论文阅读记录: Automatic Image Colorization sig16
Posted MingChaoSun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读记录: Automatic Image Colorization sig16相关的知识,希望对你有一定的参考价值。
sig论文阅读记录
Let there be Color!: Joint End-to-end Learning of Global and Local Image Priorsfor Automatic Image Colorization with Simultaneous Classification ( siggraph 2016 )
论文简介
论文主页:http://hi.cs.waseda.ac.jp/~iizuka/projects/colorization/en/
作者是来自Waseda University(早稻田大学)的 Satoshi Iizuka 、 Edgar Simo-Serra 、 Hiroshi Ishikawa
这篇sig paper主要是基于深度学习做Colorization的,相关的工作也有不少,使用CNN的也有几篇论文,但是这篇Paper的效果是非常出众的,从figure1展示的效果来看,从Gray Image还原的Color Image 效果十分惊艳。
Figure1:

下面我们来大体介绍一下这篇Paper的要点:
Key Point:
首先这篇Paper提出了一种基于全局先验(global priors)和局部特征(local image features)的自动上色方法。使用卷积神经网(CNN),从small image patches中提取局部信息,从整张图像完成全局先验。这整个过程是端对端学习的(end-to-end learning),不需要预处理和后期处理。
传统的Colorization算法需要用户交互,图割等手段,而这篇Paper基于深度学习数据驱动,可以全自动的上色。不过关于这一点,在我测试了一些结果之后,我认为如果在自动生成的基础上再加上交互,实用性会大大加强。
Paper提出的方法可以对任何分辨率的图像上色,这是和大部分基于CNN的方法所不同的,这当然和网络结构有关,后面会细说。
Paper提出的方法可以做到基于global信息,完成不同图像之间的风格转换,这个后面也会根据网络结构细说。
论文使用了一个大型场景分类的数据集来进行模型的训练,利用数据集中的分类标签更加有效和有鉴别性的进行了全局的学习,比如利用图像的类别信息:室内,室外,白天,夜晚等来引导网络学习图像的语义(semantic context)信息。使得网络可以区分不同场景下的图像,来提高performance。论文也证明了这种方法比单纯使用局部信息要优秀很多。
使用的色彩空间为CIE L* A * B * ,论文后面也说明了使用L* A * B *比 RGB和YUV更接近Ground truth,并且通过这一点,也很巧妙地降低了网络的学习难度,保证了输出的分辨率与输入相同,这里后面会细说。
最终模型的泛华能力是比较强的,不仅适用于现在设备拍到的灰度图像,还适用于几十年前,甚至一个世纪之前拍到的图像。
模型包括4个部分(整个framework由4个sub-network构成):
low-level feature network:底层的卷积网络,分为两个网络,两个网络的权重是共享的,用于从图像中提取最基本的特征,并后接不同的网络。
mid-level feature network:一个两层conv,感觉为这个专门起个名不大合适。与 global-level feature network相融合得到Fusion Layer。
