止进程的
执行。然而,可以捕捉信号,处理句柄可将控制返回给主程序。如果进程继续耗费CPU时间,核心会以每秒一次的频率给其发送SIGXCPU信号,
直到达到硬限制,那时将给进程发送 SIGKILL信号终止其执行。
这里我们将二者的硬限制都设置为无穷大RLIM_INFINITY,软限制设置为题目要求的,具体代码如下:
static void SetProcLimit(int cpu_limit, int mem_limit)
struct rlimit climit;
climit.rlim_cur = cpu_limit;
climit.rlim_max = RLIM_INFINITY;
setrlimit(RLIMIT_CPU, &climit);
struct rlimit mlimit;
mlimit.rlim_cur = mem_limit * 1024; // 转为kb
mlimit.rlim_max = RLIM_INFINITY;
setrlimit(RLIMIT_AS, &mlimit);
父进程需要分析运行结果,如果waitpid的返回值小于0,说明父进程等待失败,也是运行错误,否则分析status,如果是正常退出,我们可以提取出退出码分析,如果是异常退出,此时我们能够知道子进程是被信号所杀,这时,我们只需要提取出信号即可
// father
int status = 0;
int ret = waitpid(id, &status, 0);
int sig = 0; // 检验是否是被信号所杀
if (ret > 0)
if (WIFEXITED(status))
// 正常退出
int exit_code = WEXITSTATUS(status);
if (exit_code == 0)
LOG(INFO, "run success");
else if (exit_code == 1)//子进程替换失败 exit(1);
LOG(ERROR, "run execlp fail");
return -1;
else
LOG(ERROR, "unknow status code:" + std::to_string(exit_code));
return -1;
else
// 异常退出
sig = status & 0x7f;
LOG(WARNING, "sig: " + std::to_string(sig));
else
// 等待失败
LOG(ERROR, "run wait fail");
return -1;
return sig; // 返回收到的信号 正常是0 异常时一个信号
综合编译和运行结果进行分析,对返回json串进行设置:
- 如果编译失败,或编译成功运行失败,我只需要设置status、reason两个个字段
- 如果编译运行成功,我们还需要设置stdout和stderr两个字段
测试
这里我们使用postman进行简单的测试,自己构建json串,并向我们的编译服务器发起请求,请求成功之后可以得到一段响应,可以在postman这个工具中查看,请求json串如下:
"code": "#include <iostream>\\nint main()\\n\\n\\twhile(1);std::cout << \\"hello world\\" << std::endl;\\n\\treturn 0;\\n",
"input": "",
"cpu_limit": 1,
"mem_limit": 30000
上面是一段正常的代码,响应结果如下:

我们往code中加入一段死循环代码,如while(1);,再发起请求,响应结果如下:

往code中加入一段野指针访问的代码,如int* p = nullptr; *p = 0;,再发起请求,响应结果如下:

往code中加入一段申请很大内存的代码,如int* p = new int[10000];,再发起请求,响应结果如下:

业务逻辑模块
介绍
该模块是整个项目业务逻辑的核心,包括用户登录注册、题目获取、与数据库进行数据交互、网页渲染以及协调编译服务器的负载均衡,同时该模块也会用到会话模块和数据库模块,进行用户会话管理、数据管理。综合这些利用第三方库cpp-httplib结合MVC模式框架搭建一个oj服务器,该服务器注册了很多Get和Post请求方法,供前端页面发起ajax请求进行前后端数据交互,及时更新前端页面
MVC模式框架
模型(Model)
Model负责与数据库进行交互,听取控制器的调用,往数据库中插入数据或从数据库中获取数据并让View将请求结果返回给用户
插入数据的几种情形:
- 用户注册
- 管理员添加题目
查询数据的几种情形:
- 用户获取题目信息
- 获取用户信息
题目设计:
- 我们项目题目的属性有这么几个:编号、标题、难度、时间限制、内存限制、题目描述、头文件、用户显示代码、测试代码,后序我们需要对header、body和tail这三个部分进行拼接,形成一份新的代码,再提交给编译服务器
- 形成的数据库表结构如下:
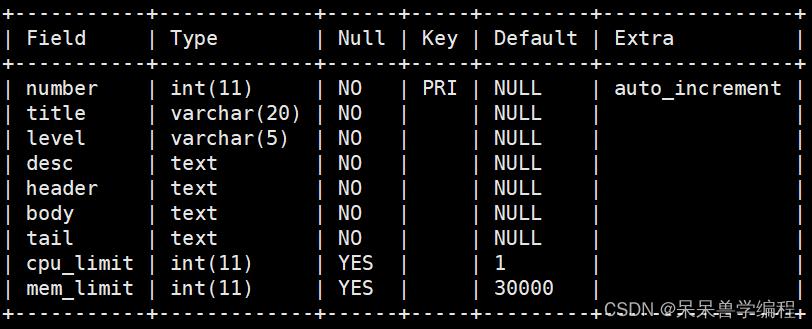
-
结构体如下:
