Attention机制总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Attention机制总结相关的知识,希望对你有一定的参考价值。
参考技术A感兴趣区域ROI和定位机制。
每一步只关注特定小区域,抽取区域表征信息,再整合到之前的步骤所积累的信息中。
Soft attention: 以概率进行加权输入到下一层;
Hard attention: 选取一个输入到下一层。
策略梯度的强化学习技术 使得训练定位小框位置变得可能,在每次探索中,如果分类模块能正确预测,给与正反馈,强化对这个位置的选择,反之则给负反馈。
一瞥模块:接收一个位置的二维向量作为输入 画出小框提取特征再结合位置信息 得到中间向量z。
循环模块:接收中间向量z 包含2层RNN,下层主要积累识别的信息 上层主要预测位置。
发射模块:上层RNN输出的累积位置信息(隐层的高维向量)映射成二维位置向量,并进行高斯采样。
分类模块:根据下层 RNN的输出向量进行预测。
上下文模块:解决第一步往哪儿看的问题 接收整张图怓 输出初始状态向量作为上层RNN的初始输入得到第一个glimpse的位置
将输入分解成序列化的 同时学习 where and what的思想就是attention的核心
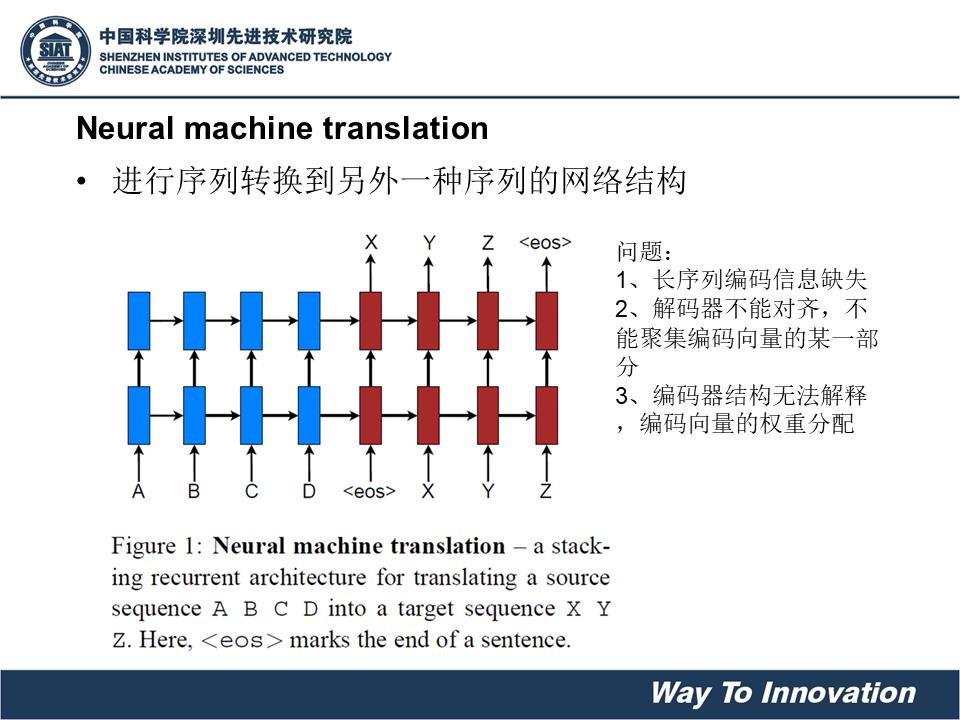
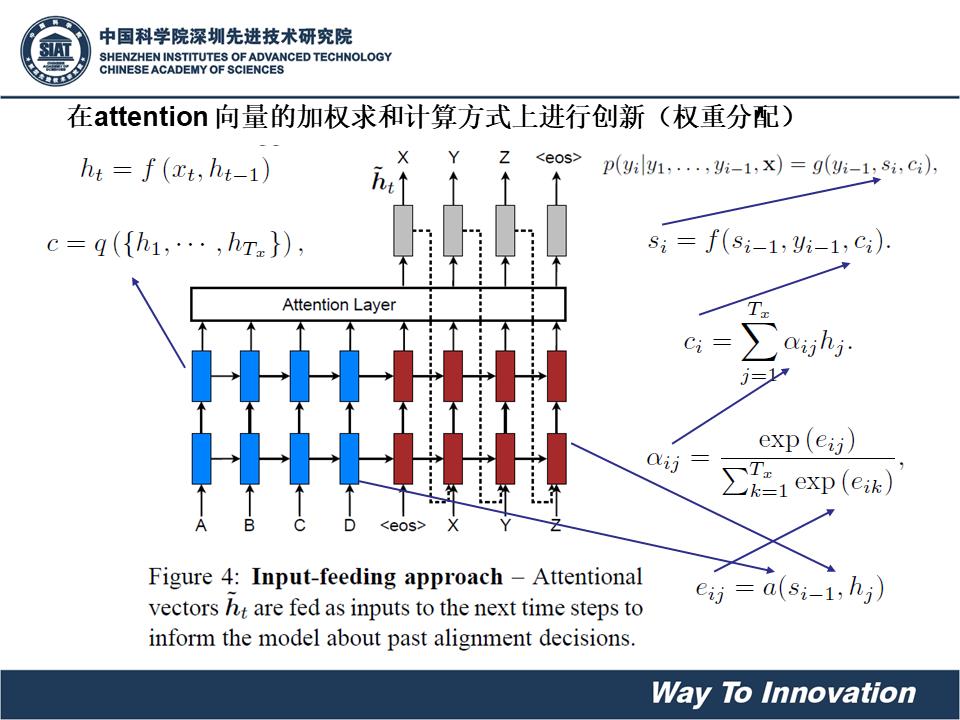
Attention机制是连接编码层和解码层的一个通道。由于我们在编码(encoder)过程中保留每个RNN单元的隐藏状态(hidden state)得到(h1……hN)。而后对于解码(decoder)过程中每一个timestep,因为有此时decoder的输入和上一步隐藏状态的输出,计算得到当前步的隐藏状态。假设第t步的隐藏状态为St(当前输入和上一步隐藏状态)。
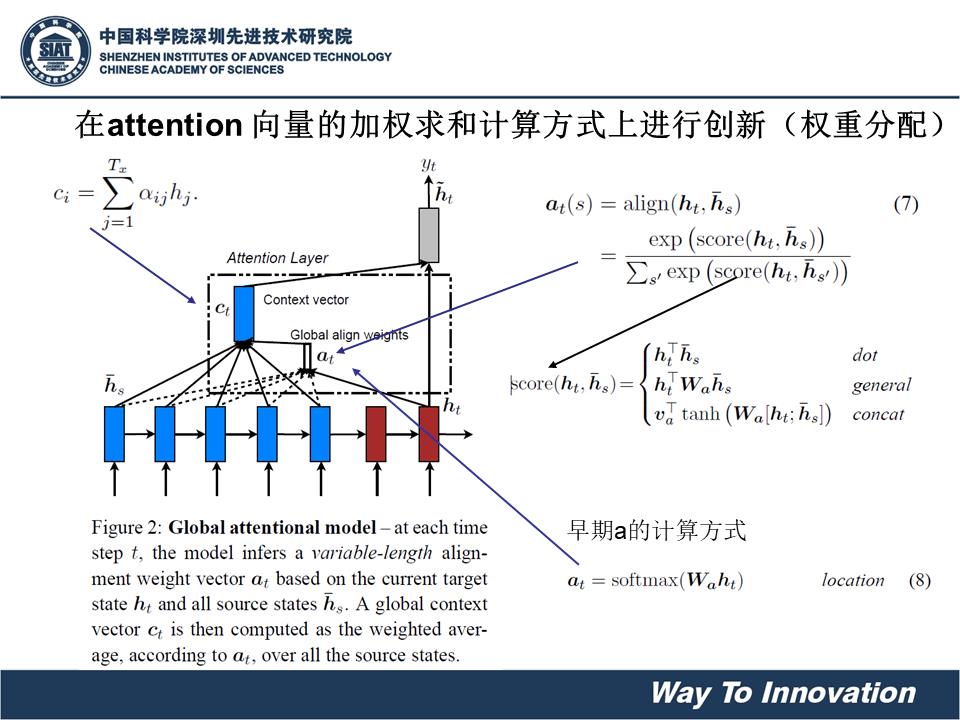