global-level feature network:由几个conv和fc组成的分类网络,对输入的固定大小的图片进行分类,与mid-level feature network共同构成Fusion Layer,让colorization network可以得到 global feature。
colorization network:一个反卷积网络,从feature maps还原到target image。
网络结构:
这篇Paper主要是基于卷积神经网络的,网络结构自然是作者精心设计的,为一非循环图,作者把网络结构分成了四个主要部分,low-level feature network,mid-level feature network,global-level feature network,colorization network,通过这个网络完成了我们上述的要点。下面我们来仔细看一下论文作者设计的网络:
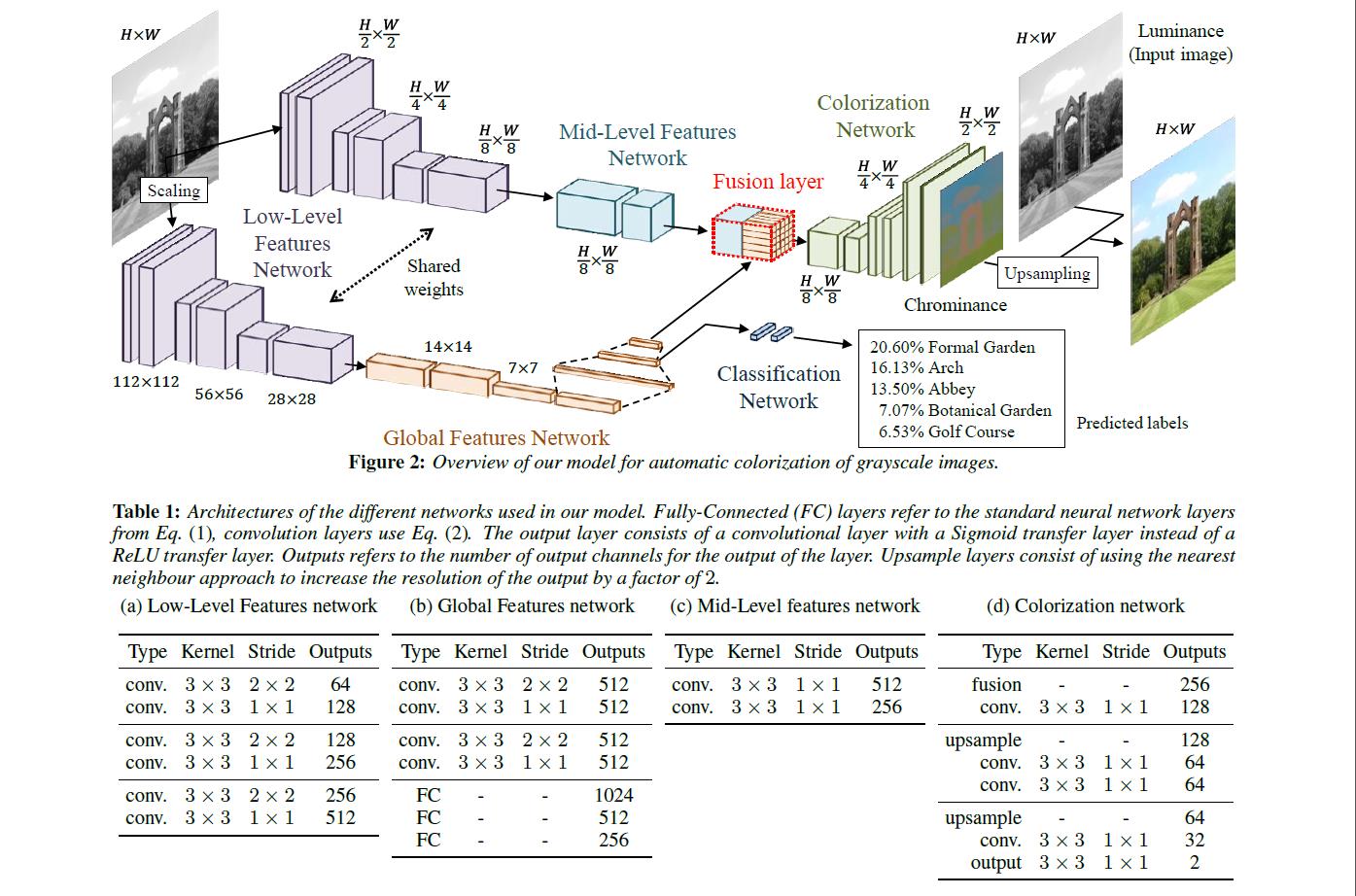
上图很详细的表现了整个网络结构,我们按照作者划分的几个部分来看一下整个网络的细节:
low-level feature network:
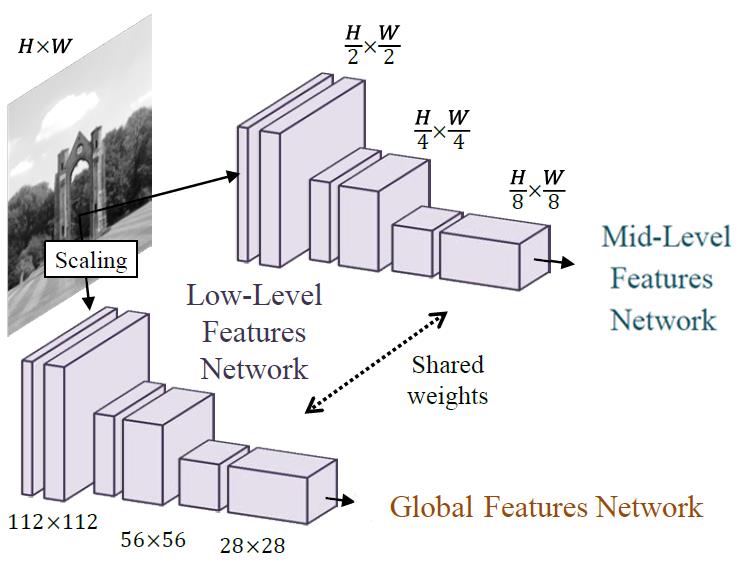
一个6层的卷积网络,用于直接从输入图像提取基本特征,激励函数:ReLU。这部分网络分为两个网络,两个网络的权重是共享的。
我认为这里分成两个网络是因为其后面接的网络是不同的,一个网络接用于图像分类的 global-level feature network来完成全局先验,另一个网络接mid-level feature network + colorization network反卷积网络来完成上色。
其中接 global-level feature network的网络是固定大小的(112*112),需要将图像Scaling后输入,之所以固定大小我觉得这是因为这部分网络是是用来确定图像的所处环境(学习semantic context),说白了就是一个图像分类的网络,所以采取了和AlexNet相似的结构,固定大小conv + fc 的结构。
而接 mid-level feature network + colorization network的网络是不固定大小的(H/2 * W/2),这里也很好理解,colorization network的目的在于可以处理任意输入大小的图像,是一个全卷积网络(FCN),所以网络大小取决于原图。
也因为这样的设计,虽然全局特征的计算是使用固定大小的图片,但是通过Fusion Layer将全局特征与局部特征融合,使得可以计算任意分辨率的图像。
这部分网络的下采样并不是采用的max pooling层,而是使用了strides,这种方法要优于max pooling,目前也比较流行。
(use convolution layers with increased strides)
mid-level feature network:
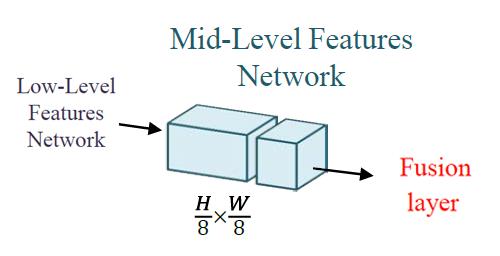
这部分网络是一个两层conv,激励函数:ReLU,感觉把这一部分单独拿出来命名确实有些牵强,可能是为了更清楚的描述整个网络吧。这部分网络的输入为low-level feature network输出的H/8 * W/8 * 512维特征,经过两层卷积神将网络后输出H/8 * W/8 * 256维特征与 global-level feature network输出的256维向量进行融合得到Fusion Layer。
global-level feature network:

因为论文作者用到了具有类别标签的Places Sence Dataset(共2448872张,205种类别),所以可以通过这些标签让网络学习到照片的semantic context,来作为全局特征。因此在global-level feature network后接一个ClassificationNetwork完成场景分类,使用互熵损失完成训练。
所以这部分网络是由4个conv和3个fc组成的分类网络(激励函数:ReLU)。说白了就是对输入的固定大小的图片进行分类,输出为一个256维的向量,与mid-level feature network共同构成Fusion Layer,让colorization network可以得到 global feature。
Fusing Global and Local Features(Fusing Layer):

作者一直强调全局特征与局部特征的融合,我也认为这个Fusing Layer是framework的关键点之一。通过将不同网络的特征融合到一起,学习到不同的特征,提升performance。例如,如果全局特征表明,它是一种室内图像,局部特征将偏向于不尝试添加天空颜色或草的颜色,而是偏向于尝试家具的颜色。
mid-level feature network将low-level feature network输出的H/8 * W/8 * 512维特征,经过两层卷积神将网络后,得到了 H/8 * W/8 * 256维特征;global-level feature network输出的全局特征为一256维向量;这两者通过作者提出的Fusing Layer进行了融合,使得colorization network能够基于局部与全局信息进行上色。
融合公式为:
Yfusionu,v=σ(b+W[YglobalYmidu,v])

这里把global-level feature network和mid-level feature network通过一层网络进行了融合,图上示例画的很清楚。
colorization network:

这部分网络是由一系列conv Layer和upsample Layer组成反卷积网络,类似auto-encoder的后半部分网络,从feature maps还原到target image。upsample Layer使用最近邻的方法(nearest neighbour)来不断地上采样,conv和upsample不断交叉输出直到size为输入图像的一半。
colorization network的输出层是一个使用sigmod函数做激励函数的Conv层,用来输出原始灰度图的色度(chrominance)
网络的最后会将色度(chrominance)与输入的亮度图(luminance)(即输入的灰度图)相结合,生成最后的彩色图像。
这里是Paper的一个非常巧妙的地方,之前说过作者一直使用的是CIE L* a * b * 色彩空间,那么为什么不使用常用的RGB,YUV呢?(事实上,paper里也做了RGB和YUV的对比实验)
这里网络的结果是色度(chrominance)也就是CIE L* a * b * 中的 a * b * , 而不是直接生成rgb。这是因为灰度图本身就是L* ,因此使用CIE L* a * b * 就可以只学习a* b* ,而不用学习L* ,这样不仅降低了网络的学习难度,而且不需要改变原来的L*。
paper里对RGB、YUV、L* a * b * 的对比实验:

训练:
目标函数:
先来看一下目标函数:

目标函数由2个损失函数构成,一项是colorization network的预测和目标图像之间的欧式距离,另一项是global-level feature network + ClassificationNetwork分类的互熵损失(cross-entropy loss),这都是非常常用的损失函数。也不需要过多解释,两者之间用alpha变量来控制不同网络的权重。
作者也提到过直接使用最终的上色结果和GrandTruth之间的欧氏距离作为损失,梯度回传整个网络的方法,但是这样会导致没法很好的学习到全局特征。
而且我认为ClassificationNetwork在这里不仅起到了学习global features,semantic context这些信息的作用,一个更重要的作用是在一定程度上减缓了梯度回传的梯度弥漫的问题,使得这么大的网络更加容易学习。
在反向传播过程中color loss 会影响这个网络,而分类损失只影响 ClassificationNetwork,global-level feature network以及共享的low-level feature network,不影响colorization network和mid-level feature network。
训练优化:
Paper中也提到了一些针对训练过程的优化:
一是对于训练数据大小的选择,如果使用的input image的size是224 * 224 像素,那么大家可以看到low-level feature network的两个子网络将完全相同,那么两个子网络的outputs就可以进行共享,也就是说训练的时候只需要训练一个网络就可以了,然后把outputs输入接下来的两种不同网络,对于作者使用的比较大的数据集,这里少训练一个子网络还是很有用的,所以作者在训练数据集的时候采用的是224 * 224像素的图像。
再就是为了使得网络可以加快收敛或者能够收敛起来,paper里还提到了可以用目前比较火的batch normalization,2015年提出,只过了一年已经300+引用,具体可以看大神的博客:
http://blog.csdn.net/hjimce/article/details/50866313
以及使用AdaDelta optimizer来优化目标函数,加快训练。
时间:
paper里提及训练该网络,所用的数据集有2448872个training image 和 20500个 validation image,总共有205个场景类别,比如修道院,会议中心,火山。训练使用的batch size 为 128,大约200000次迭代,11个epoch,在NVIDIA Tesla K80 GPU上训练整整需要3周。
至于计算时间,使用GPU的话作者说大概可以接近实时,不过作者的GPU是NVIDIA GeForce GTX TITAN X 。CPU是 Intel Core i7 - 5960X。
风格转换:
另外之前也提到了,Paper提到可以做不同图像的style的transfer,其实也是对网络结构的一个小利用:由于low-level feature network是是两个网络构成,一个对应原图输入进行局部特征提取,一个对应固定大小的输入完成全局分类,当这两个输入对应于不同的输入图像时,固定大小的输入图像的style就会嫁接到原图输入上。这是由于global-level feature network学习的是固定大小输入图像的global feature和semantic context导致的。
下面是一些style转换结果:

结果:
论文中贴出了很多验证集上的结果,看着效果都很不错:

甚至在一些100年前的老照片上也取得了不错的效果,说明模型的泛化能力还是很不错的:

作者为了证明加入全局特征的效果,也做了只使用上半部分网络,不使用全局信息的实验,下面是一些对比,BaseLine就是令融合公式中的alpha为0,即抛弃全局特征的实验结果。


可以看到上面这个图片把室内的天花板当做了天空,而增加了全局信息之后就不会出现这样的情况,对室内温暖的光线模拟的很好。
另外由于灰度图到彩色图是不可逆的,所以灰度图对应的彩色图可能是多种情况的,所以和Ground truth有所差距也是很正常的,比如paper中的这个例子:

当然这就是论文里提到的最失败的例子了,我自己从作者的Github上下载了作者的模型,然后随便找了一些自己拍的学校啊,网上的照片啊,进行尝试,我发现对于草和天空,木质纹理等等,这些自然场景,以及人的皮肤,上色的效果非常的好,对于建筑和人的衣物就差一些,有的时候建筑颜色很诡异,衣服很多情况下都是棕色。对于一些乱七八糟的图片,甚至是画的画,感觉模型总是会用棕色来进行填充,下面是一些结果,大家随意感受一下就好:
先来几个效果好的:
从网上找的一些自然风光的图:
GT:

Proposed:

GT:

Proposed:

GT:

Proposed:

GT:

Proposed:

学校的楼呵呵了,试了几个建筑效果都不大好,但是草和树很逼真
GT:

Proposed:

纹理比较复杂的,估计也没这个语义
GT:

Proposed:

还试了一些自己同学的照片,皮肤部分做的确实不错,涉及他人权利,就不上传了。
老照片:
input:

Proposed:

input:

Proposed:

从网上找的老毕业照
input:

Proposed:

input:

Proposed:

input:

Proposed:

input:

Proposed:

以上是关于论文阅读记录: Automatic Image Colorization sig16的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读记录: Automatic Image Colorization sig16
Automatic classification of defective photovoltaic module cells in electroluminescence images-论文阅读笔记
Automatic surface defect detection for mobile phone screen glass based on machine vision-论文阅读笔记
Automatic Metallic Surface Defect Detection and Recognition with Convolutional NeuralNetworks-论文阅读笔记
关于automatic_Panoramic_Image_Stitching_using_Invariant_features 的阅读笔记