struct Question std::string show_num; // 显示编号 std::string num; // 题目编号 std::string title; // 题目标题 std::string level; // 题目难度等级 int cpu_limit; // 题目时间限制 单位 s int mem_limit; // 题目内存限制 单板 kb std::string desc; // 题目描述 std::string header; // 用户需要用到的头文件 std::string body; // 显示给用户的代码 std::string tail; // 用来测试用户的代码 ;
接口设计:
- 接口主要包括加载配置、单个题目的获取、全部题目的获取、添加题目和用户数据相关操作
- 加载配置主要是将show_num和num建立起映射关系,show_num这个属性是给用户页面显示的,不直接用number显示给用户的原因是:number在数据库中是自增长的,且每次添加题目,其number是从最大的number+1开始增长,在不删除题目的情况下,number是连续的,如果中途删除了某个题目,后序number这个序列就不会是连续的,中间会断开,如:1、2、3、4,删除了3,再增加一个题目,number是5,这时number序列就是1、2、4、5,这样就不是连续的,所以用number显示给用户不太好,设计一个show_num是连续的,并与number建立好映射关系,这样就比较友好
- 单个题目的获取和多个题目的获取,主要是查询数据库,获取到的数据可以交付给View
- 添加题目需要往数据库中插入数据,同时更新show_num和number的映射关系
- 用户数据操作结合数据库操作一起完成
视图(View)
View负责将Model提供的数据以某种方式呈现给用户,这个项目主要是网页界面。View会使用google的开源库ctemplate进行网页渲染,以这种方式将数据呈现给用户
ctemplate的获取
可以在GitHub的国内镜像网站中获取,速度会比较快,链接如下(里面有详细的安装方法说明):
https://hub.fastgit.xyz/OlafvdSpek/ctemplate
ctemplate的简单用法
-
变量名:把它放入我们的网页中,该部分会被替换成我们字典中添加的值,使用如:number、show_num
-
#片断名:片断在数据字典中表现为一个子字典,字典是可以分级的,根字典下面有多级子字典。片断可以处理条件判断和循环,循环的结束/片段名
-
TemplateDictionary:可以创建字典
-
SetValue:可以往字典中添加模板
-
AddSectionDictionary:可以往字典中添加子字典
-
GetTemplate和Expand:两个接口可以获取到扩展之后的模板
ctemplate::Template* tpl = ctemplate::Template::GetTemplate("./ctexample.tpl",ctemplate::DO_NOT_STRIP); std::string output; tpl->Expand(&output, &dict);
接口设计:
这里对题目列表和单个题目两张网页进行渲染,将数据添加到网页中,实现如下:
void ExpandAllQuestionsHtml(const std::vector<Question> qs, std::string &outhtml)
std::string src_html = template_path + "all_questions.html";
// 创建数据字典
TemplateDictionary root("all_questions");
for (auto &q : qs)
// 往root添加子字典
TemplateDictionary *sub = root.AddSectionDictionary("questions_list");
sub->SetValue("number", q.num);
sub->SetValue("show_num", q.show_num);
sub->SetValue("title", q.title);
sub->SetValue("level", q.level);
// 获取要渲染的网页 不做删除任何符号的动作
Template *tpl = Template::GetTemplate(src_html, DO_NOT_STRIP);
// 开始渲染
tpl->Expand(&outhtml, &root);
void ExpandOneQuestioHtml(Question &q, std::string &outhtml)
std::string src_html = template_path + "question.html";
// 创建数据字典
TemplateDictionary root("question");
root.SetValue("show_num", q.show_num);
root.SetValue("title", q.title);
root.SetValue("level", q.level);