在每个第t步利用St和每个 编码过程中的隐藏状态 hi进行dot点积得到attention score,也称为相似度或影响得分。即每个 编码过程的隐藏状态 对当前的输出St的一个贡献度。计算公式如下:(此处按照斯坦福大学教材上用st和hi计算,原始论文为st-1)。
之后用softmax将attention-score转换为概率分布。按照概率分布将隐藏状态转换成加权和。公式如下:
由此得到上下文向量c(或者是注意力向量)。
最后将注意力向量ct和decoder的t时刻的隐藏状态St并联起来,继续之后步骤。
其图示如下:
给定一组向量集合values,以及查询向量query,我们根据query向量去计算values加权和,即成为attention机制。
attention的重点即为求这个集合values中每个value的权值。我们也称attention的机制叫做query的输出关注了(考虑到了)原文的不同部分。
如seq2seq模型中,St是后面的query向量,而编码过程的隐藏状态hi是values。其就是根据某些规则(或额外信息query)从向量表达集合values中抽取特定的向量进行加权组合的方法,只要从部分向量里用了加权和,计算使用了attention机制。
1.在向量加权和上做文章。
2.在匹配度的计算方式上做文章。
针对向量计算方式的变体:
soft / global / dynamic (都是soft attention)
hard
local attention(半软半硬attention)
静态attention
强制前向attention
soft / global / dynamic (都是soft attention)
是求概率分布,就是对于任意一个单词或者values都给出概率,attention得分经过softmax后权值用aph表示,把attention向量用ct表示。
hard attention
一般用在图像中 只选中一个区域,只选1个,其余为0。
local attention(半软半硬attention)
先选中一个区域,然后在其中的各个小部分生成概率分布。
论文:Effective Approaches to Attention-based Neural Machine Translation
在这个模型中,对于是时刻t的每一个目标词汇,模型首先产生一个对齐的位置 pt(aligned position),context vector 由编码器中一个集合的隐藏层状态计算得到,编码器中的隐藏层包含在窗口[pt-D,pt+D]中,D的大小通过经验选择。
上式之中,大S指的是源句子的长度,Wp和vp是指的模型的参数,通过训练得到,为了支持pt附近的对齐点,设置一个围绕pt的高斯分布,其中小s是在以pt为中心的窗口中的整数,pt是一个在[0,S]之间的实数。小Sigma σ 一般取窗口大小的一半。
静态attention
对输出句子共用一个St。一般在BiLstm首位hidden state输出拼接起来作为St(图中为u)。
针对attention-score计算的变体:
第一个,s和hi的维数要一样。
第二个W矩阵是训练得到的参数,维度是d2 x d1,d2是s的hidden state输出维数,d1是hi的hidden state维数,也就是两者可以不同维度。
最后就是上面提到的additive attention,是对两种hidden state 分别再训练矩阵然后激活过后再乘以一个参数向量变成一个得分。
其中,W1 = d3xd1,W2 = d3xd2,v = d3x1 ,d1,d2,d3分别为h,s,v的维数,属于超参数。
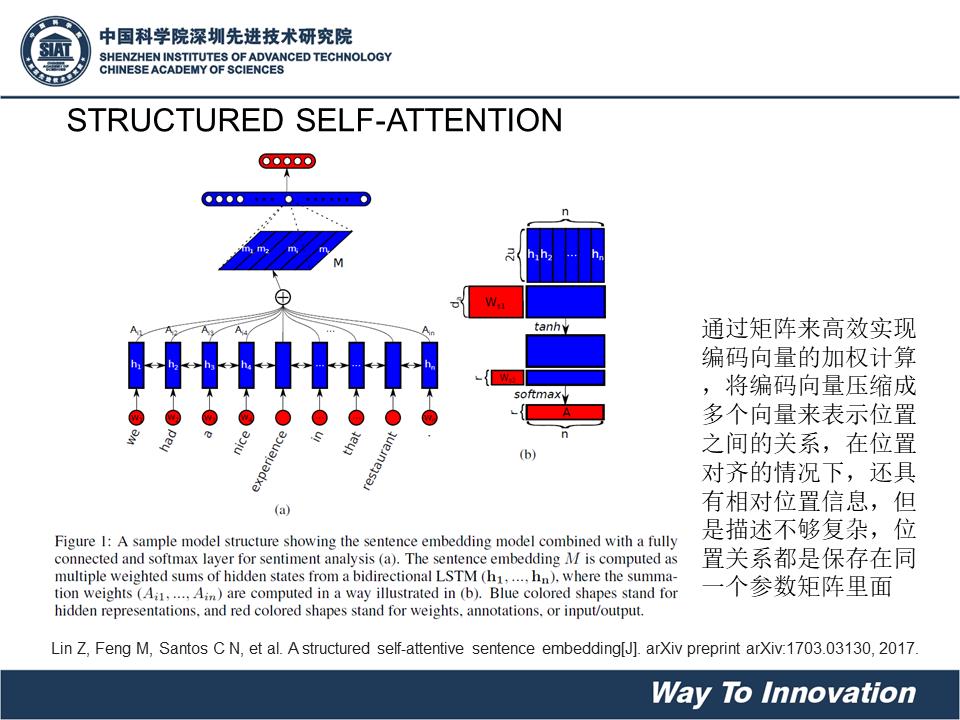
Self- attention
在没有额外信息下,仍然可以允许向量values使用self attention来处理自己,从句子中提取需要关注的信息。