root.SetValue("desc", q.desc);
root.SetValue("pre_code", q.body);
// 获取要渲染的网页 不做删除任何符号的动作
Template *tpl = Template::GetTemplate(src_html, DO_NOT_STRIP);
// 开始渲染
tpl->Expand(&outhtml, &root);
控制器(Controller)
Controller是整个项目业务逻辑的控制器负责协调model和view一起完成业务。
负载均衡设计
控制器的核心还包括了一个负载均衡的小模块,帮助控制器根据主机负载选择编译服务器,负载均衡的设计框架如下:
class LoadBlance
public:
LoadBlance()
assert(LoadConf()); // 加载配置文件
bool LoadConf()
int AutoChoose(Machine *&machine)
void Online(int id)
void Offline(int id)
public:
std::vector<Machine> _machines; // 可以提供服务的所有主机,下标充当主机id
int _count = 0; // 在线主机数
std::mutex _mtx;
;
主机设计: 主机的属性应该有状态(上线、下线),当前负载,主机id,主机ip,主机绑定端口号,如下:
enum status
ONLINE,
OFFLINE
;
struct Machine
int id; // 主机id
std::string ip;
int port;
enum status status = OFFLINE;
uint64_t load = 0; // 负载
std::mutex *mtx = nullptr;
;
加载配置文件: 我们的配置文件中存放着我们需要用到的主机信息,每行存放一台主机的信息,格式如:ip:port,如下:
ip1:port1
ip2:port2
ip3:port3
通过读取文件,并对每一行进行分析,将主机信息存放到vector容器中
根据负载选择主机: 我们需要遍历所有上线的主机,选出负载最小的那一台主机,如果当前上线主机上为0,则打印出提示信息,发起警告,如果选择主机成功,我们可以返回主机id,具体操作如下:
int AutoChoose(Machine *&machine)
_mtx.lock();
if (_count == 0)
LOG(FATAL, "所有主机全部下线,请及时核查原因");
_mtx.unlock();
return -1;
int id = 0;
int min_load = INT_MAX;
for (int i = 0; i < _machines.size(); ++i)
// 当前主机下线就选择另一台主机
if (_machines[i].status == OFFLINE)
continue;
int load = _machines[i].GetLoad();
if (load < min_load)
min_load = load;
id = i;
_mtx.unlock();
machine = &_machines[id];
return id;
主机上线: 我们需要能够设计一个接口来更改status这个字段,如果主机上线了,我们就把status字段改为ONLINE,否则改为OFFLINE,如何检测主机是否上线呢?还记得我们前面在编译服务器中注册的一个Post /chech_net用来检测网络通畅请求方法吗,我们可以在oj_sever启动时开辟一个线程,该线程会不停地给所有状态为OFFLINE的主机发起请求,如果得到了响应,那么说明,该主机已经上线,我们就可以把该主机的status字段改成ONLINE,表示主机已经上线,检测方法如下:
void *check(void *arg)
sleep(1);
pthread_detach(pthread_self());
Control *ctrl = (Control *)arg;
LoadBlance *loadblance = &ctrl->_lb;
while (1)
std::vector<Machine> machines = loadblance->_machines;
for (auto &machine : machines)
if (machine.status == OFFLINE)
Client clt(machine.ip, machine.port);
if (auto res = clt.Post("/check_net", "check", "text/plain;charset=utf-8"))
// 得到响应,证明对端主机上线
loadblance->Online(machine.id);
主机上线了。我们需要对负载均衡模块中的上线主机上count进行加1的操作:
void Online(int id)
_mtx.lock();
_machines[id].status = ONLINE;
LOG(INFO, 以上是关于项目基于负载均衡的在线OJ项目的主要内容,如果未能解决你的问题,请参考以下文章