2.以当前状态本身去计算得分作为当前单元attention score,这种方式更常见,也更简单,例如:
key-values attention
即将hi 隐藏状态拆分成两部分一部分是key(i) 一部分是values(i)然后只针对key部分计算attention的权值,然后加权使用values部分的值进行加权求和。
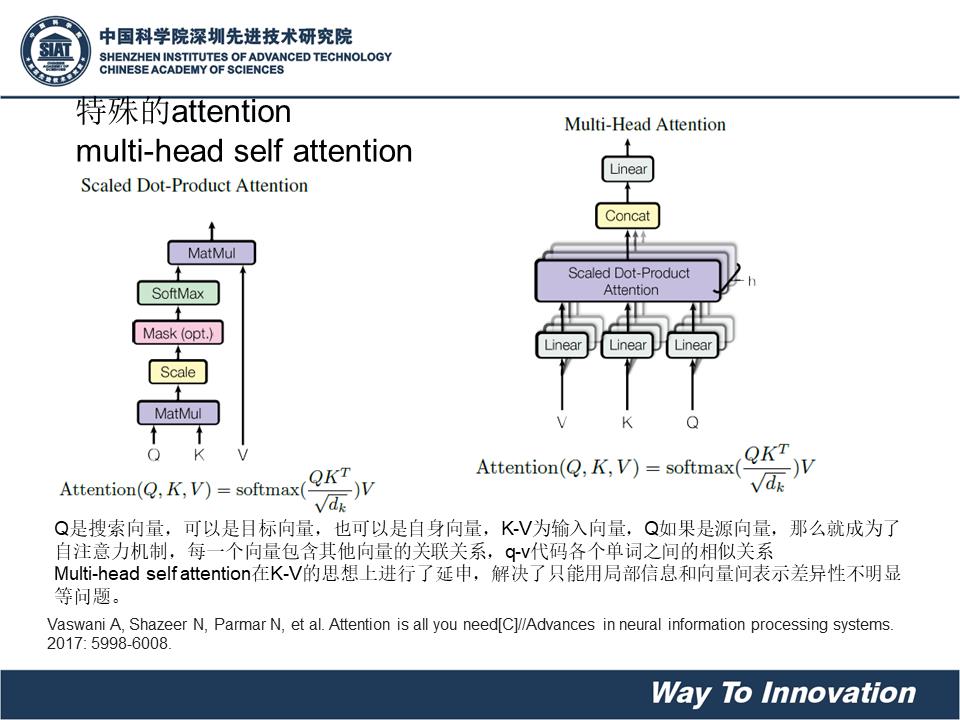
Multi-head attention:
首先,google先定义了一下attention的计算,也是定义出key,value,query三个元素(在seq2seq里面,query是st,key和value都是hi)在self 里面,query 是当前要计算的hi,k和v仍然一样,是其他单元的hidden state。在key value attention里面key和value则是分开了的。
然后除以了一下根号dk,为了让内积不至于太大(太大的话softmax后就非0即1了,不够“soft”了)
这里我们不妨假设,Q是
Wi用来先在算attention对三个矩阵做不同的矩阵变换映射一下,变成nxdk’,mxdk’,mxdv’维度。
最后做并联,有点类似于inception 里面多个卷积核的feature map并联的感觉。附:多核卷积示意图。
部分内容参考CSDN: https://blog.csdn.net/hahajinbu/article/details/81940355
Attention机制







ppt下载:
Attention机制ppt
以上是关于Attention机制总结的主要内容,如果未能解决你的问题,请参考以下文章
Attention机制的精要总结,附:中英文机器翻译的实现!
NLP-Word Embedding-Attention机制
CV中的Attention机制易于集成的Convolutional Block Attention Module(CBAM模块)